Spacy: UserWarning: [W030] Some entities could not be aligned in the text ...
Since upgrading to the latest Spacy 2.3.0 (I think from 2.2.4, but am not sure, I repeatedly get the following warning, always related to the same character ('-'):
lib/python3.7/site-packages/spacy/language.py:479: UserWarning: [W030] Some entities could not be aligned in the text ... Use `spacy.gold.biluo_tags_from_offsets(nlp.make_doc(text), entities)` to check the alignment. Misaligned entities ('-') will be ignored during training.
gold = GoldParse(doc, **gold)
What does this warning mean? When does it occur?
Your Environment
Info about spaCy
- spaCy version: 2.3.0
- Platform: Linux-4.15.0-101-generic-x86_64-with-Ubuntu-18.04-bionic
- Python version: 3.7.4
 visionscaper
visionscaper
All 4 comments
Yes, this warning was added in v2.3.0. In v2.2 misaligned entities were silently ignored while training, which can potentially be pretty confusing for users. It occurs when the character offsets that you provide for an entity don't line up with a token boundary. An exaggerated example:
text = "Susan went to Switzerland."
entities = [(0, 3, "PERSON")]
Susan as an entity should be [(0, 5, "PERSON")] and the character span text[0:3] doesn't correspond to a token produced by the tokenizer. A lot of the real-life cases you might run into are related to punctuation like periods after abbreviations, currency symbols, and quotes where your NER annotation tokenization doesn't line up with spacy's tokenization.
The error message is trying to explain that misaligned entities will show up as '-' when you run spacy.gold.biluo_tags_from_offsets(nlp.make_doc(text), entities). I will think about how to clarify the error message, I see that it's confusing.
We also updated the warnings configuration to make it easier to control how warnings are shown in v2.3.0. You can see one example of how to filter warnings here (check out the possibilities for warnings.filterwarnings in the python warnings documentation):
 adrianeboyd
on 8 Jul 2020
adrianeboyd
on 8 Jul 2020
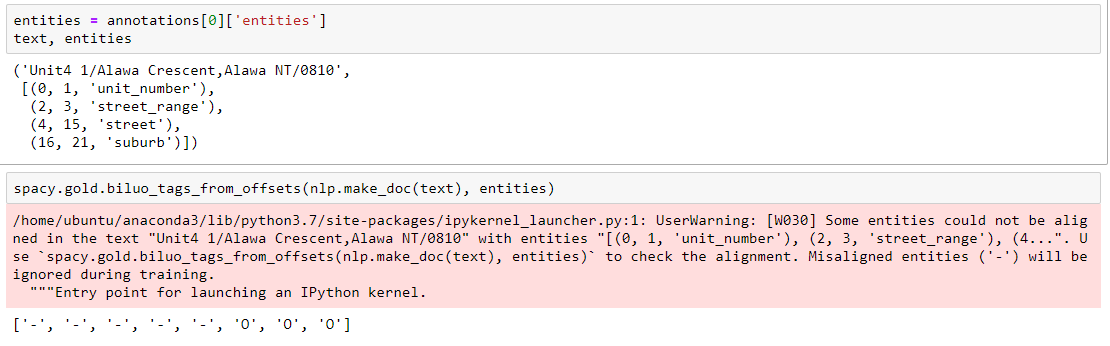
@adrianeboyd I am trying to create a custom parser with new entities like unit_number, street_range etc
I still get the same error and don't understand why? Could you please help and guide me what I am doing wrong?
 amaarora
on 11 Jul 2020
amaarora
on 11 Jul 2020
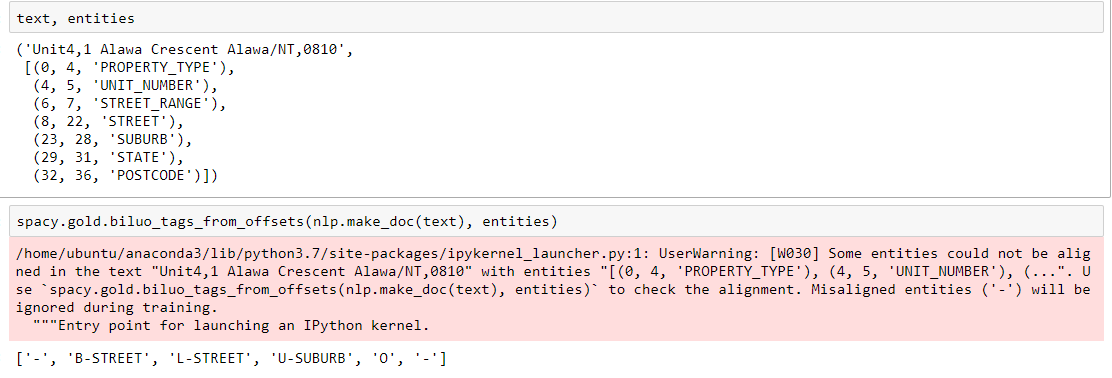
Just sharing another example for reference.
amaarora
on 11 Jul 2020
Hi @amaarora, this warning occurs when your "gold" entity offsets do not align with token boundaries as set by nlp.make_doc.
In your last example, you see for instance that STREET ("Alawa Crescent") could be aligned as the second (B-STREET) and third (L-STREET) token, but the first token ("Unit4,1") was kept as 1 token by the tokenizer and got 3 different entity types assigned to it (PROPERTY_TYPE, UNIT_NUMBER and STREET_RANGE) which resulted in a - instead because one token can only refer to one entity.
You have three options:
- Ignore these warnings, but note that your model won't be able to learn from misaligned entities
- Perform pre-processing on your input texts to ensure proper punctuation & white spaces:
Unit 4, 1 Alawa Crescent ... - Adjust your tokenizer so that it manages to work better on your specific text, domain and use-case.
 svlandeg
on 13 Jul 2020
svlandeg
on 13 Jul 2020
Related issues
 tonywangcn
·
3Comments
tonywangcn
·
3Comments
 besirkurtulmus
·
3Comments
besirkurtulmus
·
3Comments
 ajayrfhp
·
3Comments
ajayrfhp
·
3Comments
 cverluise
·
3Comments
cverluise
·
3Comments
 peterroelants
·
3Comments
peterroelants
·
3Comments
Most helpful comment
Hi @amaarora, this warning occurs when your "gold" entity offsets do not align with token boundaries as set by
nlp.make_doc.In your last example, you see for instance that
STREET("Alawa Crescent") could be aligned as the second (B-STREET) and third (L-STREET) token, but the first token ("Unit4,1") was kept as 1 token by the tokenizer and got 3 different entity types assigned to it (PROPERTY_TYPE,UNIT_NUMBERandSTREET_RANGE) which resulted in a-instead because one token can only refer to one entity.You have three options:
Unit 4, 1 Alawa Crescent ...