Spacy: [Website] Features table unclear

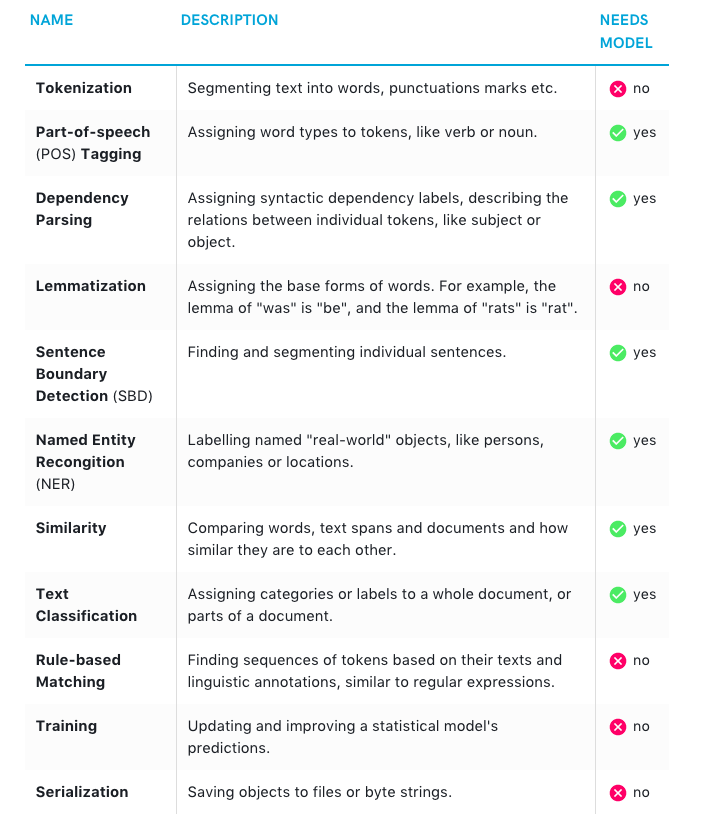
I was reading the introduction document and could not understand what the last column means. The header suggests that this is a boolean value but there are three options (red/green/gray). Does green mean that it does need a model or not? It would also be cool to avoid using only color as a means of encoding this information because it makes it difficult for colourblind red/green-blind people to judge the information.
I would propose to use symbols here or at least add a legend or tooltips on hover.
If you can explain the three colors to me I am more than happy to send a pull request or some mockups for how this could be displayed differently. 🤓
 k-nut
k-nut
All 9 comments
Thanks for the feedback – this is super valuable! The original idea here was green = yes (based on model predictions, so needs model data), red = no, grey = neutral / "it depends" (which, admittedly, is a bit vague – but both serialization and training don't actually require a model to be loaded in order to work - like dependency parsing for example – but they can be used in combination with one). Either way, I totally see how this is confusing.
Honestly, the more I look at this table, the more I'm like "wtf was I thinking when I built this", haha. It's also an accessibility nightmare btw – important information expressed with only icons and no other distinction except for colour (whyyyy?), and red/green/grey out of all colours. And ~I didn't even add ARIA labels or anything~ okay, I did add ARIA labels, but they were bad, so screen readers can't parse this mess either. So yeah, sorry about that. No idea why I did this.
As a solution, how about replacing the icons with "yes" and "no", and maybe adding an additional note to the "depends" features? The same also applies to the feature comparison here. And while I'm at it, I'll also add some proper ARIA attributes to the before/after code examples (e.g. here – it's more obvious visually, but still completely inaccessible).
I'm happy to take care of this, since it'll require some more fixes and decisions on the front-end – but let me know if this makes sense, and if you have any other suggestions!
Edit: I've been playing around with this, and the "needs model" thing is slightly trickier than I thought. I do think it's important to get this information across as early as possible, since it's one of the main sources of confusion for beginners. It's not immediately intuitive which functionality is built into spaCy, and what needs a statistical model. On the other hand, it's not always so black and white. The Lemmatizer in English uses the part-of-speech tags to predict a token's lemma – however, many languages also come with a lookup table that doesn't require a model at all. But this distinction is a little complex for one of the very first sections of the beginners guide... 🤔
 ines
on 28 Oct 2017
ines
on 28 Oct 2017
Current work in progress: now with distinctive icons and label. I also think that a better policy for categorising the features that "need a model" is to interpret "need" as "absolutely need", i.e. "can't do without" (at least, not by default in spaCy).
ines
on 29 Oct 2017
Thanks for improving the website / documentation!
Maybe it's worth adding a sentence above the table to describe the "needs model" column? If I didn't know SpaCy or NLP tools in general, I might wonder what it exactly means. Does it mean SpaCy is not feature complete? The red mark looks like something is "missing", "not yet supported" or "not available". In conjunction with "needs model" it sounds like we still wait for somebody to train a model for tokenization.
Maybe something like this:
While some features require an appropriate model, others work independently.
 emste
on 30 Oct 2017
emste
on 30 Oct 2017
@emste Good point, thanks! I hadn't really thought about the problems with the positive/negative connotation of the icons in this context. We definitely don't want new users to get the impression that tokenization not requiring a statistical model is somehow "bad" or "worse". (In fact, the main point of the table should be to demystify the processing pipeline and move away from just reducing it to spacy.load('en') – which I feel like hasn't particularly come across well in the past.)
Maybe we should just remove the "needs model" column and replace it with a column that describes how spaCy "does it" and where the information comes from? For example, something like:
- tokenization: special case rules and regular expressions
- part-of-speech tagging: statistical model, tagger
- dependency parsing: statistical model, parser
- lemmatization: lookup tables, dependency parse
- sentence boundaries: dependency parse, punctuation rules
- NER: statistical model
- similarity: word vectors, statistical model
- text classification: statistical model
- rule-based matching: token or phrase patterns
- training: ???
- serialization: ???
I really like your text suggestion btw. We could use that for the intro, plus maybe the text that's currently in the aside on the right (where it kinda gets lost at the moment – asides should be for additional notes, not for critical information).
While some features require an appropriate model, others work independently. If one of spaCy's functionalities needs a model, it means that you need to have one of the available statistical models installed. Models are used to predict linguistic annotations – for example, if a word is a verb or a noun.
We could still have an aside there that goes into more details about what exactly a "statistical model" is, what it does, where to find the models and install them etc.
ines
on 31 Oct 2017
I agree with the problem of the positive/negative connotations of the icons and think replacing them would be a good idea. ✅
@ines I like your idea of removing the column entirely. Thinking about it now: The main goal of this table is to show the reader what they can do with spacy, right? So it might not even be necessary to explain the way in which spacy does this because all the readers want to know is: What can I do with this tool? The actual implementation details could be deferred further down to the individual sections.
On the other hand it might be interesting to learn something about the internals in the summary table already for people that have some more knowledge of NLP and would like to understand, how spacy implements certain features...
k-nut
on 31 Oct 2017
@k-nut Yes, I think you're right! The main reason I wanted to cover the models in this section was to show what's statistical and what isn't – and to get this across as early as possible.
This may seem obvious to users who already have some knowledge of NLP, but to a beginner, this isn't necessarily intuitive. (And that whole "magical AI" narrative that's often used when talking about the technology doesn't help, either.)
For example: How does spaCy assign part-of-speech tags or named entities? Are there rules? Does the code in the library do all the magic? And what does it mean if spaCy "gets it wrong"? I also think that the concept of loading and installing models – and choosing between the different options – becomes much more obvious once you view the models as "binary data packs that enable spaCy to make predictions".
In terms of the 101 guide, another option could be to add this as a separate section underneath the features table and cover the components of the statistical models. Or just give a quick overview of what can be included – like, binary weights for the tagger, parser and entity recognizer, lexical entries in the vocabulary, word vectors etc.
If we manage to get this across right, I hope that what a new users takes away from this will be: "Ah, cool, so I can use spaCy to find entities in my text. All I need to do is plug in a binary data pack spaCy can use to make the predictions. And if I want different results for a different language or domain, I need to plug in a different data pack – or create my own!"
ines
on 31 Oct 2017
I really like this new approach os separating the two issues! ✨
k-nut
on 1 Nov 2017
Yay – it's all on develop now and will be uploaded as soon as v2.0.0a18 is out. So I'm closing this issue for now. Thanks again for your feedback!
ines
on 1 Nov 2017
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 8 May 2018
lock[bot]
on 8 May 2018
Related issues
 curiousgeek0
·
3Comments
curiousgeek0
·
3Comments
 smartinsightsfromdata
·
3Comments
smartinsightsfromdata
·
3Comments
 armsp
·
3Comments
armsp
·
3Comments
 ajayrfhp
·
3Comments
ajayrfhp
·
3Comments
 bebelbop
·
3Comments
bebelbop
·
3Comments