Shap: Questions about SHAP handling categorical variables
Hello,
I'm trying to use SHAP to provide ML model explanations for 3rd party customers.
There are two questions below about explanation results on categorical variables.
1) Suppose when I built the model, I applied one hot encoding on the categorical variable assume I don’t have many categories available, and then applied GBT.
The SHAP values I get is a list for [category_0, category_1, category_2 ……]
Should I take SUM or MAX among these values when I expose the explanation to customers?
2) Are there more elegant ways that SHAP can output a single shapley value for the categorical feature?
Consider that we can try other ways of doing string hashing, and we are looking to use both tree explainer and kernel explainer.
Appreciate your suggestions:)
Thanks,
Grace
 Grace-lambdaY
Grace-lambdaY
All 11 comments
Hey!
- You should use SUM (assuming you don't want to break it out by category). Because that will measure the total effect of all the categories, and so capture the impact of that feature before one-hot encoding.
- I think sum is already a very well motivated way of computing the Shapley values for the group. The nice thing about Shapley values additivity is that it makes sense to let the credit of a group be the sum of the credit assigned to each member. A less-obvious feature is also to tell KernelExplainer to treat a whole group of features as a single entity by using the
shap.common.DenseDataobject (which also makes the method faster). The only difference between summing up the credit of each feature and treating them all as a single "group feature" is that when credit for interaction effects is split evenly among the set of all participating features, the size of that set could change if you collapse some features to a single group.
 slundberg
on 19 Jan 2019
slundberg
on 19 Jan 2019
Using shap.common.DenseData and kernel explainer allowed me to do the work. However, is group shap baked in Tree Shap algorithm? I am building a XGBoost tree model. I would expect much speedup if Tree Shap supports feature groups.
 pancodia
on 16 Apr 2019
pancodia
on 16 Apr 2019
@pancodia I would recommend just summing up the SHAP values for the group to get the group attribution when using TreeExplainer. The main reason KernelExplainer can explicit support explicit grouping of features is because it can help make KernelExplainer faster.
slundberg
on 18 Apr 2019
Hey!
- You should use SUM (assuming you don't want to break it out by category). Because that will measure the total effect of all the categories, and so capture the impact of that feature before one-hot encoding.
- I think sum is already a very well motivated way of computing the Shapley values for the group. The nice thing about Shapley values additivity is that it makes sense to let the credit of a group be the sum of the credit assigned to each member. A less-obvious feature is also to tell KernelExplainer to treat a whole group of features as a single entity by using the
shap.common.DenseDataobject (which also makes the method faster). The only difference between summing up the credit of each feature and treating them all as a single "group feature" is that when credit for interaction effects is split evenly among the set of all participating features, the size of that set could change if you collapse some features to a single group.
Hey,
I have a question about converting one-hot to ordinal and applying Shap (I assume it is similar to using shap.common.DenseData) in KernelExplainer. I was expecting to have faster KernelExplainer using such a conversion (60 columns with one-hot vs 20 with ordinal conversion). However, I get a very similar speed. I am wondering why this is the case?
Thanks!
 XAI-360
on 26 Nov 2019
XAI-360
on 26 Nov 2019
That is because the number of samples used by KernelExplainer determines its runtime (because it determines how many times it needs to run the underlying model). When you reduce the number of features you make it easier for KernelExplainer to converge, but if you don't change the default nsamples = 2 * X.shape[1] + 2048 you won't get faster runtime (just better, lower variance estimates).
slundberg
on 27 Nov 2019
Thanks @slundberg
XAI-360
on 27 Nov 2019
That is because the number of samples used by KernelExplainer determines its runtime (because it determines how many times it needs to run the underlying model). When you reduce the number of features you make it easier for KernelExplainer to converge, but if you don't change the default
nsamples = 2 * X.shape[1] + 2048you won't get faster runtime (just better, lower variance estimates).
Hi @slundberg ,
Thanks for your helpful response above. However, how does this argument relate to your earlier comment: _A less-obvious feature is also to tell KernelExplainer to treat a whole group of features as a single entity by using the shap.common.DenseData object (which also makes the method faster)_? I didn't have time to read the code in detail but it did seem that grouping would result in different values for self.M in KernelExplainer, which in turn would influence the number of calls to the underlying model, since it used to compute nsamples if the latter is set to auto. So I should expect to see faster runtime by grouping the features. What are your thoughts with regards to the method accuracy when resorting to grouping as opposed to treating the individual dimensions independently and summing the contributions?
Thank you in advance.
 alexcoca
on 4 Feb 2020
alexcoca
on 4 Feb 2020
@alexcoca reducing the number of features makes sampling methods like KernelExplainer much easier. But the default nsamples = 2 * X.shape[1] + 2048 is dominated by the 2048 term when you have 60 or 20 features, so reducing M won't change how many samples are used by default (unless you get to the point where you can fully enumerate the space with 2**M samples. So grouping helps a lot, but if you don't then also reduce the number of samples you are using you will have spent all that value on getting lower variance estimates not on faster runtimes.
slundberg
on 4 Feb 2020
Hi @slundberg ,
Thanks for the reply, your explanation makes sense. So simply put, I should also change nsamples to some smaller value to see the benefits, with the trade-off that the variance of the shap values estimates will be higher.
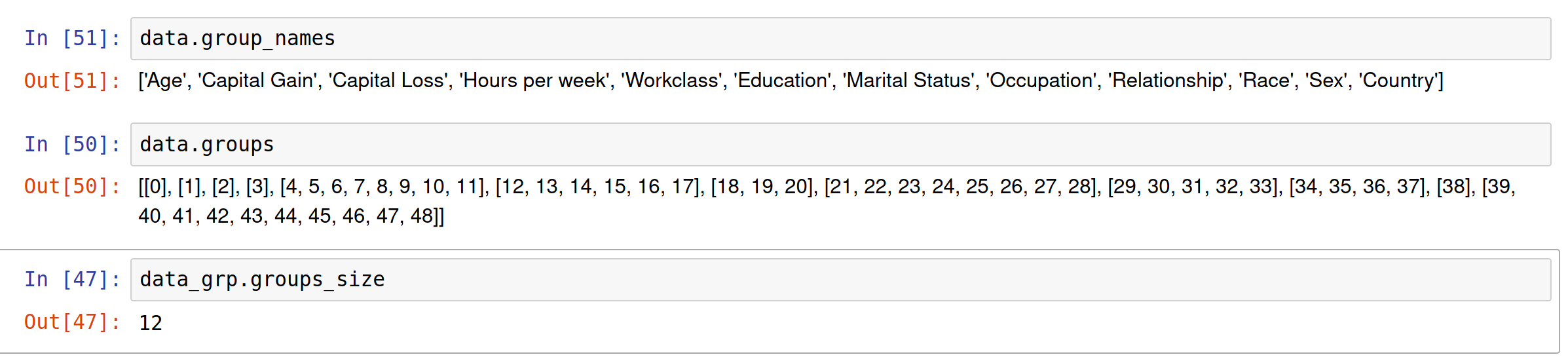
I have spent some time playing with the grouping now. I am not certain if the grouping will work correctly if the DenseData object is initialised with a sparse matrix (which is what we want if we have mostly categorical variables)? In fact, I passed a sparse matrix X to the DenseData object alongside group_names , a list with the feature names before encoding, and a groups list which contains sublists with column indices of each feature in X (see below). However, this does not seem to have done the trick. What happens in this case is that the call to self.varying_groups in L236 (kernel.py) returns self.varyingInds, which are column indices in X, as opposed to telling us which feature groups change (aka giving us indices in self.data.groups). As a result, the call in L241 fails. One could convert the output of self.varying_groups to be correct in this case (simple do a pass through the list of indices already returned and identify the group which it belongs to; groups not in this list do not 'vary'). However, I was wondering whether there is a reason why this is not supported at the minute ? Is there any way to both group features and use sparse representations?
Any thoughts on this? Ever so grateful for your support!
alexcoca
on 4 Feb 2020
Great questions! The short answer is that sparse matrix support was added later, and I don't think grouping was supported by the update. So it would be great if support was added but it is now there right now. This same issue will also impact our model-agnostic PartitionExplainer code so whatever we do here will impact that as well.
slundberg
on 6 Feb 2020
Hi @slundberg,
Thank you for the explanations and the insight on the topic.
I had a follow up question regarding: 'You should use SUM (assuming you don't want to break it out by category). Because that will measure the total effect of all the categories, and so capture the impact of that feature before one-hot encoding.'
If you add up the features in such a way, would that not favor features with higher number of categories over features with fewer categories. If you have two categorical variables that contribute the same to the model but one has 50 categories and the other is binary, by summing would it not seem like the 50 category variable is much more important (higher total shap value) than the binary variable?
 emilian84
on 10 Apr 2020
emilian84
on 10 Apr 2020
Related issues
 yolle103
·
3Comments
yolle103
·
3Comments
 gabrielcs
·
3Comments
gabrielcs
·
3Comments
 ArpitSisodia
·
3Comments
ArpitSisodia
·
3Comments
 samupino
·
3Comments
samupino
·
3Comments
 franciscorodriguez92
·
4Comments
franciscorodriguez92
·
4Comments
Most helpful comment
Hey!
shap.common.DenseDataobject (which also makes the method faster). The only difference between summing up the credit of each feature and treating them all as a single "group feature" is that when credit for interaction effects is split evenly among the set of all participating features, the size of that set could change if you collapse some features to a single group.