Spring-cloud-sleuth: Spring Cloud Sleuth incompatible with Brave's Kafka Instumentation
I'm trying to use Sleuth with Kafka and Kafka Streams. I'm using Spring Cloud Stream for both Kafka and Kafka Streams. I have a producer app (using Kafka) and a consumer app (using Kafka Streams). Sleuth is producing spans for both apps but the spans aren't forming unified traces. Instead I'm getting separate traces for each app.
I've debugged through the Sleuth and Zipkin code and I think I can see what's causing the issue but I'm not sure why it's happening. On the consumer side, each header on a Kafka message has quotes round the value. E.g. The X-B3-Sampled header has a value of ""1"" instead of "1", the "X-B3-TraceId" header has a value of ""5d5e68b48c8c725b37ce966d36fdeb82"" instead of "5d5e68b48c8c725b37ce966d36fdeb82" etc.
I have created a sample codebase: https://github.com/msmsimondean/kafka-tracing
 msmsimondean
msmsimondean
All 19 comments
Here's the output of kafkacat showing the headers on one of the messages from the example codebase above:
$kafkacat -localhost:9092 -t greetingsgs -C -f '\nKey (%K bytes): %k
Value (%S bytes): %s
Timestamp: %T
Partition: %p
Offset: %o
Headers: %h\n'
Key (-1 bytes):
Value (7 bytes): payload
Timestamp: 1566486626518
Partition: 10
Offset: 228
Headers: spanTraceId="5d5eb0621d2abe60567b80a606de911a",spanId="f997c2c7e57426fd",spanParentSpanId="567b80a606de911a",nativeHeaders={"X-B3-TraceId":["5d5eb0621d2abe60567b80a606de911a"],"spanTraceId":["5d5eb0621d2abe60567b80a606de911a"],"X-B3-SpanId":["f997c2c7e57426fd"],"spanId":["f997c2c7e57426fd"],"X-B3-ParentSpanId":["567b80a606de911a"],"spanParentSpanId":["567b80a606de911a"],"X-B3-Sampled":["1"],"spanSampled":["1"]},X-B3-SpanId="f997c2c7e57426fd",X-B3-ParentSpanId="567b80a606de911a",X-B3-Sampled="1",X-B3-TraceId="5d5eb0621d2abe60567b80a606de911a",spanSampled="1",contentType="application/json",spring_json_header_types={"spanTraceId":"java.lang.String","spanId":"java.lang.String","spanParentSpanId":"java.lang.String","nativeHeaders":"org.springframework.util.LinkedMultiValueMap","X-B3-SpanId":"java.lang.String","X-B3-ParentSpanId":"java.lang.String","X-B3-Sampled":"java.lang.String","X-B3-TraceId":"java.lang.String","spanSampled":"java.lang.String","contentType":"java.lang.String"}
When debugging through the consumer, in the https://github.com/openzipkin/brave/blob/5.6.5/brave/src/main/java/brave/propagation/B3Propagation.java#L136 class in the B3Extractor.extract method it isn't able to handle the value of the X-B3-Sampled header because of the double quotes.
msmsimondean
on 22 Aug 2019
Here's a screenshot of my debugger showing the value of the sampled variable is ""1"" (with extra quotes) causing sampledV to evaluate to null instead of true.
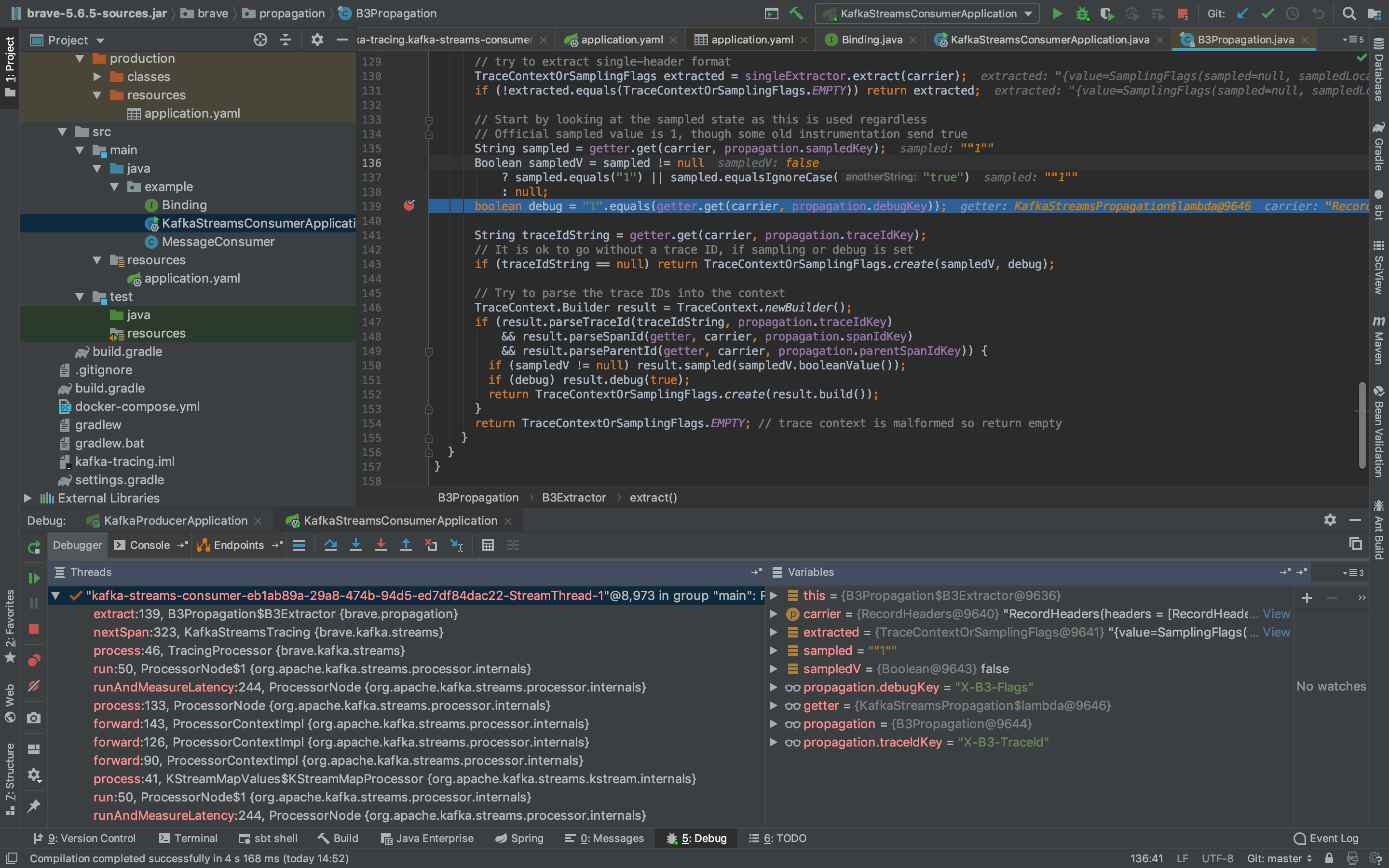
msmsimondean
on 22 Aug 2019
I'm using Spring Cloud Stream Binder Kafka with Spring Cloud Sleuth on the Producer side. On the Consumer side I'm using Spring Cloud Stream Binder Kafka _Streams_ with Brave's Kafka Instumentation.
In the Producer, org.springframework.cloud.stream.binder.kafka.BinderHeaderMapper (replaced with org.springframework.kafka.support.DefaultKafkaHeaderMapper in new version of Spring Cloud Stream Binder Kafka) is JSONifying the B3 message headers. Whereas on the Consumer side brave.kafka.streams.KafkaStreamsPropagation is trying to read the raw message headers without de-JSONifying them.
msmsimondean
on 22 Aug 2019
bear in mind propagation formats are not point-to-point between two java libraries. It is a multi-language issue. double-quotes will break anyone. Let's please figure out where the json encoding is happening and stop it https://github.com/openzipkin/b3-propagation
 codefromthecrypt
on 23 Aug 2019
codefromthecrypt
on 23 Aug 2019
Here's a workaround. Place the following config and bean in the producer:
Config:
spring.cloud.stream.kafka.binder.header-mapper-bean-name: headerMapper
Bean:
import org.springframework.kafka.support.SimpleKafkaHeaderMapper;
...
@Bean
public SimpleKafkaHeaderMapper headerMapper() {
SimpleKafkaHeaderMapper headerMapper = new SimpleKafkaHeaderMapper("*");
headerMapper.setMapAllStringsOut(true);
return headerMapper;
}
Can we do sth about this @olegz ? Is it a stream issue, or Sleuth should take into consideration some user setup?
 marcingrzejszczak
on 26 Aug 2019
marcingrzejszczak
on 26 Aug 2019
Here's another workaround. Place the following config and bean in the producer:
Config:
spring.cloud.stream.kafka.binder.header-mapper-bean-name: headerMapper
Bean:
import org.springframework.kafka.support.DefaultKafkaHeaderMapper;
...
@Bean
public DefaultKafkaHeaderMapper headerMapper() {
DefaultKafkaHeaderMapper headerMapper = new DefaultKafkaHeaderMapper("*");
Map<String, Boolean> rawMappedHeaders = new HashMap<>();
rawMappedHeaders.put("spanId", true);
rawMappedHeaders.put("spanParentSpanId", true);
rawMappedHeaders.put("spanSampled", true);
rawMappedHeaders.put("spanTraceId", true);
rawMappedHeaders.put("X-B3-ParentSpanId", true);
rawMappedHeaders.put("X-B3-Sampled", true);
rawMappedHeaders.put("X-B3-SpanId", true);
rawMappedHeaders.put("X-B3-TraceId", true);
// Note the `setRawMappedHaeaders` method contains a typo in its method name.
// See the extra 'a' after the 'H' in 'Headers'. The type has been fixed in
// a later (not yet released as part of Spring Cloud) version of the
// `spring-kafka` library.
headerMapper.setRawMappedHaeaders(rawMappedHeaders);
return headerMapper;
}
ping @olegz
marcingrzejszczak
on 4 Sep 2019
After discussing it with @sobychacko it appears that there may be an issue with DefaultKafkaHeaderMapper from spring-kafka. We're going o take a look and get back to you.
Also tagging @garyrussell and @artembilan to see if they can add something to this. . .
 olegz
on 5 Sep 2019
olegz
on 5 Sep 2019
It's not an "issue" with Spring Kafka per se; the workaround provided by @msmsimondean above is correct - it instructs the mapper to not JSON encode those headers. We could hard code them into the mapper but that would be brittle and not desirable; we need some mechanism for libraries to provide a list of headers to treat as raw.
 garyrussell
on 5 Sep 2019
garyrussell
on 5 Sep 2019
There is also an option like this:
/**
* Set to true to map all {@code String} valued outbound headers to {@code byte[]}.
* To map to a {@code String} for inbound, there must be an entry in the rawMappedHeaders map.
* @param mapAllStringsOut true to map all strings.
* @since 2.2.5
* @see #setRawMappedHeaders(Map)
*/
public void setMapAllStringsOut(boolean mapAllStringsOut) {
So, no need to worry about some specific String-based headers to configure explicitly.
 artembilan
on 5 Sep 2019
artembilan
on 5 Sep 2019
Since it's not an issue in Sleuth and the workaround got documented in this issue I'll close it for now.
marcingrzejszczak
on 18 Sep 2019
@marcingrzejszczak surely it is an issue in Sleuth though? @garyrussell indicated it's not really a Spring Kafka issue. If it wasn't a Spring Kafka issue and it wasn't Spring Cloud Sleuth issue, then where would the issue lie?
msmsimondean
on 18 Sep 2019
Ah sorry, I misread it.
marcingrzejszczak
on 18 Sep 2019
I've tried to implement this workaround for a project using springboot 2.0.0.RELEASE but I failed.
Is there any other workaround for this despite upgrade my dependencies?
 amandasantanati
on 20 Sep 2019
amandasantanati
on 20 Sep 2019
2.0.0.RELEASE is an ancient version. Please upgrade to the latest one
marcingrzejszczak
on 25 Sep 2019
looks much better now:
marcingrzejszczak
on 2 Oct 2019
Hi,
sorry, maybe I am totaly wrong but after lot of debuging i think that this:
class SleuthDefaultKafkaHeaderMapper extends DefaultKafkaHeaderMapper {
// related to #1430
static final String BEAN_NAME = "kafkaBinderHeaderMapper";
SleuthDefaultKafkaHeaderMapper() {
setMapAllStringsOut(true);
}
}
broke this:
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'")
public void receiveBogey(@Payload BogeyPojo bogeyPojo) {
// handle the message
}
however this works buy i don't like it
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'.getBytes()")
 mmarko-tempest
on 6 Dec 2019
mmarko-tempest
on 6 Dec 2019
Related issues
 apolischuk
·
7Comments
apolischuk
·
7Comments
 dsyer
·
8Comments
dsyer
·
8Comments
 oburgosm
·
4Comments
oburgosm
·
4Comments
 beltram
·
7Comments
beltram
·
7Comments
 JaxXu
·
4Comments
JaxXu
·
4Comments
Most helpful comment
Hi,
sorry, maybe I am totaly wrong but after lot of debuging i think that this:
broke this:
however this works buy i don't like it
@StreamListener(target = Sink.INPUT, condition = "headers['type']=='bogey'.getBytes()")