Stable-baselines: DDPG + HER results surpass all baselines results. What am I doing wrong?
I know that this is not a direct issue stemming from this repository, and I apologise if this is not the place to open such an issue. For this work I am using my own repo, forked from OpenAI Baselines, to which I added some of the useful tools found in this repository. Thank you for any suggestions in advance.
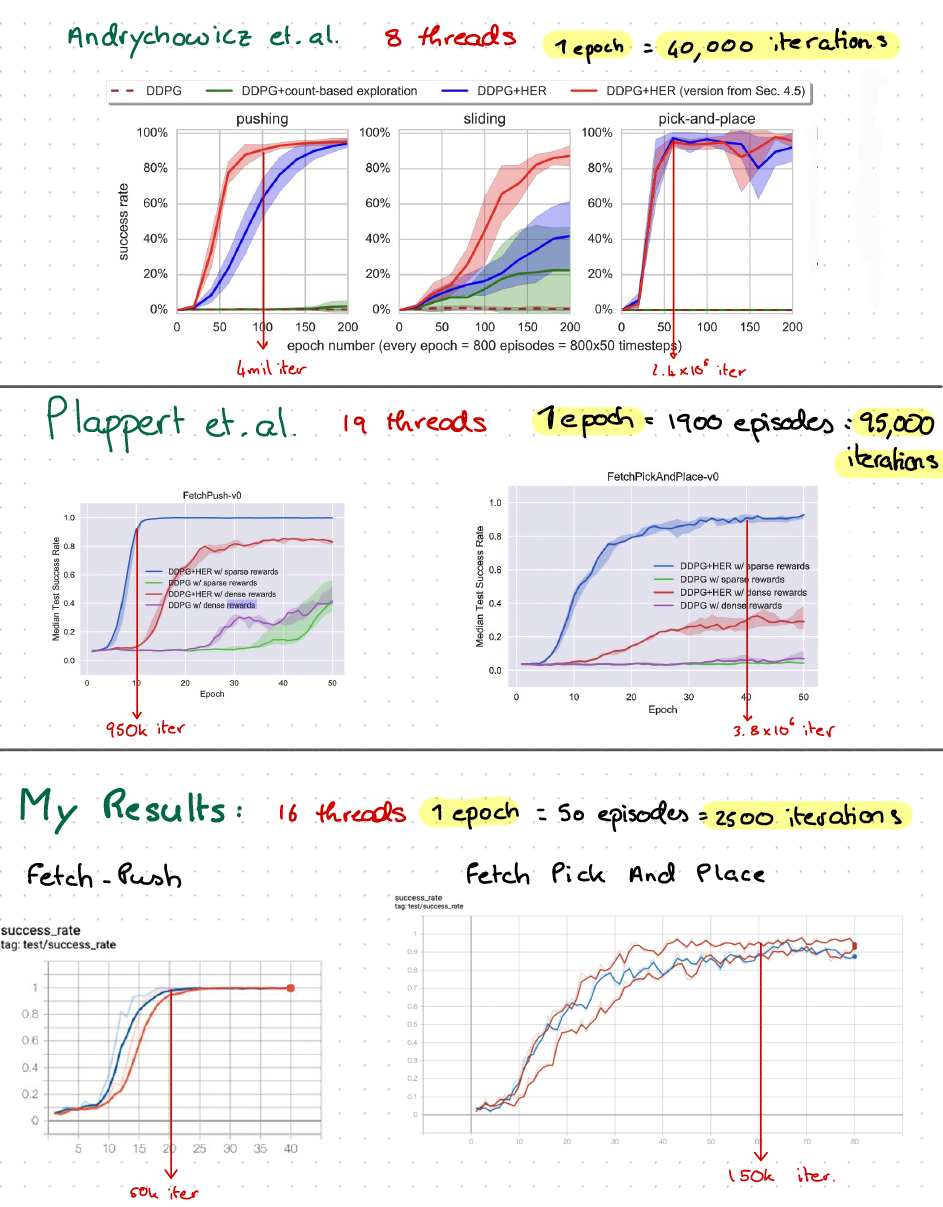
I am reproducing the results from Hindsight Experience Replay by Andrychowicz et. al. In the original paper they present the results below, where the agent is trained for 200 epochs.
200 epochs * 800 episodes * 50 time steps = 8,000,000 total time steps.
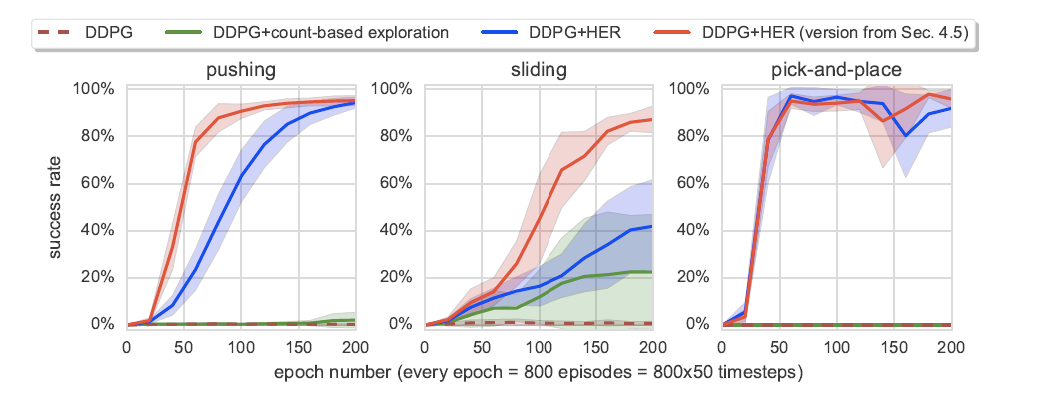
I try to reproduce the results but instead of using 8 cpu cores, I am using 16 CPU cores.
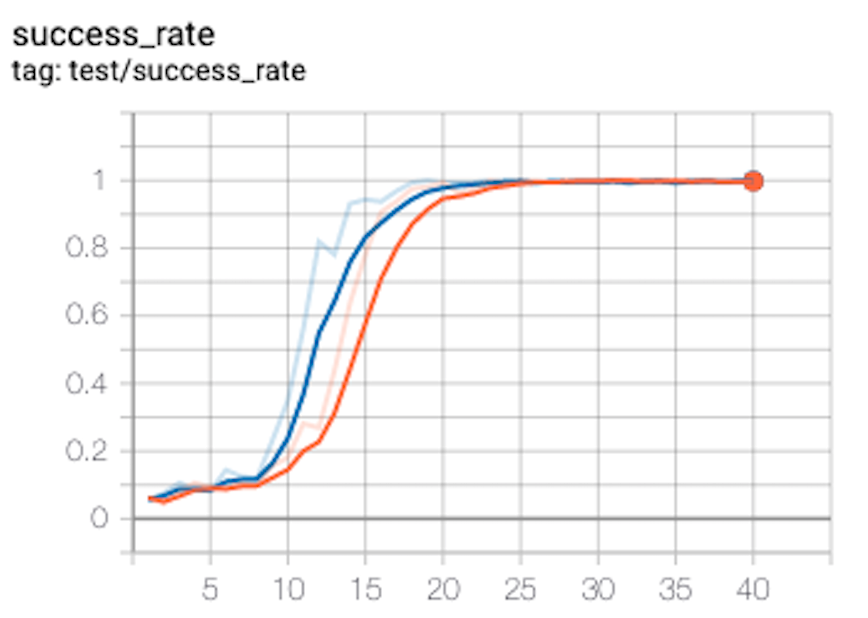
Fetch Push
I train the FetchPush for 80 epochs, but with only 50 episodes per epoch. Therefore 80 * 50 * 50 = 200,000 iterations. I present the curve below, generated using two random seeds:
After 20 epochs = 50,000 iterations we solve this environment. In the paper above, it took the original authors 100 episodes = 4,000,000 iterations to do so.
How is my algorithm converging 50 times faster?
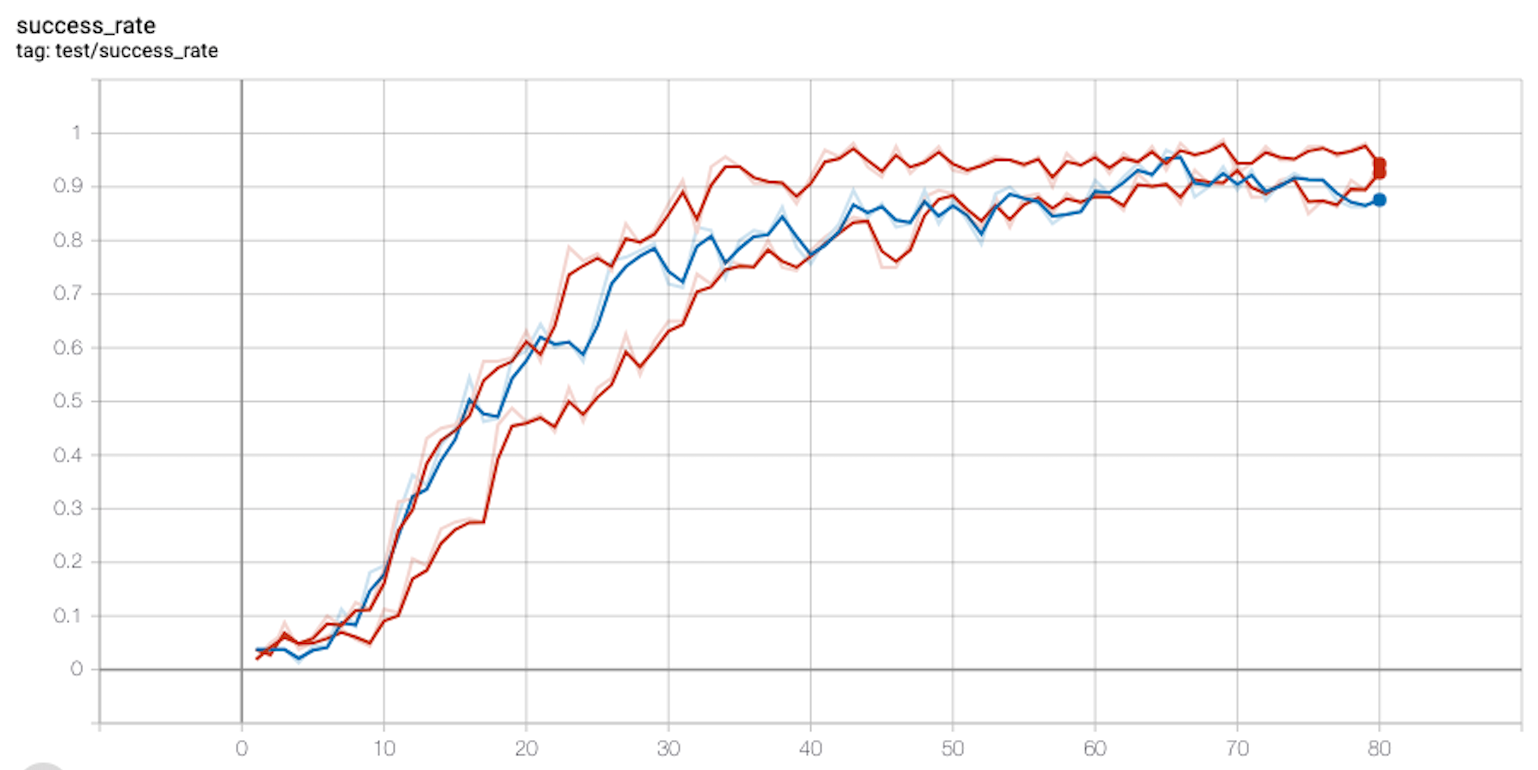
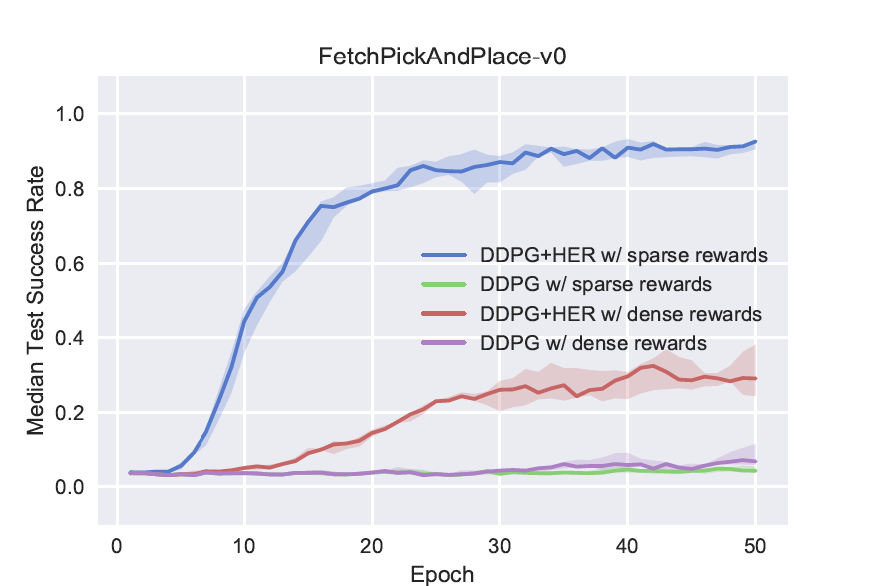
Pick and Place
I train the FetchPickAndPlace for 80 epochs, but with only 50 episodes per epoch. Therefore 80 * 50 * 50 = 200,000 iterations. I present the curve below, generated using three random seeds:
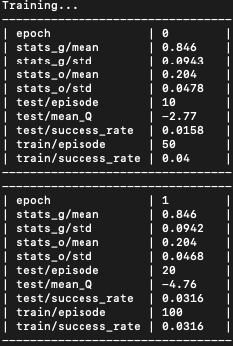
and logger output for the first two epochs, showing that indeed I have 50 episodes per epoch:
Now, as can be seen from my tensorboard plot, after 40 epochs we get a steady success rate, close to 1. 40 epochs * 50 episodes * 50 time steps = 100,000 iterations. Therefore it took the algorithm approximately 100,000 time steps to learn this environment.
The original paper took approximately 50 * 800 * 50 = 2,000,000 time steps to achieve the same goal.
How is it that in my case the environment was solved nearly 20 times faster? Are there any flaws in my workings above? Surely I am doing something wrong, right?
Results are also faster than another paper which also uses 19 MPI workers:
As stated in this paper: "We train for 50 epochs (one epoch consists of 19 2 50 = 1 900 full episodes), which amounts to a total of 4.75 x10^6 timesteps." It took around 2,000,000 timesteps to reach a median success rate of 0.9.
Summary
Any suggestions on what I may be doing wrong would be appreciated.
EDIT - Logging
Logging process shows that the rank 0 worker is reporting results. Inside her.py)
if rank == 0:
logger.dump_tabular()
The function responsible for writing all diagnostics is dumpkvs() inside logger.py:
def dumpkvs():
"""
Write all of the diagnostics from the current iteration
"""
Logger.CURRENT.dumpkvs()
Code can be found here (Very similar to the stable baselines logger):
https://github.com/openai/baselines/blob/master/baselines/logger.py
 RyanRizzo96
RyanRizzo96
All 4 comments
Related: #566 #424
I will do a more complete answer later ;)
 araffin
on 19 Feb 2020
araffin
on 19 Feb 2020
Quick remark that comes to my mind:
- did you check that the mujoco/gym version matches the original papers? (in gym, changes are sometimes made without notice)
- as mentioned in the other issues, the code of baselines is quite hard to read, especially regarding the different quantities for computing the number of timesteps.
araffin
on 19 Feb 2020
Thank you for your insight. Turns out that the gym and mujoco versions do not match. Authors are using FetchPush-v0 while I am using FetchPush-v1.
It still seems quite odd, however, that this would result in a 30 times increase in performance.
Also, epochs are calculated as follows:
n_epochs = total_timesteps // n_cycles // rollout_worker.T // rollout_worker.rollout_batch_size
where in my case:
80 = 200,000 // 50 // 50 // 1
I doubt I will be able to exactly replicate the results above, since having only one mujoco license restricts me from trying to satisfy all requirements.
RyanRizzo96
on 20 Feb 2020
I was reading the results incorrectly.
1 epoch = 50 episodes = 2500 timesteps
50 epochs = 2500 episodse = 125,000 timesteps
125,000*16 CPU cores = 2 million time steps.
Needed to multiply by number of CPUs. Thank you for your guidance and suggestions.
RyanRizzo96
on 23 Feb 2020
Related issues
 smorad
·
3Comments
smorad
·
3Comments
 JankyOo
·
3Comments
JankyOo
·
3Comments
 maystroh
·
3Comments
maystroh
·
3Comments
 sahilgupta2105
·
3Comments
sahilgupta2105
·
3Comments
 SerialIterator
·
3Comments
SerialIterator
·
3Comments