Spacy: Is there a way to find the probability or confidence score of the extracted named entities?
Usage
Your Environment
- Operating System: Windows 10
- Python Version Used: 2.7, 64 bit
- spaCy Version Used: 1.6.0
- Environment Information: Anaconda
 faizan30
faizan30
All 5 comments
The entity recogniser uses a transition-based model with greedy decoding. On every word it decides between the following actions:
- Begin: begin a new entity
- In: Continue the current entity
- Last: End the current entity (adding this token to it)
- Unit: Mark this work as a single-word entity
- Out: Mark the current word as not an entity.
The model scores each action on every word, unless only one action is available, e.g. at the end of a sentence. In that situation.
You can get the scores with the following method, although it's quite inefficient:
scores = numpy.zeros((len(doc), nlp.entity.model.nr_class))
with nlp.entity.step_through(doc) as state:
while not state.is_final:
action = state.predict()
next_tokens = state.queue
scores[next_tokens[0].i] = state.scores
state.transition(action)
You'll want to apply a softmax transformation over the raw scores so you can work with them as probabilities.
Several details of the model design make the scores not very useful, though:
- The model is trained on 0/1 loss, so it wasn't trained to be well calibrated
- The feature set is sparse and redundant, leading to peaky scores
- The model is trained using an imitation-learning paradigm and greedy decoding. The model has seen errors during training and is supposed to "know what to do" if previous decisions were incorrect.
The last point is probably the most significant. The model goes over the sentence and makes its predictions. At each word, it's only looking two words forward. This means it often has no access to information that tells it its decision is wrong. When that information comes in, its decision has been made --- and the model will condition on its previous actions. This is true both during training and testing.
Basically: everything about the design of the model is geared towards getting out the best 1-best sequence. If you need ambiguity, there's a beam-search implementation in the beam branch that you might want to look at. If you can get that running, you'll have much better luck getting alternative analyses.
 honnibal
on 17 Feb 2017
honnibal
on 17 Feb 2017
Follow #881 for progress on this.
honnibal
on 10 Mar 2017
Thank you.
faizan30
on 27 Mar 2017
The code above seems bit out-of-date
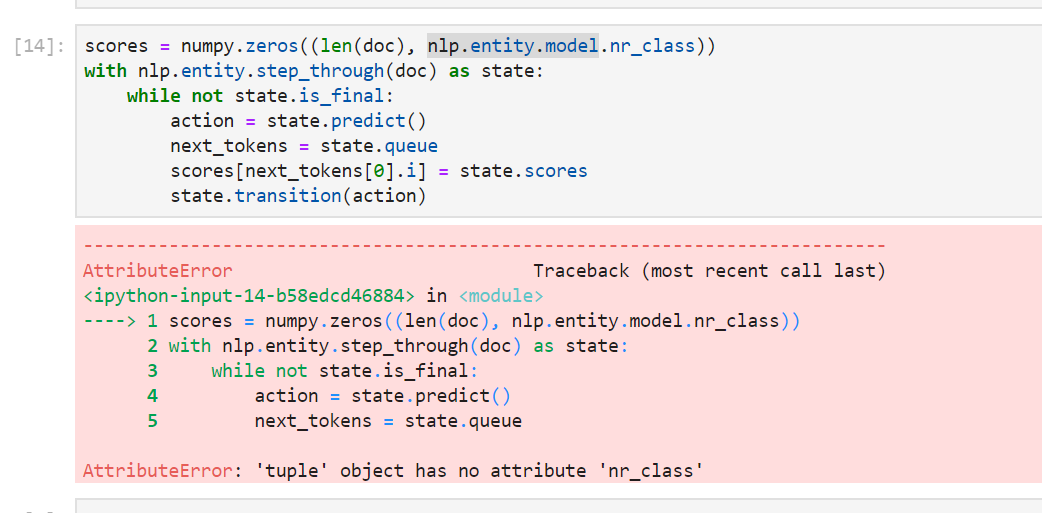
nlp.entity.model returns a tuple for me:
(
I imagine one of these used to be returned earlier.
Also none of these 3 has a method/attribute for nr_class
 rbhambriiit
on 19 Nov 2018
rbhambriiit
on 19 Nov 2018
Merging with the more recent thread https://github.com/explosion/spaCy/issues/5917
 svlandeg
on 10 Dec 2020
svlandeg
on 10 Dec 2020
Related issues
 smartinsightsfromdata
·
3Comments
smartinsightsfromdata
·
3Comments
 TropComplique
·
3Comments
TropComplique
·
3Comments
 bebelbop
·
3Comments
bebelbop
·
3Comments
 peterroelants
·
3Comments
peterroelants
·
3Comments
 ines
·
3Comments
ines
·
3Comments
Most helpful comment
The code above seems bit out-of-date
nlp.entity.model returns a tuple for me:,
,
)
(
I imagine one of these used to be returned earlier.
Also none of these 3 has a method/attribute for nr_class