Sequelize: TimeoutError: ResourceRequest timed out
What you are doing?
Testing the connection to a postgres amazon rds instance
const sequelize = new Sequelize('dbname', 'username', 'password', {
host: 'example.rds.amazonaws.com',
dialect: 'postgres'
});
sequelize
.authenticate()
.then(() => {
console.log('Connection has been established successfully.');
})
.catch(err => {
console.error('Unable to connect to the database:', err);
});
What do you expect to happen?
App should connect and should output in console: "Connection has been established successfully"
What is actually happening?
Unable to connect to the database: { TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (\myapp\node_modules\generic-pool\lib\ResourceRequest.js:58:17)
at Timeout.bound (\myapp\node_modules\generic-pool\lib\ResourceRequest.js:8:15)
at ontimeout (timers.js:380:14)
at tryOnTimeout (timers.js:244:5)
at Timer.listOnTimeout (timers.js:214:5) name: 'TimeoutError' }
__Dialect:__ postgres
__Database version:__ 9.6
__Sequelize version:__ 4.2.1
 clutariomark
clutariomark
All 133 comments
I cannot reproduce the error. Obviously there was a timeout in connecting to the DB server, it doesn't look like a bug in Sequelize to me.
 felixfbecker
on 5 Jul 2017
felixfbecker
on 5 Jul 2017
Tried the same endpoint and other credentials using pg-promise, and I was successfully connected. Could you tell what db server you tried it on? Of course, the app connects to my local db.
clutariomark
on 5 Jul 2017
Own applications running on AWS that use Sequelize.
I am sorry, but even if you can connect with pg-promise, I have no way to find out why it wouldn't work with Sequelize without a repro.
felixfbecker
on 5 Jul 2017
please use this and try if you can reproduce the same error
postgres://testuser:[email protected]:5432/safepath
Already tried connecting to it using node-postgres and it worked, same error for sequelize though.
clutariomark
on 5 Jul 2017
I have the same exact issue!
 afituri
on 6 Jul 2017
afituri
on 6 Jul 2017

afituri
on 6 Jul 2017
Same issue here. The connection is established but when the connection of any connection is lost, the pool is getting smaller and after death of all threads application goes down. We had no troubles with this with 3+ version of Sequelize, so I guess it's not problem of db connection. Also tried downgrade from 4.2.1 (latest) to 4.1.0 and same problem.
 pavelkrcil
on 8 Jul 2017
pavelkrcil
on 8 Jul 2017
I have fixed the issue by maximizing the acquire option of pool configuration in sequelize
pool: {
max: 5,
min: 0,
idle: 20000,
acquire: 20000
}
I guess Amazon RDS runs a lot of checks when asking for resources.
Also I am running the Free Tier of Amazon RDS.
afituri
on 8 Jul 2017
I'm having the exact same issue! The above pool configuration did NOT work. In our production environment, in a 24h period this error is logged ~5,000 times. It's been consistent for the last 27 days. I too am on the latest v4 of sequelize and using AWS RDS. It would be great to have this looked into more closely as it's a serious risk in the latest release.

 swordfish444
on 10 Jul 2017
swordfish444
on 10 Jul 2017
@felixfbecker It looks like this is the same as https://github.com/sequelize/sequelize/issues/7882
Also https://github.com/sequelize/sequelize/issues/7616 is likely related to the same problem.
swordfish444
on 10 Jul 2017
@afituri This saved my life. Thank you!
pavelkrcil
on 10 Jul 2017
Yeah, I'm having this same issue on a DigitalOcean server as well. I've tried the configuration from above with no luck.
 philipdbrown
on 10 Jul 2017
philipdbrown
on 10 Jul 2017
I am encountering the same problem on a DigitalOcean server. Do you have any updates on this issue?
I have also tried swordfish444 solution, but it didn't work.
 tiboprea
on 27 Jul 2017
tiboprea
on 27 Jul 2017
@tiboprea
I was able to solve it with async.queue. Checkout this quick article: https://medium.com/the-node-js-collection/processing-a-large-dataset-in-less-than-100-lines-of-node-js-with-async-queue-9766a78fa088
philipdbrown
on 27 Jul 2017
Cheers @philipdbrown for the solution. I have actually solved it in a dumb way by using setTimeout.
It's not the most efficient method but it should do for now until they fix it.
tiboprea
on 28 Jul 2017
thanks @afituri, your solution fixed the timeout error (for now).
just curious, in which case Sequelize can reach that options and get the TimeOut error again?
what are the "rare" and "optimal" options we need to set, to stay safe of Timeout error?.
i got Timeout error (with default pool options) just by quering 700 items (one by one) not everyone at the same time, but in the same proccess/thread.
what happen if y upload a massive excel with huge data to quering like 10k or more items?
 ningacoding
on 8 Aug 2017
ningacoding
on 8 Aug 2017
Along with using long timeout and fix in https://github.com/sequelize/sequelize/pull/7924, this should be fixed
 sushantdhiman
on 10 Aug 2017
sushantdhiman
on 10 Aug 2017
@sushantdhiman
After upgrade sequelize to v4.4.7, I still have the same problem.
 hronro
on 14 Aug 2017
hronro
on 14 Aug 2017
@foisonocean hmm, any way to reproduce this ?
sushantdhiman
on 14 Aug 2017
@sushantdhiman I'm using mysql, and when I insert 8000 items, I got this error.
By the way, when i connecting to my local mysql database, I also got the same problem.
hronro
on 14 Aug 2017
@foisonocean you can see our CI works properly. If anyone can submit a proper failing test case I will try resolve this. I cant help if I cant reproduce this issue :)
sushantdhiman
on 14 Aug 2017
@sushantdhiman so where can i submit a failing test case?
hronro
on 14 Aug 2017
as a PR
sushantdhiman
on 14 Aug 2017
I'm having this same issue and I want to give a PR to reproduce this issue but I can not reproduce every time! My test code like:

sequelize version: 4.4.3
posgrese 9.4.10
pool config {
max: 5,
min: 1,
idle: 10000,
acquire: 10000,
evict: 60000,
handleDisconnects: true
}
 nnsay
on 15 Aug 2017
nnsay
on 15 Aug 2017
sequleize: 4.5.0
mysql2: 1.4.1
engine: MySQL 5.6.27 (db.t2.small)
issue on binarylane/digitalocean
however, running from home on win 10 no issue with the same code.
{ SequelizeConnectionError: connect ETIMEDOUT
at Utils.Promise.tap.then.catch.err (/var/app/node_modules/sequelize/lib/dialects/mysql/connection-manager.js:146:19)
at tryCatcher (/var/app/node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (/var/app/node_modules/bluebird/js/release/promise.js:512:31)
at Promise._settlePromise (/var/app/node_modules/bluebird/js/release/promise.js:569:18)
at Promise._settlePromise0 (/var/app/node_modules/bluebird/js/release/promise.js:614:10)
at Promise._settlePromises (/var/app/node_modules/bluebird/js/release/promise.js:689:18)
at Async._drainQueue (/var/app/node_modules/bluebird/js/release/async.js:133:16)
at Async._drainQueues (/var/app/node_modules/bluebird/js/release/async.js:143:10)
at Immediate.Async.drainQueues (/var/app/node_modules/bluebird/js/release/async.js:17:14)
at runCallback (timers.js:672:20)
at tryOnImmediate (timers.js:645:5)
at processImmediate [as _immediateCallback] (timers.js:617:5)
name: 'SequelizeConnectionError',
parent:
{ Error: connect ETIMEDOUT
at Connection._handleTimeoutError (/var/app/node_modules/mysql2/lib/connection.js:194:13)
at ontimeout (timers.js:386:14)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5)
errorno: 'ETIMEDOUT',
code: 'ETIMEDOUT',
syscall: 'connect',
fatal: true },
original:
{ Error: connect ETIMEDOUT
at Connection._handleTimeoutError (/var/app/node_modules/mysql2/lib/connection.js:194:13)
at ontimeout (timers.js:386:14)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5)
errorno: 'ETIMEDOUT',
code: 'ETIMEDOUT',
syscall: 'connect',
fatal: true } }
Unhandled rejection SequelizeConnectionError: connect ETIMEDOUT
at Utils.Promise.tap.then.catch.err (/var/app/node_modules/sequelize/lib/dialects/mysql/connection-manager.js:146:19)
at tryCatcher (/var/app/node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (/var/app/node_modules/bluebird/js/release/promise.js:512:31)
at Promise._settlePromise (/var/app/node_modules/bluebird/js/release/promise.js:569:18)
at Promise._settlePromise0 (/var/app/node_modules/bluebird/js/release/promise.js:614:10)
at Promise._settlePromises (/var/app/node_modules/bluebird/js/release/promise.js:689:18)
at Async._drainQueue (/var/app/node_modules/bluebird/js/release/async.js:133:16)
at Async._drainQueues (/var/app/node_modules/bluebird/js/release/async.js:143:10)
at Immediate.Async.drainQueues (/var/app/node_modules/bluebird/js/release/async.js:17:14)
at runCallback (timers.js:672:20)
at tryOnImmediate (timers.js:645:5)
at processImmediate [as _immediateCallback] (timers.js:617:5)
it is only loading 100 results with 3 table joins, so nothing strenuous.
 mavrick
on 17 Aug 2017
mavrick
on 17 Aug 2017
A thought for those of you on AWS, ensure the security group has ipv4/ipv6 rules in place. I have a sneaky suspicion AWS changed something around IPv6 routing recently and anyone without the ipv6 rule will get these connection timeouts.
mavrick
on 17 Aug 2017
Same error using google cloud postgres.
PostgreSQL 9.6
Sequelize 4.2.0
 alejomendoza
on 20 Aug 2017
alejomendoza
on 20 Aug 2017
pool config {
max: 100,
min: 0,
idle: 10000,
acquire: 10000,
}
The main thing here for me was that I created swap space. When i initially added the acquire, it still was not working. I guess, I ran out memory because i was inserting about 19,000 records during that operation. But after creating the swap space and adding the acquire param, i was good to go. I am actually running on a 1 gig memory digital ocean server..
 niilarbie
on 21 Aug 2017
niilarbie
on 21 Aug 2017
Adding another one onto the pile. Azure app service connecting to Azure SQL:
SequelizeConnectionError: Failed to connect to <redacted>.database.windows.net:1433 - write ECONNRESET
at Connection.connection.on.err (D:\home\site\wwwroot\node_modules\sequelize\lib\dialects\mssql\connection-manager.js:99:22)
at emitOne (events.js:96:13)
at Connection.emit (events.js:188:7)
at Connection.socketError (D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:699:14)
at emitOne (events.js:96:13)
at Socket.emit (events.js:188:7)
at onwriteError (_stream_writable.js:345:10)
at onwrite (_stream_writable.js:363:5)
at WritableState.onwrite (_stream_writable.js:89:5)
at fireErrorCallbacks (net.js:468:13)
at Socket._destroy (net.js:509:3)
at Socket._writeGeneric (net.js:710:17)
at Socket._write (net.js:729:8)
at doWrite (_stream_writable.js:333:12)
at writeOrBuffer (_stream_writable.js:319:5)
at Socket.Writable.write (_stream_writable.js:246:11)
at Socket.write (net.js:656:40)
at MessageIO.sendPacket (D:\home\site\wwwroot\node_modules\tedious\lib\message-io.js:221:21)
at MessageIO.sendMessage (D:\home\site\wwwroot\node_modules\tedious\lib\message-io.js:211:14)
at Connection.sendPreLogin (D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:738:22)
at Connection.socketConnect (D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:1197:14)
at Connection.dispatchEvent (D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:687:45)
at Connection.socketConnect (D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:713:19)
at D:\home\site\wwwroot\node_modules\tedious\lib\connection.js:606:16
at Socket.onConnect (D:\home\site\wwwroot\node_modules\tedious\lib\connector.js:176:9)
at emitNone (events.js:86:13)
at Socket.emit (events.js:185:7)
at TCPConnectWrap.afterConnect [as oncomplete] (net.js:1072:10)
I haven't been able to get this to work since upgrading to sequelize 4.
 tylerjwatson
on 22 Aug 2017
tylerjwatson
on 22 Aug 2017
Bad connections are not automatically removed / evicted from pool, I have submitted a PR to node-pool https://github.com/coopernurse/node-pool/pull/201
sushantdhiman
on 22 Aug 2017
I'm having the same issue when running seeders with +10000 records.
Sequelize: 4.7.2, tedious: 2.0.0, node: 6.9.2
Microsoft SQL Server 2016
Windows 10 (x64) 10.0.14393
Works fine under sequelize v3.33.
Workaround proposed by @afituri seem's to work for now.
 Undre4m
on 25 Aug 2017
Undre4m
on 25 Aug 2017
I was getting the same error due to trying to write 1842 records to mysql concurrently. I started using Promise.map with concurrency option of 250 and I stopped getting the timeout.
 cubbuk
on 8 Sep 2017
cubbuk
on 8 Sep 2017
I have same error.
[2017-09-13 20:07:45.844] [ERROR] app - Unhandled Rejection at: Promise {
<rejected> { TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (/Users/felix/Desktop/ugengit/node/iot-app/node_modules/[email protected]@generic-pool/lib/ResourceRequest.js:58:17)
at Timeout.bound [as _onTimeout] (/Users/felix/Desktop/ugengit/node/iot-app/node_modules/[email protected]@generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:386:14)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5) name: 'TimeoutError' } } reason: { TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (/Users/felix/Desktop/ugengit/node/iot-app/node_modules/[email protected]@generic-pool/lib/ResourceRequest.js:58:17)
at Timeout.bound [as _onTimeout] (/Users/felix/Desktop/ugengit/node/iot-app/node_modules/[email protected]@generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:386:14)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5) name: 'TimeoutError' }
Sequelize:4.8.2
when I insert more than 5000 rows
 kid2682
on 13 Sep 2017
kid2682
on 13 Sep 2017
I found the way to reproduce this issue
The way is as follows:
- Prepare MySQL Server
- Install sequelize and mysql2 packages
- Start MySQL Server
- Execute the following code. While executing, you must start and stop the MySQL Server according to the instructions in the comments.
'use strict';
const readline = require('readline');
const Sequelize = require('sequelize');
const rl = readline.createInterface({ input: process.stdin, output: process.stdout });
async function main() {
const sequelize = new Sequelize('test', 'root', '', { dialect: 'mysql' }); // Set your db params
// First, you need to acquire a connection successfully once.
await q('Start mysql server and press return key');
await sequelize.transaction(async () => {}); // try to acquire a connection
// After succeed acquiring, stop mysql server
await q('Stop mysql and press return key')
// Acquire a connection again, and fail it
try {
await sequelize.transaction(async () => {}); // try to acquire a connection
}
catch (err) {
// and fail it
}
// Start mysql server again
await q('Start mysql server and press return key');
// Here, we will never acquire a connection again :(
try {
await sequelize.transaction(async () => {});
}
catch (err) {
// ResourceRequest timed out error will occur
console.error(err);
}
}
function q(message) {
return new Promise((resolve, reject) => rl.question(message, resolve));
}
main();
Why does the problem occur?
The problem is, I think, caused by the following mechanism:
- Although sequelize.connectionManager.dialect.connectionManager.connect(config) is rejected, factory.create method, the first argument of Pooling.createPool, will never be rejected or resolved.
- An operation, that will never be deleted, is added to pool._factoryCreateOperation.
- pool._potentiallyAllocableResourceCount is never less than pool._factoryCreateOperation.size.
- Thus, pool.acquire will wait for a request that will never be resolved. It will cause a ResourceRequest timed out error.
I really want a pool:false option...
 amachang
on 15 Sep 2017
amachang
on 15 Sep 2017
I'm getting this error when trying to do 1000 inserts. It doesn't matter if limit concurrency or not, as soon as it processes about 750 of them I get a bunch of ResourceRequest timeouts.
I'm using RDS and I've tried changing the pool config to match the ones in this issue.
Is there anything else I can try, or maybe I should just downgrade my version of Sequelize?
"sequelize": "^4.8.4"
 spencercwood
on 16 Sep 2017
spencercwood
on 16 Sep 2017
@amachang Seems like @sushantdhiman already called it out here https://github.com/coopernurse/node-pool/issues/161#issuecomment-264387712
 caseyduquettesc
on 17 Sep 2017
caseyduquettesc
on 17 Sep 2017
@caseyduquettesc Yeah, but 9 months ago... I think we need fix it on the sequelize side, not only on the node-pool side.
amachang
on 18 Sep 2017
Actually we need this fixed on generic-pool side, if acquire call never resolves we cant be sure if this is a network lag or factory create error. Old version of generic-pool used to properly reject for acquire calls.
We have three options
1) Someone fix that generic-pool issue, acquire calls properly rejects and there is no leftover acquire call waiting for getting resolved, hence not keeping pool busy forever.
2) Revert back to old version of generic-pool (may be breaking as we expose pool API in pool config)
3) Switch pooling library or create a pooling library for Sequelize (Lots of work)
I would prefer (1) but I dont have any extra time to dive into generic-pool, I am pretty busy with Sequelize already :)
Edit:
If someone wants to fix this, Please checkout these issues
https://github.com/coopernurse/node-pool/issues/175
https://github.com/coopernurse/node-pool/issues/183
https://github.com/coopernurse/node-pool/issues/161
sushantdhiman
on 18 Sep 2017
@sushantdhiman Does https://github.com/coopernurse/node-pool/pull/201 fix this issue, or was that for something else?
caseyduquettesc
on 18 Sep 2017
@caseyduquettesc I don't think coopernurse/node-pool#201 fix this issue. It's another problem. Try the code https://github.com/sequelize/sequelize/issues/7884#issuecomment-329656948 to reproduce this issue.
amachang
on 18 Sep 2017
@sushantdhiman
I think we should now consider the complete solution and temporary solution separately.
Complete Solution
I think, ideally, ResourceRequest should be rejected, not retried, on the node-pool side if connection fails, and node-pool users must be able to decide how to treat rejections.
Yeah, (1) or (3) is good for the complete solution.
But as far as reading a conversation 9 months ago, @sandfox responds that ResourceRequest needs to be retried until acquireTimeoutMillis.
There is no consensus on (1) solution...
Temporary Solution
This issue takes a long time to be solved, and we need a temporary solution.
As a temporary solution, how about trying the fix like the following?
- If factory.create method fails to connect, cause factory.create to be resolved, not rejected, with an error object.
- And then, cause pool.acquire to be resolved with the error object.
- If pool.acquire is resolved with the error object, cause getConnection to be rejected, and the error object to be destroyed with pool.destroy method
amachang
on 18 Sep 2017
@amachang
Temporary solution is a really dirty hack ;) But it can work. I think I can accept this solution so a PR is welcomed, then other maintainers can review as well.
sushantdhiman
on 18 Sep 2017
I am a bit drive-by commenting here, so sorry if I'm missing some of the context:
as regards
But as far as reading a conversation 9 months ago, @sandfox responds that ResourceRequest needs to be retried until acquireTimeoutMillis.
What I wanted to put across in the issue was that this is just how the current implementation works, not how I intended it to work with regards to this problem.
I think the best solution to the problem of factory.create calls constantly failing is place some kind of circuit breaker layer between the user supplied factory object and the pool.
Unfortunately I haven't had the time yet to prototype such a thing, but it's the direction I'd like to take even if we later fold the solution into generic-pool
(I'm also aware that generic-pool will probably need some work to allow the circuit breaker layer to access the information it needs)
TL;DR - I'd like to make things like this userland pluggable if possible.
 sandfox
on 18 Sep 2017
sandfox
on 18 Sep 2017
Now I need help from this thread participants, I have worked on @amachang idea and added other fixes for generic-pool here https://github.com/sequelize/sequelize/pull/8330
I want you guys to test that PR and report if it works for pooling issues or not :)
sushantdhiman
on 18 Sep 2017
@sushantdhiman Thanks! Will give it a test drive. Don't know where you find the time.
caseyduquettesc
on 18 Sep 2017
@sushantdhiman You, the fast worker! Thanks! I'll test it later!
amachang
on 19 Sep 2017
Config changes suggested by @afituri helped in my case (using [email protected]), #8330 PR didn't help. I don't have specific test case. What I did was run a lot of very simple queries that are supposed to return 1 row (N+1 queries, basically). I know, I'll fix N+1 problem soon.
Interestingly, this issue didn't exist with older version of my application using [email protected].
 thehappycoder
on 19 Sep 2017
thehappycoder
on 19 Sep 2017
After upgrading to 4.9.0 I still see the issue.
"mysql2": "^1.3.6",
 yazdanagh
on 21 Sep 2017
yazdanagh
on 21 Sep 2017
Does anyone still get this this issue? I'm on AWS RDS and still experiencing this problem on 4.10
 iamakimmer
on 26 Sep 2017
iamakimmer
on 26 Sep 2017
@iamakimmer I'm experiencing it with Postgres and v4.10. Heavy loads of queries running via cron jobs.
 gustaflindqvist
on 26 Sep 2017
gustaflindqvist
on 26 Sep 2017
What value you guys have set for pool.acquire
sushantdhiman
on 26 Sep 2017
You need to configure pool.acquire , default is 10sec . Set to a higher value, if its too low.
I am thinking about setting it to 30sec or may be 60sec by default (in v3 it used to be Infinity AFAIK, but you could end up waiting for infinite time to acquire an connection)
sushantdhiman
on 26 Sep 2017
var sequelize = new Sequelize(process.env[config.use_env_variable], {
pool: {
max: 5,
min: 0,
idle: 20000,
acquire: 20000
}
});
This is what I have, acquire is set to 20000 and it's still happening. I didn't get any of the timeout issues until recently
iamakimmer
on 26 Sep 2017
There is always an chance that connection isnt acquired in 20 sec, set to a higher value if its timing out. You could set this to 0 to get v3 behavior.
sushantdhiman
on 26 Sep 2017
@sushantdhiman is there anything my application could be doing to be causing this? I didn't get the timeout last month, but I do get a lot more volume and activity. Any suggestions on how I can further diagnose?
iamakimmer
on 27 Sep 2017
I upgraded to latest version and still getting this issue :(
Edit: nvm, this was my own fault. All my db connections were being used by transactions, BUT hidden in the same code-path I was trying to do a query that wasn't part of the transactions. The query not in a transaction was waiting for a connection to become available (transaction to finish), and the transactions were waiting for the query to finish before committing. I should have renamed my function to deadlockGenerator()
 michaelwayman
on 4 Oct 2017
michaelwayman
on 4 Oct 2017
If what @afituri suggested didn't helped you, you might check if your event loop is too busy, this also can cause this issue.
 amnons77
on 20 Oct 2017
amnons77
on 20 Oct 2017
@michaelwayman did you find by just reading through all the lines of your code? I'm trying to find a way to generate logs where my connections are not getting released
iamakimmer
on 23 Oct 2017
@iamakimmer yeah basically had to binary search my code... I wrote an integration test that could duplicate the issue, then console.logged() everywhere to see where I was freezing.
After wasting the whole day trying to figure out what was going on I decided to let it be, and tackle it the next day with a fresh start. I literally put console.logs() after every function in my code path to see exactly where the app was freezing/timing out at. Once I found the function, I noticed a database call was being made that wasn't part of the transactions.
So with a connection pool of 5.. we actually triggered the same long-running transaction's code-path 5x.. so each connection was in use by a transaction, and all other queries were stuck waiting for a transaction to finish so a connection could become available.
So I was basically doing this
transaction(() => {
doThing1();
doThing2();
doThing3();
});
each doThing() called a series of other functions.. in doThing3() probably 10 function calls down we were making another query that wasn't part of the transaction.. So like I said, the non-transaction query was waiting for a connection, and and doThing3() wouldn't finish until that query was done. So the transaction never releases a connection, the query never gets a connection to finish to allow the transaction... yadayada... deadlocked.
michaelwayman
on 23 Oct 2017
Hi guys. We've just been bitten by this one. Experiencing a very high number of ResourceRequest time outs when running under production load.
Putting this here to help anyone else out that comes across this ticket when migrating to v4. It looks like there are still some others out there scratching their head.
It turns out that it acquire times were a bit of a red hearing. Increasing the acquire time would only slightly alleviate the issue. Benchmarking our v3 times to v4, it was clear that there was a significant performance impact when running under v4. Requests for connections from the pool were very likely to hit the 10s default timeout because everything was running so slow.
We have traced this to a change in how a paranoid model deletion is handled in v4.
Under v3 a select over a paranoid model would be
...WHERE "MyModel"."deleted" IS NULL
Under v4 a select over a paranoid model is
...WHERE ("MyModel"."deleted" > '2017-10-26 05:23:19.646 +00:00' OR "MyModel"."deleted" IS NULL
This change in paranoid lookup misses our existing indexes that worked under v3.
Query plans which used to be quick index conditions are now full sequence scans.
Everything slows down and what do you know ResourceRequest timeouts everywhere.
This change was introduced in https://github.com/sequelize/sequelize/pull/5897
 crispkiwi
on 26 Oct 2017
crispkiwi
on 26 Oct 2017
Interesting observation @crispkiwi , I think we should maintain some sort of FAQ on documentation site and mention this information so it can help others. I will try to work on FAQ this weekend.
sushantdhiman
on 26 Oct 2017
After checking the log, I discover the same situation we have.
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1159): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1160): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1161): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1162): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1163): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1164): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1165): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1166): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1167): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1168): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1169): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1170): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1171): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1172): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1173): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1174): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1175): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1176): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1177): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1178): TimeoutError: ResourceRequest timed out
[0] (node:27749) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1179): TimeoutError: ResourceRequest timed out
I am still trying to figure out why this happen.
 shtse8
on 2 Nov 2017
shtse8
on 2 Nov 2017
@crispkiwi great find! How did you solve the solution for you? How would you change your indexes to fix this? Do we now need to add deletedAt column at the end of all our indexes?
 xdamman
on 2 Nov 2017
xdamman
on 2 Nov 2017
@xdamman, no long term solution for us at this stage, the discussion has moved over here https://github.com/sequelize/sequelize/issues/8496
This will only be a problem for you if you currently exclude soft deleted records from your indexes. E.g you have a model set up like this
paranoid: true,
indexes: [{
fields: [ 'email' ],
where: {
deletedAt: null,
},
}],
If you do not have a paranoid model and you have not manually excluded soft deleted records you should not be experiencing a slowdown from this particular issue.
crispkiwi
on 2 Nov 2017
I'm not excluding deletedAt in the indexes but I still run into this timeout issue for query intense processes (for processing the monthly email report to users).
Adding {concurrency: 1} to Promise.map helps but it's not enough. It's quite annoying. We didn't have such issue with Sequelize v3.
https://github.com/opencollective/opencollective-api/blob/2194992a865d16bea9000cab5077488c61d302d5/cron/monthly/host-report.js#L72
xdamman
on 2 Nov 2017
@xdamman I noticed your pool config isnt using any acquire, https://github.com/opencollective/opencollective-api/blob/2194992a865d16bea9000cab5077488c61d302d5/config/production.json#L11
If you follow this thread its stated many times that v3 and v4 have different acquire time. For v4 its 20sec, are you sure 20sec is enough for your case. If its not increase it.
In v3 you wont have this timeout because acquire was set to 0, which means sequelize will wait for ever to get connection, which is not ok either.
You just need to increase acquire time to something that is suitable to your usercase
sushantdhiman
on 2 Nov 2017
@crispkiwi Thank you for digging into our code and finding that out! Really appreciated! 🙏
xdamman
on 2 Nov 2017
Bit of a drive by comment, but in case it helps someone: We were getting hundreds of ResourceRequest errors. Naturally, we started trying to tweak the connection pool settings, etc. It turned out we had some expensive calculations completely outside of sequelize that were starving the event loop, and that was meaning that anything else could not happen in time. It just so happened that "anything else" was 95% interacting with the database, the first step of which is to grab a connection from the pool. So, that's where we saw the failure.
 joshuapaling
on 9 Nov 2017
joshuapaling
on 9 Nov 2017
I see the same issue:
(node:1) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: timeout exceeded when trying to connect
(node:1) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 2): Error: timeout exceeded when trying to connect
(node:1) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 3): Error: timeout exceeded when trying to connect
....
Unable to connect to the database using sequelize: { TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (/srv/app/node_modules/generic-pool/lib/ResourceRequest.js:58:17)
at Timeout.bound (/srv/app/node_modules/generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:386:11)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5) name: 'TimeoutError' }
...
 mirajshah05
on 21 Nov 2017
mirajshah05
on 21 Nov 2017
@xdamman did that config solve it for you?
 anurag29
on 21 Nov 2017
anurag29
on 21 Nov 2017
I am experiencing this issue as well using sequelize v4.23.1 (newest version).
Steps to reproduce:
1) use replication for 2 read instances
2) start up server/sequelize and hit it a few times
3) turn off one of the dbs (i.e. just shut down the db, not the whole machine that the db is running on)
4) continue to hit the server/sequelize (it will intermittently return 500 due to TimeoutError: ResourceRequest timed out
5) Eventually, it seems to get completely stuck in an unrecoverable state (short of completely restarting it). It continuously returns the error even if the one db is still running.
Here is my pool config:
pool: {
max: 5,
min: 0,
idle: 5000,
acquire: 20000,
evict: 30000,
handleDisconnects: true
}
 istrau2
on 27 Nov 2017
istrau2
on 27 Nov 2017
The ResourceRequest timed out error appears after prolonged usage of Sequelize on a production server. Does anyone know what could be the problem?
The error gets fixed when I restart the project. Am I handling something incorrectly?
I have the acquire 20s in my pool config.
 iamjoyce
on 30 Nov 2017
iamjoyce
on 30 Nov 2017
Updated to 4.22.5 but still run into the issue ResourceRequest timed out sometimes.
My pool config
dialect: 'mssql',
pool: {
max: 5,
min: 1,
idle: 20000,
evict: 20000,
acquire: 20000
},
Please advise @sushantdhiman
 Jackychans
on 6 Dec 2017
Jackychans
on 6 Dec 2017
@philipdbrown thank you, I was able to solve this by using async.queue as well
 jess0407
on 11 Dec 2017
jess0407
on 11 Dec 2017
Hi @jess0407, did you monitor the situation for a pro-longed period of time?
iamjoyce
on 12 Dec 2017
Updated to 4.22.5, but still have the issue for Sql Server. I didn't insert or update any record, just let the application run for a while without any operations, and then I had the issue when I tried to query data from the database.
 shilu911
on 1 Jan 2018
shilu911
on 1 Jan 2018
@sushantdhiman
v4.23.2
mysql
pool (use default)
In production, still got ResourceRequest timed out (when db backup after),
and can't auth restart (or reconnect db)
how to fix it ?
 justintien
on 13 Jan 2018
justintien
on 13 Jan 2018
BTW, for people who are on production server, you might want to set pool.max to a higher value than 5, depending on what your database server can support. For example, my database on Azure allows up to 600 sessions.
I find that increasing the maximum number of pools reduces the occurrence of the timeout error.
iamjoyce
on 17 Jan 2018
@iamjoyce
I did reconnect when catch 'ResourceRequest timed out' (retry: 3 times)
sequelize.close() && and new Sequelize to resolve for temp.
but I think it's not better....
justintien
on 17 Jan 2018
@iamjoyce I setting pool max to 50 (old is use default 5),
seems, it didn't timed out and work fine...
I will keep check it....
Maybe slow query or connection hange up cause of 'ResourceRequest timed out'
@sushantdhiman
current, I have a mysql instance 'A' (azure)
Each time, exec mysqldump ( lock table ), then 'ResourceRequest timed out'
but I don't know how to test it
I have tried copy mysql instance 'B', and exec mysqldump but it didn't 'ResourceRequest timed out'
justintien
on 19 Jan 2018
I am having the exact same issue when I connect to a remote server. But developing locally was flawless.
Unable to connect to the database: { SequelizeConnectionError: connect ETIMEDOUT
at Utils.Promise.tap.then.catch.err (/home/arvi/Projects/sample-project/node_modules/sequelize/lib/dialects/mysql/connection-manager.js:149:19)
at tryCatcher (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/promise.js:512:31)
at Promise._settlePromise (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/promise.js:569:18)
at Promise._settlePromise0 (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/promise.js:614:10)
at Promise._settlePromises (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/promise.js:689:18)
at Async._drainQueue (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/async.js:133:16)
at Async._drainQueues (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/async.js:143:10)
at Immediate.Async.drainQueues (/home/arvi/Projects/sample-project/node_modules/bluebird/js/release/async.js:17:14)
at runCallback (timers.js:789:20)
at tryOnImmediate (timers.js:751:5)
at processImmediate [as _immediateCallback] (timers.js:722:5)
name: 'SequelizeConnectionError',
parent:
{ Error: connect ETIMEDOUT
at Connection._handleTimeoutError (/home/arvi/Projects/sample-project/node_modules/mysql2/lib/connection.js:194:13)
at ontimeout (timers.js:475:11)
at tryOnTimeout (timers.js:310:5)
at Timer.listOnTimeout (timers.js:270:5)
errorno: 'ETIMEDOUT',
code: 'ETIMEDOUT',
syscall: 'connect',
fatal: true },
original:
{ Error: connect ETIMEDOUT
at Connection._handleTimeoutError (/home/arvi/Projects/sample-project/node_modules/mysql2/lib/connection.js:194:13)
at ontimeout (timers.js:475:11)
at tryOnTimeout (timers.js:310:5)
at Timer.listOnTimeout (timers.js:270:5)
errorno: 'ETIMEDOUT',
code: 'ETIMEDOUT',
syscall: 'connect',
fatal: true } } +10s
"mysql2": "^1.5.1",
"sequelize": "^4.31.2",
const sequelize = new Sequelize(config.sqldb.name, config.sqldb.user, config.sqldb.pwd, {
host: config.sqldb.host,
dialect: 'mysql',
pool: {
max: 100,
min: 0,
acquire: 20000,
idle: 20000,
},
});
@philipdbrown Did you use async.queue when trying to connect? Do you have sample snippet. Maybe this issue will be solved if we have await or something like that to wait for connection before doing anything... or maybe I don't understand the problem :sweat_smile:
 arvi
on 19 Jan 2018
arvi
on 19 Jan 2018
@arvi This error doesn't seem like what we are experiencing. If I don't remember wrongly, your error happened because it couldn't establish a connection to your database in the first place - It could be because your host / username / password is wrong.
iamjoyce
on 19 Jan 2018
@iamjoyce, the credentials are not wrong. Sometimes it would print that error sometimes it would connect. It is intermittent. But maybe 90% of the time it wouldn't connect and result to that error.
arvi
on 22 Jan 2018
I get this issue on Google Cloud Functions but running the same code from home it works. Not a firewall issue or use issue as everything is open to the world (for testing). Submitted various support tickets to Firebase support but they say it's an AWS issue.
mavrick
on 22 Jan 2018
We're still getting this, we've updated to the most recent version, and our databases are on a Digital Ocean droplet. This didn't start happening until about a month ago (for us). Now after about 24 hours of traffic, this error begins to show.
 Celadora
on 24 Jan 2018
Celadora
on 24 Jan 2018
We're still getting this error.
Here is my sequelize connection
dialect: 'mysql',
port: 3306,
database: 'onsports',
replication: {
read: [
{ host: 'mysql-slave',
username: 'root',
password: 'secret',
pool: { // If you want to override the options used for the read/write pool you can do so here
max: 100,
idle: 5000,
acquire: 30000,
database: 'xxx'
} },
{ host: 'mysql-master',
username: 'root',
password: 'secret',
pool: { // If you want to override the options used for the read/write pool you can do so here
max: 100,
idle: 5000,
acquire: 30000,
database: 'xxx'
}
}
],
write: { host: 'mysql-master',
username: 'root',
password: 'secret',
pool: { // If you want to override the options used for the read/write pool you can do so here
max: 20,
idle: 5000,
acquire: 30000,
database: 'xxx'
}
}
}
when i use apache benchmark to test server performance, i try to send 1000 req with 300 req/second, i get this error. i test with my home page ( it will call about 4 - 5 API ). Pls help
 nguyenviettuananh
on 25 Jan 2018
nguyenviettuananh
on 25 Jan 2018
Getting this error too using postgres 9.6, pg 6.4.2 and sequelize 4.31.2. We're using dedicated servers with 2-nodes postgres replication.
TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (.../node_modules/sequelize/node_modules/generic-pool/lib/ResourceRequest.js:62:17)
at Timeout.bound (.../node_modules/sequelize/node_modules/generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:386:14)
at tryOnTimeout (timers.js:250:5)
at Timer.listOnTimeout (timers.js:214:5)
You have triggered an unhandledRejection, you may have forgotten to catch a Promise rejection:
TypeError: Cannot read property 'query' of undefined
at parameters.length.Promise (.../node_modules/sequelize/lib/dialects/postgres/query.js:65:53)
at Promise._execute (.../node_modules/bluebird/js/release/debuggability.js:300:9)
at Promise._resolveFromExecutor (.../node_modules/bluebird/js/release/promise.js:483:18)
at new Promise (.../node_modules/bluebird/js/release/promise.js:79:10)
at Query.run (.../node_modules/sequelize/lib/dialects/postgres/query.js:65:9)
at retry (.../node_modules/sequelize/lib/sequelize.js:544:32)
at .../node_modules/retry-as-promised/index.js:39:21
at Promise._execute (.../node_modules/bluebird/js/release/debuggability.js:300:9)
at Promise._resolveFromExecutor (.../node_modules/bluebird/js/release/promise.js:483:18)
at new Promise (.../node_modules/bluebird/js/release/promise.js:79:10)
at retryAsPromised (.../node_modules/retry-as-promised/index.js:29:10)
at Promise.try.then.connection (.../node_modules/sequelize/lib/sequelize.js:544:14)
at tryCatcher (.../node_modules/bluebird/js/release/util.js:16:23)
at Promise._settlePromiseFromHandler (.../node_modules/bluebird/js/release/promise.js:512:31)
at Promise._settlePromise (.../node_modules/bluebird/js/release/promise.js:569:18)
at Promise._settlePromiseCtx (.../node_modules/bluebird/js/release/promise.js:606:10)
at Async._drainQueue (.../node_modules/bluebird/js/release/async.js:138:12)
at Async._drainQueues (.../node_modules/bluebird/js/release/async.js:143:10)
at Immediate.Async.drainQueues (.../node_modules/bluebird/js/release/async.js:17:14)
at runCallback (timers.js:672:20)
at tryOnImmediate (timers.js:645:5)
at processImmediate [as _immediateCallback] (timers.js:617:5)
 FreakenK
on 26 Jan 2018
FreakenK
on 26 Jan 2018
I am getting the same error. I am very scared to put this into production. I hope there is a way to recreate the error.
Basically, if I let the app run for a few days, requests start to time out. The error goes away when I forcibly recreate sequelize.
Sequelize: 4.25.1.
Here is how I initialize the connection:
const db = function(): IModels {
if (_db) {
return _db;
}
_db = {};
const env = process.env.NODE_ENV || 'development';
const config = require('../../config/config.json');
const dbConfig = config[env];
const basename = path.basename(__filename);
let sequelize;
const LOG_TAG = 'models.';
if (dbConfig.use_env_variable) {
sequelize = new Sequelize(process.env[dbConfig.use_env_variable], {
dialect: dbConfig.dialect,
dialectOptions: dbConfig.dialectOptions,
logging: process.env.DB_LOGGING === 'true',
pool: {
max: 100,
min: 0,
idle: 20000,
acquire: 20000
}
});
} else {
sequelize = new Sequelize(
dbConfig.database,
dbConfig.username,
dbConfig.password,
{
...dbConfig,
logging: process.env.DB_LOGGING === 'true',
pool: {
max: 100,
min: 0,
idle: 20000,
acquire: 20000
}
}
);
}
const modelsNames: Array<string> = [];
const isCorrectModelFile = (fileName: string) => {
return (
fileName.indexOf('.') !== 0 &&
fileName !== basename &&
(fileName.slice(-3) === '.ts' || fileName.slice(-3) === '.js') &&
fileName.indexOf('types') === -1 &&
fileName.indexOf('schema') === -1 &&
fileName.indexOf('spec') === -1
);
};
const findModels = (directory: string) => {
fs.readdirSync(directory).forEach(file => {
if (file.indexOf('.') === -1) {
// Assume that it is a directory
findModels(`${directory}/${file}/`);
} else if (isCorrectModelFile(file)) {
modelsNames.push(`${directory}${file}`);
}
});
};
_db.sequelize = sequelize;
findModels(__dirname);
modelsNames.forEach(modelPath => {
const model: any = sequelize.import(modelPath);
_db[model.name] = model;
});
Object.keys(_db).forEach(modelName => {
if (_db[modelName].associate) {
_db[modelName].associate(_db);
}
});
return _db;
};
Here is how I "forcibly" reconnect:
const reconnectDb = () => {
if (_db) {
_db.sequelize.close();
_db = null;
}
return db();
};
Here are my logs:
"ResourceRequest timed out"
"TimeoutError: ResourceRequest timed out\n at ResourceRequest._fireTimeout (/app/node_modules/sequelize/node_modules/generic-pool/lib/ResourceRequest.js:58:17)\n at Timeout.bound (/app/node_modules/sequelize/node_modules/generic-pool/lib/ResourceRequest.js:8:15)\n at ontimeout (timers.js:475:11)\n at tryOnTimeout (timers.js:310:5)\n at Timer.listOnTimeout (timers.js:270:5)\nFrom previous event:\n at new Deferred (/app/node_modules/sequelize/node_modules/generic-pool/lib/Deferred.js:14:21)\n at new ResourceRequest (/app/node_modules/sequelize/node_modules/generic-pool/lib/ResourceRequest.js:24:5)\n at Pool.acquire (/app/node_modules/sequelize/node_modules/generic-pool/lib/Pool.js:408:29)\n at promise.then (/app/node_modules/sequelize/lib/dialects/abstract/connection-manager.js:274:24)\nFrom previous event:\n at ConnectionManager.getConnection (/app/node_modules/sequelize/lib/dialects/abstract/connection-manager.js:273:20)\n at Promise.try (/app/node_modules/sequelize/lib/sequelize.js:538:92)\nFrom previous event:\n at Sequelize.query (/app/node_modules/sequelize/lib/sequelize.js:445:23)\n at QueryInterface.bulkUpdate (/app/node_modules/sequelize/lib/query-interface.js:976:27)\n at Promise.try.then.then.then.results (/app/node_modules/sequelize/lib/model.js:2775:34)\nFrom previous event:\n at Function.update (/app/node_modules/sequelize/lib/model.js:2764:8)\n at Object.<anonymous> (/app/dist/models/scheduled_messages/scheduled_messages.js:55:72)\n at Generator.next (<anonymous>:null:null)\n at /app/dist/models/scheduled_messages/scheduled_messages.js:7:71\n at new Promise (<anonymous>:null:null)\n at __awaiter (/app/dist/models/scheduled_messages/scheduled_messages.js:3:12)\n at Function.ScheduledMessage.prepareDueMessagesForSending (/app/dist/models/scheduled_messages/scheduled_messages.js:53:66)\n at Object.<anonymous> (/app/dist/lib/send_scheduled_flows_worker.js:35:45)\n at Generator.next (<anonymous>:null:null)\n at /app/dist/lib/send_scheduled_flows_worker.js:7:71\n at new Promise (<anonymous>:null:null)\n at __awaiter (/app/dist/lib/send_scheduled_flows_worker.js:3:12)\n at Queue.onProcess (/app/dist/lib/send_scheduled_flows_worker.js:31:34)\n at ret (<anonymous>:13:39)\n at Queue.processJob (/app/node_modules/bull/lib/queue.js:897:22)\n at runCallback (timers.js:789:20)\n at tryOnImmediate (timers.js:751:5)\n at processImmediate [as _immediateCallback] (timers.js:722:5)"
 effortlesscoding
on 6 Feb 2018
effortlesscoding
on 6 Feb 2018
@ sequelize maintainers (@sushantdhiman?) I wonder if a good solution here is to have a way to inspect the connection pool (how many active connections are there, and what query is each of them running). That way, when the error happens, we could log all active queries and see what's really happening here. I suspect if I were to log the queries, it would show that all active connections are bust making long-running queries.
That would help a lot with debugging this issue, and would reduce (or at least shed light on) these complaints.
 idris
on 7 Feb 2018
idris
on 7 Feb 2018
I played a bit more with this during the weekend and can now easily reproduce the issue by consuming all connections with somewhat long-running queries (1 second) and many concurrent requests. Taking some time to test different pool options and fixing problematic queries (using postgres, found queries with missing indexes in some places using the slow query log) helped a lot and gives me a bit more confidence about the future.
I think at this point, it's about making sure your queries are optimized and finding the proper pool options for your setup.
FreakenK
on 7 Feb 2018
@FreakenK when you reproduce and do get the timeout, are the connections released back into the pool for, and available for reuse?
iamakimmer
on 12 Feb 2018
@iamakimmer We're using pm2 (from keymetrics.io) as our process manager which restarts the process as soon as an exception gets thrown, so I couldn't tell. We're running 8 processes, all of which now have a 10 connections in their pool (was 5 before changes), but I believe that fixing / better managing our long-running queries was the key here.
I deployed our new configuration in production 5 days and didn't have a timeout since, whereas we were getting 4-5 timeouts a day before the changes.
FreakenK
on 13 Feb 2018
@FreakenK thanks I will try that out!
iamakimmer
on 14 Feb 2018
I finally managed to solve this issue by investigating slow queries in MySQL and addressing them. I found one in particular that was bringing my server on its knees. It contained a bad sub-query on a table that grows rapidly and did not have the right indexing.
Re-writing the query and adding a couple indexes not only fixed the TimeoutError but also greatly improve the performances of that endpoint:
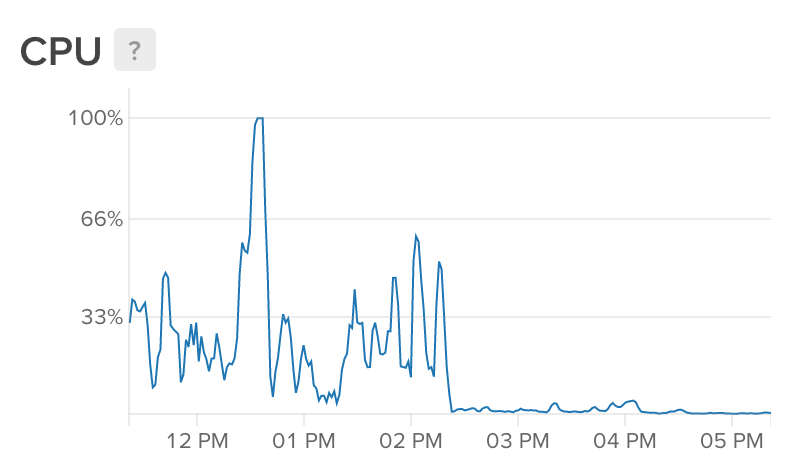
I initially blamed the issue on Sequelize 4 because the issue started around the time I upgraded my dependencies. But fundamentally this error was the symptom of something wrong with my code.
Edit: thanks @FreakenK for the suggestion.
 gzurbach
on 22 Feb 2018
gzurbach
on 22 Feb 2018
@gzurbach interesting. We have this issue on initial connection to the db... without querying anything yet connected to a database hosted via AWS. I resort to mongodb for now which didn't have any problem connecting to AWS. Maybe I'll try bookshelf as I find it similar to sequelize and see if issue persist there.
arvi
on 22 Feb 2018
Just came to say that async.queue worked for us as well. Code:
const queue = require('async').queue;
async function massUpdate() {
const items = [... BIG LIST ...];
return new Promise<User>(async (resolve, reject) => {
// We need async queue to prevent the DB acquire lock from timing out
// We have 5 workers, so leave 1 to handle request while 4 work on this insert
const asyncQueue = queue(async (item) => (
Model.insert(item)
), 4);
// Set callbacks
asyncQueue.drain = () => {
winston.info(`INSERTED ${items.length} rows`);
resolve();
};
asyncQueue.error = (err) => {
reject(err);
};
// Add all items to the queue
asyncQueue.push(items);
});
};
}
 lingz
on 26 Feb 2018
lingz
on 26 Feb 2018
For anyone running against Azure Managed Postgre DB:
We have discovered that the PG driver does not close sockets properly when using the Azure PG DB that can cause connection timeouts due to port exhaustion. More info here: https://twitter.com/Vratislav_/status/983249713825804288
Fix is pending here:
 Vratislav
on 9 Apr 2018
Vratislav
on 9 Apr 2018
Has this bug ever been figured out? Still getting it...
Error: { TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (/app/node_modules/generic-pool/lib/ResourceRequest.js:62:17)
at Timeout.bound (/app/node_modules/generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:427:11)
at tryOnTimeout (timers.js:289:5)
at listOnTimeout (timers.js:252:5)
at Timer.processTimers (timers.js:212:10) name: 'TimeoutError' }
File "/app/node_modules/generic-pool/lib/ResourceRequest.js", line 62, col 17, in ResourceRequest._fireTimeout
this.reject(new errors.TimeoutError("ResourceRequest timed out"));
File "/app/node_modules/generic-pool/lib/ResourceRequest.js", line 8, col 15, in Timeout.bound
return fn.apply(ctx, arguments);
File "timers.js", line 427, col 11, in ontimeout
File "timers.js", line 289, col 5, in tryOnTimeout
File "timers.js", line 252, col 5, in listOnTimeout
File "timers.js", line 212, col 10, in Timer.processTimers
File "/app/node_modules/raven/lib/client.js", line 407, col 15, in Raven.captureException
err = new Error(err);
File "/app/node_modules/winston-raven-sentry/index.js", line 93, col 23, in Sentry.log
return this.raven.captureException(message, context, function() {
File "/app/node_modules/winston/lib/winston/logger.js", line 234, col 15, in transportLog
transport.log(level, msg, meta, function (err) {
File "/app/node_modules/winston/node_modules/async/lib/async.js", line 157, col 13, in null.<anonymous>
iterator(x, only_once(done) );
File "/app/node_modules/winston/node_modules/async/lib/async.js", line 57, col 9, in _each
iterator(arr[index], index, arr);
File "/app/node_modules/winston/node_modules/async/lib/async.js", line 156, col 9, in Object.async.each
_each(arr, function (x) {
File "/app/node_modules/winston/lib/winston/logger.js", line 246, col 9, in exports.Logger.Logger.log
async.forEach(targets, transportLog, finish);
File "/app/node_modules/winston/lib/winston/common.js", line 54, col 18, in exports.Logger.target.(anonymous function) [as error]
target.log.apply(target, args);
File "/app/src/lib/exchanges.js", line 38, col 12, in handleTransactionModel
logger.error(err, {
 shortcircuit3
on 15 Aug 2018
shortcircuit3
on 15 Aug 2018
@milesalex try increasing the specs of your VM
iamjoyce
on 16 Aug 2018
@milesalex in my case this was related to the DNS requests timing out under heavy load. I was able to reproduce this issue by running the mysql cli utility at first, and then by just using nslookup. Both of these commands would time out occasionally. I ended up hardcoding the MySQL server IP to the app config and that fixed the issue. Later on I just added the server IP entry to /etc/hosts to avoid hardcoding the same IP in multiple config files for multiple apps.
 jeremija
on 16 Aug 2018
jeremija
on 16 Aug 2018
@milesalex when you see ResourceRequest timed out error it tends to suggest that all the connection in your pool were busy being used and the waiting requests for a connection timed out. You probably have some slow or long running queries. There's no generic way to fix this but good things to look at include
- increasing the max connections in the pool (you should check if your database has a upper limit though)
- checking your database to see if it has a slow query log or anyway to tell you about long running queries and then seeing if you have missing indexes or could rewrite the queries to be more efficient
- increasing the cpu/ram of your database server
sandfox
on 16 Aug 2018
@sandfox, I met the same problems.
When I increased the max connections in the pool, the Exception still happened with same frequency.
 wendell-zhang
on 17 Aug 2018
wendell-zhang
on 17 Aug 2018
@Wendell220 If increasing max connections in your application isn't helping then it very strongly suggests that you either need to increase the resources available to your database (e.g more ram/cpu), or find a way to make your queries less expensive (e.g , add an index, limit the number of rows/columns returned for queries, remove joins, move/copy columns), or reduce the number of queries (maybe you have a loop in your application code that is creating a query for every iteration, which could be replaced by a single query outside the loop).
sandfox
on 20 Aug 2018
I am experiencing similar issues. The database's logging shows that there were never more than 6 out of 10 parallel connections. Furthermore all queries from this process finished in less than 3ms., so I do not think that this issue is (only) caused by inefficient database queries. I am using the postgres driver.
 reezer
on 30 Aug 2018
reezer
on 30 Aug 2018
If anyone out there is facing the issue and the pool thing(in above comments) is not solving your problem. Have a look at the following comment by @michaelwayman
https://github.com/sequelize/sequelize/issues/7884#issuecomment-338778283
In a nutshell. What @michaelwayman is trying to bring up is that if you have multiple queries happening in a particular function and some of them uses a transaction & some of them don't. Try to manage them in a way that queries not using transactions dont have a transaction already initialized by sequelize.transaction
This analysis helped me solve my problem. Thanks @michaelwayman
 delveintechnolabs
on 21 Sep 2018
delveintechnolabs
on 21 Sep 2018
We've bumped into the same error. It's weird, but we don't have any transactions in that piece of code. It looks like a bunch of asynchronous queries to the DB, two of them use sequelize.query() to query data and the rest 8 are made with models. I don't know why exactly, but calling one of the .query() after the others resolved somehow fixed the issue. So, we first run all those 9 queries simultaneously, and after they resolved we run the latest one. Only this worked for us.
 lancedikson
on 7 Nov 2018
lancedikson
on 7 Nov 2018
Had same problem for MySQL on AWS - it appeared that the issue was caused by high CPU utilization on ECS nodes (up to 100%) - as @milesalex suggested.
Solved by adding more nodes to ECS cluster (CPU utilization went to 10% avg)
 aillusions
on 15 Nov 2018
aillusions
on 15 Nov 2018
My reason fot this issue was unhandled transaction (make bunch of transaction, no commit or rollback).
 rlaace423
on 28 Jan 2019
rlaace423
on 28 Jan 2019
I have a .txt file with 21497 rows and I read this file with fs.readFile and forEach row, I sync with Product table and insert the new records or update the existing ones.

A lot of records are inserted or updated on the Postgres database, but the major part I get this error:

If I try to run again on the same file, new records are inserted, but the error continues on other records.
Maybe it's a lot of processing at the same time and some records are timed out. But how can I solve this? I tried to increase the max pool value but doesn't work.
 lcandiago
on 27 Feb 2019
lcandiago
on 27 Feb 2019
Suggest a bulk insert here, so instead of 21497 inserts it is 1 insert. I think method is bulkCreate or bulkInsert
On Feb 27, 2019, at 07:54, Lorenzo de Vargas Candiago notifications@github.com wrote:
I have a .txt file with 21497 rows and I read this file with fs.readFile and forEach row, I sync with Product table and insert the new records or update the existing ones.
A lot of records are inserted or updated on the postgres database, but the major part I get this error:
If I try tu run again on the same file, new records are inserted, but the error continues on other records.
Maybe it's a lot of processing at the same time and some records are timed out. But how can I solve this? I tried to increase the max pool value but doesn't work.
—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or mute the thread.
iamakimmer
on 27 Feb 2019
Suggest a bulk insert here, so instead of 21497 inserts it is 1 insert. I think method is bulkCreate or bulkInsert
I found the updateOnDuplicate option on bulkCreate documentation, but it's only supported by mysql.. so I don't know how to use bulkCreate with the Upsert effect. Do you have any idea?
Thanks!
lcandiago
on 27 Feb 2019
Are you using postgres? There is this:
PostgreSQL since version 9.5 has UPSERTsyntax, with ON CONFLICT clause. with the following syntax (similar to MySQL)
On Feb 27, 2019, at 09:35, Lorenzo de Vargas Candiago notifications@github.com wrote:
Suggest a bulk insert here, so instead of 21497 inserts it is 1 insert. I think method is bulkCreate or bulkInsert
I found the updateOnDuplicate option on bulkCreate documentation, but it's only supported by mysql.. so I don't know how to use bulkCreate with the Upsert effect. Do you have any idea?
Thanks!—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub, or mute the thread.
iamakimmer
on 27 Feb 2019
Having same issue. Using postgres 9.6
(node:61927) UnhandledPromiseRejectionWarning: TimeoutError: ResourceRequest timed out
at ResourceRequest._fireTimeout (/Users/McFlat/indexer/node_modules/generic-pool/lib/ResourceRequest.js:62:17)
at Timeout.bound (/Users/McFlat/indexer/node_modules/generic-pool/lib/ResourceRequest.js:8:15)
at ontimeout (timers.js:466:11)
at tryOnTimeout (timers.js:304:5)
at Timer.listOnTimeout (timers.js:267:5)
Turns out Sequelize isn't production ready yet after all. Doesn't surprise me! Man will never be like the father in heaven, deny it all you want, but that's the reality. youtube search "Shaking My Head Productions". Can't depend on any of this tech crap, it's all garbage from the devil himself, that's the real nature of the problem if you think about it deep enough.
 McFlat
on 6 Mar 2019
McFlat
on 6 Mar 2019
@lcandiago If I read your code correctly, you are syncing the Product model for every row, and you are actually running all queries in parallel. This is where your timeout comes from. Just put a console.log before const product = ... and you'll see what I mean. Your console.log will probably have time to execute 21497 before a handful of queries complete.
Sync your Product model beforehand and change your forEach for a plain old for loop such as this :
for(let i = 0; i < rows.length; ++i) {
const product = {
...
}
try {
await Product.upsert(product);
console.log(...);
}
catch(...) {
}
}
You will then run all queries sequentially and this should to the trick. You could try to run them in batches of 5, 10, 20, etc. to get better performance.
FreakenK
on 7 Mar 2019
For anyone coming to this thread later, checkout the changelist for v5. It seems to address this issue:
https://github.com/sequelize/sequelize/blob/master/docs/upgrade-to-v5.md
 weexpectedTHIS
on 18 Mar 2019
weexpectedTHIS
on 18 Mar 2019
me too
 acodercat
on 19 Apr 2019
acodercat
on 19 Apr 2019
I'm experiencing the same issue started recently, MariaDB, sequelize 4.42.0, mysql2 1.6.5.
 idangozlan
on 28 Apr 2019
idangozlan
on 28 Apr 2019
I just wanted to post this to potentially help anyone else out.. because I was really struggling with this myself and could not figure out why I couldn't connect to the database on my server (ubuntu 18.04), but could in dev. Turns out, inbound rules on Amazon were set to a specific ip, and editing inbound rules to anywhere (any ip address), I wasn't getting anymore connection timeouts. I thought I had set this up in the beginning because it's a test project, but apparently not..
 aschambers
on 2 May 2019
aschambers
on 2 May 2019
I had the same issue, but locally. Turns out I forgot to commit a transaction before returning a model instance.
 vkaracic
on 12 Jun 2019
vkaracic
on 12 Jun 2019
For those of you still using v4 of Sequelize, this problem may have been fixed by v4.44.1.
See PR: https://github.com/sequelize/sequelize/pull/11140
See Issue: https://github.com/sequelize/sequelize/issues/11139
 mkaufmaner
on 2 Jul 2019
mkaufmaner
on 2 Jul 2019
Still experiencing the bug on v4.44.1.
It might be worth just migrating to v5 and to see if it's been resolved there.
 joshua-turner
on 2 Jul 2019
joshua-turner
on 2 Jul 2019
Still experiencing the bug on v4.44.1.
It might be worth just migrating to v5 and to see if it's been resolved there.
@joshua-turner are u successfully migrated to v5 and find everything perfect? Do you have any experience with the v5?
 polaroi8d
on 15 Jul 2019
polaroi8d
on 15 Jul 2019
We have upgraded to v5 and seems like it helped for some reason. But it was such a shot in the dark.
lancedikson
on 15 Jul 2019
We upgraded to v5 as well. With no further sequelize (i. e. pooling) configuration other than that, we still get SequelizeConnectionAcquireTimeoutError: Operation timeout. Anecdotally, this timeout-ing seems to occur less, but haven't measured/monitored closely in our deployment.
Will update if we find a configuration or bugfix that eradicates our issues completely!
 btroo
on 1 Aug 2019
btroo
on 1 Aug 2019
Update:
Found this issue yesterday https://github.com/sequelize/sequelize/issues/10976
Turns out that we had a case of a concurrent nested transaction stalling a parent transaction, which resulted in a connection to hang on the parent transaction. When this case was reached n (where n = our max pool size) times that filled our pool with hanging connections, we'd get bursts of time that ended up degrading our service. We have health checker that will kill degraded instances, so this didn't give us complete downtime; instantiating new instances put off the problem until we reached that all-connections-in-pool-hanging state again.
We solved this by refactoring to split out the concurrent nested transaction from the parent (they weren't actually dependent on each other). Our initial code would have the nested transaction fail silently, leaving the parent waiting for it to finish. Also did a pass through the codebase to ensure that anywhere we were doing nested transaction calls, we were passing transactions properly.
We were able to replicate the issue in staging doing something similar to the code in the issue above, so I'm fairly confident this was our issue; after shipping our fix below we aren't seeing the same results.
Disclaimer: may or may not understand the full intricacies of connections/transactions/pooling, so take with a grain of salt!
btroo
on 2 Aug 2019
There's always been some issues with having N concurrent transactions where N is greater than your pool.max, i forgot the specific case but you could end up with code waiting for a connection to do something to finish up the transactions but the transactions had all the connection etc.
 mickhansen
on 5 Aug 2019
mickhansen
on 5 Aug 2019
For reference my company has been running Sequelize against RDS for 4+ years with no issues, if there were ever connection issues it's cause there were actually connection issues.
mickhansen
on 5 Aug 2019
as @btroo and @mickhansen said, This issue happened when the count of concurrent transactions is greater than your pool.max. I'm trying to describe it in a simple way, Let's see what happens:
What is the connection pool?
When your application needs to retrieve data from the database, it creates a database connection. Creating this connection involves some overhead of time and machine resources for both your application and the database. Many database libraries and ORM's will try to reuse connections when possible so that they do not incur the overhead of establishing that DB connection over and over again. The pool is the collection of these saved, reusable connections that
what is concurrent transactions?
in a simple way, if you are trying to run some CRUD command in a nested transaction, it means you are using concurrent transactions. let's assume our Sequlize config is like this:
pool: {
max: 7,
min: 0,
acquire: 30000,
idle: 10000,
},
we are trying to run this command:
let nested = function() {
// here we are making a new transaction:
return db.sequelize.transaction(t1 => {
// as you see in bellow command we won't use t1 transaction
// which means our DB (in my case postgress) run below command in other transaction
// and this is where the problem lies!
// when we'll execute nested function, we'll create a concurrent transaction per each call
return db.user.findOne();
});
};
const arr = [];
for (let i = 0; i < 7; i++) {
arr.push(nested());
}
Promise.all(arr)
.then(() => {
console.log('done');
})
.catch(err => {
console.log(err);
});
The workaround is just run _db.user.findOne()_ in t1 transaction to avoid concurrent transactions and it will be fixed:
db.user.findOne({transaction: t1})
you can also use continuation-local-storage to pass transaction automatically, just check below link:
https://sequelize.org/master/manual/transactions.html#concurrent-partial-transactions
 derakhshanfar
on 21 Aug 2019
derakhshanfar
on 21 Aug 2019
In pool settings just keep the minimum count to about 2 to 4.
This solved the issue for me.
pool: {
max: 7,
min: 2,
acquire: 30000,
idle: 10000,
},
 ashutoshpw
on 9 Sep 2019
ashutoshpw
on 9 Sep 2019
We've bumped into the same error. It's weird, but we don't have any transactions in that piece of code. It looks like a bunch of asynchronous queries to the DB, two of them use
sequelize.query()to query data and the rest 8 are made with models. I don't know why exactly, but calling one of the.query()after the others resolved somehow fixed the issue. So, we first run all those 9 queries simultaneously, and after they resolved we run the latest one. Only this worked for us.
Thanks, Your solution solved my issue.
 hrabizadeh
on 29 Dec 2019
hrabizadeh
on 29 Dec 2019
I don't understand how solving acquire timeout errors is fixed by reducing the timeout from the default of 60 seconds to 20?
https://github.com/sequelize/sequelize/issues/7884#issuecomment-313853545
edit: because the default is actually 10 sec... not sure where I saw a default of 60
 intellix
on 29 May 2020
intellix
on 29 May 2020
I don't understand how solving acquire timeout errors is fixed by reducing the timeout from the default of 60 seconds to 20?
edit: because the default is actually 10 sec... not sure where I saw a default of 60
I guess the key here is that 2 connections are never released ("min: 2")...
 val-pidburtnyi
on 1 Sep 2020
val-pidburtnyi
on 1 Sep 2020
Looks like the acquire timeout is 60 seconds in sequelize v5 and v6.
 johnfazzietempus
on 21 Oct 2020
johnfazzietempus
on 21 Oct 2020
Related issues
mickhansen
·
3Comments
 moatazelmasry2
·
3Comments
moatazelmasry2
·
3Comments
 Pomax
·
3Comments
Pomax
·
3Comments
 haikyuu
·
3Comments
haikyuu
·
3Comments
 davidleureka
·
3Comments
davidleureka
·
3Comments
Most helpful comment
I have fixed the issue by maximizing the acquire option of pool configuration in sequelize
I guess Amazon RDS runs a lot of checks when asking for resources.
Also I am running the Free Tier of Amazon RDS.