Site-kit-wp: Replace isDoingGet* selectors with relying on resolvers
Feature Description
We currently have several selectors in our datastores specifically to check whether an API call for a selector is in progress (these are always called isDoingGet*). This seems somewhat unnecessary since every datastore exposes selectors like isResolving( selectorName ), via Gutenberg core.
We should consider getting rid of all isDoingGet* selectors and instead rely on these built-in isResolving selectors, which is more applicable. The trade-off is that we would in a few more tests need to add calls to mark a resolver as completed (specifically Jest component tests). In the more dynamic cases like Storybook this should be covered by the logic we already have in our resolvers to not run the query if there already is data, but for Jest the resolvers need to be manually marked as finished.
We could think about removing all the boilerplate code to always check for data already being there in the resolver and instead become strict about requiring calls to finishResolution for pretty much every receiveGet* call - this would be a bit more consistent, but would actually make setting up test stores a lot more tedious, unless we combined this somehow. Potentially, createFetchStore could expose a receiveAndResolveGet*( response, args ), which calls receiveGet* with response and argsToParams( ...args ) and finishResolution( slug, args )? This may be overkill, but worth discussing.
See https://github.com/google/site-kit-wp/pull/1388#discussion_r436806064 for some context on where this came up.
_Do not alter or remove anything below. The following sections will be managed by moderators only._
Acceptance criteria
- Whenever a
receiveGet*action associated with a selector/resolver is called manually in the codebase (mostly in tests and Storybook, although there are a few cases in production code, such as in themodules/analyticsstore), the respective selector should also be marked as completed (via built-in actionfinishResolution( selectorName, args )).
- This applies to almost all
receiveGet*calls within tests and Storybook, although there are a few which require slightly different changes since the resolver does more than just run that single API request. The few production code cases likely require more specific inspection since they are special cases. For example, the AnalyticsgetAccountsresolver should of course not mark itself as finished after callingreceiveGetAccounts, since there is more logic to run first, and at the end it will be marked as finished anyway.
- This applies to almost all
- In parallel to the above, all our resolvers should be updated to no longer check in the beginning if the data the resolver exists for is already set. Per the above, we should rely on explicitly marking selectors as resolved instead, so all of these somewhat double checks are no longer necessary.
- All usages of
isDoingGet*should be migrated to using the built-inisResolvingselectors. - All
isDoingGet*selectors should be removed. Other store utilities that purely exist for theisDoingGet*selectors, such as theisAwaiting*Completionlogic in themodules/analyticsstore, should be removed as well.
Implementation Brief
- Rename older selector names to be in-line with our new
receiveGet*approach and convert them like otherreceiveGet*selectors/resolvers:
receiveIsAdBlockerActiveshould be renamedreceiveGetIsAdBlockerActivereceiveSiteInfoshould be renamedreceiveGetSiteInfo- Worth checking for others with the regex
/receive[^Get][A-Za-z]*\(/in the code base, as they likely warrant conversion as well.
- Note the instances in production code https://github.com/google/site-kit-wp/blob/develop/assets/js/modules/analytics/datastore/accounts.js#L225-L244 where we explicitly call
receiveGet*actions for other selectors. ThegetProfilesandgetPropertiesselectors should be marked as resolved whengetAccounts()is run, likewisegetProfiles()should be marked as resolved whengetProperties()is called. - Update all instances of
receiveGet*(...args)to also callfinishResolution(selectorName, [...args]). Most of these will be in tests/storybooks. It's possible there is a handy abstraction to write here, but no worries if not. - Update all resolvers to stop checking for
undefineddata like so: https://github.com/google/site-kit-wp/blob/develop/assets/js/modules/analytics/datastore/accounts.js#L210. There are too many of these checks to exhaustively list, so please look through all resolvers and remove said checks. It would be worthwhile to add tests for resolvers to ensure they are run even when theinitialStatefor those previously-checked values (in this cause,accountsis notundefined. - Convert all instances of
isDoingGet*to instead rely onisResolving(selectorName, [...selectorArgs]),. An example of one such call is here: `https://github.com/google/site-kit-wp/blob/develop/assets/js/modules/analytics/components/common/AccountCreateLegacy.js#L40, but understand that there are too many to exhaustively list here. - Remove all
isDoingGet*selectors and tests. It might be worth doing this first, to find all instances that need to be updated to theisResolvingselector. But that's up to whomever codes this 🙂 - Remove all
isAwaiting*Completelogic, found in:
assets/js/googlesitekit/modules/datastore/modules.jsassets/js/modules/adsense/components/setup/SetupMain.jsassets/js/modules/analytics/datastore/accounts.jsassets/js/modules/analytics/datastore/properties.js
QA Brief
- Unfortunately this touches nearly all surface area of the app; any components using our new data store (eg. everything at least in part) will be affected by this change. So best bet is to watch for usual issues in release testing and call them out—if it's to do with data loading or refreshing regressions/changes, this issue is likely the cause.
- Of particular note are the setup and editing screens for each module (especially Analytics, AdSense, and Tag Manager as they're more complex). They are the main places these changes will impact the most so worth looking out for any abnormalities in behaviour, especially around initial/loading states.
Changelog entry
 felixarntz
felixarntz
All 19 comments
On the subject on relying on the built-in module resolution status to indicate that a fetch action is complete I'm… suspect. It sounds like a good idea, and I like the reduction in code, but given createFetchStore is already what creates it with no developer input, why not separate out the entire selector's resolution from each fetch action? Fetching might be one part of a resolver's resolution: take a multi-fetch resolver that gets some data, then some other unrelated data, for instance. It's also a more natural selector to write than the hasFinishedResolution one.
That said, I think _all_ or nearly all of our calls to isDoing* are internal. If that's the case and it's largely about tests, then I think that's fine. It reduces extra code/complexity… and we might as well not support something we aren't using. 🤷♂️
But there's value in knowing if a fetch action is currently taking place, and I don't see the isDoingFetch selectors as being too much to maintain or adding much complexity.
We could think about removing all the boilerplate code to always check for data already being there in the resolver and instead become strict about requiring calls to
finishResolutionfor pretty much everyreceiveGetcall.
I'm not quite sure what this bit means. WordPress data is what sets the hasFinishedResolution flag, so we shouldn't be calling that in our own code, preferably. But if our code doesn't make the fetch request if the data is already there, the resolver can still continue on and be marked as resolved once the generator function completes.
Basically: I don't think we need to do this, because the creation of these selectors is automated and it's useful to separate out an entire resolver from a fetch action. Plus: calling isDoingTYPOFetch() if it doesn't exist will error, but I'm not sure about hasFinishedResolution('TYPEFetch').
 tofumatt
on 12 Jun 2020
tofumatt
on 12 Jun 2020
why not separate out the entire selector's resolution from each fetch action? Fetching might be one part of a resolver's resolution: take a multi-fetch resolver that gets some data, then some other unrelated data, for instance. It's also a more natural selector to write than the
hasFinishedResolutionone.
Fetching potentially only being _a part_ of the resolver is actually another reason we can avoid the isDoingGet* selectors. Note that they are not the same as the isFetching* selectors - the latter are auto-generated and apply specifically to the fetch call, the first are manually added, and we've been probably slightly inconsistent there whether we make this about the resolver being resolved or the fetch call being completed (in most cases, for us it means the same, that's why we haven't thought about it before).
We should definitely continue to auto-generate the isFetching* selectors. Those should be used if that fetch request is what we need to check for. However if we need to check the resolver (which is what we _actually_ want in most such areas in our codebase), we don't need an extra isDoingGet* selector, we can rely on the built-in isResolving.
But there's value in knowing if a fetch action is currently taking place, and I don't see the
isDoingFetchselectors as being too much to maintain or adding much complexity.
This is what we have the isFetching* selectors for :) isDoingGet* is usually just a wrapper for that, with sometimes some modifications.
We could think about removing all the boilerplate code to always check for data already being there in the resolver and instead become strict about requiring calls to
finishResolutionfor pretty much everyreceiveGetcall.I'm not quite sure what this bit means. WordPress data is what sets the
hasFinishedResolutionflag, so we shouldn't be calling that in our own code, preferably. But if our code doesn't make the fetch request if the data is already there, the resolver can still continue on and be marked as resolved once the generator function completes.
This comment was mostly about our tests, specifically Jest component tests. We're currently setting datastore data there via receiveGet*, but we don't mark the respective selectors as resolved. This is currently fine since we always have extra logic in the resolver to not issue a request if the data is already there. I haven't been a fan of this since it seems kind of a patch just to make our tests work - if we marked the selectors as resolved in the applicable places, we wouldn't need this extra code in all our resolvers.
felixarntz
on 12 Jun 2020
Oh, gosh, right. Fair point then—I clearly got the two selectors confused, which is really another reason we should ditch them. I forgot we had those separate to the isFetching ones. 😅
Also: marking the selectors as resolved in tests over using the "check for existing data" hack is definitely a 👍 from me. It's more idiomatic to how WP Data works and I think is probably less error-prone and manually as well. It's more work, but then it's also more accurate and descriptive, and that's fine for tests.
So actually, yeah, I'm on-board 😆
I think what we'd want here as an AC is to no longer have tests that supply data but don't mark a resolver as "finished" to fail, and then to dispatch, manually, the "finishResolution" action in tests where we don't want a request/to mock fetch. Sometimes I wonder if we should just be mocking fetch all of the time, but that could be a later thing and I do realise it's a fair bit more verbose.
So remove the "has data" checks in the tests, ensure they fail, then add finishResolution actions to tests that are using receive*. Then remove the isDoing* actions entirely. As I think we only use them internally/for tests there shouldn't be too much code to change, and they can rely on hasFinishedResolution() instead.
I think that covers it. 🤔
tofumatt
on 12 Jun 2020
I've added my suggested ACs for that based on what you said above; lmk what you think - I believe there's value in simplifying this common pattern of calling receiveGet* and also marking resolution as finished, so I'm suggesting to enhance createFetchStore.
With the ACs, code would basically turn from
dispatch.receiveGetClients( clients, { accountID } );
dispatch.finishResolution( 'getClients', [ accountID ] );
into
dispatch.resolveGetClients( clients, [ accountID ] );
I started to look at the IB for this and while the _concept_ is straightforward, there's an issue with using isResolving with our dynamically-created selectors and our selectors that rely on other (resolver-based) selectors.
If we are converting a selector like https://github.com/google/site-kit-wp/blob/e4539d97a47fee9a21e6ef29e1a6bdd4d86d5379/assets/js/modules/tagmanager/datastore/accounts.js#L188, it's a straightforward change:
const isDoingGetAccounts = useSelect( ( select ) => select( STORE_NAME ).isDoingGetAccounts() );
becomes:
const isDoingGetAccounts = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getAccountID' ) );
and we get to remove the isDoingGetAccounts selector. Nice!
Metaprogramming problems
But this won't work with selectors that rely on other ones without bubbling up implementation details. Consider something like:
const accountID = useSelect( ( select ) => select( STORE_NAME ).getAccountID() );
Intuitively, I'd expect to be able to use:
const accountID = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getAccountID' ) );
with this new system. But that won't work; you'd need to know that accountID is a setting and the getAccountID is a dynamically-created selector and know to call:
const accountID = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getSettings' ) );
I find this all a bit confusing, and wonder if us not explicitly defining these isDoingX selectors obscures things or forces us to bubble-up implementations of the datastore to the components.
Looking at the effort involved in this ticket for the minimal code reduction and clarification we'd gain from it, I'm inclined to say we either close this for now or at least put it on the backburner. I agree that there are benefits to the revised approach, but I think they're very marginal and we could direct our efforts elsewhere more efficiently. Thoughts @aaemnnosttv @felixarntz?
tofumatt
on 16 Jul 2020
@tofumatt Hmm I'm not sure I follow your argumentation.
If we are converting a selector like
, it's a straightforward change:
const isDoingGetAccounts = useSelect( ( select ) => select( STORE_NAME ).isDoingGetAccounts() );becomes:
const isDoingGetAccounts = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getAccountID' ) );
Note this would be
const isDoingGetAccounts = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getAccounts' ) );
instead - that's not really the point of this discussion, just wanted to avoid confusion.
But that won't work; you'd need to know that
accountIDis a setting and thegetAccountIDis a dynamically-created selector and know to call:const accountID = useSelect( ( select ) => select( STORE_NAME ).isResolving( 'getSettings' ) );I find this all a bit confusing, and wonder if us not explicitly defining these
isDoingXselectors obscures things or forces us to bubble-up implementations of the datastore to the components.
I see it's a somewhat undesirable complexity having to know whether a selector relies on another selector in order to know what resolver to check for. However, that isn't really different from the existing isDoingGet* selectors. Right now if we want to check whether the data for getAccountID is being loaded, we'll also need to know that: There is no isDoingGetAccountID because this is a generated selector and the underlying one we _would_ need to check is isDoingGetSettings, for settings in general. So I don't think what you're describing is in any way better or worse compared to what we have today.
felixarntz
on 16 Jul 2020
Oops, sorry for the difference in selector args!
The isDoingGet selectors are at least manually searchable in the codebase. I think relying on the isResolving further obscures the code path when looking through the code base. My concern is that we start to get a bit too clever with our metaprogramming and make it difficult to grep through the codebase to find where code lives. This is already the case for getFooBar() type selectors, where I need to know to search the code for 'fooBar' as a setting to find that selector's code.
I'm a bit concerned by how much we're obscuring more code behind code that isn't widely known for relatively little benefit and a lot of engineering effort is all I'm really getting at.
tofumatt
on 16 Jul 2020
It seems this issue has shifted a bit from replacing our isDoingGet selectors with core isResolving selectors to being more specific to createFetchStore and manually marking resolvers as completed, although I don't think we're suggesting that the fetch actions resolve the selector by default, it should still manually be called only when needed.
There are definitely cases where marking a resolver completed makes sense from a receive action or another resolver (e.g. Analytics' getAccounts resolver should fulfill getProperties and getProfiles since it receives all of them in the same request).
It would also be nice to be able to remove all the checks for existing data in most resolvers. In order to do that, we need to manually mark them as resolved, mostly in tests but there are those few cases where it makes sense to mark them resolved in source code as well.
I'm not sure this issue is quite as large as it may seem. Outside of tests, we use very few isDoingGet selectors as it is
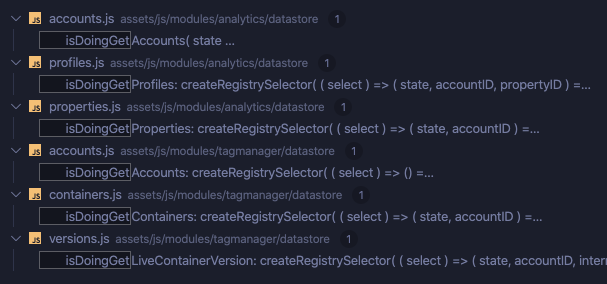
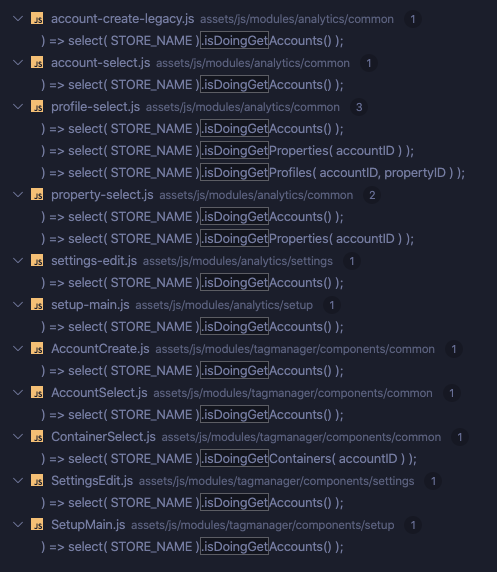
isDoingGet* selectors and use screenshots
Selector definitions
Selector use in source
Selector use in tests
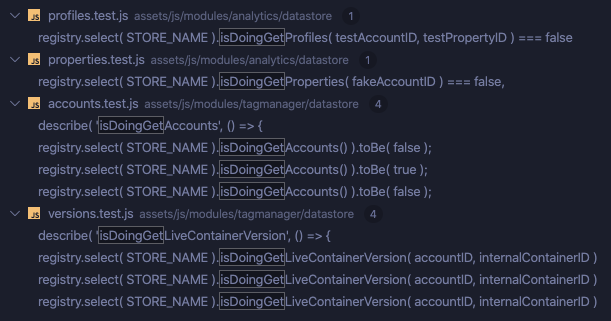
It's worth noting that several of these checks are actually unnecessary since we need to also check if the selector is specifically resolved because this will return false before the resolution even starts. E.g. https://github.com/google/site-kit-wp/blob/20f826af64092da7633d94ead7d23a75667762a7/assets/js/modules/analytics/setup/setup-main.js#L81-L83
There may be other cases where we should be doing similar checks and are not so it could be that most of them are really unneeded.
Many of these are also simply wrappers for isFetchingGet* selectors so it's possible we can refactor with those where still needed.
The main benefit here seems to be a significant reduction of code and less options to confuse use with ("should I use isDoingGet or isFetchingGet?) which is a worthwhile win. The latter is a bit of a tradeoff though as now there may be confusion about what action should be used to receive ("should I use receiveGet* or resolveGet*?").
So maybe this issue isn't as big as it seems? We should actively shed any code that we don't use or need to avoid passively letting the codebase grow because it's easier to add things than to remove/refactor so this seems like more of a chore+enhancement that probably isn't a top priority but seems worth doing to me.
Regarding the AC, I would prefer less magic regarding the resolver that the resolve action is for.
Why not just define the selector and resolver as part of the fetch store and then it would know if there was a resolver or not? If we no longer need to check if there's data first in the resolver, then the fetch store could have a default resolver which only yields the fetch action (an alternate function could be passed). Then it would make more sense for the store to also produce a resolve action because the store would be aware of the selector and resolver. I know we originally thought to keep the selector separate for documentation purposes (and also possibly due to the limitations around resolvers that we're discussing now) but I think the selector could still be just as documentable using the fetch store. It would also co-locate all of the pieces rather than split some at the top and the rest at the bottom. We could always do something like this:
// selectors...
/**
* Docs...
*/
getAccounts: fetchGetAccountsStore.fetchSelector
In retrospect, this would error in combineStores - this would be easy to solve though if we updated the combine* utils to not error on equal duplicates.
One other quick thought regarding the resolve action is that it would be cleaner I think to use resolveGet*( response, ...args ) rather than an array, that way we only ever call an action with params, or a list of args; passing as an array is unnecessary and a bit confusing IMO.
 aaemnnosttv
on 17 Jul 2020
aaemnnosttv
on 17 Jul 2020
@aaemnnosttv
It seems this issue has shifted a bit from replacing our
isDoingGetselectors with coreisResolvingselectors to being more specific tocreateFetchStoreand manually marking resolvers as completed, although I don't think we're suggesting that the fetch actions resolve the selector by default, it should still manually be called only when needed.
Yes, a fetch action should definitely not resolve by default.
I think we should circle back towards the original goal here actually, i.e. not modify createFetchStore. The point you've made that the resolver should be part of it if it returns resolve* action makes sense, but I'd rather not have us go that path. A consideration here for example is that the selector arguments may not be the same as the arguments passed to the fetch call, in which case we'd kind of need two different argsToParams (or at least another validation function to handle actual selector/resolver arguments), and it would become quite messy.
It would also be nice to be able to remove all the checks for existing data in most resolvers. In order to do that, we need to manually mark them as resolved, mostly in tests but there are those few cases where it makes sense to mark them resolved in source code as well.
Yes, this is somewhat double logic we currently have. We should be relying on resolvers and their built-in functionality to know whether we need to make an API request. The current code where we always check for data is merely a patch over that we don't properly mark selectors as resolved like we should.
@tofumatt
The
isDoingGetselectors are at least manually searchable in the codebase. I think relying on theisResolvingfurther obscures the code path when looking through the code base.
I'm not sure I see the value in this though. Technically isDoingGet should be doing the same as isResolving. And while I agree it's more intuitive to have clear selector names (isDoingGetAccounts() vs isResolving( 'getAccounts' )), they're still both based on the selector name, which you should be aware of either way when working on such code. To me the more confusing part is that we have those isDoingGet selectors while there is a built-in functionality that does the same, even more so because we're already using those built-in tools in other places (e.g. invalidateResolutionForStoreSelector).
I think we should update the ACs as follows:
- Whenever a
receiveGet*action associated with a selector/resolver is called manually in the codebase (mostly in tests and Storybook, although there are a few cases in production code, such as in themodules/analyticsstore), the respective selector should also be marked as completed (via built-in actionfinishResolution( selectorName, args )).
- This applies to almost all
receiveGet*calls within tests and Storybook, although there are a few which require slightly different changes since the resolver does more than just run that single API request. The few production code cases likely require more specific inspection since they are special cases. For example, the AnalyticsgetAccountsresolver should of course not mark itself as finished after callingreceiveGetAccounts, since there is more logic to run first, and at the end it will be marked as finished anyway.
- This applies to almost all
- In parallel to the above, all our resolvers should be updated to no longer check in the beginning if the data the resolver exists for is already set. Per the above, we should rely on explicitly marking selectors as resolved instead, so all of these somewhat double checks are no longer necessary.
- All usages of
isDoingGet*should be migrated to using the built-inisResolvingselectors. - All
isDoingGet*selectors should be removed. Other store utilities that purely exist for theisDoingGet*selectors, such as theisAwaiting*Completionlogic in themodules/analyticsstore, should be removed as well.
I think we should split this work into multiple PRs. For example, the last two bullet points should be decoupled from the first two bullet points. And since the first two bullet points will just touch a ton of (test and Storybook) code, we may want to separate those further (just to reduce the chance for merge conflicts). The estimate overall would probably remain between 19 and 30, with the vast majority of that time being spent on the first two bullet points (simply since it's touching a ton of code).
felixarntz
on 20 Jul 2020
@felixarntz, @tofumatt
Whenever a
receiveGet*action associated with a selector/resolver is called manually in the codebase (mostly in tests and Storybook, although there are a few cases in production code, such as in themodules/analyticsstore), the respective selector should also be marked as completed (via built-in actionfinishResolution( selectorName, args )).
I don't think we should add an additional line to dispatch a finishResolution for all selectors that have a resolver sounds rather extreme and would be a huge addition across all our tests (component, unit/jest, as well as storybook).
Looking at some resolvers in core, most don't have these guards, but some do (e.g. https://github.com/WordPress/gutenberg/blob/master/packages/block-directory/src/store/resolvers.js, https://github.com/WordPress/gutenberg/blob/c6ded94fdf5dabd6afc8dc9a007bfc78ab1d626e/packages/core-data/src/resolvers.js#L54-L64). It is however _even more uncommon_ to see a resolver manually marked as resolved, although this is done where one resolver seems to fulfill another (which is our main use-case for this as well).
If reducing this boilerplate is part of the intention, we could have a higher-order function for resolvers, something like createConditionalResolver which would only call the given resolver function if the selector by the same name+args returned undefined
function createConditionalResolver( storeName, selectorName, resolver ) {
return *function conditionalResolver( ...args ) {
const { select } = yield Data.commonActions.getRegistry();
if ( select( storeName )[ selectorName ]( ...args ) === undefined ) {
yield resolver( ...args );
}
}
}
Then in a store we would use it like so:
const resolvers = {
/* Note: arrow functions can't be generators :..( */
getData: createConditionalResolver( STORE_NAME, 'getData', function* ( foo, bar ) {
const data = yield actions.fetchData( foo, bar, { something: 'else maybe' } );
yield actions.receiveThatData( data );
} ),
};
const selectors = {
getData( state, foo, bar ) {
return state[ `${ foo }::${ bar }` ];
},
};
I realize this isn't the main point of the issue but I think that the above would be preferrable over the alternative.
Manually marking resolvers as finished when we receive them manually would still trigger actions to flow through the reducer which seems to be something we're trying to avoid here, although I don't think that's necessary (or at least worth the cost).
There shouldn't be a case where a resolver is triggered and immediately finished (because it has nothing to do) where the UI would be affected in any way, even if it were selecting for isResolving for the same selector/resolver.
This is worth testing just to be sure, but it should happen so fast that it wouldn't matter.
aaemnnosttv
on 7 Aug 2020
@aaemnnosttv Hmm I am still not convinced about _not_ marking resolvers as finished. I agree it is a massive addition to our tests and Storybook, and it'd be great to find a way to make that more concise (e.g. something like the receiveAndResolveGet* or something like that action). Yet, I don't think because this adds a lot of code (only to tests and Storybook, to emphasize that - in production code it's only very very few instances) we shouldn't do it.
Without marking resolvers as finished in these instances, we essentially cause an unexpected state. The functions to check for resolver state exist for a reason and we're using them in several places (and we should use them over our custom isDoingGet*, which is what this is mostly about). Not marking resolvers as finished when they should be makes this code error-prone and likely behave in weird ways.
The approach of a conditional resolver is a great idea if were keeping the current behavior of the resolvers, but I think that is the underlying problem here. Simplifying the boilerplate for a resolver makes sense, but we shouldn't actually need these checks for existing data at all if we were taking care of resolvers' state properly when providing that data manually.
felixarntz
on 7 Aug 2020
IB is ready for review, sorry for the delay on this one, but #1888 had us a bit side-tracked.
tofumatt
on 7 Aug 2020
@tofumatt
Note the instances in production code https://github.com/google/site-kit-wp/blob/develop/assets/js/modules/analytics/datastore/accounts.js#L225-L244 where we explicitly call
receiveGet*actions. In fact, it should be safe to allowgetAccountsto be resolved here because the next calls togetProfilesandgetPropertieswill still run in the resolver.
I'm not sure I understand this bit: This resolver for getAccounts shouldn't resolve getAccounts manually (of course it will do that automatically once gone through) - it should instead mark the resolver for the respective getProperties( accountID ) resolver and getProfiles( accountID, propertyID ) resolver as finished because it's essentially those two resolvers' tasks that it covers. Similarly, the getProperties resolver (which has the same "cascading-down" approach) should mark the resolver for getProfiles( accountID, propertyID ) as finished.
Update all instances of
receiveGet*(...args) to also callfinishResolution(selectorName, [...args]). Most of these will be in tests/storybooks. It's possible there is a handy abstraction to write here, but no worries if not.
Worth adding a note here that there are a few other receive* actions currently (somewhat inconsistently) _not_ called receiveGet* although they are also for selectors (e.g. receiveSiteInfo for getSiteInfo should be receiveGetSiteInfo). Preferably these actions should be renamed and wherever they are called, the selector resolver should also be marked as finished.
The rest of the IB looks good to me.
Regarding the QA brief, I think there's still a few areas to highlight here. Generally yes, this should be merged early in a release cycle so that there's naturally more time for testing. But still I'd argue the biggest surface areas from these changes are the different module setup screens and editing module settings, so this could be mentioned. Particularly Analytics, AdSense, and Tag Manager, which are more complex, should be tested in depth.
felixarntz
on 11 Aug 2020
Argh, you're right. I mixed up the order when I wrote it down, sorry about that! IB amended to make more sense of the "cascading" getAccounts and getProperties resolvers.
tofumatt
on 12 Aug 2020
IB ✅
felixarntz
on 12 Aug 2020
@aaemnnosttv @tofumatt For reference, here is one example for why we should also mark all resolvers as finished when passing data to them, passing "success" data is not the only way for those to resolve: https://github.com/google/site-kit-wp/pull/1864/commits/a48fc295a4d0f867399e45d76322594aa2c8851b#diff-f21ee1328fdda1025c0d89e270318048R119-R122
felixarntz
on 15 Aug 2020
There's still a reason to do this task, but I think its priority is very low. Given the amount of time this will take, it's not worth doing at this point. It's not really part of the component refactoring epic, so I removed that one from here.
We already improved a few related areas via #1995 and #2436. Most work in here involves updating Storybook stories, so the impact on production code would be fairly small anyway. Let's keep this open, but not do it for now.
felixarntz
on 7 Dec 2020
Hey folks, I have been working (trying at least) on this issue. And I can't really understand the following from the IB
Update all resolvers to stop checking for undefined data like so: https://github.com/google/site-kit-wp/blob/develop/assets/js/modules/analytics/datastore/accounts.js#L210. There are too many of these checks to exhaustively list, so please look through all resolvers and remove said checks. It would be worthwhile to add tests for resolvers to ensure they are run even when the initialState for those previously-checked values (in this cause, accounts is not undefined.
According to this, the undefined check must be removed from the resolvers. If I do this, then quite some tests are failing.
For example,
https://github.com/google/site-kit-wp/blob/8dc8de99f9225f62972c2bb82f67f6e3d39651ad/assets/js/modules/analytics/datastore/properties.test.js#L55-L73
This properties test first creates the property using the createProperty action and then tries selecting the property later on via getProperty.
If the falsy check condition is removed from the resolver then the selector (getProperty) from the test will call the getProperty resolver (selector being called for the first time, acc to @wordpress/data's resolvers) which will send a GET request to the API. The GET request will make the test fail as the test is not expecting a GET request.
https://github.com/google/site-kit-wp/blob/8dc8de99f9225f62972c2bb82f67f6e3d39651ad/assets/js/modules/analytics/datastore/properties.js#L292
There are other instances like this. Acc to me, an abstraction will be great in the cases when we want to resolve only when state is falsy but unfortunately I can't think of a good approach. Any inputs are appreciated 😄
 sudhanshu16
on 30 Dec 2020
sudhanshu16
on 30 Dec 2020
Let's close this - I think it's not worth investing all the time and risk for breakage for the small benefits. We've already improved a lot here via relying more on hasFinishedResolution, I think that's sufficient.
felixarntz
on 7 Jan 2021
Related issues
 quangbahoa
·
5Comments
felixarntz
·
4Comments
quangbahoa
·
5Comments
felixarntz
·
4Comments
 theeducatedbarfly
·
4Comments
theeducatedbarfly
·
4Comments
 jsmshay
·
3Comments
aaemnnosttv
·
5Comments
jsmshay
·
3Comments
aaemnnosttv
·
5Comments
Most helpful comment
There's still a reason to do this task, but I think its priority is very low. Given the amount of time this will take, it's not worth doing at this point. It's not really part of the component refactoring epic, so I removed that one from here.
We already improved a few related areas via #1995 and #2436. Most work in here involves updating Storybook stories, so the impact on production code would be fairly small anyway. Let's keep this open, but not do it for now.