Hi,
in Sentry i can sort by First Seen, Frequency, etc. but i cannot sort by user.
I know, detecting unique users can be hard, but the numbers are there already, when i can sort by user it would give me at least some hint how many people are affected.
A bug that happened for 10k users once is in my view more important than a bug that a happened 10k times for two user :)
PS: keep up the great work, sentry is great!
 karli2000
karli2000
All 11 comments
 ehfeng
on 17 May 2016
ehfeng
on 17 May 2016
What if we just implemented it like this:

 benvinegar
on 1 Jun 2016
benvinegar
on 1 Jun 2016
++
And what is the status of?
 mordaha
on 4 Mar 2017
mordaha
on 4 Mar 2017
The user count that's displayed in the stream view is derived from the GroupTagKey (sentry_grouptagkey table) record. As far as I can tell, the biggest blocker here is that there is no index that would satisfy this query. Most (maybe all?) of the other sort clauses are directly off indexed[1] columns on the sentry_groupedmessage table.
There are a couple of options:
- If we wanted to implement arbitrary threshold filters (as well as sorting choices) on the number of distinct times any tag value — not just user — has been seen, we'd probably want to create an index similar to
(project_id, key, values_seen DESC)on thesentry_grouptagkeytable. - If we only wanted to index the user tag for a sort clause, we could do that with a partial index, at least for PostgreSQL.
Regardless, we'd have to create some additional index on this table in either case which could potentially be expensive. I do think this is a potentially useful feature, but not sure offhand what the cost of creating this index would be on write operations or on disk utilization.
 tkaemming
on 10 Mar 2017
tkaemming
on 10 Mar 2017
Interested to hear if there has been any progress with this. Sorting by users still is one prominent wish for us and would greatly improve our work with Sentry.
 tow-ableton
on 4 Apr 2019
tow-ableton
on 4 Apr 2019
Indeed. My organization judges issue severity by number of users impacted, rather than total occurrences.
 chrismerck
on 6 Aug 2019
chrismerck
on 6 Aug 2019
I don't really understand why is this complicated? Cleary, when I do an API call to issue the response, does have userCount field. Can you just include this to you Sentry CLI then?
 chocnut
on 13 Dec 2019
chocnut
on 13 Dec 2019
Anyways, I just made a small script for me to use. Let me know if anyone want this happy to share it. I hope the sentry team can add this as their feature.
chocnut
on 13 Dec 2019
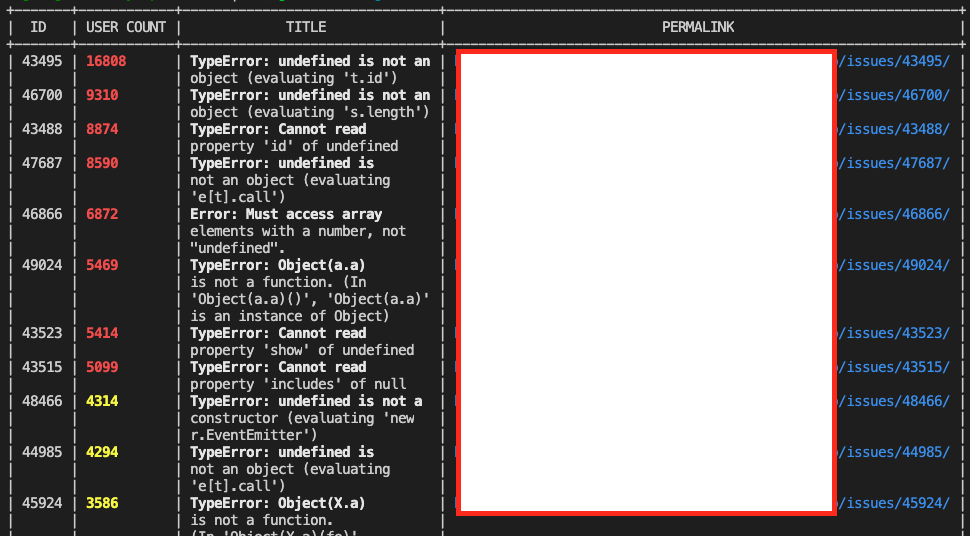
Here is the script that I've been using to get the details out that I need, sorted by users affected:
curl -H 'Authorization: Bearer $SENTRY_TOKEN' $SENTRY_DOMAIN/api/0/projects/$ORGANIZATION/$PROJECT/issues/ | \
jq -r '[.[] | {id: .id, title: .title, count: .count | tonumber, users: .userCount, firstSeen: .firstSeen, lastSeen: .lastSeen, culprit: .culprit, filename: .metadata.filename, link: .permalink}] | sort_by(-.users)' | \
in2csv -f json > /tmp/errors.csv
Relies on jq and csvkit. If you want the output similar to @chocnut, instead of redirecting to a file, pipe to csvlook -y 0
 rjnienaber
on 4 Mar 2020
rjnienaber
on 4 Mar 2020
Can't believe this was raised in 2016 and not yet addressed.
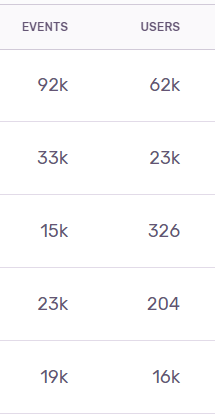
When ordered by Frequency there are cases when the error rate per user is higher than some other issues. For example on the screenshot below the 3rd highest had 15k events from 326 users where as the 5th most frequent issue had 19k events from 16k users. I would think that most people would prioritize the 19k events from 16k users issue rather then the 15k events from 326 users issue.
 mpspencer
on 10 Mar 2020
mpspencer
on 10 Mar 2020
Anyone who still interested in or looking for a tool. Please check my repo here
chocnut
on 19 Mar 2020
Related issues
 fatagun
·
4Comments
fatagun
·
4Comments
 bruno-garcia
·
3Comments
benvinegar
·
4Comments
bruno-garcia
·
3Comments
benvinegar
·
4Comments
 Leroygirl
·
3Comments
Leroygirl
·
3Comments
 gocarlos
·
3Comments
gocarlos
·
3Comments
Most helpful comment
Indeed. My organization judges issue severity by number of users impacted, rather than total occurrences.