Spinalcordtoolbox: Output cord segmentation is empty on image with reasonable contrast
Description
The function runs successfully, but the resulting segmentation image is empty.
Steps to Reproduce
Data: sct_testing/issues/20180517_issue1740
Run:
sct_deepseg_sc -i 9611-0_0-images_017_jvgre10TE2mm1001_trace15Cav.nii.gz -c t2s
State of spinalcordtoolbox
master/9e294bb9dc06f980b12cf80f3fde6ab8416ac860
 stephaniealley
stephaniealley
All 19 comments
I experience the same problem with sct_deepseg_gm, i.e., output segmentation is empty.
 jcohenadad
on 17 May 2018
jcohenadad
on 17 May 2018
Investigating further, the issue with sct_deepseg_sc happens at the centerline detection: for each slice, the centerline is located at the R-P corner.
@charleygros Maybe a problem with the image intensity (<1), and type conversion done before running Optic (float32 --> uint)?
jcohenadad
on 17 May 2018
@jcohenadad : Yes it is certainly caused by this line:
https://github.com/neuropoly/spinalcordtoolbox/blob/master/spinalcordtoolbox/centerline/optic.py#L95
 charleygros
on 17 May 2018
charleygros
on 17 May 2018
So, this volume doesn't seem to be unnormalized (the intensities seems to be zero centered, so they probably did a zscore normalization). Our models assume that the input isn't already normalized because we have to do normalization on the input, so if we feed this normalized data, there will be another normalization done by the algorithm, shifting the distributions depending on the normalization employed in the algorithm. Are they able to send the original data without pre-processing ? We had the same issue with the marmoset dataset, where they sent the data with bias corrections, etc.
As a side note, I'm working actively to find a better normalization (both for input of the model and also inside the model) as part of the domain adaptation work, so after finishing this we can change the way we do normalization, but right now it's risky to change this just for this subject because it will involve retraining and re-validating the entire pipeline again. I spoke with @charleygros and on his case he is doing a different normalization so he will not have the same problems that I have on sct_deepseg_gm, but there is always a risk of things going wrong when two stages of normalization is applied on the input data, so it's always good to make sure that the data labs send, are not pre-processed because every lab can do a different pre-processing or corrections that will break our assumptions.
 perone
on 17 May 2018
perone
on 17 May 2018
@perone two things
- some sequences or dcm conversion software can give you any dtype or normalized intensity. So we cannot assume "unnormalization".
- even if there is normalization, applying another normalization should not be a problem if precision was not lost at the first place. So i suggest you check your assumptions on the input data type?
jcohenadad
on 18 May 2018
Oka, I'll work on finding something that would be robust to it and that it will not cause issues when applied to data already normalized. 👍
perone
on 18 May 2018
If we are worried that those modifications will impact the results in a large dataset, sct_pipeline running on sct_testing/large is here to help and should be used for the sct_deepseg* functions as well. Issue opened here: https://github.com/neuropoly/spinalcordtoolbox/issues/1747
jcohenadad
on 18 May 2018
@perone maybe you could use what is already implemented there for safe intensity rescaling and to avoid code duplication in SCT. The code is currently not working (as of 2018-05-18 10.25) but @charleygros is working on it.
jcohenadad
on 18 May 2018
So, we can use the same thing, however, the model has to be trained with this same normalization. There is also interaction with the model internal way of doing normalization or not (batchnorm, etc), especially when using multiple distributions (multiple centers, etc). So what I'm doing now is testing different ways of doing the initial normalization together with different ways of normalizing the internal representations of the network in a way that can improve generalization to other centers data. I want to be sure of that, otherwise we might solve some issues for one center and then not for another, etc. I also have to retrain the model later, validate, update the code, the model, test everything, so I don't want to to all of this without making sure that it will improve for other cases too. Right now I can't just change the normalization because the model wasn't trained with this normalization and it will just give poor results.
perone
on 18 May 2018
@perone I don't understand this argument. To me, so far your function has been working fine with uint16 input, right? So, if that's the case, then how could a rescaling+changeType (float-->uint16), which produces similar intensity distribution as "unprocessed data which are uint16 at the first place", be problematic? I don't understand how this has to do with the way the model has been trained. To me this is a completely separate issue. Maybe I am missing something?
jcohenadad
on 18 May 2018
I think we're discussing two different things probably. If we look the file 9611-0_0-images_017_jvgre10TE2mm1001_trace15Cav.nii.gz, we'll see that it is indeed float 32-bits:
~# fslinfo 9611-0_0-images_017_jvgre10TE2mm1001_trace15Cav_-31_689_31_115999.nii.gz
data_type FLOAT32
dim1 416
dim2 416
dim3 25
dim4 1
datatype 16
What I was referring to, is that this volume has float data type but it was normalized to be zero-cenetered (the intensities are all around 0.0). Now, the sct_deepseg_gm model was trained with data normalized using a standardization where the values for the mean and std. dev. were estimated using the mean and std. dev. from the entire dataset that the model was trained. The reason why it is not working now, is that these normalized values (around 0.0) will enter in the pipeline and it will get normalized again but with different parameters (the ones estimated from the dataset), therefore un-centering the data before feeding them into the network.
If I change the normalization procedure for the sct_deepseg_gm now, it might work for this data, but not for other data that is not normalized. I never use other data type besides a float 32-bits for inputing data into the model, so I didn't get the part about uint16.
perone
on 18 May 2018
@perone My understanding is that the mean/std of this particular dataset is very different from the average mean/std of your trained dataset, right? So my suggestion was to rescale the input data at the beginning of sct_deepseg_gm, such that it matches the range that you expect to see as the input of your algorithm. For example, if you expect to see [0, 65,535] (uint16), then by rescaling the input data to this range, you will be 100% sure that you are feeding the correct data range, regardless the distribution: it should work for ranges [-1,1], [0,1], etc.
Note: here I am using uint16 as an example.
jcohenadad
on 18 May 2018
The first phrase is correct, the mean/std is very different with this dataset, however we don't expect a range but a zero-centered and unit-variance distribution normalized by the training set parameters, and this normalization is done by normalizing data with training dataset estimated parameters, that is where the problem lies. For instance, if I remove the pre-processing now it won't work (the distribution of this volume is very different then the other trained volumes and is actually not centered/unit-variance). However, if I normalize this volume to be zero-centered and unit-variance (it wasn't before, I really don't know why these intensities are like that in this volume), it yelds good results:
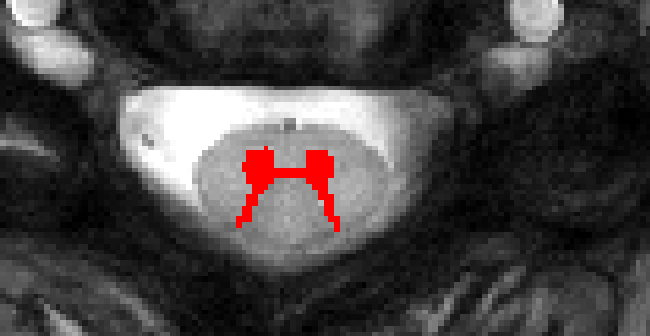
However, if we change the normalization to that scheme, it might work for this case, but not for others. That's why we need to retrain the model with another normalization that is robust to it, maybe per-slice but I need to test to compare results and validate, otherwise we might end up solving the problem for some cases and not for the others.
My proposal is: let me finish the testing with the different normalizations for the domain adaptation and then I can use the same normalization in the sct_deepgm_seg, just to be sure and avoid doing something that we'll have rework later. I think that a per-slice standardization (with estimated parameters from the slice itself) will work fine, but I just need to test before.
PS: The network will always expect float's, I don't think we should use uint16 for anything here, even if the volume is using integers, we should use the get_fdata() as the get_data() is being deprecated because of that many data types confusion in the volumes (where it is really hard to predict the type your're going to get with get_data() and the correct scaling). If you do something like that, to expect values between 0 and 65535 (integer), you'll be decimating information because different intensities will map to the same integer value, and this isn't good for the model because it will lose precision.
perone
on 18 May 2018
@perone ok, I get it about the range. I also get it that you would like to work on another intensity normalization method, based on the discussion we had previously this week. I agree this has to change, so it's great that you are looking into it. What I still don't understand however, is why you don't want to standardize all input images at the beginning of your pipeline, without touching the model. You mentioned that "it might work for this case, but not for others", but unless we try it, we'll never know. Maybe it is a good fix for now.
The reason I am pushing for that route, is that the deadline for the GM challenge is coming in a few days, and we need to have a stable version of SCT ready for it. My feeling is that your investigations will take more than 1-2 days, which is why I would like to at least try the standardization. If it works, then great! We'll have a working SCT to present to the community, and you can continue working on better normalization strategies for the coming weeks/months.
Now about the question: "how can we make sure it will not break with other images?". I'm working on it (#1750, #1747, working branch: jca_1750). Currently testing on Compute Canada on ~2000 images from different centers, intensities, type, etc. I think this is the ultimate test that we should base our decisions on.
jcohenadad
on 19 May 2018
Ah ok I didn't know about the GM challenge deadline ! I'll work on a PR to change the normalization of the model then and submit it soon. There is also another alternative, instead of changing it, we can add a flag that will switch the normalization, what do you think it's better ? A flag that can be used or changing the current normalization we have ?
perone
on 19 May 2018
Ah ok I didn't know about the GM challenge deadline ! I'll work on a PR to change the normalization of the model then and submit it soon. There is also another alternative, instead of changing it, we can add a flag that will switch the normalization, what do you think it's better ? A flag that can be used or changing the current normalization we have ?
how about you try with systematic standardization, we test in on the large database, and if we are happy we won't need the flag (might be confusing for users)
jcohenadad
on 19 May 2018
Oka, by systematic standardization you mean volume-wise standardization by making it zero-centered and unit-variance right ? Just to be sure.
perone
on 19 May 2018
While we are working on this issue, a workaround is to multiply by 1000 before running deepseg:
~
sct_maths -i T2SAG_resample.nii.gz -mul 1000 -o T2SAG_resample_scaled.nii.gz
sct_propseg -i T2SAG_resample_scaled.nii.gz -c t2
~
also see: https://sourceforge.net/p/spinalcordtoolbox/discussion/help/thread/66475b3e/
jcohenadad
on 22 May 2018
fixed via #1746 and #1757
jcohenadad
on 23 May 2018
Related issues
 joshuacwnewton
·
20Comments
jcohenadad
·
24Comments
jcohenadad
·
37Comments
jcohenadad
·
24Comments
jcohenadad
·
20Comments
joshuacwnewton
·
20Comments
jcohenadad
·
24Comments
jcohenadad
·
37Comments
jcohenadad
·
24Comments
jcohenadad
·
20Comments