Stable-baselines: save and load is different from save then load ??!!
Hello I met one really strange problem. I write one snake environment as custom enrivonment https://github.com/pedrohbtp/snake-rl and using PPO2 to train it . the problem is, when i save model and load at the same time, this is correct. but when i save the model first and then load the model, it is wrong, I have tested many days and the situation is
snake_model.learn(total_timesteps=100000)
snake_model.save('./snake_modeltest')
snake_model2 = PPO2.load("./snake_modeltest")nake_model.learn(total_timesteps=100000)
snake_model2 = PPO2.load("./snake_modeltest")snake_model2 = PPO2.load("./snake_modeltest")
only the first situation will succeed. If I save it and then load it , it will fail. In other words, I must train, save and load at the same will the load function succeed. I used set_env and other functions so this is
not the problem.
And I tested another simple question, then it succeed no matter which situation !! So I guess this is the problem of your save and load. Maybe some situation will not work??
 zhaishengfu
zhaishengfu
All 11 comments
Hello,
I'm not sure to get your point... can you write a complete minimal example? And what do you mean by "succeed" ?
 araffin
on 27 Feb 2020
araffin
on 27 Feb 2020
ok I will give you detailed informaiton.
below is my snake environment based on https://github.com/pedrohbtp/snake-rl.
snake.zip
And I begin to train this model using PPO as following:
snake = Snake(width=20)
snake_env = DummyVecEnv([lambda : snake])
snake_model = PPO2('MlpPolicy', snake_env, verbose=1, learning_rate=1e-4)
snake_model.learn(total_timesteps=100000)
end = time.time()
print('training: ', end-start)
evaluate(snake_model, snake_env, num_steps = 1000)
snake_model.save('./snake_modeltest')
this is correct, the evaluate will return about 100, and the render result is correct .
the problem is , when I finish training and load it from dist as below:
snake_model2 = PPO2.load("./snake_modeltest")
snake_model2.set_env(snake_env)
evaluate(snake_model2, snake_env, num_steps = 1000, isrender=True)
the evaluate is about -50, that is , the trained model does not work!!!. I have tested multiple times and the results are always not correct,, reward about -50.
and what's more, If I train and load at the same time as below:
snake = Snake(width=20)
snake_env = DummyVecEnv([lambda : snake])
snake_model = PPO2('MlpPolicy', snake_env, verbose=1, learning_rate=1e-4)
snake_model.learn(total_timesteps=100000)
end = time.time()
print('training: ', end-start)
evaluate(snake_model, snake_env, num_steps = 1000)
snake_model.save('./snake_modeltest')
snake_model2 = PPO2.load("./snake_modeltest")
snake_model2.set_env(snake_env)
evaluate(snake_model2, snake_env, num_steps = 1000, isrender=True)
the model can work again. So, I must load at the same time when training. And If I load it from disk after traing, It will always not work at all.
And later, I tried another simple environment and load from disk, this time it worked. So I guess for some environment your save and load funtion may have bug??
I have seen the parameters but it confused me . Is this clear enough?
zhaishengfu
on 27 Feb 2020
Could you use snake_model.get_parameters() function to get the network parameters in these both cases, and compare them? For evaluation (using predict), the only things that should matter are network parameters. If these parameters are the same, but with different evaluation results, there could be something wonky in the environment (seeding?). However, if parameters are different, then indeed there is a bug we need to fix.
 Miffyli
on 27 Feb 2020
Miffyli
on 27 Feb 2020
@Miffyli this is the most strange part. the parameters is totally the same!!! You can test using the code i upload. when finished training, I evaluate it and see the parameters:
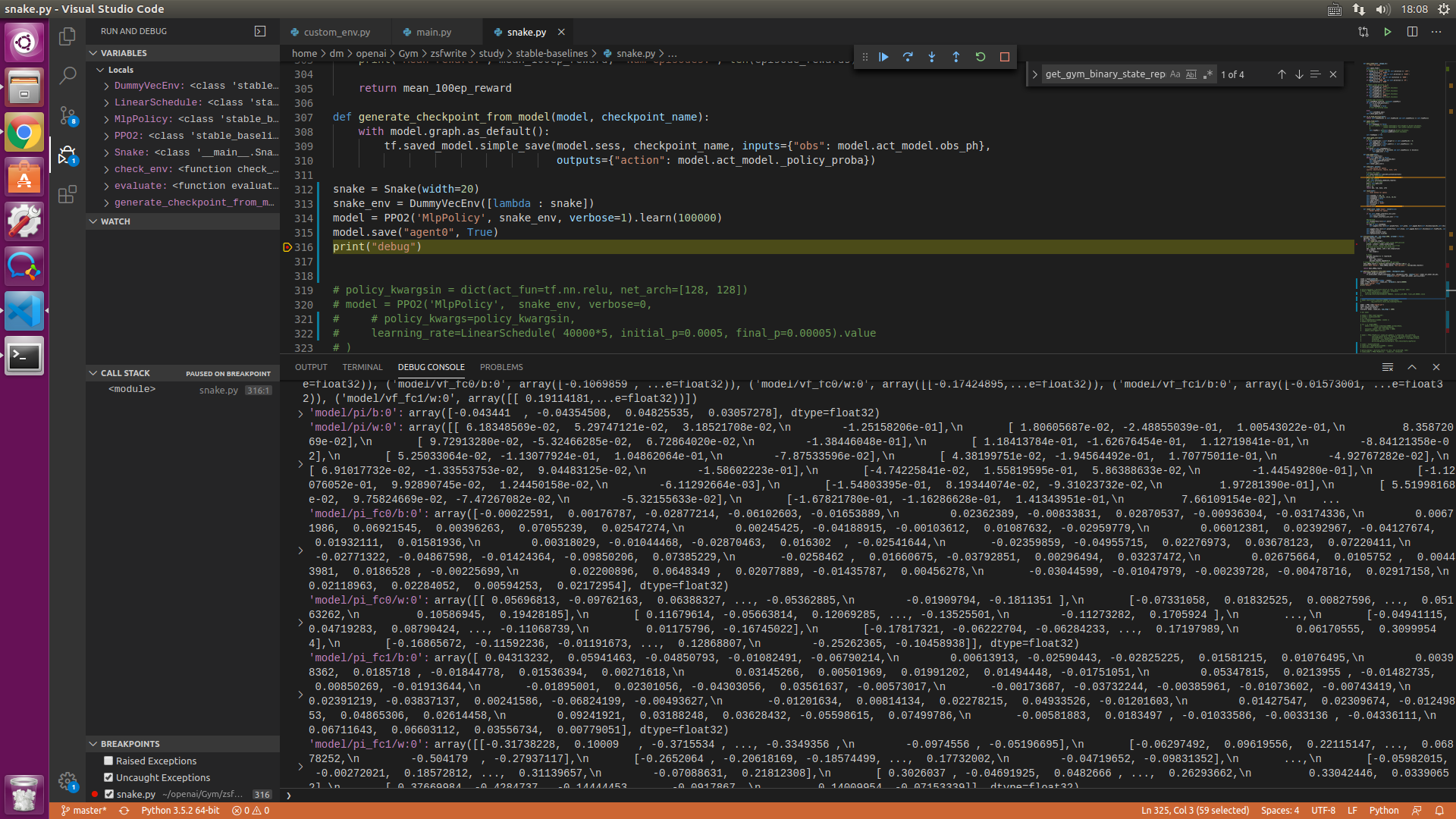
and both time they are the same!!!!
but when evaluate and render it , first train will be good and correct, but when load it and evaluate, the result is bad
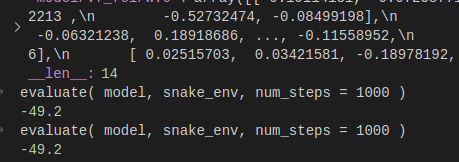
even though their parameters are the same !!
this is the reason I say "I have seen the parameters but it confused me". You can test my code . I really do not know the reason
zhaishengfu
on 27 Feb 2020
@Miffyli What you said confused me. If the parameters are the same , The reward will be similar, that is about 100 , not -49.2, right??
zhaishengfu
on 27 Feb 2020
Please use deterministic actions for evaluations. I would recommend you to report both the mean and std of the performance and use evaluate_policy (cf doc).
araffin
on 27 Feb 2020
@araffin hello, I tried both methods, and the results are wrong in both situation. As I said, If If train and save in the same time as below , this is correct :
snake = Snake(width=20)
snake_env = DummyVecEnv([lambda : snake])
model = PPO2('MlpPolicy', snake_env, verbose=1).learn(100000)
model.save("agent0", True)
model = PPO2.load("agent0.pkl")
model.set_env(snake_env)
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
print("debug", mean_reward, std_reward)
the mean and std is 130, 2630 and If I render it , the snake will get the food as expected.
and If I load it from disk, the result is wrong :
model = PPO2.load("agent0.pkl")
model.set_env(snake_env)
mean_reward, std_reward = evaluate_policy(model, model.get_env(), n_eval_episodes=10)
print("debug", mean_reward, std_reward)
the mean ans std is -50, 160. and -50 is the same as random model. That is, If I do not train and do random action, the reward is -50, So this time the load function does not work!.
and using predict with deterministic is the same result
model.predict(obs, deterministic=True)
If you have time you can try this code, It only cost about 30 second , Thanks
zhaishengfu
on 28 Feb 2020
@araffin And I have tried A2c save and load, the situation is the same
zhaishengfu
on 28 Feb 2020
@araffin @Miffyli and I used official baseline, found the same problem. I used deepq(I do not know why, but ppo2 using baselind does not work). the reward of deepq is ok.
python3 -m baselines.run --alg=deepq --env=Snake-v1 --num_timesteps=1e6 --save_path=~/models/snake_10M_deepq
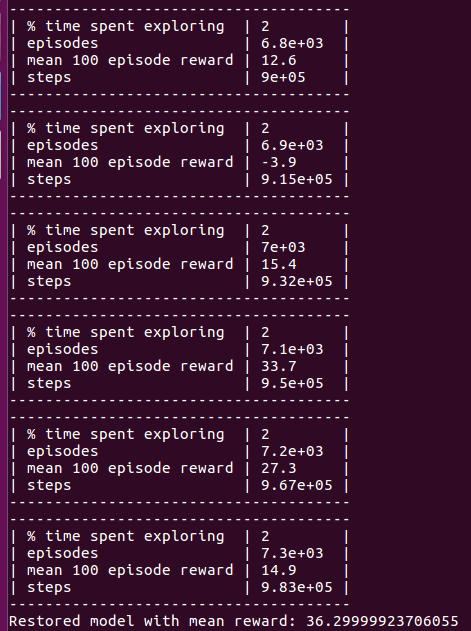
but when i using load and play, the result is wrong
python3 -m baselines.run --alg=deepq --env=Snake-v1 --num_timesteps=0 --load_path=~/models/snake_10M_deepq --play
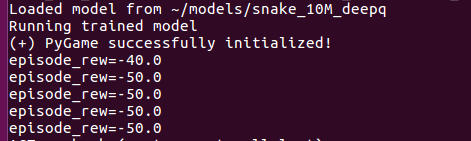
and I see the render result, Is is almost the same as
python3 -m baselines.run --alg=deepq --env=Snake-v1 --num_timesteps=0 --play
that is , whether load the model does not have any meaning .....
Indeed I want to load the saved model to train better results. But If in this situation I can only train once . This is really bad
zhaishengfu
on 28 Feb 2020
Issue lies in the environment code, specifically line 85. The observation vector is put into a dictionary (not sure why), and then iterated over. _Order of items is not guaranteed in a dictionary_, which is why at different runs you get different results: the observation vector is different!
Try removing the use of dictionary at that point, or if you really have to use a dictionary, use collections.OrderedDict.
If the environment then works fine, you can close this issue.
Miffyli
on 28 Feb 2020
@Miffyli @araffin Yes, you are right!!! I used collections.OrderedDict and Now I can load it correctly and the render result is also wonderful! Thank you very much 👍
Besides, I used official openai baseline, I do not know why but it is much slower than stable baseline with the same algorithm, and your library is easy to use. You really offered a wonderful library, Thanks again.
I will close this issue.
zhaishengfu
on 28 Feb 2020
Related issues
 smorad
·
3Comments
smorad
·
3Comments
 stefanbschneider
·
3Comments
stefanbschneider
·
3Comments
 HareshKarnan
·
3Comments
HareshKarnan
·
3Comments
 saeid93
·
3Comments
saeid93
·
3Comments
 ktattan
·
3Comments
ktattan
·
3Comments
Most helpful comment
Issue lies in the environment code, specifically line 85. The observation vector is put into a dictionary (not sure why), and then iterated over. _Order of items is not guaranteed in a dictionary_, which is why at different runs you get different results: the observation vector is different!
Try removing the use of dictionary at that point, or if you really have to use a dictionary, use
collections.OrderedDict.If the environment then works fine, you can close this issue.