Sickchill: Another issue with cfscrape and the location key error
Issue stems from #2206 - creating a separate issue to track it. It was originally opened back in 2016 and quickly closed - but it is making a rather large comeback. I made a comment on that post, but i forgot how quickly things get buried there... Here is my comment again:
I did a bit of investigating and tracebacks... This is... unsurprisingly... about cfscrape again...
We hit the line: https://github.com/SickChill/SickChill/blob/master/lib/cfscrape/__init__.py#L195
And when we are there, the redirect variable holds a 404, and therefore the location header is missing. One problem I have is that the traceback is kind of hidden when we hit the handlers.py it might be worth adding the full traceback instead of just the 2 lines from here:
2019-11-30 05:29:55 INFO SEARCHQUEUE-DAILY-SEARCH :: No needed episodes found
2019-11-30 05:29:54 WARNING SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: Unable to connect to provider
AA KeyError: 'location'
AA raise requests_exception
AA File "/app/sickrage/sickbeard/helpers.py", line 1527, in handle_requests_exception
AA KeyError: 'location'
AA raise requests_exception
AA File "/app/sickrage/sickbeard/helpers.py", line 1527, in handle_requests_exception
AA Traceback (most recent call last):
2019-11-30 05:29:54 ERROR SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: [2404f19] Request failed: 'location' ()
AA KeyError: 'location'
AA raise requests_exception
AA File "/app/sickrage/sickbeard/helpers.py", line 1527, in handle_requests_exception
AA KeyError: 'location'
AA raise requests_exception
AA File "/app/sickrage/sickbeard/helpers.py", line 1527, in handle_requests_exception
AA Traceback (most recent call last):
2019-11-30 05:29:50 ERROR SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: [2404f19] Request failed: 'location' ()
2019-11-30 05:29:44 INFO SEARCHQUEUE-DAILY-SEARCH :: Beginning daily search for new episodes
Will help how I can, but not sure what else to do.
 CodyWoolaver
CodyWoolaver
All 20 comments
Same location error here. I have been sending error logs to closed issue 2206 for a couple days. I am only seeing the error with IPTorrents this time.
 mitch71h
on 30 Nov 2019
mitch71h
on 30 Nov 2019
I created a bug report over at cfscrape, let's see what they can figure out. https://github.com/Anorov/cloudflare-scrape/issues/317
CodyWoolaver
on 1 Dec 2019
A fix has been found: https://github.com/Anorov/cloudflare-scrape/pull/315
We can wait for it to be merged into master of cfscrape, or I could upload a branch here with the fix already in play. Regardless, I will open a PR when it gets fully merged in. Let me know if the branch would be needed.
CodyWoolaver
on 2 Dec 2019
that works.. was able to use that updated __init__.py and solved the issue
 momoz
on 2 Dec 2019
momoz
on 2 Dec 2019
I tried applying that fix to https://github.com/SickChill/SickChill/blob/master/lib/cfscrape/__init__.py but SickChill crashes with an error saying it cant import etree from lxml. Does this mean we might need to update lmxl as well?
File "C:\SickRage\SickRage\lib\cfscrape\__init__.py", line 13, in <module>
from lxml import etree
ImportError: cannot import name etree
 ryangribble
on 8 Dec 2019
ryangribble
on 8 Dec 2019
Looks like they are adding it in for some reason as a dependency, not entirely sure why. But yes, if they submit this pr it will mean that we will need to include it in our libs... however with that comes additional problems, as it requires the system dependency of libxml2 - which might not be available on all systems / docker containers / etc.
Working with the PR author to remove this dependency :) Good catch @ryangribble
CodyWoolaver
on 8 Dec 2019
It looks like it was used to interpret/traverse the HTML (xml) structure more reliably than using regex.
My point was mostly in reference to @momoz who said they applied the fix and it works but when I tried to apply the fix I found it caused the error saying it couldn't import the new dependency, so wondering how @momoz actually managed to apply the change manually
ryangribble
on 8 Dec 2019
The pr has been updated since I originally posted that link.
This commit should work for you: https://github.com/Anorov/cloudflare-scrape/blob/9e2f91cfda80712232a763b3edac14c785cf1831/cfscrape/__init__.py
Edit: Also looks like it has been updated to remove the new import. Trying the latest might work again.
CodyWoolaver
on 9 Dec 2019
There is still an issue with cfscrape when the website has enabled the "I'm under attack"-mode.
Replacing the cfscrape module with cloudscraper fixes the issue for me.
- Install cloudscraper (https://github.com/VeNoMouS/cloudscraper) module to /opt/sickchill/lib
- Apply this patch to change to cloudscraper.
diff --git a/sickbeard/helpers.py b/sickbeard/helpers.py
index c22197550..57ba50fe2 100644
--- a/sickbeard/helpers.py
+++ b/sickbeard/helpers.py
@@ -48,6 +48,7 @@ import adba
import bencode
import certifi
import cfscrape
+import cloudscraper
import rarfile
import requests
import six
@@ -1375,7 +1376,7 @@ def touchFile(fname, atime=None):
def make_session():
- session = cfscrape.create_scraper()
+ session = cloudscraper.create_scraper()
session.headers.update({'User-Agent': USER_AGENT, 'Accept-Encoding': 'gzip,deflate'})
return CacheControl(sess=session, cache_etags=True)
 tobias-urdin
on 19 Dec 2019
tobias-urdin
on 19 Dec 2019
Thanks Tobias, I have a problem following your direction, as much as it is appreciated.
I have downloaded cloudscraper, and copied the source files from the release page of their github as you linked to c:\sickchill\sickchill\lib\cloudscraper-1.2.16 (after running the shutdown link from within sickchill), and ran the setup.py from the folder via cmd (python setup.py install) as per the instruction on their github page.
it seemed to run fine, but nothing was returned to the console.
I then went into sickbeard/helpers.py and made the changes via VSCode, added the import, changed the session line as per your diff report.
It now errors when starting the service, likely due to the changes I made, but I'm hoping you could help.
I am a software dev, but have very little pyton experience. Any help you could offer would be appreciated.
* side note * Sickchill gave me a message to update being 9 commits behind, which I did before attempting this but the existing problem remained. I have also tried a fresh install of sickchill, again not resolving the issue.
 beironjohn
on 20 Dec 2019
beironjohn
on 20 Dec 2019
Take the cloudscraper directory in the repo https://github.com/VeNoMouS/cloudscraper/tree/master/cloudscraper and place it in c:\sickchill\sickchill\lib
tobias-urdin
on 20 Dec 2019
Hi Tobias,
Thanks for the reply. I have copied the cloudscraper folder, however the service still doesn't start, same issue as before.
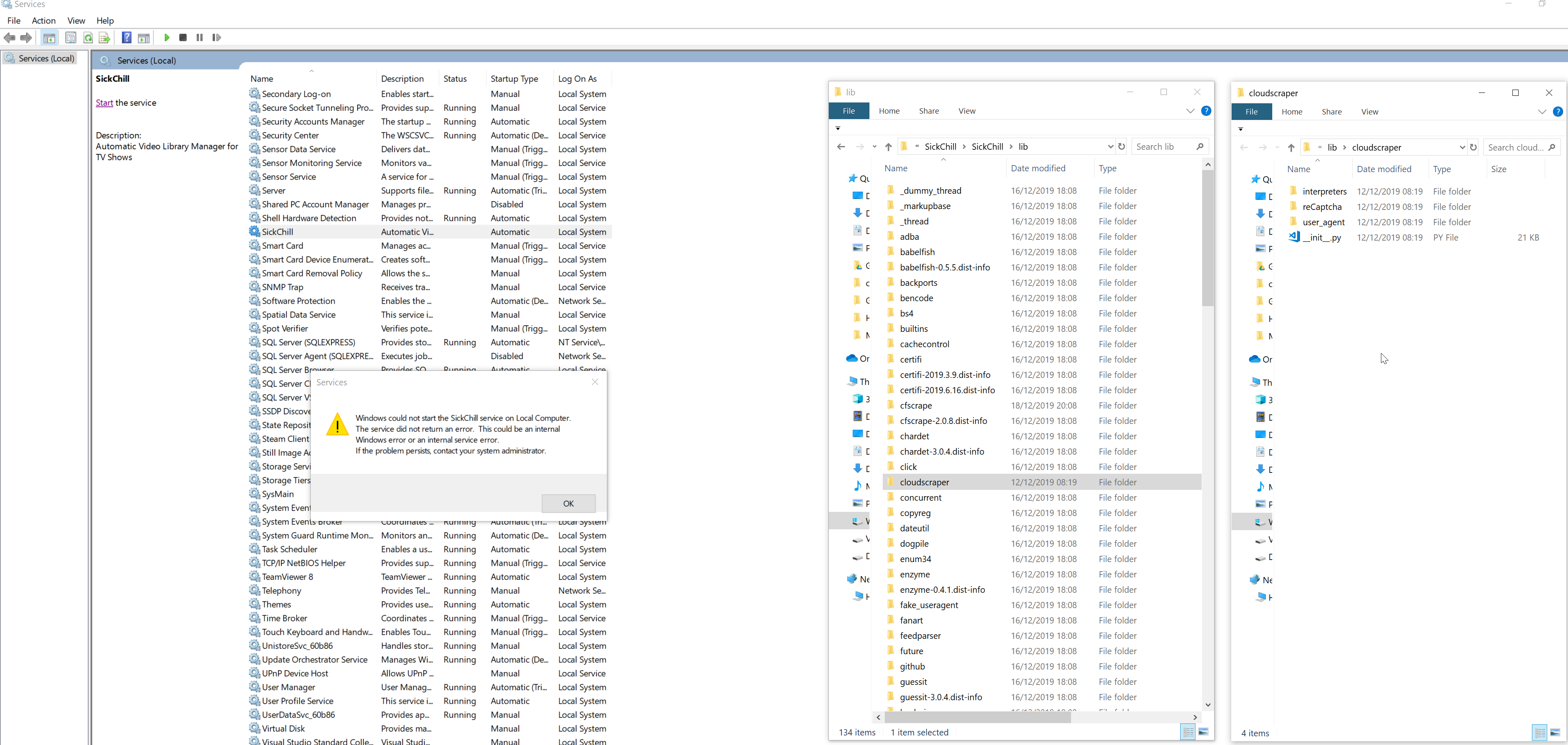
any ideas?
Thanks
Beiron
beironjohn
on 21 Dec 2019
Take the cloudscraper directory in the repo https://github.com/VeNoMouS/cloudscraper/tree/master/cloudscraper and place it in c:\sickchill\sickchill\lib
Hello Tobais,
I also tried your suggestion below but the issue remains.
C:\Users\Administrator>dir C:\SickChill\SickChill\lib\cloudscraper
Volume in drive C has no label.
Volume Serial Number is 82A5-C7BF
Directory of C:\SickChill\SickChill\lib\cloudscraper
12/24/2019 11:56 AM <DIR> .
12/24/2019 11:56 AM <DIR> ..
12/24/2019 11:56 AM <DIR> interpreters
12/24/2019 11:56 AM <DIR> reCaptcha
12/24/2019 11:56 AM <DIR> user_agent
12/12/2019 02:19 AM 21,102 __init__.py
1 File(s) 21,102 bytes
5 Dir(s) 465,756,647,424 bytes free
2019-12-24 12:22:55 WARNING SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: Unable to connect to provider
AA KeyError: 'location'
AA raise requests_exception
AA File "C:\SickChill\SickChill\sickbeard\helpers.py", line 1527, in handle_requests_exception
AA Traceback (most recent call last):
2019-12-24 12:22:55 ERROR SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: [2c72459] Request failed: 'location' ()
AA KeyError: 'location'
AA raise requests_exception
AA File "C:\SickChill\SickChill\sickbeard\helpers.py", line 1527, in handle_requests_exception
AA Traceback (most recent call last):
2019-12-24 12:22:51 ERROR SEARCHQUEUE-DAILY-SEARCH :: [IPTorrents] :: [2c72459] Request failed: 'location' ()
Any further ideas for us windows users?
 hooligeek
on 24 Dec 2019
hooligeek
on 24 Dec 2019
Any chance this fix is going to get pulled into the sickchill master branch?
 scottfreeze
on 1 Jan 2020
scottfreeze
on 1 Jan 2020
This isnt the fix, updating cfscrape is im pretty sure. we arent going to be using cloudscraper I think
 miigotu
on 8 Jan 2020
miigotu
on 8 Jan 2020
I can make a branch for this to be tested out I guess, im unsure of the non-python requirements of this chain though.
miigotu
on 8 Jan 2020
Looks like there is indeed a pending pull request for cfscrape that fixes this issue. Hopefully it will get addressed soon.
scottfreeze
on 8 Jan 2020
Yeah cloudscraper has a dependancy that is platform and architecturally dependant, so Im not sure we can use it until a pure python brotli is offered such as https://github.com/pothos/brotlipython
There was also some drama in the cfscrape vs cloudscraper leads and we didnt want to be a part of that, but we need to use what works if we can use it.
miigotu
on 8 Jan 2020
If any of you can, please try the cfscrape branch and let me know. Thanks
miigotu
on 8 Jan 2020
I cannot help test, I keep losing my iptorrents account due to inactivity lol
miigotu
on 8 Jan 2020
Related issues
 spiddeer
·
5Comments
spiddeer
·
5Comments
 SimonHova
·
3Comments
SimonHova
·
3Comments
 Hydrog3n
·
4Comments
Hydrog3n
·
4Comments
 mofman
·
4Comments
mofman
·
4Comments
 Raymoz101
·
4Comments
Raymoz101
·
4Comments