Someone has started to work on italian language for POS tags and NER or is interested to collaborate?
 italo1983
italo1983
All 15 comments
Hi @italo1983! I am italian... :) I have just started with spacy. I always used OpenNLP (Java). I would like to create POS and NER models with custom features. We can help each other.
 damianoporta
on 23 Apr 2017
damianoporta
on 23 Apr 2017
Hi @damianoporta how can we collaborate? Write me to [email protected] so we can get in touch.. speaking italian :)
italo1983
on 26 Apr 2017
Hi,
I'm Italian too and I'm interested in helping to add support for the Italian language
I have read the documentation https://spacy.io/docs/usage/adding-languages.
It would be interesting to have a bit more detailed doc about all the activities/commands needed to create a language package.
Eg,
What are the steps that were made to create en_core_web_sm language?
Thanks in advance
 abunet
on 9 May 2017
abunet
on 9 May 2017
Another Italian guy who is looking forward to see the Italian language among Spacy's models.
How have you organized to work on it? Is there a roadmap? Maybe @honnibal can guide us in order to correctly support Italian in Spacy.
Thank you to everyone for your support!
Bests,
Alessandro
 aleSuglia
on 23 May 2017
aleSuglia
on 23 May 2017
I've tried to follow the doc but without a more detailed guideline and examples it's very hard to build the POS and NER models and grammar rules.
I think that we can start from this page http://universaldependencies.org/#it to build something and generate the models.
italo1983
on 24 May 2017
Me too. Unfortunately I've never done something like this so it's not straightforward for me to do that. I've found this tagsets: http://universaldependencies.org/tagset-conversion/it-conll-uposf.html and http://universaldependencies.org/tagset-conversion/it-isdt-uposf.html. Can they be used to create a tagmap for Spacy?
aleSuglia
on 24 May 2017
Hey guys. Were you ever able to make any progress with an Italian language profile? Not Italian but I've been working on an application that has some Italian users and it'd be nice to be able to support them. Even if you've got something that's partially finished it might be interesting to have a look. Thanks!
 jdukatz
on 7 Aug 2017
jdukatz
on 7 Aug 2017
Dear @jdukatz,
My mother tongue is Italian so I'm really interested in helping SPaCy to support the Italian language. Do you have any ideas about how to create the required configuration files that are reported in the documentation?
Alessandro
aleSuglia
on 7 Aug 2017
@italo1983 @damianoporta @abunet @aleSuglia @jdukatz
Good news 🎉 The new version of spaCy alpha, v2.0.0a18, now comes with an Italian model, it_core_news_sm, which supports context vectors, tagging, parsing and NER. See here for model details and accuracy.
pip install -U spacy-nightly
spacy download it_core_news_sm
Would be cool to get some feedback on how it performs on your data!
 ines
on 3 Nov 2017
ines
on 3 Nov 2017
I will test on my data for sure in the next days too. I am very excited about this news!
 MartinoMensio
on 3 Nov 2017
MartinoMensio
on 3 Nov 2017
Wow! Thank you @ines
damianoporta
on 3 Nov 2017
Just pushed another update to the Italian model btw. There was a problem with the tag mapping to pos and pos_, which should now be fixed.
ines
on 5 Nov 2017
I am testing the displaCy visualizer on the italian model. I am getting some unwanted behaviour on the POS visualization:
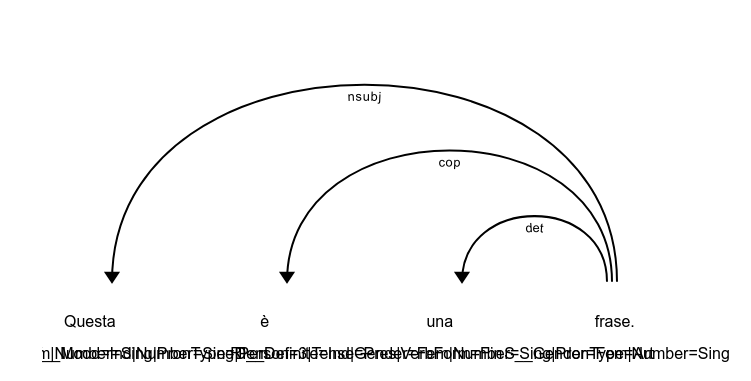
However if I check without displaCy, the values are ok.
Displacy code:
import spacy
from spacy import displacy
nlp = spacy.load('it')
doc = nlp(u'Questa è una frase.')
displacy.serve(doc, style='dep')
Spacy code:
import spacy
from spacy import displacy
nlp = spacy.load('it')
doc = nlp(u'Questa è una frase.')
for token in doc:
print(token.text, token.dep_, token.head.text, token.head.pos_,
[child for child in token.children])
output:
Questa nsubj frase NOUN []
è cop frase NOUN []
una det frase NOUN []
frase ROOT frase NOUN [Questa, è, una, .]
. punct frase NOUN []
Details of installed spaCy and model:
>>> spacy.info()
Info about spaCy
spaCy version 2.0.2
Location /home/martino/tesi/spacy2/venv_stable/lib/python3.6/site-packages/spacy
Platform Linux-4.13.12-1-ARCH-x86_64-with-arch-Arch-Linux
Python version 3.6.3
Models en, it
>>> nlp.meta
{'lang': 'it', 'pipeline': ['tagger', 'parser', 'ner'], 'name': 'core_news_sm', 'license': 'CC BY-SA 4.0', 'author': 'Explosion AI', 'url': 'https://explosion.ai', 'notes': 'Because the model is trained on Wikipedia, it may perform inconsistently on many genres, such as social media text. The NER accuracy refers to the "silver standard" annotations in the WikiNER corpus. Accuracy on these annotations tends to be higher than correct human annotations.', 'vectors': {'width': 0, 'vectors': 0, 'keys': 0}, 'sources': ['Universal Dependencies', 'Wikipedia'], 'version': '2.0.0', 'spacy_version': '>=2.0.0a18', 'description': 'Italian multi-task CNN trained on the Universal Dependencies and WikiNER corpus. Assigns context-specific token vectors, POS tags, dependency parse and named entities. Supports identification of PER, LOC, ORG and MISC entities.', 'parent_package': 'spacy', 'email': '[email protected]', 'accuracy': {'token_acc': 100.0, 'ents_p': 85.7416642222, 'ents_r': 85.4625550661, 'uas': 90.5078742042, 'tags_acc': 96.0421940928, 'ents_f': 85.6018821324, 'las': 86.7550619884}}
@MartinoMensio Thanks for the detailed report – now that I think about it, displaCy should probably show the POS as the default (instead of TAG), or at least offer an option to let you change this behaviour. Will fix this!
The thing with Italian (and some of the other new languages) is that they end up with very long tags, consisting of the tag and morphological features. spaCy jointly predicts those jointly, so they're merged before training. The .pos attribute is the shorter, simple part-of-speech tag.
In the meantime, to make displaCy more readable, you can edit this line in spacy/displacy/__init__.py and change .tag_ to .pos_:
ines
on 21 Nov 2017
This thread has been automatically locked since there has not been any recent activity after it was closed. Please open a new issue for related bugs.
![lock[bot] picture](https://avatars1.githubusercontent.com/in/6672?v=4&s=40) lock[bot]
on 20 Jun 2018
lock[bot]
on 20 Jun 2018
Related issues
 melanietosik
·
3Comments
melanietosik
·
3Comments
 curiousgeek0
·
3Comments
curiousgeek0
·
3Comments
 smartinsightsfromdata
·
3Comments
smartinsightsfromdata
·
3Comments
 ahalterman
·
3Comments
ahalterman
·
3Comments
 besirkurtulmus
·
3Comments
besirkurtulmus
·
3Comments
Most helpful comment
@italo1983 @damianoporta @abunet @aleSuglia @jdukatz
Good news 🎉 The new version of spaCy alpha,
v2.0.0a18, now comes with an Italian model,it_core_news_sm, which supports context vectors, tagging, parsing and NER. See here for model details and accuracy.Would be cool to get some feedback on how it performs on your data!