I'm trying to train an NER model using spacy train on data that's in spaCy's JSON format. I've set all the dependency and POS labels to "" and the head to 0 and given the model the --no-tagger --no-parser arguments. After the first epoch of training, I get this error:
Traceback (most recent call last):
File "/Users/ahalterman/anaconda3/lib/python3.6/runpy.py", line 193, in _run_module_as_main
"__main__", mod_spec)
File "/Users/ahalterman/anaconda3/lib/python3.6/runpy.py", line 85, in _run_code
exec(code, run_globals)
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/spacy/__main__.py", line 31, in <module>
plac.call(commands[command])
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/plac_core.py", line 328, in call
cmd, result = parser.consume(arglist)
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/plac_core.py", line 207, in consume
return cmd, self.func(*(args + varargs + extraopts), **kwargs)
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/spacy/cli/train.py", line 130, in train
scorer = nlp_loaded.evaluate(dev_docs)
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/spacy/language.py", line 472, in evaluate
scorer.score(doc, gold, verbose=verbose)
File "/Users/ahalterman/anaconda3/lib/python3.6/site-packages/spacy/scorer.py", line 91, in score
for annot in gold.orig_annot]))
File "gold.pyx", line 31, in spacy.gold.tags_to_entities
AssertionError: ['B-ORG', 'I-ORG', 'L-ORG', 'O', 'U-GPE', 'O', 'B-DATE', 'L-DATE', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'L-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'U-ORDINAL', 'O', 'O', 'O', 'U-ORDINAL', 'B-ORG', 'I-ORG', 'I-ORG', 'I-ORG', 'L-ORG', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-LOC', 'I-LOC', 'L-LOC', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'B-GPE', 'I-GPE', 'L-GPE', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'O', 'B-GPE', 'L-GPE', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'O', 'B-GPE', 'I-GPE', 'L-GPE', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'L-DATE', 'O', 'B-GPE', 'L-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'U-DATE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'U-DATE', 'O', 'O', 'B-EVENT', 'I-EVENT', 'I-EVENT', 'L-EVENT', 'O', 'O', 'O', 'O', 'U-NORP', 'O', 'O', 'O', 'O', 'U-GPE', 'O', 'U-DATE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'U-NORP', 'O', 'O', 'U-DATE', 'O', 'O', 'O', 'O', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'I-DATE', 'L-DATE', 'O', 'U-GPE', 'O', 'O', 'O', 'O', 'B-ORG', 'I-ORG', 'L-ORG', 'O', 'O', 'B-ORG', 'L-ORG', 'O', 'B-ORG', 'I-ORG', 'I-ORG', 'B-ORG', 'I-ORG', 'L-ORG']
Do you know what's going on? Here's the relevant part of my data, and I can share a complete training file if that's helpful.
{"head": 0,
"dep": "",
"tag": "",
"orth": "that ",
"ner": "O",
"id": 19},
{"head": 0,
"dep": "",
"tag": "",
"orth": "China ",
"ner": "U-GPE",
"id": 20}, ...
Your Environment
- Operating System:
- Python Version Used:
- spaCy Version Used:
- Environment Information:
 ahalterman
ahalterman
All 5 comments
I actually had a look at this last night, so I'm just copying over my reply from the Prodigy Support thread – maybe this helps?
Looking at the
AssertionErrorabove, it seems like the main issue here is that the data contains an invalid sequence (see the last few labels). So maybe something went wrong during the conversion?
'B-ORG', 'I-ORG', 'I-ORG', 'B-ORG', 'I-ORG', 'L-ORG'
^ start of new entity within open entity
 ines
on 30 Jan 2018
ines
on 30 Jan 2018
Oh yeah, definitely not right. But if I just call spacy.gold.tags_to_entities on that input, it converts it to spans just fine without the AssertionError. And I've gotten the error on a bunch of sets of documents, including ones that look fine (['B-ORG', 'I-ORG', 'I-ORG', 'L-ORG', 'O', 'O', 'O', 'O', 'O', 'O', 'U-ORG']).
ahalterman
on 30 Jan 2018
Let me know if there's another experiment I can try to figure out what could be up. It doesn't seem to matter whether I use "", 0, or "-", or fake tags for the labels and I'm getting the AssertionError even when the NER tags are correct.
ahalterman
on 9 Feb 2018
work with @ahalterman made the the spacy ar train working, so with Branch 2.0.9 I just customize build it with the AsserError get commented in the gold.pyx code
elif tag.startswith('I'):
#assert start is not None, tags[:i] (made this an comment)
continue
Also I notice that when git clone the branch v2.0.9 the ar model is not included under the /lang directory, but when pip install ar mode is there, so in order to make the ar model work with customized build, need to copy the ar model under the correspinding directory.
With the ontoNotes data we have we have 269358 labeled records being trained, and the performance looks good,
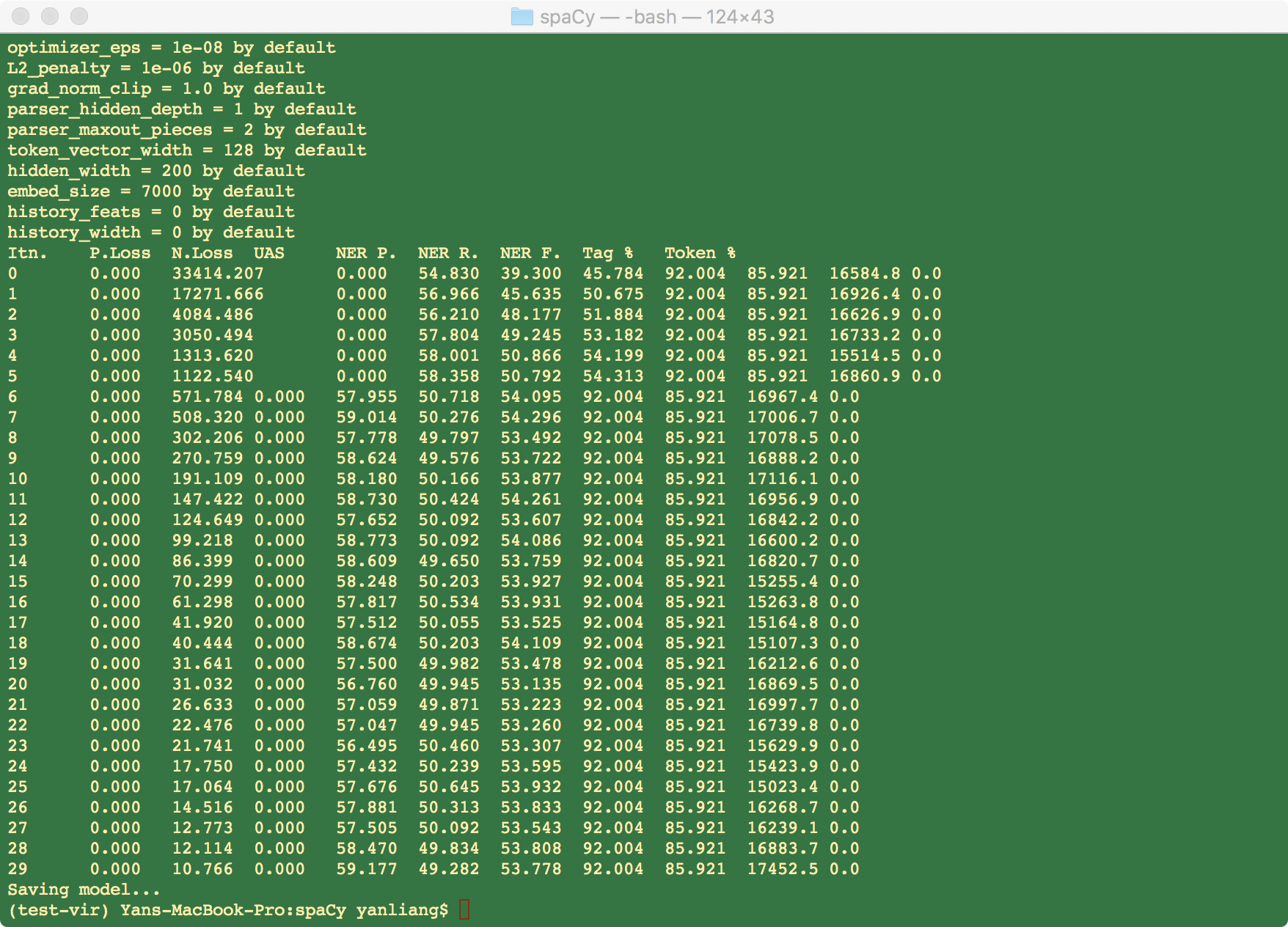
@ines
 YanLiang1102
on 1 Mar 2018
YanLiang1102
on 1 Mar 2018
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 12 Oct 2018
lock[bot]
on 12 Oct 2018
Related issues
 tonywangcn
·
3Comments
tonywangcn
·
3Comments
 ank-26
·
3Comments
ank-26
·
3Comments
 bebelbop
·
3Comments
bebelbop
·
3Comments
 cverluise
·
3Comments
cverluise
·
3Comments
 besirkurtulmus
·
3Comments
besirkurtulmus
·
3Comments
Most helpful comment
work with @ahalterman made the the spacy ar train working, so with Branch 2.0.9 I just customize build it with the AsserError get commented in the gold.pyx code
Also I notice that when git clone the branch v2.0.9 the ar model is not included under the /lang directory, but when pip install ar mode is there, so in order to make the ar model work with customized build, need to copy the ar model under the correspinding directory.
With the ontoNotes data we have we have 269358 labeled records being trained, and the performance looks good,

@ines