I know this feature has been suggested before as part of #479. My use case is however a bit different.
I suggest to put a normalization factor in the kdeplot function. When looking at a subset of data, I would like to scale the KDE to normalize to the fraction of included data. Now you get something like the figure below, where blue is the total data set and green/orange are two subsets of my data. If we could include a normalization parameter, we can match the KDE's of the subsets to the KDE of the total set.

 Dimchord
Dimchord
All 5 comments
This is actually a duplicate of a very old issue: #61
 mwaskom
on 5 Apr 2018
mwaskom
on 5 Apr 2018
No, it is an entirely different issue. That issue is about setting the Axis limits.
Dimchord
on 5 Apr 2018
I am having the same issue, and it is not related to the issue #61.
Please consider the following minimal example:
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
####################
data1 = np.random.rand(100)/100 + 1
data2 = np.random.rand(100)/100 - 1
tot_data = np.concatenate((data1, data2))
plt.figure()
sns.kdeplot(tot_data)
plt.title('only total data')
plt.figure()
sns.kdeplot(tot_data)
sns.kdeplot(data1)
sns.kdeplot(data2)
plt.title('total data with separate subsets')
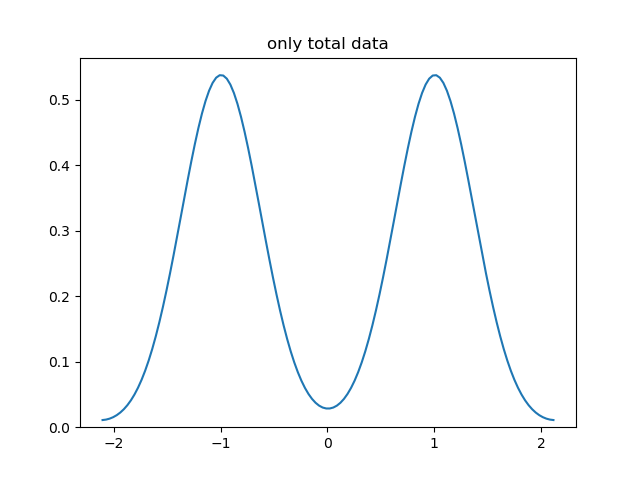
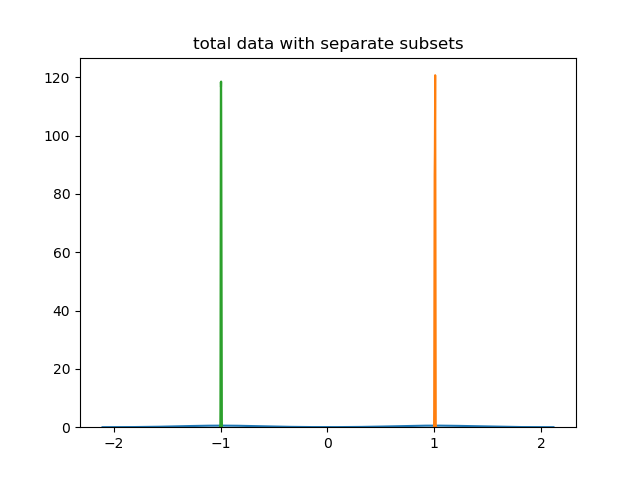
Changing the normalisation factor would allow for a graph on which one could show qualitative features of both the total dataset and its subsets.
 snoopyhunter2
on 28 Nov 2018
snoopyhunter2
on 28 Nov 2018
You don’t want to change the vertical normalization, you want to change the bandwidth. But also think hard about what you’re trying to accomplish by using a Gaussian kernel density estimate here.
mwaskom
on 28 Nov 2018
You are right of course, in a quantitative way of thinking it makes absolutely no sense to rescale a kde.
However, apart from being used to quantitatively estimate probability density functions, showing the kde is also a handy way to highlight some qualitative properties of the data's distribution.
For this second application, it is my feeling that "rescaling" the kde would be a useful feature here. In particular, my aim is to plot the kdes of different subsets of a larger dataset in one graph, which is not very helpful if some of the subsets are very localised and others are more spread out.
Indeed, I could also play around with the bandwidth, thanks for that suggestion.
snoopyhunter2
on 28 Nov 2018
Related issues
 amelio-vazquez-reina
·
4Comments
amelio-vazquez-reina
·
4Comments
 phantom0301
·
3Comments
phantom0301
·
3Comments
 stonebig
·
4Comments
stonebig
·
4Comments
 btyukodi
·
3Comments
btyukodi
·
3Comments
 sofiatti
·
4Comments
sofiatti
·
4Comments