Runtime: API Proposal: Add Intel hardware intrinsic functions and namespace
This proposal adds intrinsics that allow programmers to use managed code (C#) to leverage Intel® SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, AVX, AVX2, FMA, LZCNT, POPCNT, BMI1/2, PCLMULQDQ, and AES instructions.
Rationale and Proposed API
Vector Types
Currently, .NET provides System.Numerics.Vector<T> and related intrinsic functions as a cross-platform SIMD interface that automatically matches proper hardware support at JIT-compile time (e.g. Vector<T> is size of 128-bit on SSE2 machines or 256-bit on AVX2 machines). However, there is no way to simultaneously use different size Vector<T>, which limits the flexibility of SIMD intrinsics. For example, on AVX2 machines, XMM registers are not accessible from Vector<T>, but certain instructions have to work on XMM registers (i.e. SSE4.2). Consequently, this proposal introduces Vector128<T> and Vector256<T> in a new namespace System.Runtime.Intrinsics
namespace System.Runtime.Intrinsics
{
// 128 bit types
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct {}
// 256 bit types
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct {}
}
This namespace is platform agnostic, and other hardware could provide intrinsics that operate over them. For instance, Vector128<T> could be implemented as an abstraction of XMM registers on SSE capable processor or as an abstraction of Q registers on NEON capable processors. Meanwhile, other types may be added in the future to support newer SIMD architectures (i.e. adding 512-bit vector and mask vector types for AVX-512).
Intrinsic Functions
The current design of System.Numerics.Vector abstracts away the specifics of processor details. While this approach works well in many cases, developers may not be able to take full advantage of the underlying hardware. Intrinsic functions allow developers to access full capability of processors on which their programs run.
One of the design goals of intrinsics APIs is to provide one-to-one correspondence to Intel C/C++ intrinsics. That way, programmers already familiar with C/C++ intrinsics can easily leverage their existing skills. Another advantage of this approach is that we leverage the existing body of documentation and sample code written for C/C++ instrinsics.
Intrinsic functions that manipulate Vector128/256<T> will be placed in a platform-specific namespace System.Runtime.Intrinsics.X86. Intrinsic APIs will be separated to several static classes based-on the instruction sets they belong to.
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
public static bool IsSupported {get;}
// __m256 _mm256_add_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_add_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> Add(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
// __m256 _mm256_addsub_ps (__m256 a, __m256 b)
[Intrinsic]
public static Vector256<float> AddSubtract(Vector256<float> left, Vector256<float> right) { throw new NotImplementedException(); }
// __m256d _mm256_addsub_pd (__m256d a, __m256d b)
[Intrinsic]
public static Vector256<double> AddSubtract(Vector256<double> left, Vector256<double> right) { throw new NotImplementedException(); }
......
}
}
Some of intrinsics benefit from C# generic and get simpler APIs:
// Sse2.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse
{
public static bool IsSupported {get;}
// __m128 _mm_castpd_ps (__m128d a)
// __m128i _mm_castpd_si128 (__m128d a)
// __m128d _mm_castps_pd (__m128 a)
// __m128i _mm_castps_si128 (__m128 a)
// __m128d _mm_castsi128_pd (__m128i a)
// __m128 _mm_castsi128_ps (__m128i a)
[Intrinsic]
public static Vector128<U> StaticCast<T, U>(Vector128<T> value) where T : struct where U : struct { throw new NotImplementedException(); }
......
}
}
Each instruction set class contains an IsSupported property which stands for whether the underlying hardware supports the instruction set. Programmers use these properties to ensure that their code can run on any hardware via platform-specific code path. For JIT compilation, the results of capability checking are JIT time constants, so dead code path for the current platform will be eliminated by JIT compiler (conditional constant propagation). For AOT compilation, compiler/runtime executes the CPUID checking to identify corresponding instruction sets. Additionally, the intrinsics do not provide software fallback and calling the intrinsics on machines that has no corresponding instruction sets will cause PlatformNotSupportedException at runtime. Consequently, we always recommend developers to provide software fallback to remain the program portable. Common pattern of platform-specific code path and software fallback looks like below.
if (Avx2.IsSupported)
{
// The AVX/AVX2 optimizing implementation for Haswell or above CPUs
}
else if (Sse41.IsSupported)
{
// The SSE optimizing implementation for older CPUs
}
......
else
{
// Scalar or software-fallback implementation
}
The scope of this API proposal is not limited to SIMD (vector) intrinsics, but also includes scalar intrinsics that operate over scalar types (e.g. int, short, long, or float, etc.) from the instruction sets mentioned above. As an example, the following code segment shows Crc32 intrinsic functions from Sse42 class.
// Sse42.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Sse42
{
public static bool IsSupported {get;}
// unsigned int _mm_crc32_u8 (unsigned int crc, unsigned char v)
[Intrinsic]
public static uint Crc32(uint crc, byte data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u16 (unsigned int crc, unsigned short v)
[Intrinsic]
public static uint Crc32(uint crc, ushort data) { throw new NotImplementedException(); }
// unsigned int _mm_crc32_u32 (unsigned int crc, unsigned int v)
[Intrinsic]
public static uint Crc32(uint crc, uint data) { throw new NotImplementedException(); }
// unsigned __int64 _mm_crc32_u64 (unsigned __int64 crc, unsigned __int64 v)
[Intrinsic]
public static ulong Crc32(ulong crc, ulong data) { throw new NotImplementedException(); }
......
}
}
Intended Audience
The intrinsics APIs bring the power and flexibility of accessing hardware instructions directly from C# programs. However, this power and flexibility means that developers have to be cognizant of how these APIs are used. In addition to ensuring that their program logic is correct, developers must also ensure that the use of underlying intrinsic APIs are valid in the context of their operations.
For example, developers who use certain hardware intrinsics should be aware of their data alignment requirements. Both aligned and unaligned memory load and store intrinsics are provided, and if aligned loads and stores are desired, developers must ensure that the data are aligned appropriately. The following code snippet shows the different flavors of load and store intrinsics proposed:
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* address) { throw new NotImplementedException(); }
......
[Intrinsic]
public static Vector256<T> Load<T>(ref T vector) where T : struct { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadAligned(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_load_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* address) { throw new NotImplementedException(); }
......
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> LoadDqu(sbyte* address) { throw new NotImplementedException(); }
// __m256i _mm256_lddqu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> LoadDqu(byte* address) { throw new NotImplementedException(); }
......
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_storeu_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void Store(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
public static void Store<T>(ref T vector, Vector256<T> source) where T : struct { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_store_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAligned(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(sbyte* address, Vector256<sbyte> source) { throw new NotImplementedException(); }
// void _mm256_stream_si256 (__m256i * mem_addr, __m256i a)
[Intrinsic]
public static unsafe void StoreAlignedNonTemporal(byte* address, Vector256<byte> source) { throw new NotImplementedException(); }
......
}
}
IMM Operands
Most of the intrinsics can be directly ported to C# from C/C++, but certain instructions that require immediate parameters (i.e. imm8) as operands deserve additional consideration, such as pshufd, vcmpps, etc. C/C++ compilers specially treat these intrinsics which throw compile-time errors when non-constant values are passed into immediate parameters. Therefore, CoreCLR also requires the immediate argument guard from C# compiler. We suggest an addition of a new "compiler feature" into Roslyn which places const constraint on function parameters. Roslyn could then ensure that these functions are invoked with "literal" values on the const formal parameters.
// Avx.cs
namespace System.Runtime.Intrinsics.X86
{
public static class Avx
{
......
// __m256 _mm256_blend_ps (__m256 a, __m256 b, const int imm8)
[Intrinsic]
public static Vector256<float> Blend(Vector256<float> left, Vector256<float> right, const byte control) { throw new NotImplementedException(); }
// __m256d _mm256_blend_pd (__m256d a, __m256d b, const int imm8)
[Intrinsic]
public static Vector256<double> Blend(Vector256<double> left, Vector256<double> right, const byte control) { throw new NotImplementedException(); }
// __m128 _mm_cmp_ps (__m128 a, __m128 b, const int imm8)
[Intrinsic]
public static Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
// __m128d _mm_cmp_pd (__m128d a, __m128d b, const int imm8)
[Intrinsic]
public static Vector128<double> Compare(Vector128<double> left, Vector128<double> right, const FloatComparisonMode mode) { throw new NotImplementedException(); }
......
}
}
// Enums.cs
namespace System.Runtime.Intrinsics.X86
{
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
......
}
Semantics and Usage
The semantic is straightforward if users are already familiar with Intel C/C++ intrinsics. Existing SIMD programs and algorithms that are implemented in C/C++ can be directly ported to C#. Moreover, compared to System.Numerics.Vector<T>, these intrinsics leverage the whole power of Intel SIMD instructions and do not depend on other modules (e.g. Unsafe) in high-performance environments.
For example, SoA (structure of array) is a more efficient pattern than AoS (array of structure) in SIMD programming. However, it requires dense shuffle sequences to convert data source (usually stored in AoS format), which is not provided by Vector<T>. Using Vector256<T> with AVX shuffle instructions (including shuffle, insert, extract, etc.) can lead to higher throughput.
public struct Vector256Packet
{
public Vector256<float> xs {get; private set;}
public Vector256<float> ys {get; private set;}
public Vector256<float> zs {get; private set;}
// Convert AoS vectors to SoA packet
public unsafe Vector256Packet(float* vectors)
{
var m03 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[0])); // load lower halves
var m14 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[4]));
var m25 = Avx.ExtendToVector256<float>(Sse2.Load(&vectors[8]));
m03 = Avx.Insert(m03, &vectors[12], 1); // load higher halves
m14 = Avx.Insert(m14, &vectors[16], 1);
m25 = Avx.Insert(m25, &vectors[20], 1);
var xy = Avx.Shuffle(m14, m25, 2 << 6 | 1 << 4 | 3 << 2 | 2);
var yz = Avx.Shuffle(m03, m14, 1 << 6 | 0 << 4 | 2 << 2 | 1);
var _xs = Avx.Shuffle(m03, xy, 2 << 6 | 0 << 4 | 3 << 2 | 0);
var _ys = Avx.Shuffle(yz, xy, 3 << 6 | 1 << 4 | 2 << 2 | 0);
var _zs = Avx.Shuffle(yz, m25, 3 << 6 | 0 << 4 | 3 << 2 | 1);
xs = _xs;
ys = _ys;
zs = _zs;
}
......
}
public static class Main
{
static unsafe int Main(string[] args)
{
var data = new float[Length];
fixed (float* dataPtr = data)
{
if (Avx2.IsSupported)
{
var vector = new Vector256Packet(dataPtr);
......
// Using AVX/AVX2 intrinsics to compute eight 3D vectors.
}
else if (Sse41.IsSupported)
{
var vector = new Vector128Packet(dataPtr);
......
// Using SSE intrinsics to compute four 3D vectors.
}
else
{
// scalar algorithm
}
}
}
}
Furthermore, conditional code is enabled in vectorized programs. Conditional path is ubiquitous in scalar programs (if-else), but it requires specific SIMD instructions in vectorized programs, such as compare, blend, or andnot, etc.
public static class ColorPacketHelper
{
public static IntRGBPacket ConvertToIntRGB(this Vector256Packet colors)
{
var one = Avx.Set1<float>(1.0f);
var max = Avx.Set1<float>(255.0f);
var rsMask = Avx.Compare(colors.xs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var gsMask = Avx.Compare(colors.ys, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var bsMask = Avx.Compare(colors.zs, one, FloatComparisonMode.GreaterThanOrderedNonSignaling);
var rs = Avx.BlendVariable(colors.xs, one, rsMask);
var gs = Avx.BlendVariable(colors.ys, one, gsMask);
var bs = Avx.BlendVariable(colors.zs, one, bsMask);
var rsInt = Avx.ConvertToVector256Int(Avx.Multiply(rs, max));
var gsInt = Avx.ConvertToVector256Int(Avx.Multiply(gs, max));
var bsInt = Avx.ConvertToVector256Int(Avx.Multiply(bs, max));
return new IntRGBPacket(rsInt, gsInt, bsInt);
}
}
public struct IntRGBPacket
{
public Vector256<int> Rs {get; private set;}
public Vector256<int> Gs {get; private set;}
public Vector256<int> Bs {get; private set;}
public IntRGBPacket(Vector256<int> _rs, Vector256<int> _gs, Vector256<int>_bs)
{
Rs = _rs;
Gs = _gs;
Bs = _bs;
}
}
As previously stated, traditional scalar algorithms can be accelerated as well. For example, CRC32 is natively supported on SSE4.2 CPUs.
public static class Verification
{
public static bool VerifyCrc32(ulong acc, ulong data, ulong res)
{
if (Sse42.IsSupported)
{
return Sse42.Crc32(acc, data) == res;
}
else
{
return SoftwareCrc32(acc, data) == res;
// The software implementation of Crc32 provided by developers or other libraries
}
}
}
Implementation Roadmap
Implementing all the intrinsics in JIT is a large-scale and long-term project, so the current plan is to initially implement a subset of them with unit tests, code quality test, and benchmarks.
The first step in the implementation would involve infrastructure related items. This step would involve wiring the basic components, including but not limited to internal data representations of Vector128<T> and Vector256<T>, intrinsics recognition, hardware support checking, and external support from Roslyn/CoreFX. Next steps would involve implementing subsets of intrinsics in classes representing different instruction sets.
Complete API Design
Add Intel hardware intrinsic APIs to CoreFX dotnet/corefx#23489
Add Intel hardware intrinsic API implementation to mscorlib dotnet/corefx#13576
Update
08/17/2017
- Change namespace
System.Runtime.CompilerServices.IntrinsicstoSystem.Runtime.IntrinsicsandSystem.Runtime.CompilerServices.Intrinsics.X86toSystem.Runtime.Intrinsics.X86. - Change ISA class name to match CoreFX naming convention, e.g., using
Avxinstead ofAVX. - Change certain pointer parameter names, e.g., using
addressinstead ofmem. - Define
IsSupportas properties. - Add
Span<T>overloads to the most common memory-access intrinsics (Load,Store,Broadcast), but leave other alignment-aware or performance-sensitive intrinsics with original pointer version. - Clarify that these intrinsics will not provide software fallback.
- Clarify
Sse2class design and separate small calsses (e.g.,Aes,Lzcnt, etc.) into individual source files (e.g.,Aes.cs,Lzcnt.cs, etc.). - Change method name
CompareVector*toCompareand get rid ofCompareprefix fromFloatComparisonMode.
08/22/2017
- Replace
Span<T>overloads byref Toverloads.
09/01/2017
- Minor changes from API code review.
12/21/2018
- All the proposed APIs are enabled in .NET Core runtime.
 fiigii
fiigii
All 181 comments
cc: @russellhadley @mellinoe @CarolEidt @terrajobst
fiigii
on 4 Aug 2017
Overall I love this proposal. I do have a few questions/comments:
Each vector type exposes an IsSupported method to check if the current hardware supports
I think this can be a property, as it is in Vector<T>.
Does this take the type of T into account? For example, will IsSupported return true for Vector128<float> but false for Vector128<CustomStruct> (or is it expected to throw in this case)?
What about formats that may be supported on some processors, but not others? As an example, lets say there is instruction set X which only supports Vector128<float> and later comes instruction set Y which supports Vector128<double>. If the CPU currently only supports X would it return true for Vector128<float> and false for Vector128<double> with Vector128<double> only returning true when instruction set Y is supported?
In addition, this namespace would contain conversion functions between the existing SIMD type (Vector
) and new Vector128 and Vector256 types.
My concern here is the target layering for each component. I would hope that System.Runtime.CompilerServices.Intrinsics are part of the lowest layer, and therefore consumable by all other APIs in CoreFX. While Vector<T>, on the other hand, is part of one of the higher layers and is therefore not consumable.
Would it be better here to either have the conversion operators on Vector<T> or to expect the user to perform an explicit load/store (as they will likely be expected to do with other custom types)?
SSE2.cs (the bottom-line of intrinsic support that contains all the intrinsics of SSE and SSE2)
I understand that with SSE and SSE2 being required in RyuJIT this makes sense, but I would almost prefer an explicit SSE class to have a consistent separation. I would essentially expect a 1-1 mapping of class to CPUID flag.
Other.cs (includes LZCNT, POPCNT, BMI1, BMI2, PCLMULQDQ, and AES)
For this specifically, how would you expect the user to check which instruction subsets are supported? AES and POPCNT are separate CPUID flags and not every x86 compatible CPU may always provide both.
Some of intrinsics benefit from C# generic and get simpler APIs
I didn't see any examples of scalar floating-point APIs (_mm_rsqrt_ss). How would these fit in with the Vector based APIs (naming wise, etc)?
 tannergooding
on 4 Aug 2017
tannergooding
on 4 Aug 2017
Looks good and in line with the suggestions I have made. The only thing that probably do not resonate with me (maybe because we deal with pointers on a regular basis on our codebase) is having to use Load(type*) instead of supporting also the ability to call the function with a void* as the semantics of the operation are very clear. Probably it is me, but with the exception of special operations like a non-temporal store (where you would need to use a Store/Load operation explicitely) not having support for arbitrary pointer types would only add bloat to the algorithm without any actual improvement in readability/understandability.
 redknightlois
on 4 Aug 2017
redknightlois
on 4 Aug 2017
Therefore, CoreCLR also requires the immediate argument guard from C# compiler.
Going to tag @jaredpar here explicitly. We should get a formal proposal up.
I think that we can do this without language support (@jaredpar, tell me if I'm crazy here) if the compiler can recognize something like System.Runtime.CompilerServices.IsLiteralAttribute and emits it as modreq isliteral.
Having a new recognized keyword (const) here is likely more complicated as it requires formal spec'ing in the language etc.
tannergooding
on 4 Aug 2017
Thanks for posting this @fiigii. I'm very eager to hear everyone's thoughts on the design.
IMM Operands
One thing that came up in a recent discussion is that some immediate operands have stricter constraints than just "must be constant". The examples given use a FloatComparisonMode enum, and functions accepting it apply a const modifier to the parameter. But there is no way to prevent someone from passing a non-enum value, still a constant, to a method accepting that parameter.
`AVX.CompareVector256(left, right, (FloatComparisonMode)255);
EDIT: This warning is emitted in a VC++ project if you use the above code.
Now, this may not be a problem for this particular example (I'm not familiar with its exact semantics), but it's something to keep in mind. There were also other, more esoteric examples given, like an immediate operand which must be a power of two, or which satisfies some other obscure relation to the other operands. These constraints will be much more difficult, most likely impossible, to enforce at the C# level. The "const" enforcement feels more reasonable and achievable, and seems to cover most instances of the problem.
SSE2.cs (the bottom-line of intrinsic support that contains all the intrinsics of SSE and SSE2)
I'll echo what @tannergooding said -- I think it will be simpler to just have a distinct class for each instruction set. I'd like for it to be very obvious how and where new things should be added. If there's a "grab bag" sort of type, then it becomes a bit murkier and we have to make lots of unnecessary judgement calls.
 mellinoe
on 4 Aug 2017
mellinoe
on 4 Aug 2017
💭 Most of my initial thoughts go to the use of pointers in a few places. Knowing what we know about ref structs and Span<T>, what parts of the proposal can leverage new functionality to avoid unsafe code without compromising performance.
❓ In the following code, would the generic method actually be expanded to each of the forms allowed by the processor, or would it be defined in coed as a generic?
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
// __m128 _mm_add_ps (__m128 a, __m128 b)
// __m128d _mm_add_pd (__m128d a, __m128d b)
[Intrinsic]
public static Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right) where T : struct { throw new NotImplementedException(); }
 sharwell
on 4 Aug 2017
sharwell
on 4 Aug 2017
❓ If the processor doesn't support something, do we fall back to simulated behavior or do we throw exceptions? If we choose the former, would it make sense to rename IsSupported to IsHardwareAccelerated?
sharwell
on 4 Aug 2017
Knowing what we know about ref structs and Span
, what parts of the proposal can leverage new functionality to avoid unsafe code without compromising performance.
Personally, I am fine with the unsafe code. I don't believe this is meant to be a feature that app designers use and is instead meant to be something framework designers use to squeeze extra performance and also to simplify overhead on the JIT.
People using intrinsics are likely already doing a bunch of unsafe things already and this just makes it more explicit.
If the processor doesn't support something, do we fall back to simulated behavior or do we throw exceptions?
The official design doc (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) indicates that it is up in the air whether software fallbacks are allowed.
I am of the opinion that all of these methods should be declared as extern and should never have software fallbacks. Users would be expected to implement a software fallback themselves or have a PlatformNotSupportedException thrown by the JIT at runtime.
This will help ensures the consumer is being aware of the underlying platforms they are targeting and that they are writing code that is "suited" for the underlying hardware (running vectorized algorithms on hardware without vectorization support can cause performance degradation).
tannergooding
on 4 Aug 2017
If the processor doesn't support something, do we fall back to simulated behavior or do we throw exceptions?
The official design doc (https://github.com/dotnet/designs/blob/master/accepted/platform-intrinsics.md) indicates that it is up in the air whether software fallbacks are allowed.
These are the raw CPU platform intrinsics e.g. X86.SSE so PNS is probably fine; and will help get them out quicker.
Assuming the detection is branch eliminated; it should be easy to build a library on top that then does software fallbacks, which can be iterated on (either coreclr/corefx or 3rd party)
 benaadams
on 4 Aug 2017
benaadams
on 4 Aug 2017
Personally, I am fine with the unsafe code.
I am not against unsafe code. However, given the choice between safe code and unsafe code that perform the same, I would choose the former.
I am of the opinion that all of these methods should be declared as extern and should never have software fallbacks.
The biggest advantage of this is the runtime can avoid shipping software fallback code that never needs to execute.
The biggest disadvantage of this is test environments for the various possibilities are not easy to come by. Fallbacks provide a functionality safety net in case something gets missed.
sharwell
on 4 Aug 2017
The biggest disadvantage of this is test environments for the various possibilities are not easy to come by.
@sharwell, what possibilities are you envisioning?
The way these are currently structured, proposed, the user would code:
C#
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
Under this, the only way a user is faulted is if they write a bad algorithm or if they forget to provide any kind of software fallback (and an analyzer to detect this should be fairly trivial).
tannergooding
on 4 Aug 2017
running vectorized algorithms on hardware without vectorization support can cause performance degradation.
I would rephrase @tannergooding thought into: "running vectorized algorithms on hardware without vectorization support will with utmost certainty cause performance degradation."
redknightlois
on 4 Aug 2017
For this specifically, how would you expect the user to check which instruction subsets are supported? AES and POPCNT are separate CPUID flags and not every x86 compatible CPU may always provide both.
@tannergooding We defined an individual class for each instruction set (except SSE and SSE2) but put certain small classes into the Other.cs file. I will update the proposal to clarify.
// Other.cs
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class LZCNT
{
......
}
public static class POPCNT
{
......
}
public static class BMI1
{
.....
}
public static class BMI2
{
......
}
public static class PCLMULQDQ
{
......
}
public static class AES
{
......
}
}
AOT compilation, however, the compiler generates CPUID checking code that would return different values each time it is called (on different hardware).
I don't think this needs to be true all the time. In some cases, the AOT can drop the check altogether, depending on the target operating system (Win8 and above require SSE and SSE2 support, for example).
In other cases, the AOT can/should drop the check from each method and should instead aggregate them into a single check at the highest entry point.
Ideally, the AOT would run CPUID once during startup and cache the results as globals (honestly, if the AOT didn't do this, I would log a bug). The IsSupported check then becomes essentially a lookup of the cached value (just like a property normally behaves). This behavior is what the CRT implementations do to ensure that things like cos(double) remain performant and that they can still run FMA3 code where supported.
tannergooding
on 4 Aug 2017
For AOT compilation, however, the compiler generates CPUID checking code that would return different values each time it is called (on different hardware).
The implication would be from a usage perspective:
For Jit we could be quite granular on the checks as they are no-cost branch eliminated.
For AOT we'd need to be quite course on the checks and perform it at algorithm or library level, to offset the cost of CPUID; which may push it much higher than intended e.g. you wouldn't use a vectorized IndexOf; unless your strings were huge because CPUID would dominate.
Probably could still cache on AOT in startup, so it would set the property; it wouldn't branch eliminate, but would be fairly low cost?
benaadams
on 4 Aug 2017
I understand that with SSE and SSE2 being required in RyuJIT this makes sense, but I would almost prefer an explicit SSE class to have a consistent separation. I would essentially expect a 1-1 mapping of class to CPUID flag.
I think it will be simpler to just have a distinct class for each instruction set. I'd like for it to be very obvious how and where new things should be added. If there's a "grab bag" sort of type, then it becomes a bit murkier and we have to make lots of unnecessary judgement calls.
@tannergooding @mellinoe The current design intent of class SSE2 is to make more intrinsic functions friendly to users. If we had two classes SSE and SSE2, certain intrinsics would loose the generic signature. For example, SIMD addition only supports float in SSE, and SSE2 complements other types.
public static class SSE
{
// __m128 _mm_add_ps (__m128 a, __m128 b)
public static Vector128<float> Add(Vector128<float> left, Vector128<float> right);
}
public static class SSE2
{
// __m128i _mm_add_epi8 (__m128i a, __m128i b)
public static Vector128<byte> Add(Vector128<byte> left, Vector128<byte> right);
public static Vector128<sbyte> Add(Vector128<sbyte> left, Vector128<sbyte> right);
// __m128i _mm_add_epi16 (__m128i a, __m128i b)
public static Vector128<short> Add(Vector128<short> left, Vector128<short> right);
public static Vector128<ushort> Add(Vector128<ushort> left, Vector128<ushort> right);
// __m128i _mm_add_epi32 (__m128i a, __m128i b)
public static Vector128<int> Add(Vector128<int> left, Vector128<int> right);
public static Vector128<uint> Add(Vector128<uint> left, Vector128<uint> right);
// __m128i _mm_add_epi64 (__m128i a, __m128i b)
public static Vector128<long> Add(Vector128<long> left, Vector128<long> right);
public static Vector128<ulong> Add(Vector128<uint> left, Vector128<ulong> right);
// __m128d _mm_add_pd (__m128d a, __m128d b)
public static Vector128<double> Add(Vector128<double> left, Vector128<double> right);
}
Comparing to SSE2.Add<T>, the above design looks complex, and users have to remember SSE.Add(float, float) and SSE2.Add(int, int). Additionally, SSE2 is the bottom-line of RyuJIT code generation for x86/x86-64, seperating SSE from SSE2 has no advatage on functionality or convenience.
Although the current design (class SSE2 including SSE and SSE2 intrinsics) hurts API consistency, there is a trade-off between design consistency and user experience, which is worth discussing.
fiigii
on 4 Aug 2017
Rather than X86 maybe x86x64 as x86 is often used to donate 32-bit only?
benaadams
on 4 Aug 2017
Very excited we are finally seeing a proposal for this. My initial thoughts below.
AVX-512 is missing, probably since it is not that widespread yet, but I think it would be good to at least give this some thought and how to structure these because AVX-512 feature set is very fragmented. In this case I would assume we need to have a class for each set i.e. (see https://en.wikipedia.org/wiki/AVX-512):
public static class AVX512F {} // Foundation
public static class AVX512CD {} // Conflict Detection
public static class AVX512ER {} // Exponential and Reciprocal
public static class AVX512PF {} // Prefetch Instructions
public static class AVX512BW {} // Byte and Word
public static class AVX512DQ {} // Doubleword and Quadword
public static class AVX512VL {} // Vector Length
public static class AVX512IFMA {} // Integer Fused Multiply Add (Future)
public static class AVX512VBMI {} // Vector Byte Manipulation Instructions (Future)
public static class AVX5124VNNIW {} // Vector Neural Network Instructions Word variable precision (Future)
public static class AVX5124FMAPS {} // Fused Multiply Accumulation Packed Single precision (Future)
and add a struct Vector512<T> type, of course. Note that the latter two AVX5124VNNIW and AVX5124FMAPS are hard to read due to number 4.
Some of these can have a huge impact for deep learning, sorting etc.
Regarding Load I have some concerns as well. As @redknightlois I think void* should be considered too, but more importantly also load from/store to ref. Given this, perhaps these should be relocated to the "generic"/platform-agnostic namespace and type, since assumably all platforms should support load/store for a supported vector size. So something like (not sure where we could put this, and how naming should be done, if it can be moved to platform agnostic type.
[Intrinsic]
public static unsafe Vector256<sbyte> Load(sbyte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadSByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(byte* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<sbyte> LoadByte(void* mem) { throw new NotImplementedException(); }
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException(); }
// Etc.
The most important thing here is if ref can be supported as it would be essential for supporting generic algorithms. Naming should be revised no doubt, but just trying to make a point. If we want to support load from void* method name needs to include return type or method needs to be on type specific static class.
 nietras
on 4 Aug 2017
nietras
on 4 Aug 2017
It's great we are discussing a concrete proposal right now. 😄
The above linked
const keyword usagelanguage proposal was created explicitly to provide support for some of SIMD instructions requiring immediate parameters. I think it will be straightforward to implement but since it may delay introduction of intrinsics there were strong arguments in favor of going with simple attribute implementation first and later expand C# syntax and API by including support forconst method parameters.IMO we have to discuss in parallel forward looking designs which comprise two different areas:
System.Numerics APIwhich can bepartially implementedwith support of discussed here x86 intrinsicsIntrinsics APIwhich should comprise other architectures as well as this will have an impact on final shape of the intrinsics API
Intrinsics
Namespace and assembly
I would propose to move intrinsics to separate namespace located relatively high in hierarchy and each platform specific code into separate assembly.
System.Intrinsics general top level namespace for all intrinsics
System.Intrinsics.X86 x86 ISA extensions and separate assembly
System.Intrinsics.Arm ARM ISA extensions and separate assembly
System.Intrinsics.Power Power ISA extensions and separate assembly
System.Intrinsics.RiscVRiscV ISA extensions and separate assembly
Reason for the above division is large API area for every instruction set i.e. AVX-512 will be represented by more than 2 000 intrinsics in MsVC compiler. This same will be true for ARM SVE very soon (see below). Size of the assembly due to string content only won't be small.
Register sizes (currently XMM, YMM, ZMM - 128, 256, 512 bits in x86)
Current implementations support limited set of register sizes:
- 128, 256, 512 bits in x86
- 128 in ARM Neon and IBM Power 8 and Power 9 ISA
However, ARM recently published:
ARM SVE - Scalable Vector Extensions
see: The Scalable Vector Extension (SVE), for ARMv8-A published on 31 March 2017 with status Non-Confidential Beta.
This specification is quite important as it introduces new register sizes - altogether there are 16 register sizes which are multiples of 128 bits. Details are on page 21 of the specification (table is below).
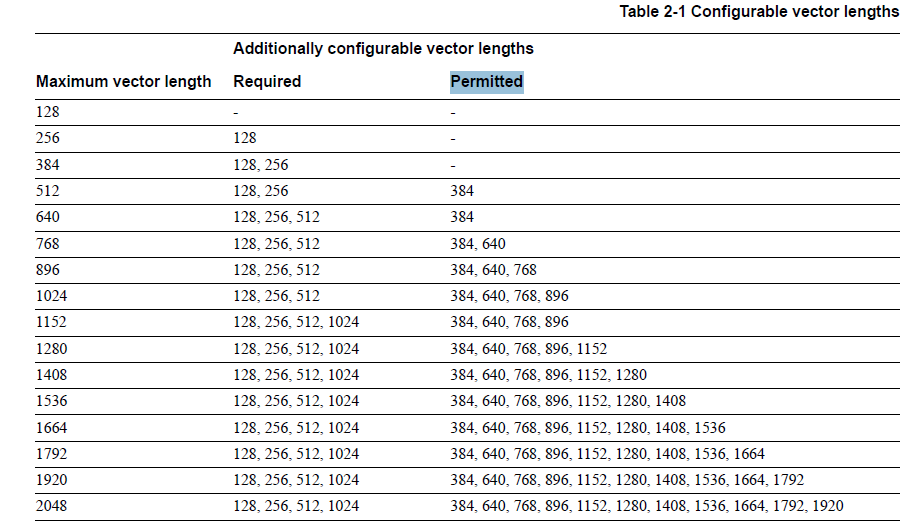
Maximum vector length: 2048 bits
Required vector lengths: 128, 256, 512, 1024 bits
Permitted vector lengths: 384, 640, 768, 896, 1152, 1280, 1408, 1536, 1664, 1792, 1920
It would be necessary to design API which is capable to support in near future 16 different register sizes and several thousands (or tens of thousands) of opcodes/functions (counting with overloads). Predictions of not having 2048 bit SIMD instructions in couple of years seems to have been falsified to anyone's surprise by ARM this year. Looking at history (ARM published public beta of ARMv8 ISA on 04 September 2013 and first processor implementing it was available to users globally in October 2014 - Samsung Galaxy Note 4) I would expect that first silicon with SVE extensions will be available in 2018. I suppose this would be most probably very close in time to public availability of DotNet SIMD intrinsics.
I would like to propose:
Vectors
Implement basic Vectors supporting all register sizes in System.CoreLib.Private
```C#
namespace System.Numerics
{
[StructLayour(LayoutKind.Explicit)]
public unsafe struct Register128
{
[FieldOffset(0)]
public fixed byte [16];
.....
// accessors for other types
}
// ....
[StructLayour(LayoutKind.Explicit)]
public unsafe struct Register2048
{
[FieldOffset(0)]
public fixed byte [256];
.....
// accessors for other types
}
public struct Vector<T, R> where T, R: struct
{
}
public struct Vector128<T> : Vector<T, Register128>
{
}
// ....
public struct Vector2048<T> : Vector<T, Register2048>
{
}
}
### System.Numerics
All safe APIs would be exposed via Vector<T> and VectorXXX<T> structures and implemented with support of intrinsics.
### System.Intrinsics
All vector APIs will use System.Numerics.VectorXXX<T>.
```C#
public static Vector128<byte> MultiplyHigh<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
public static Vector128<byte> MultiplyLow<Vector128<byte>>(Vector128<byte> value1, Vector128<byte> value2);
Intrinsics APIs will be placed in separate classes according to functionality detection patterns provided by processors. In case of x86 ISA this would be one to one correspondence between CPUID detection and supported functions. This would allow for easy to understand programming pattern where one would use functions from given group in way consistent with platform support.
Main reason for that kind of division is a requirement set by silicon manufacturers to use instructions only if they are detected in hardware. This allows for example to ship processor with support matrix comprising SSE3 but not SSSE3, or comprising PCLMULQDQ and SHA and not AESNI. This direct class - hardware support detection correspondence is the only safe way of having IsHardwareSupported detection and be compliant with Intel/AMD instruction usage restrictions. Otherwise kernel will have to catch for us #UD exception 😸
Mapping APIs to C/C++ intrinsics or to ISA opcodes
Intrinsics abstract usually in 1 to 1 way ISA opcodes however there are some intrinsics which map to several instructions. I would prefer to abstract opcodes (using nice names) and implement multi opcode intrinsics as functions on VectorXxx
 4creators
on 4 Aug 2017
4creators
on 4 Aug 2017
@nietras
Given this, perhaps these should be relocated to the "generic"/platform-agnostic namespace and type, since assumably all platforms should support load/store for a supported vector size.
The best place would be System.Numerics.VetorXxx<T>
4creators
on 4 Aug 2017
all platforms should support load/store for a supported vector size
Is the platform agnostic Load/Store any different from the existing Unsafe.Read/Write?
 jkotas
on 4 Aug 2017
jkotas
on 4 Aug 2017
Is the platform agnostic Load/Store any different from the existing Unsafe.Read/Write?
@jkotas I had the same thought, how do those tie in with Unsafe? I assume these would be unaligned then, and we can only use aligned via LoadAligned/StoreAligned...
Or could we add Unsafe.ReadAligned/WriteAligned and have the JIT recognize these for the vector types?
nietras
on 4 Aug 2017
IsSupported should be a property (or a static readonly field) like IntPtr.Size or BitConverter.IsLittleEndian.
Combining SSE and SSE2 into a single class looks like a good trade-off for a simpler Add function.
Like @redknightlois and @nietras I'm also concerned about the Load/Store API. ref support is needed to avoid fixed references. For void* Load/Store generics could help:
[Intrinsic]
public static extern unsafe Vector256<T> Load<T>(void* mem) where T : struct;
[Intrinsic]
public static extern unsafe Vector256<sbyte> Load(sbyte* mem);
[Intrinsic]
public static extern Vector256<sbyte> Load(ref sbyte mem);
[Intrinsic]
public static extern unsafe Vector256<byte> Load(byte* mem);
[Intrinsic]
public static extern Vector256<byte> Load(ref byte mem);
// Etc.
Looking forward to using PDEP/PEXT!
 pentp
on 4 Aug 2017
pentp
on 4 Aug 2017
I would propose to move intrinsics to separate namespace located relatively high in hierarchy and each platform specific code into separate assembly.
Reason for the above division is large API area for every instruction set i.e. AVX-512 will be represented by more than 2 000 intrinsics in MsVC compiler. This same will be true for ARM SVE very soon (see below). Size of the assembly due to string content only won't be small.
@4creators, I am vehemently against moving this feature higher in the hierarchy.
For starters, the runtime itself has to support any and all intrinsics (including the strings to identify them, etc) regardless of where we put them in the hierarchy. If the runtime doesn't support them, then you can't use them.
I also want to be able to consume these intrinsics from all layers of the stack, including System.Private.CoreLib. I want to be able to write managed implementations of System.Math, System.MathF, various System.String functions, etc. Not only does this increase maintainability of the code (since most of these are FCALLS or hand tuned assembly today) but it also increases cross-platform consistency (where the resulting FCALL or assembly is part of the underlying C runtime).
tannergooding
on 4 Aug 2017
@pentp
Combining SSE and SSE2 into a single class looks like a good trade-off for a simpler Add function.
I do not think that intrinsics should abstract anything - instead simple add can be created on Vector128 - Vector2048. On the other hand it would be openly against Intel usage recommendations.
4creators
on 4 Aug 2017
I also want to be able to consume these intrinsics from all layers of the stack, including System.Private.CoreLib. I want to be able to write managed implementations of System.Math, System.MathF, various System.String functions, etc.
@tannergooding Agree that it has to be available from System.Private.CoreLib
However it doesn't mean that it has to be low in hierarchy. No one will ship runtime (vm, gc, jit) which will support all intrinsics for all architectures. Division line goes through ISA plane - x86, Arm, Power. There is no reason to ship ARM intrinsics on x86 runtime. Having it in separate platform assembly in coreclr which could be referenced (circularly) by System.Private.CoreLib could be a solution (I think that a bit better than ifdefing everything)
4creators
on 4 Aug 2017
The current design intent of class SSE2 is to make more intrinsic functions friendly to users. If we had two classes SSE and SSE2, certain intrinsics would loose the generic signature.
@fiigii, why does separating these out mean we lose the generic signature?
The way I see it, we have two options:
- Explicitly lists the types out
Vector128<float> Add(Vector128<float> left, Vector128<float> right)
- This enforces type safety but increases the number of exposed APIs
- Use generics
Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right)
- This decreases the number of exposed APIs but loses the enforced compiler type safety
- Some functions will require multiple generics (casts, for example, require
<T, U>, and this can potentially become even more complex elsewhere)
I see no reason why we can't have SSE and SSE2 and why we can't just have both expose Vector128<T> Add<T>(Vector128<T> left, Vector128<T> right).
That being said, I personally prefer the enforced form that requires additional APIs to be listed. Not only does this help enforce that the user is passing the right things down to the API, but it also decreases the number of checks the JIT must do.
Vector128<float> means T has already been enforced/validated as part of the API contract, Vector128<T> means the JIT must validate T is of a correct/supported type. This could potentially change from one runtime to the next (depending on the exact set of intrinsics the runtime was built to support) which can make this even more confusing.
tannergooding
on 4 Aug 2017
However it doesn't mean that it has to be low in hierarchy. No one will ship runtime (vm, gc, jit) which will support all intrinsics for all architectures. Division line goes through ISA plane - x86, Arm, Power. There is no reason to ship ARM intrinsics on x86 runtime. Having it in separate platform assembly in coreclr which could referenced (circularly) by System.Private.CoreLib could be a solution.
I could get behind this. The caveats being that:
- The reference assembly has to list all the APIs regardless
- The JIT probably needs special support so that it doesn't throw an exception when it tries to compile my function (which has paths for x86 and ARM) on one of the architectures and it doesn't find the APIs for the other architecture.
tannergooding
on 4 Aug 2017
Is the platform agnostic Load/Store any different from the existing Unsafe.Read/Write?
@jkotas, I think the primary difference is that Load/Store will compile down to a SIMD instruction and will likely go directly into a register for most cases.
tannergooding
on 4 Aug 2017
Having it in separate platform assembly in coreclr which could be referenced (circularly) by System.Private.CoreLib could be a solution
Circular references are non-starter. The existing solution for this problem is to have a subset required by CoreLib in CoreLib as internal, and the full blown (duplicate) implementation in separate assembly. Though, it is questionable whether this duplication in the sake of layering is really worth it.
Another thought about naming. The runtime/codegen has many intrinsics today all over the place, for example methods on System.Threading.Interlocked or System.Runtime.CompilerServices.RuntimeHelpers are implemented as intrinsics.
Should the namespace name be more specific to capture what actually goes into it, say System.Runtime.HardwareIntrinsics?
jkotas
on 4 Aug 2017
Code bloat due to Register128 ... Register2048 design
Providing we would like to have direct access to numeric types encoded in RegisterXxx structures - similar to current System.Numerics.Register implementation which is IMO a good design - one would need to create (rather generate) total of 10 064 fields with the following pattern:
```C#
namespace System.Numerics
{
[StructLayout(LayoutKind.Explicit)]
public unsafe struct Register128
{
public fixed byte Reg[16];
// System.Byte Fields
[FieldOffset(0)]
public byte byte_0;
[FieldOffset(1)]
public byte byte_1;
[FieldOffset(2)]
public byte byte_2;
// System.SByte Fields
// etc.
Specifically due to this problem there exists solution proposal based on extended generics syntax: _Const blittable parameter as a generic type parameter_ (https://github.com/dotnet/csharplang/issues/749)
```C#
namespace System.Numerics
{
public unsafe struct Register<T, const int N>
{
public fixed T Reg[N];
}
public struct Vector128<T> : Vector<T, Register<T, 16>> {}
Later by specialising generics one can easily create required struct tree.
4creators
on 4 Aug 2017
Load/Store will compile down to a SIMD instruction and will likely go directly into a register for most cases.
Unsafe.Load/Store compiles into a SIMD instruction for the right sized structs today.
jkotas
on 4 Aug 2017
Circular references are non-starter. The existing solution for this problem is to have a subset required by CoreLib in CoreLib as internal, and the full blown (duplicate) implementation in separate assembly. Though, it is questionable whether this duplication in the sake of layering is really worth it.
@jkotas @tannergooding This settles this problem since duplicate implementation for API comprising roughly 10k functions ...
4creators
on 4 Aug 2017
Unsafe.Load/Store compiles into a SIMD instruction for the right sized structs today.
This may be the case implicitly, but it is not explicit in the API (which is the case for Vector128<float> SSE.Load(float* address)). It is also implicit on whether this is an aligned read/write or if it is unaligned.
One of my favorite features of this proposal is that the APIs are very explicit. If I say LoadAligned, I know that I am going to get the MOVAPS instruction (with no "ifs" "ands", or "buts" about it). If I say LoadUnaligned, I know I am going to get the MOVUPS instruction.
tannergooding
on 4 Aug 2017
Should the namespace name be more specific to capture what actually goes into it, say System.Runtime.HardwareIntrinsics
Simple calculation for assembly size difference for functions defined as
C#
public static void System.Runtime.CompilerServices.Intrinsics.AVX2::ShiftLeft
public static void System.Intrinsics.AVX2::ShiftLeft
for 5 000 functions is 250 KB.
4creators
on 4 Aug 2017
duplicate implementation for API comprising roughly 10k functions ...
The stuff duplicated in CoreLib would be just say the 50 functions that are actually needed in CoreLib.
jkotas
on 4 Aug 2017
for 5 000 functions is 250 KB.
How did you come up with this number? The namespace name is stored in the managed binary just once. The difference between ShortNameSpace and VeryLoooooooooooooooooongNameSpace should be always ~20 bytes, independent on how many functions are contained in the namespace.
jkotas
on 4 Aug 2017
The stuff duplicated in CoreLib would be just say the 50 functions that are actually needed in CoreLib.
This would solve the problem of shipping all architectures together 😄
4creators
on 4 Aug 2017
As to all the statements around things like exposing ref or void* (@pentp, @nietras, @redknightlois) and also as to whether or not a software fallback should be provided.
ref might be worth exposing
Unsafe.ToPointersolves part of this but requires users to take a separate dependency. It also means thatcorlibhas more trouble dealing withref
void* is probably not worth exposing. Just cast to the appropriate type (float*)((void*)(p)).
- We can't override based on return type so
void*means we either need unique method names or we have to use<T>and have the JIT perform validation
It may already be obvious by my existing statements, but I believe these APIs should be explicit but also simple:
- We should use
Vector128<float>instead ofVector128<T>as this enforces compile time checks and removes JIT overhead - We should have APIs like
LoadandStoreas part of this and not rely on things elsewhere (System.Runtime.CompilerServices.Unsafe).
- The other APIs, where applicable, should be updated to call the intrinsic functions instead
- We should enforce all functions to be
extern
- If software fallbacks were provided,
CoreFXitself would/should never use them - Due to perf and other reasons, consumers should never rely on or use the software fallbacks anyways
- This enforces the JIT/AOT to understand the method or have it fail
- We can always expose a wrapper API at a higher level (read as
CoreFXExtensionsor third party repo) that provides software fallbacks for each instruction
- If software fallbacks were provided,
tannergooding
on 4 Aug 2017
How did you come up with this number?
@jkotas from CIL spec which states that CIL does not have implementation of namespaces and recognises methods by their full name, however, I understand I should check PE file specs - my bad.
4creators
on 4 Aug 2017
Rather than X86 maybe x86x64 as x86 is often used to donate 32-bit only?
@benaadams, In the same veign x86-64 is sometimes used to denote the 64-bit only version of the x86 instruction set, so this would be confusing as well (https://en.wikipedia.org/wiki/X86-64)
I think that x86 makes the most sense and is used most frequently to refer to the entire platform.
At least for Wikipedia:
- x86 refers to the 16, 32, and 64-bit implementations (https://en.wikipedia.org/wiki/X86)
- IA-32 or i386 refers to the 32-bit implementation (https://en.wikipedia.org/wiki/IA-32)
- It is sometimes referred to as x86
- x86-64, x64, x86_64, AMD64, and Intel64 are used to refer to the 64-bit implementation (https://en.wikipedia.org/wiki/X86-64)
tannergooding
on 4 Aug 2017
It seems it won't be simple API and it would require multiple design decisions - is it possible to start working on details of it in CoreFXLabs or separate branch in coreclr/corefx?
Separate repo would support issue tracking system which IMO would be needed to get it done fast and efficiently.
4creators
on 4 Aug 2017
It seems it won't be a simple API and it would require multiple design decisions - is it possible to start working on details of it in CoreFXLabs or separate branch in coreclr/corefx?
I'm going to second this. I think it would be worthwhile to get the basic API shape (as proposed) up in CoreFXLabs and to "use" it in a real-scenario.
I would propose we take Vector2, Vector3, and Vector4 and reimplement them to call the APIs as per https://github.com/Microsoft/DirectXMath and potentially do the same for Cos, Sin, and Tan in Math/MathF.
Although we won't get any perf numbers from this and we won't be able to run the code, it will let us view the use case in "real-world" scenarios to get a better feel for what makes the most sense and what the strengths/deficiencies of the proposal (and any suggested modifications to the proposal).
tannergooding
on 4 Aug 2017
Although we won't get any perf numbers
To get perf numbers, it should be fine to add some support for this in the JIT (without exposing it in the stable shipping profile) and experiment with the API shape in corefxlab.
jkotas
on 4 Aug 2017
Unsafe.ToPointer solves part of this
@tannergooding leaving a GC hole or requiring pinning, which is specifically what we want to avoid ;) ref is essential for generic Span<T> based algorithms, without the need for pinning. Unsafe.Read/Write should work too. I want both apples ;)
We should have APIs like Load and Store as part of this and not rely on things elsewhere (System.Runtime.CompilerServices.Unsafe).
Agreed, and I am not saying that. But Unsafe.Read/Write<Vector128<T>> should still work. That is a must in my view. Otherwise, generic code becomes very difficult, which can handle different vector registers, basic types etc.
nietras
on 4 Aug 2017
💭 ❓ Would these new vector types be candidates for being ref struct instead of just struct?
sharwell
on 4 Aug 2017
void* is probably not worth exposing. Just cast to the appropriate type (float)((void)(p)).
@tannergooding you can't do that in generic code. I think it would be good to consider algorithms that are generic too, lots of things could be done here in a generic way exposing many numerical operations on say images without the need for a hand tailored loop for each operation. There are many many cases where generic code could be made with this.
nietras
on 4 Aug 2017
I don't see any issue with an API with static methods for void* e.g.
public class Vector128<T>
{
public static Vector128<T> Load(void* p);
}
The JIT of course has to handle this, but shouldn't that be rather straightforward. My assumption here is that if Vector128<T>.IsSupported then you must be able to Load and Store so these do not have to be in platform specific places.
If they do, then yes we need something like Vector<128> SSE2.LoadInt(void* p) and in some cases even AVX512VL.LoadInt256(void* p) maybe... ugly naming aside. Otherwise, out could be a fallback although it makes code cumbersome, less so with C# 7.
void* p = ...;
AVX512VL.LoadAligned(p, out Vector256<int> v);
It is not that much more cumbersome when viewed from this. And hopefully has no perf issues.
nietras
on 4 Aug 2017
Don't think void* is needed? Just a ref version. Can convert void* to ref with Unsafe.AsRef
e.g.
void* input;
ref Unsafe.AsRef<Vector<short>>(input);
Don't think void* is needed? Just a ref version.
Yes I could live with that, in fact I would go as far as say why have any pointer versions at all. These should solely be based on ref. A pointer can easily be converted to a ref and this way all scenarios are supported (pointers, span, refs, Unsafe etc.). And without any perf issues I imagine.
namespace System.Runtime.CompilerServices.Intrinsics.X86
{
public static class AVX
{
......
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<sbyte> Load(ref sbyte mem) { throw new NotImplementedException(); }
// __m256i _mm256_loadu_si256 (__m256i const * mem_addr)
[Intrinsic]
public static unsafe Vector256<byte> Load(ref byte mem) { throw new NotImplementedException();
......
}
Usage with pointer would be a little more cumbersome, but not a big deal for me.
nietras
on 4 Aug 2017
Well, this definition would still not support generic scenario out-of-the-box, though, we need it on the type proper for that Vector256<T> for that, but with Unsafe this can be circumvented. I would still prefer to have Vector256<T>.Load(ref T mem) since this makes generic programming easier.
nietras
on 4 Aug 2017
@nietras The signature I want to think we can get away with is this:
[Intrinsic]
public static Vector256<sbyte> Load(in Vector256<sbyte> mem);
In this case the generic form should work as well:
[Intrinsic]
public static Vector256<T> Load<T>(in Vector256<T> mem);
The JIT of course has to handle this, but shouldn't that be rather straightforward. My assumption here is that if Vector128
.IsSupported then you must be able to Load and Store so these do not have to be in platform specific places.
I think the assumption here is correct. However, there are multiple ways to "Load" a value and those may not always be consistent across platforms.
You have aligned and unaligned. But there may be a platform that requires alignment, in which case, Unaligned is then inapplicable for use under Vector128<T>. So now we have some load methods on Vector128<T> and some under SSE and it breaks consistency.
You also have various load/store instructions that are clearly platform specific like non-temporal, masked, shuffle, broadcast, etc.
My opinion is that Vector128<T> (and the other register types) should be completely opaque. Users should not be able to use the register itself for anything other than the IsSupported check and should be strictly required to use intrinsics to load/store/manipulate/etc. The only special case here is the debugger which should have a special type to display relevant register data.
This enforces the intrinsic model, ensures that nothing is special cased, helps prevent future breaks if we support new hardware that behaves differently, etc.
tannergooding
on 4 Aug 2017
Here a pretty simple example of the generic transform I could imagine. And a pattern I have shown many times here 😄
public interface IVectorFunc<T>
{
T Invoke(T a, T b);
Vector128<T> Invoke(Vector128<T> a, Vector128<T> b);
Vector256<T> Invoke(Vector256<T> a, Vector256<T> b);
Vector512<T> Invoke(Vector512<T> a, Vector512<T> b);
}
public static void Transform<T, TFunc>(Span<T> a, Span<T> b, TFunc func, Span<T> result)
where TFunc : IVectorFunc<T>
{
// Check span equal sizes
var length = a.Length;
ref var refA = ref a.DangerousGetPinnableReference();
ref var refB = ref a.DangerousGetPinnableReference();
ref var refRes = ref a.DangerousGetPinnableReference();
int i = 0;
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
for (; i < length; ++i)
{
var va = Unsafe.Add(ref refA, i);
var vb = Unsafe.Add(ref refB, i);
Unsafe.Add(ref refRes, i) = func.Invoke(va, vb);
}
}
Now this can, of course, be written entirely with Unsafe.Read/Write/AsRef if this is supported, but for optimal performance one could check alignment before and use Vector256<T>.LoadAligned etc. instead.
nietras
on 4 Aug 2017
Now this can, of course, be written entirely with Unsafe.Read/Write/AsRef
I would think that Unsafe.Read/Write is going to be the recommendation for generic algorithms. Yes, you may lose a bit of performance. It is the cost of doing business for writing generic algorithms.
but for optimal performance one could check alignment
For optimal performance, you may also want to use non-temporal loads or other platform specific load variants...
jkotas
on 4 Aug 2017
but for optimal performance one could check alignment before and use Vector256
.LoadAligned etc. instead.
@nietras @jkotas On current processors and even couple of generations back there is no need to check alignment as instructions used to load and store check for alignment and in the case data are aligned there is 0 cycle performance penalty in comparison to instructions specialised for aligned data. Code which will check for alignment would penalize with several cycles implementation. This is specific for xmm, ymm, zmm registers and corresponding instructins.
4creators
on 4 Aug 2017
Probably my void* example was misinterpreted. I was using void* as placeholder, the one that accept whatever you throw using the intended representation for it at the instruction level.
@benaadams Problem is you cannot do pointer arithmetic over references. That means that code that does pointer arithmetic will become bloated with calls to ref Unsafe.AsRef<Vector<short>>(input); every time a new translation happens. Probably I am missing something but thinking on the kind of algorithms I tend to work with, I can guess how bad that could become.
@nietras In the prototype code you need the "runtime" version so you can pass the type to the function. But if you drop that to do lets say just add, the code would be far simpler for the common Load/Store cases (I am explicitly avoiding the case of non-temporal kinds here). Simpler code -> less bugs -> better life over time.
redknightlois
on 4 Aug 2017
Unsafe.Read/Write is going to be the recommendation for generic algorithms. may lose a bit of performance
Ok, but what if aligned access is only supported? How do we detect this? We can have three scenarios for Unsafe perhaps.
|Alignment | Unaligned Only*| Aligned Only | Both |
|-----|----|----|----|
|Unsafe.Read/Write|Unaligned |Aligned|Unaligned|
|VectorXXX
|VectorXXX
In the case of aligned only, how do we determine if we have to align first? Maybe this is theoretical, but if the VectorXXX<T> types would have properties saying what is possible then this would be a minimum for general methods with these, bare minimum e.g. VectorXXX<T>.UnalignedSupported or something.
In fact, as a broader question how can I ask in a simple way I can check which architecture I am running i.e. enum Arch { x86, Arm, etc. }
With just a bare minimum of general/overall methods a lot of opportunities are opened up without having us users to go through hoops to do this.
@4creators aren't some of ARM vector instructions aligned only? Not sure haven't done much ARM stuff. Hoping for ForwardCom to get some traction ;)
@tannergooding yes lots of ways to load/store/broadcast/shuffle but I think some common very basic ground would be good. Not having this makes a lot of basic things difficult.
nietras
on 4 Aug 2017
On current processors and even couple of generations back thee is no need to check alignment as instructions used to load and store check for alignment and in the case data are aligned there is 0 cycle performance penalty in comparison to instructions specialised for aligned data.
@4creators, that may be the case for modern Intel/Amd processors, but that may not be the case for all processors (older Intel/AMD, possibly ARM, possibly future hardware).
tannergooding
on 4 Aug 2017
In the prototype code you need the "runtime" version so you can pass the type to the function. But if you drop that to do lets say just add, the code would be far simpler for the common Load/Store cases
@redknightlois sorry you completely lost me there? 💥 😄 This would mean implementing many differenct VectorFuncs e.g. ThresholdVectorFunc, AddVectorFunc etc.
nietras
on 4 Aug 2017
@nietras Sorry I wasn't clear enough. What I meant was that with that code, the objective explicitly requires to have a Vector<T> or Vector<float> so it can be passed down to a function for operation. The use of void* as placeholder would allow you to execute with the platform safe Load an operation straight from its pointer and avoid the many instances of ref Unsafe.Add(ref r, i) there are in the prototype function which with the current proposal requires the generation of a ref instance and or loading of a Vector<T> explicitly instead of just passing the pointer.
redknightlois
on 4 Aug 2017
@nietras ForwardCom with all respect for Agner Fog for his work is lost case since RiscV got enough traction to essentially wipe out all competition (other unis with competing architectures were really upset about this). If RiscV gets implemented in silicon by some bigger players we may start to think how to port our code from 64 bit to 128 bit architecture 😄
4creators
on 4 Aug 2017
@tannergooding yes lots of ways to load/store/broadcast/shuffle but I think some common very basic ground would be good. Not having this makes a lot of basic things difficult.
@nietras, I think in both cases (providing general load/store intrinsics on VectorXXX<T> and providing platform specific intrinsics such as SSE.Load) you have to have some kind of IsSupported check (either on VectorXXX<T> or on SSE). If it isn't supported, you have to provide a software fallback yourself (assuming intrinsic functions don't have a software fallback, both to keep it simple and to keep it performant).
So, in either case, you end up writing some code like:
```C#
if (X.IsSupported)
{
// Copy Vector512
}
if (Y.IsSupported)
{
// Copy Vector256
}
if (Z.IsSupported)
{
// Copy Vector128
}
// Copy remaining (probably using Unsafe)
```
The primary difference being whether the intrinsics are explicit (SSE.Load) or implicit (VectorXXX
tannergooding
on 4 Aug 2017
use of void* as placeholder
@redknightlois if I understand you correctly, I am explicitly avoiding pointer and fixed here to support both managed and unmanaged memory and avoid obstructing the GC. Yes no doubt the code would be leaner using pointers directly... but that's not really the issue here. I am fine with how it looks, it's generic option I would like.
@tannergooding yes of course there would be checks here i.e. (@redknightlois Unsafe. can be removed here with a using static):
if (Vector512<T>.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = Vector512<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector512<T>.Load(ref Unsafe.Add(ref refB, i));
Vector512<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = Vector256<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector256<T>.Load(ref Unsafe.Add(ref refB, i));
Vector256<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (Vector256<T>.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Vector128<T>.Load(ref Unsafe.Add(ref refA, i));
var vb = Vector128<T>.Load(ref Unsafe.Add(ref refB, i));
Vector128<T>.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
As a minimum. Probably also have to check VectorXXX<T>.AlignmentSupport { Aligned, Unaligned }, but with just these few general methods, this kind of code becomes immensely simpler to do. Yes, it is not ideal for highly highly optimized scenarios but for 80-90% of basic numerical processing it is damn good, compared to a normal one element at a time loop.
nietras
on 4 Aug 2017
I am not sure I am making myself clear here. But think of the possibilities here and the combinatorial power of this, instead of 1000 custom loops with code in them, I have one generic loop and 1000s of small funcs. The assembly becomes much smaller, we use less memory, and only the actual combinations used are JIT'ed at runtime or even at AOT.
Much less code, far fewer bugs, and many many combinations can done.
It is the combinatorial power that comes from a few key algorithms Transform/ForEach/InPlaceTransform etc. x dimensions (1D, 2D, 3D, tensors etc.) x 1000s funcs == 10-100.000 combinations. Yes, many will be less performant than a custom loop, but much better than average home made loops.
1000s of funcs is no doubt exagerated. 😉
nietras
on 4 Aug 2017
that may be the case for modern Intel/Amd processors, but that may not be the case for all processors (older Intel/AMD, possibly ARM, possibly future hardware).
@tannergooding not really - 0 cycle penalty is true for all AVX, AVX2, AVX512 and SSE implementations back to Nehalem microarchitecture (I have stopped checking at this point as Microsoft does not fully support Windows Vista).
aren't some of ARM vector instructions aligned only?
@nietras I have not checked yet - but there are so many ARM implementations ... - IMO in general we should not provide LoadAligned/Unaligned, StoreAligned/Unaligned on x86 as the penalty of working on aligned or unaligned intrinsics is not there, obviously, it does not mean that unaligned data will move as fast as aligned. By introducing them we ask developers implicitly to check alignment before using them and if they see in IntelliSense that there is Load/Store instruction as well, it will be treated as not optimal one.
I would generalize this problem to other question: How do we map intrinsics to x86 ISA instructions? Or do we map intrinsics to C/C++ instrinsics?
Problem of overloads and generics is a one part of the discussion but decision has to be made about mapping of the instructions per se. Do we map 1 to 1, do we map 1 to ... . Do we expose all instructions, even those we know are legacy ones and not performant, or do we expose everything except those instructions which were replaced by better implementations. We are not bound by legacy code compiled to x86 as Intel and AMD are.
4creators
on 4 Aug 2017
We are not bound by legacy code compiled to x86 as Intel and AMD are.
CoreCLR might not be, but CoreCLR is also not the only runtime. There is also CoreRT, Mono, several other AOT implementations (some even used for developing managed operating systems).
CoreFX is not tied 1-to-1 with CoreCLR, it has to be useable on all of these.
If I know (for certain) my structures are aligned, I should be able to write my algorithm to explicitly use aligned instructions. If I know my structures might be unaligned, I should have the option to either check alignment and use the appropriate instruction or to just use the unaligned instructions (knowing that on old/legacy platforms there might be a slight perf hit).
I am all for user choice here and making it open to the users to write the algorithms the way they feel is best for their target platforms.
tannergooding
on 4 Aug 2017
@tannergooding @4creators I will agree with you that on modern Intel based architectures, that the costs of aligned vs unaligned accesses are the same; there are definite cases where things will go off a cliff (cache line splits currently), and as vectors get wider even in the best cases splits will happen due to cache line granularity. So, from a design point perspective applying to more than just mainstream Intel based architectures, supporting aligned and unaligned forms of instructions. Intrinsics (at least natively) have no safety net. It is healthy to debate whether all of the ISA needs to be exposed as intrinsics just as on the native side. It's a matter of utility vs completeness. :)
 jarodrig
on 4 Aug 2017
jarodrig
on 4 Aug 2017
@nietras: I am trying to understand how this:
```C#
if (Vector512
{
for (; i < length - Vector512
{
var va = Vector512
var vb = Vector512
Vector512
}
}
if (Vector256
{
for (; i < length - Vector256
{
var va = Vector256
var vb = Vector256
Vector256
}
}
if (Vector128
{
for (; i < length - Vector128
{
var va = Vector128
var vb = Vector128
Vector128
}
}
Is really any better than this:
```C#
if (AVX512.IsSupported)
{
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (AVX.IsSupported)
{
for (; i < length - Vector256<T>.Length; i += Vector256<T>.Length)
{
var va = AVX.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX.Load(ref Unsafe.Add(ref refB, i));
AVX.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
if (SSE.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = SSE.Load(ref Unsafe.Add(ref refA, i));
var vb = SSE.Load(ref Unsafe.Add(ref refB, i));
SSE.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
else if (Neon.IsSupported)
{
for (; i < length - Vector128<T>.Length; i += Vector128<T>.Length)
{
var va = Neon.Load(ref Unsafe.Add(ref refA, i));
var vb = Neon.Load(ref Unsafe.Add(ref refB, i));
Neon.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
}
Although realistically, for a generic use, I would probably declare custom structures that wrap load/store to be optimal:
```C#
struct Data512
{
public static Data512 Load
public static void Store
}
struct Data256
{
public static Data256 Load
public static void Store
}
struct Data128
{
public static Data128 Load
public static void Store
}
```
Or possibly even just have a CopyBlock method that abstracts all this away and does rep movsb on modern hardware (where it might be faster and will definitely be smaller).
tannergooding
on 4 Aug 2017
I am all for user choice here and making it open to the users to write the algorithms the way they feel is best for their target platforms.
Seems that if we decide to go this way we simply have to expose as much as technically possible what is entirely fine with me and I will vote for it with my both hands.
But then if we all agree we have made one of the most important design decisions which narrows our discussion to other problems.
and here comes problem of the generics and of all possible implementations ... 😄
4creators
on 4 Aug 2017
@tannergooding you can't write (just an example):
for (; i < length - Vector512<T>.Length; i += Vector512<T>.Length)
{
var va = AVX512.Load(ref Unsafe.Add(ref refA, i));
var vb = AVX512.Load(ref Unsafe.Add(ref refB, i));
AVX512.Store(ref Unsafe.Add(ref refRes, i), func.Invoke(va, vb));
}
AVX512.Load isn't generic as far as I understood you. So that won't work. And, you then need many more checks, what instruction set allows loading int vs float vs byte vs double etc. It's a combinatorial nightmare...
rep movsb I seriously doubt this will be fast, it has a pretty hefty setup cost. On some platforms at least...
nietras
on 4 Aug 2017
A couple of thoughts based on past experience with this kind of thing in native compilers:
- there is often an "impedance mismatch" between using intrinsics and intrinsic types and neighboring non-intrinsic code. So getting in data into and out of these forms needs careful consideration, especially for "thin uses" where you just want to efficiently use one or two intrinsic instructions. The code generator may also have trouble in this area (the discussion about load forms hints at this, for instance).
- implications for libraries: we don't have any way of describing how an assembly/library now may/must depend on ISA feature sets, so some thought needs to be given to how nuget, etc understand the implications of there being potentially many different packages that one might need or want to use depending on the minimum supported ISA feature set of an app. Eg your apps and libraries might need to indicate "I require xxx" or "I can take advantage of xxx" and the packaging system then would try and get you the right versions. Suitability may not be black and white, so the process of choosing the "best" library version could be complicated.
- prejitting (like we do for S.P.Corelib) currently targets the lowest supported ISA feature set and so such paths would always need fallback code or else skip any such feature-set dependent methods when prejitting and just always jit such code (similar to where we end up with vectors today) . For Full AOT fallbacks or a projective feature set / packaging solution as above would be required.
- the jit is making independent decisions about what instructions to use for codegen. This can cause various problems For instance the jit might be using AVX in a method -- if you, via intrinsics, drop an SSE2 form into an AVX stream you will suffer perf penalties. This could be seen as an "experts only" problem but it makes writing library code challenging since you cannot control the end platform or the logic the jit uses. As the jit and ISA feature sets evolve existing libraries become stale and potentially unviable. So perhaps there ought to be some way to also check or constrain what code the jit intends to generate around your intrinsic. That might be useful in partially addressing the prejitting problem as this check would always return the lowest supported ISA feature set when prejitting.
 AndyAyersMS
on 4 Aug 2017
AndyAyersMS
on 4 Aug 2017
I am trying to understand how this ..... Is really any better than this:
@tannergooding @nietras
If we expose hardware instructions in hardware specific way we should discuss AVX512.IsSupported design and leave Vector512<T> at the instrinsics assembly as an abstraction of the register only and not an abstraction of functionality available in given instruction group.
However, we can than expose this functionality quite effectively in System.Numerics with all VectorXxx having general static methods and hardware support checks what would be implemented with help of intrinsics from SSE2, AVX, AVX2 ... classes.
4creators
on 4 Aug 2017
And, you then need many more checks, what instruction set allows loading int vs float vs byte vs double etc. It's a combinatorial nightmare...
@nietras, For a simple copy algorithm (such as that one) the underlying type doesn't really matter. At least for load/store, you are just copying bits around (float and int are both 32-bits and Vector512<T> is always 512-bits, regardless of T). The type of T only comes into play when operating on the data (Sqrt, Convert, Add, etc).
If, for some reason, the type did matter, that is what abstract wrapper types (Data512, Data256, Data128) should be for. You keep the intrinsics "pure" but make it easy to use locally by wrapping the calls in other types.
tannergooding
on 4 Aug 2017
prejitting (like we do for S.P.Corelib) currently targets the lowest supported ISA feature set and so such paths would always need fallback code or else skip any such feature-set dependent methods when prejitting and just always jit such code (similar to where we end up with vectors today)
@AndyAyersMS Would it be possible to store in R2R assembly both native and IL code for intrinsics only and than if platform supports expanded ISA jit it in a way which would exploit full platform capabilities? (that was kind of universal jit dream some time ago)
4creators
on 4 Aug 2017
@AndyAyersMS...
so some thought needs to be given to how nuget, etc understand the implications of there being potentially many different packages
I don't think package management needs to be brought into this at all.
In all scenarios, users should be expected to do `If (X.IsSupported) { /* Do X / } else if (Y.IsSupported) { / Do Y / } else { / Do Software */ }
If the user decides to leave off the software fallback, it will PNSE on unsupported platforms.
prejitting (like we do for S.P.Corelib) currently targets the lowest supported ISA feature set
This and AOT fall into the same category. A single startup check for CPUID can occur and be cached, the code for all applicable paths on the architecture (all paths for x86 or all paths for Arm, currently). You can then either check the flag and jump to the appropriate implementation (as is done for the cos implementation in MSVCRT) or you can do some form of dynamic dispatch (dynamically setting the method entry point during application startup).
if you, via intrinsics, drop an SSE2 form into an AVX stream you will suffer perf penalties.
I think this, for the most part, should be considered expert territory. There is the case where a consumer calls a method that users AVX and then calls a separate method which only supports SSE.
I'm still thinking about this particular scenario, but I believe we can figure something out (it is really no different from what C/C++ run into, however).
tannergooding
on 4 Aug 2017
@tannergooding it is not a copy algorithm, the explicit purpose is to invoke a func which takes generic VectorXXX<T>, how would I then go from a "type"-less register to a typed register? I am all for having a non-generic Vector128 with load/store etc. but we still need to be able to "convert" that to a generic version Vector128<T>. And Vector128 still has the question whether it has members for load/store "independent" of say static SSE2 methods etc.
nietras
on 4 Aug 2017
@nietras regarding the void* and ref, that is all well and good when working in managed memory, but there is a need to be able to run this on _unmanaged_ memory as well.
A very common use case for reducing memory / GC costs is to NOT allocate any managed memory for the common stuff ,but rely on manual memory management. I still want to be able to do that, and in that scenario, I want to be able to do that with as little overhead as possible.
In that case, not having to call AsRef would be a very good thing (unless the JIT just erase that, which I don't think it does).
 ayende
on 4 Aug 2017
ayende
on 4 Aug 2017
not having to call AsRef would be a very good thing (unless the JIT just erase that, which I don't think it does).
@ayende the JIT will completely erase them. As far as I recall. It is a simple no-op/reinterpret cast. @jkotas can chime in. I too want this for unmanaged memory which is the main source for my use case too in production, this will support both.
nietras
on 4 Aug 2017
@AndyAyersMS Thanks for bringing these points up again -- I think they are very important to the overall story.
This and AOT fall into the same category. A single startup check for CPUID can occur and be cached, the code for all applicable paths on the architecture (all paths for x86 or all paths for Arm, currently). You can then either check the flag and jump to the appropriate implementation (as is done for the cos implementation in MSVCRT) or you can do some form of dynamic dispatch (dynamically setting the method entry point during application startup).
You are describing features that don't exist yet, though. The latter option you are describing is used in many native libraries as I understand it, but the programming model is vastly different from what we are describing here. It's not clear to me that we can match that kind of behavior given how the C# hardware intrinsics will work.
I'm still thinking about this particular scenario, but I believe we can figure something out (it is really no different from what C/C++ run into, however).
The main point was that you have very little visibility into what code the JIT will be generating around you, and that code can and will change over time. You may not be explicitly calling an AVX instruction and then an SSE instruction like in your example, but you may just be doing some unrelated work in the middle of your algorithm which the JIT decides to optimize with SSE instructions. This optimization logic is opaque and non-constant -- your library may become significantly slower after a JIT update. I think this is very different from C/C++.
I agree that "not mixing instruction sets" is something the library author will just need to understand. It is "expert territory"; perhaps the best we can do is an analyzer to catch obvious failures.
mellinoe
on 4 Aug 2017
@mellinoe True about the JITted code to be a moving target, but that is essentially what we are doing in production environments. We microoptimize and fix the runtime version until we can profile and check that everything is OK with the new version (even if it is a servicing release) because for non SIMD code we are still swimming in the same pool.
redknightlois
on 4 Aug 2017
@4creators if there is IL for a method then yes it is available to the jit at runtime. If jitting, the jit will generate what it thinks is the best possible code for the current platform. That is how Vector
Assemblies can be partially prejitted to defer codegen on methods, and potentially (NYI but something we have thought about) the runtime can decide to not use or replace prejitted code and invoke the jit instead, to try and generate more tailored code. There is a tradeoff here that can potentially be leveraged to improve perf, but how one does this today is not obvious; we don't know how much benefit can be had from jitting, how long the jit will take, or how frequently this method will be called.
One could imagine that the presence of one of these IsSupported checks in a method would give us a pretty strong hint that jitting is a good idea, so we'd either skip prejitting such methods or prejit targeting the lowest supported feature set and then decide to toss that code and jit if the end platform supports richer features.
AndyAyersMS
on 4 Aug 2017
we'd either skip prejitting such methods or prejit targeting the lowest supported feature set and then decide to toss that code and jit if the end platform supports richer features.
@AndyAyersMS IMO prejitting to lowest common denominator 2 versions of code (fallback + SSE2 to choose from at startup would allow for fast startup) and later tiered jitting could do more optimized compilation and replace old code version once it becomes hot. It would be best of two worlds first fast startup and later optimal performance. It could be one of the perfect scenarios to show real jit power. This same could be true for switching on more expensive vectorization optimizations.
There is a tradeoff here that can potentially be leveraged to improve perf, but how one does this today is not obvious; we don't know how much benefit can be had from jitting, how long the jit will take, or how frequently this method will be called.
Most probably looking at current literature trace based tiered jitting would be optimal solution.
4creators
on 4 Aug 2017
You are describing features that don't exist yet, though. The latter option you are describing is used in many native libraries as I understand it, but the programming model is vastly different from what we are describing here. It's not clear to me that we can match that kind of behavior given how the C# hardware intrinsics will work.
@mellinoe, We are also discussing this for a feature that doesn't exist yet 😄
For live JIT, the values of the CPUID are statically known and everything is fine and nothing needs to be done.
For any type of AOT (including prejit, ngen, etc) I wouldn't imagine it would be too difficult to get this stuff supported. It basically requires:
- Running CPUID at startup
- Caching the results of the CPUID check at some well known or easily accessible location (for example, we could have a dword
__is_supported_avx) - Calling
cmp DWORD PTR __is_supported_avx, 0andjne avx_implementation(with additional checks for other paths).
For the most part, these checks are trivial compared to the cost savings of the better algorithm. For cases where you don't want to do the pre-checks, you can do more complicated things like late-binding of the method address (which is also done at startup, but would likely be more complicated to support)
tannergooding
on 4 Aug 2017
The main point was that you have very little visibility into what code the JIT will be generating around you, and that code can and will change over time. You may not be explicitly calling an AVX instruction and then an SSE instruction like in your example, but you may just be doing some unrelated work in the middle of your algorithm which the JIT decides to optimize with SSE instructions. This optimization logic is opaque and non-constant -- your library may become significantly slower after a JIT update. I think this is very different from C/C++.
The JIT could probably have smarts to detect cases like this (it already has some smarts for things like clearing upper bits of the register in some cases to help with perf), or maybe we can provide an attribute that tells the JIT not to use SIMD in some cases (possibly a MethodImpl.IntrinsicWrapper hint or something that users can place on their methods so the JIT knows when it can optimize to use SSE and when it shouldn't).
tannergooding
on 4 Aug 2017
@mellinoe, We are also discussing this for a feature that doesn't exist yet 😄
Of course -- bad wording 😄 . What I meant was those AOT features are probably complicated on their own (especially the late-binding idea), and we hadn't really scoped such a solution into this feature yet. It's likely the first version will just force deferred compilation a la Vector<T>. But it is good to brainstorm a better solution for the future.
mellinoe
on 4 Aug 2017
@nietras, ah, I missed the Invoke signature completely.
That is an interesting scenario, and not one I had really considered.
You could definitely provide this with a wrapper method that handles all the various types for you (for JIT, these would still be constant) and I'm still convinced that doing that is better (keep the lowest layer "simple" and put all the pressure on the consumer, not on the runtime).
As for rep movsb, there is definitely increased cost on some platforms, but post Ivy Bridge, we have a special CPUID flag (of course with some limitations, etc, but its all documented in the optimization manual):

tannergooding
on 4 Aug 2017
@nietras @tannergooding If you have something to say about Enhanced REP mov/sto instructions, I am all ears...I am more than responsible for driving the feature into IA processors along with a few friends...
jarodrig
on 5 Aug 2017
Cosmos is an example of a Operating System that is a .Net Runtime too. All code is AOT compiled before the bootable image is created and so we are forced to choose a minimum ISA we have decided that at least SSE2 should be supported (80887 makes no sense anymore...) so returning to the Cos example what we should do:
public static double Cos(double x)
{
if (x86.FMA3.IsSupported)
{
// Do FMA3
}
else if (x86.SSE2.IsSupported)
{
// Do SSE2
}
else if (Arm.Neon.IsSupported)
{
// Do ARM
}
else
{
// Do software fallback
}
}
We can surely delete the ARM branch automatically during AOT compilation for x86 but how our compiler could be so smart to know that it should retain the SSE2 and FMA3 versions to "revalutate" these at run time (that is at OS system boot as doing those checks any time Cos is used defeats the purpose of this IMHO)?
I mean how the compiler known there are intrinsics used here and that it is supposed to do something "magic"?
 fanoI
on 5 Aug 2017
fanoI
on 5 Aug 2017
@fanol, roughly speaking, it would know to do magic the same way it knows how to do any magic. The compiler would be told that these calls are "special" and that they should be handled differently from other methods.
A more in depth explanation
When parsing IL there is, essentially, two types of methods you will come across:
- Methods which have an implementation
- Methods which are marked
extern
For both cases, there can be additional attributes that tell the compiler how to treat the method (such as inlining, internal call, intrinsic, etc).
Methods with an implementation
The vast majority of methods have actual backing implementations and just need to have their IL converted to machine code.
However, there are some methods with implementations that the compiler is expected to have special understanding of.
One example of these are the System.Runtime.Numerics.Vector types. These types have a software fallback implementation for when the compiler doesn't know to treat them specially (or if the backing hardware doesn't support the instructions required for an "optimal" implementation).
The other example is methods which have a software implementation that does nothing but throw PlatformNotSupportedExecption (as is proposed for these intrinsics).
Extern Methods
For extern methods (Math.Cos, for example) the compiler has to know how to handle it and should fail to emit if it doesn't. Most commonly this is either:
- DllImport
- MethodImplOptions.InternalCall
For DllImport, the compiler locates and loads the appropriate binary, finds the method with the matching symbol, and invokes it.
For MethodImplOptions.InternalCall, the compiler has an internal implementation somewhere that it knows to emit a call to. For example, CoreCLR has a list of mappings between these extern methods and the internal implementation that it will replace the call with. For Math.Cos, this results in a call to ComDouble::Cos which itself wraps the CRT implementation.
Some of these internal calls are further treated as "Intrinsic" and optimized to a one or more optimized machine instructions (Math.Sqrt is optimized to sqrtsd on x86 CPUs, instead of being a call to the CRT sqrt function).
Special Handling
I would expect any compiler (AOT or JIT) to have special knowledge for all the types in the System.Runtime.CompilerServices.Intrinsics namespace (this is one of the reasons I think they should be marked with extern, rather than have a software implementation that throws).
When they encounter method calls on these types, they should not emit a call and should instead emit the appropriate hardware instruction (i.e. Vector128<float> SSE.Add(Vector128<float>, Vector128<float> should be replaced with addps).
For the various IsSupported properties, any compiler should know that it compiles down to a sequence of hardware instructions that check if the underlying hardware supports those calls.
For a JIT, this is "constant" and it can drop any code paths it won't hit. It also doesn't need to emit the checks.
For an AOT, the most basic option is two just compile down for a minimum supported architecture and drop all other code paths and the hardware checks. The hardware itself will fault when it encounters the emitted instruction sequences if it doesn't support them. In your case, this sounds like dropping everything that isn't SSE or SSE2.
You can, however, have the compiler be smarter and support more than the minimum architecture by emitting the required checks. Keeping in mind that these checks can be expensive, you generally want to cache these checks so your methods don't have to actually check for support at each entry point.
Most operating systems have some mechanism for running some basic "initialization" code when a dynamic library is loaded. Likewise, they generally have some mechanism for running some basic "initialization" code before the entry-point method of an executable is ran. The various CRT libraries generally hook into this initialization point so that they can do any initialization code as well.
One way to support additional architectures is to, in the "initialization" code, have the compiler emit the hardware checks and cache the results at some global/well-known address. The compiler can then emit multiple code paths for a method and have the first instructions for the method check the cached hardware support and branch appropriately (cmp DWORD PTR _is_supported_fma3, 0 and jne cos_fma3_implementation).
Another way to support additional architectures is to do late-binding of the method entry-points. Basically, this means that you would have a cos, a cos_sse2 method and a cos_fma3 method, each with the same signature (double method(double)). The compiler, in the "initialization" code, then emits hardware checks and modifies the cos method to jump to either the cos_sse2 or the cos_fma3 method depending on what is best suited for the underlying hardware (there are multiple ways to do late-binding of the method entry point, this was just one example).
In all cases, it is expected that the slight increase in startup cost is worthwhile due to the downstream savings on modern hardware.
tannergooding
on 5 Aug 2017
@fanol probably I am missing something, cause I don't see any problem that hasn't been solved a long time ago to deal with multiple path based on CPU characteristics. AFAIK (which is not a big know by any measure) AOT compilers will have to "decide" the target architecture (say x86, x64 and/or ARM) anyways.
Now the usual way to deal with that (there is a very well layed out example on the memcpy routines from Agnes Fog) is do a cpuid check on the entry point and setup the jump-table for the routines based on what path the AOT compiler has emitted (having IsSupported codes imply the compiler has to do some magic there anyways) so it emits all versions of those and at the entry point a new entry to deal with the cpuid check. After that you are just doing a call to a static memory location which in turn perform a jump to the proper routine entry instruction.
Essentially what @tannergooding said with a negligible startup cost; for the JIT version it is simple (that's how a JIT works). No self modifying code was required to do the late binding at a cost of a very predictable jump to deal with it.
redknightlois
on 5 Aug 2017
I would expect any compiler (AOT or JIT) to have special knowledge for all the types in the System.Runtime.CompilerServices.Intrinsics namespace (this is one of the reasons I think they should be marked with extern, rather than have a software implementation that throws).
This is internal implementation detail that can differ from runtime to runtime, or over time. It does not affect the public shape of these APIs.
In CoreCLR, we have been using a dummy implementations that throws for intrinsic like this because of it was easier to implement. Here is one example: https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21 . This method is intrinsic just like the intrinsics discussed here: The JIT has to understand what to do for it and it does not have any fallback implementation.
jkotas
on 6 Aug 2017
I'm really happy to see this proposal. It would be great to have the lowest level building blocks available.
To run through a few of the things already discussed:
1) As a user, I'm totally fine with this sort of API having no built-in fallbacks. If I'm diving all the way down to the level of using platform specific intrinsics, the use of an unsupported intrinsic's fallback would be a performance bug. In that situation, I'd actually prefer fail-fast behavior.
2) Regarding pointer versus ref at the API level, pretty much all the memory I work with is either from preallocated and pinned memory or the stack, so pointers wouldn't be much of a blocker for my uses. That said, avoiding fixed/a GC hole is really useful in the general case, and I'd have no issue with a ref-only API so long as the JIT outputs efficient results for pointer->ref (which I'm pretty sure it does with no overhead, last I checked).
3) Regarding explicitness, I would tend toward exposing the hardware primitives whenever reasonable. In the case of something like aligned vs. unaligned loads, it would be a little unfortunate if the API design ended up making it difficult to target a platform where aligned loads were actually notably faster. That doesn't necessarily mean that every possible intrinsic has the same implementation priority- some are clearly less widely applicable- but it's good to keep space in the API for them.
I like the idea of embracing the extremely low level nature of this API. If the design ends up hiding away a choice which could conceivably affect performance on some instruction x platform combination, there could end up being yet another proposal down the road to deabstract it further. I'd rather short circuit those issues and have access to the raw building materials to make those abstractions as necessary.
4) I don't have a great understanding of the AOT story, but making packaging ISA feature aware sounds like it would be a pretty complicated job spanning a big chunk of tooling. In the interest of getting this API running quicker, it seems like doing the minimum necessary to support it- like a jump on cached hardware checks- is a good choice. Later, lower overhead approaches or tooling for AOT-generating feature specialized packages could be useful, but the core API doesn't seem blocked by it. (I should mention that I'm kinda biased by iwannaplaywithit, so I'm gonna lean towards raw simplicity and speed of implementation :))
 RossNordby
on 6 Aug 2017
RossNordby
on 6 Aug 2017
In CoreCLR, we have been using a dummy implementations that throws for intrinsic like this because of it was easier to implement
@jkotas, there is also the case where you throw on the native side (https://github.com/dotnet/coreclr/search?utf8=%E2%9C%93&q=COMPlusThrowArgumentNull&type=).
I definitely think that it is a case-by-case basis on which is better, but for this feature in particular, I think having the runtime throw (COMPlusThrowPlatformNotSupported) would be the "goto" choice.
There is going to be, at least from this proposal alone and the discussions had so far, several hundred APIs that do not have a backing software implementation. Additionally, the methods are identified by a special attribute and they can (based on the original design doc) potentially be allowed to have a software fallback implementation.
So, I would think it would be better for the runtime code that identifies intrinsics to have a fallback that does COMPlusThrowPlatformNotSupported in the case of it finding a method marked Intrinsic and extern and it not having any known handling for it.
There are a few benefits to doing it:
- This will save (at least) 7 bytes per API (coming from the 7 bytes of IL required to throw an exception). With this proposal already being several hundred APIs (and more coming in the future for other architectures), this will quickly add up.
- The JIT will already have to have a code-path where it identifies methods marked
Intrinsic, determine if the current architecture supports the instruction and either emit the instruction if supported or emit a call to the method if it doesn't. Modifying this to throw forexternmethods seems like a trivial addition - This enforces the compiler (AOT or JIT) to understand these methods. If we have a software fallback that throws, a compiler that doesn't recognize these will happily compile them and the code will fail at runtime. If instead marked
extern, the compiler will fail at compile time (this is still runtime for JIT, but pre-runtime for AOT). - It enforces the ability for us to say, this particular API shouldn't have a software fallback now or in the future (for these, it is primarily due to perf concerns, but there could also be other reasons). If users want a software fallback, they can provide their own wrapper (
if (X.IsSupported) { X.API(); } else { /* Software Fallback */ }) which will itself be optimized properly by the compiler.
tannergooding
on 6 Aug 2017
This will save (at least) 7 bytes per API (coming from the 7 bytes of IL required to throw an exception). With this proposal already being several hundred APIs (and more coming in the future for other architectures), this will quickly add up.
Identical IL method bodies are folded into a single instance (they all share the same RVA), so it doesn't matter how many such APIs there are. That said, I also prefer extern.
pentp
on 6 Aug 2017
I think having the runtime throw (COMPlusThrowPlatformNotSupported) would be the "goto" choice.
The "manually managed code" is never our "goto" choice these days. In CoreCLR, we avoid "manually managed code" because of it is a rocket science to write correctly. In CoreRT, there is no "manually managed code" by design (e.g. there is no equivalent of COMPlusThrowPlatformNotSupported) and so everything that is "manually managed code" in CoreCLR has to be re-implemented differently in CoreRT. It goes against our desire to share as much as possible between CoreCLR and CoreRT.
This will save (at least) 7 bytes per API
It won't save anything as @pentp pointed out.
Modifying this to throw for extern methods seems like a trivial addition
It is not exactly trivial. You can take one of the existing intrinsics (e.g. https://github.com/dotnet/coreclr/blob/master/src/mscorlib/src/System/ByReference.cs#L21) and try to re-plumb it using extern to understand the problem better. The first problem that you will likely hit is that these extern methods have to have entrypoint and it is not trivial to make an entrypoint out of nothing.
It enforces the ability for us to say, this particular API shouldn't have a software fallback now
IMHO, comment is about as good for saying that this API should not have a software fallback.
Also, I expect that once this is plumbed end-to-end we are going to find that the intrinsics should better work even as individual functions to make things like debuggers, advanced profilers or IL interpreters work well. We may end implementing the intrinsics by recursively calling itself to make that work:
[Intrinsic]
public static Vector256<float> Add(Vector256<float> left, Vector256<float> right) => Add(left, right);
Note that this implementation has the exact same behavior (e.g. around throwing invalid instruction exception) as if the intrinsic is expanded inline. This trick with intrinsic implemented by recursively calling itself is used in CoreRT, see e.g. https://github.com/dotnet/corert/blob/master/src/System.Private.CoreLib/src/System/Threading/Interlocked.cs#L236.
jkotas
on 6 Aug 2017
Thanks for the explanation @jkotas. It now makes more sense as to why not marking them extern is the better option.
tannergooding
on 7 Aug 2017
I am all for the 1-to-1 mapping between method and instruction. That is great, but I still feel this proposal needs a very limited basic set of platform "agnostic" methods like.
namespace System.Runtime.CompilerServices.Intrinsics
{
public static class IntrinsicsPlatform // Naming is just an example
{
[Intrinsic]
public static IntrinsicsArchitecture Architecture { get; }
}
public enum IntrinsicsArchitecture // Not bit specific, that can be tested in other ways
{
x86,
Arm,
// etc.
}
[StructLayout(LayoutKind.Sequential, Size = 16)]
public struct Vector128<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector128<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector128<T> Store(ref T mem, Vector128<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 32)]
public struct Vector256<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector256<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector256<T> Store(ref T mem, Vector256<T> value) => Store(ref mem, value);
}
[StructLayout(LayoutKind.Sequential, Size = 64)]
public struct Vector512<T> where T : struct
{
[Intrinsic]
public static bool IsSupported() { throw new NotImplementedException(); }
[Intrinsic]
public static Vector512<T> Load(ref T mem) => Load(ref mem);
[Intrinsic]
public static Vector512<T> Store(ref T mem, Vector512<T> value) => Store(ref mem, value);
}
}
This would allow writing "generic" algorithms without referencing either x86, Arm or other platform assemblies.
Perhaps, I might not understand how all this will be packaged, etc. But I would think it would be good to avoid loading say x86 assembly on Arm. Or to phrase it differently how do we test which platform we are on? Do we test via SSE2.IsSupported? Even when running on Arm? How would that work etc.?
I think some thought about how this will work in projects targeting multiple platforms and how these can be factored into different platform specific assemblies without actually loading these assemblies and so forth would be good. How will this be done in practice?
I am primarily thinking for JIT'ed projects but AOT is just as relevant.
nietras
on 7 Aug 2017
public enum Architecture
{
X86,
X64,
Arm,
Arm64
}
Doh! 😦 Sorry, too long since .NET Core. Hopefully, this will be available in .NET Framework when/if intrinsics come to that.
nietras
on 7 Aug 2017
I'd have gone for something more like
[Flags]
public enum Architecture
{
Unknown = 0
32bit = 1 << 0,
64bit = 1 << 1,
IntelAmd = 1 << 8
Arm = 1 << 9
X86 = 1 << 16 | 32bit | IntelAmd,
X64 = 1 << 17 | 64bit | IntelAmd,
Arm = 1 << 24 | 32bit | Arm,
Arm64 = 1 << 25 | 64bit | Arm,
}
@nietras, under the current proposal, I believe you would code:
C#
if (FMA3.IsSupported)
{
}
else if (SSE2.IsSupported)
{
}
else if (Neon.IsSupported)
{
}
else
{
}
So, yes, you would code for both x86 and ARM without any additional architecture checks. It is expected that the JIT treats *.IsSupported as a constant and AOT would treat it as "somewhat" constant.
With these expectations, the compiler (JIT or AOT) would drop the x86 code paths on ARM and would drop the ARM code-paths on x86. It is additionally expected that a JIT would drop code paths that would not be executed. So, if FMA3 is supported, only the first code-path is emitted. If SSE2 is supported, only the second code path would be emitted. The third code path would never be emitted (on x86) and the fourth code path is only emitted if SSE2 is unsupported.
tannergooding
on 7 Aug 2017
I would assume that, if the System.Runtime.InteropServices.RuntimeInformation checks are also treated as constant (maybe someone could comment on this?) that you could do those additional checks without incurring any perf penalty.
tannergooding
on 7 Aug 2017
They are not. They are just regular methods for getting diagnostic information about the system.
mellinoe
on 7 Aug 2017
[Flags] public enum Architecture
@benaadams yeah wasn't trying to design the actual type just how such a constant would be good to have. It could be good to have information on whether unaligned load/stores are possible at all too and so forth. Flags has the issue that the total set is limited, could we have more than ~30 ISAs some day if int was used for the enum 😉
They are just regular methods for getting diagnostic information about the system.
Yeah ok, then I would definitely think some kind of constant for architecture, independent of x86/arm assemblies, would be good. What cons would adding this have? Compared to having to check say SSE2 or Neon to whether we are running on ARM or not? It seems quite user unfriendly considering.
nietras
on 7 Aug 2017
@nietras Why isn't the existing API good enough if you are just trying to figure out if you are running on ARM or not?
mellinoe
on 7 Aug 2017
@mellinoe maybe it is not a big deal, but to me its just weird that I would refer to (perhaps even load) the x86 or Arm assembly on a different platform. And with the extra Load/Store on the VectorXXX types basic algorithms can be independent of these too, then the platform specific "implementations" can be factored into x86/ Arm specific assemblies and these then reference the platform specific assemblies. Overall, reducing assemblies loaded and memory usage. I assume. If that is relevant, which I think it would be for restricted memory platforms.
nietras
on 7 Aug 2017
It seems quite user unfriendly considering.
Could you expand on this point?
I think that checking architectures has two flaws:
- It may lead users to make assumptions like: "I'm running on ARM, so NEON must be available"
- It makes providing a codepath for a software fallback hard
C# if (Architecture == x86) { if (SSE2.IsSupported) { } else { // Sofware } } else if (Architecture == Arm) { if (Neon.IsSupported) { } else { // Software } } // Can't put it here, as it wouldn't be hit
tannergooding
on 7 Aug 2017
@nietras You are certainly free to build platform-specific binaries and ship them with your platform-specific end-user applications, or bundle them into the appropriate locations in a nuget package. You can avoid including "dead code" that won't ever trigger on that particular platform. However, I'd be willing to venture that the gains are very small, and only likely to matter in a tiny number of cases.
mellinoe
on 7 Aug 2017
Using more safe code with Span will have performance problem respect to "naked" pointers?
For example instead of:
[Intrinsic]
public static unsafe Vector256<byte> LoadAligned(byte* mem) { throw new NotImplementedException(); }
this:
[Intrinsic]
public static Vector256<byte> LoadAligned(Span<byte> mem) { throw new NotImplementedException(); }
@fanoI Span loads wouldn't work so well in an inner loop as it you'd need to create the span per iteration, and would need to check sizes; then access the pointer
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem)
{
mem.Length != sizeof(Vector256<byte>) throw
return LoadAligned(ref mem.GetDangerousPointer())
}
It would need to be more an offset situation so the Jit could hoist the checks e.g.
public static Vector256<byte> LoadAligned(ReadOnlySpan<byte> mem, int index)
However again it would still need recongise patterns that (length - index) <= sizeof(Vector256<byte>); so not sure it would be a raw intrinsic?
[Intrinsic]
public static Vector256<byte> LoadAligned(ref Vector256<byte>)
Would probably work; but would also likely confuse people as to what its doing; why would you be loading a type to itself? (e.g. load aligned heap, or unsafe cast'd Vector256 to register Vector256)
Also I'm not sure you could ever do LoadAligned safe as you'd need to know the alignment; which you'd need to check or adjust the pointer for?
benaadams
on 8 Aug 2017
Could you expand on this point?
@tannergooding well they are of course many ways to structure code ;). However, to try to explain let me first list my assumptions. These may be entirely incorrect.
I assume that Intrinsics will be factored into a set of assemblies (although I do understand this might be implementation dependent, any .NET runtime can do it however they prefer, so all namespaces could be in one assembly, in fact that may be what .NET Core likely will do?):
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.dll
System.Runtime.CompilerServices.Intrinsics.Arm.dll
Given that we are talking many thousands of methods this might even be split into more:
System.Runtime.CompilerServices.Intrinsics.dll // Only the "platform-agnostic" types and primitives here i.e. VectorXXX<T>
System.Runtime.CompilerServices.Intrinsics.X86.SSE.dll // SSE-SSE4.X
System.Runtime.CompilerServices.Intrinsics.X86.AVX.dll // AVX-AVX2
System.Runtime.CompilerServices.Intrinsics.X86.AVX512.dll // AVX-512
System.Runtime.CompilerServices.Intrinsics.Arm.dll
// Etc.
Given this, one could limit the referenced assemblies to only those that are relevant for a given architecture. So will there be one or more assemblies? If only one, what about the memory usage that this may cause? In this thread there where discussions of how many bytes any given method might use and how that could be a problem given the many methods (although sharing would solve it maybe), is this not an issue? Do the method definitions themselves not carry some weight?
For the code I imagine building based on this I would follow a similar factoring (split into many here to make it clear) of assemblies e.g. (dependencies listed below ->):
PerfNumerics.Funcs.dll // Definitions of different func interfaces
-> System.Runtime.CompilerServices.Intrinsics
PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> System.Runtime.CompilerServices.Intrinsics
-> System.Runtime.CompilerServices.Unsafe
PerfNumerics.Funcs.Software.dll // Software specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.Arm.dll // ARM specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.dll
PerfNumerics.Funcs.x86.dll
-> PerfNumerics.Funcs.dll
These would thus define the algorithms and primitives one can use. These of course need to be composed somewhere i.e. in some functionality layer:
PerfNumerics.SomeFunctionality.dll
-> PerfNumerics.Algorithms.dll // General algorithms i.e. like the Transform I mentioned earlier but for 1D,2D,3D, etc. Tensor etc. etc.
-> PerfNumerics.Funcs.dll
-> PerfNumerics.Funcs.Software.dll
-> PerfNumerics.Funcs.Arm.dll // Specific implementations of many different funcs (e.g. threshold, multiply, and, xor etc. etc.)
-> PerfNumerics.Funcs.x86.dll
In this a given function could be composed (to avoid loading unnecessary platform code etc.) like:
public static class SomeFunctionality
{
public static int SomeFunction(Span<T> src, Span<T> dst)
{
switch (IntrinsicsPlatform.Architecture)
{
case IntrinsicsArchitecture.x86:
return SomeFunction_x86(src, dst);
case IntrinsicsArchitecture.Arm:
return SomeFunction_Arm(src, dst);
default:
return SomeFunction_Software(src, dst);
}
}
}
Within SomeFunction_x86 then defined as the composition of algorithm with func:
public static int SomeFunction_x86(Span<T> src, Span<T> dst)
{
// Here a given impl is composed of algorithm + func so say
Transform(src, new ThresholdVectorFuncX86(), dst);
// As mentioned before Transform will do switch
}
The func itself would then have the if/else switch, and in some cases this needs to be combined with another "func" and interface that can tell the algorithm whether, despite say Vector512<T> is supported, the actual intructions needed are not present so this should be skipped too. In fact, if VectorXXX<T>.Load/Store are not added this can be handled via another func. It get messy quickly though, it is a sort of C++ templates in C# kind of stuff. Abusing value type code generation of the JIT.
@mellinoe All of this can, of course, be implemented in some way with the existing API, but not without referencing platform specific static classes. With the above no Arm assembly would be even loaded on x86. Maybe that is not a concern at all?
I understand that factoring and structuring code this way is definitely not for everyone, I am not even sure it is necessarily the best way for what I want, so just spit-balling here.
nietras
on 8 Aug 2017
Would probably work; but would also likely confuse people as to what its doing; why would you be loading a type to itself?
@benaadams I don't think it would be confusing. It's the same as all the other intrinsics - allows you to more efficiently do something you could already otherwise do. If anything I find it less confusing because with the ref Vector256 signature it's doing exactly what one would expect at first glance.
sharwell
on 8 Aug 2017
But this "LoadAligned" would be the equivalent of the ASM X86 instruction movdqa? That is the result of this intrisic should be that Vector256
If it is this I don't understand well why a Vector256
fanoI
on 8 Aug 2017
If it is this I don't understand well why a Vector256 is returned...
So you have a reference to use in subsequent operations; so for example if you were loading from an array on heap and you knew you were indexing starting at an aligned location.
byte[] array = new byte[1000];
// Possible unaligned loads
//Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole? Invalid C#
//Vector256<byte> xmmReg1 = *(Vector256<byte>*)&array[i]; // implied Load + GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg2 = AVX.Load(ptr + i);
Vector256<byte> xmmReg3 = *(Vector256<byte>*)(ptr + i); // implied Load?
}
Vector256<byte> xmmReg4 = ref Unsafe.As<Vector256<byte>>(ref array[i]); // implied Load?
Vector256<byte> xmmReg5 = AVX.Load(ref Unsafe.As<Vector256<byte>>(ref array[i]));
// Possible aligned loads
//Vector256<byte> xmmReg6 = AVX.LoadAligned((byte*)&array[i]); // GC hole? Invalid C#
fixed(byte* ptr = &array[0])
{
Vector256<byte> xmmReg7 = AVX.LoadAligned(ptr + i);
}
Vector256<byte> xmmReg8 = AVX.LoadAligned(ref Unsafe.As<Vector256<byte>>(ref array[i]));
@sharwell, I don't like the ref Vector256 syntax because most of the time, I wouldn't have a Vector256 until after I call the load instruction. Instead, I would have an array of T that is at least sizeof(Vector256).
I don't want to have Unsafe.As<float, Vector256<float>>() interspersed throughtout my code when ref T, ref float, void*, or float* is much more clear, concise, and matches the backing structure.
tannergooding
on 8 Aug 2017
Vector256<byte> xmmReg0 = AVX.Load(&array[i]); // GC hole?
This is not a valid C#...
you knew you were indexing starting at an aligned location
The only way you know that is if you pin the array. The GC can move it and change the alignment any time.
jkotas
on 8 Aug 2017
The only way you know that is if you pin the array.
At which point you have a pointer. So not sure non-pointer aligned load would be useful?
benaadams
on 8 Aug 2017
I'm doing the devil advocate here but all this unsafe, GC hole and so on... doesn't risk to make C# too much similar to C/C++? There is no safety in the example of @benaadams...
It is so bad to check before writing to a XMM register that you are not writing the wrong size? Better to be 2% slower than C/C++ but retain at least a little of safety, right?
Cosmos does not accept unsafe / unverifiable code outer the lowest ring (called Core) we maybe can do an exception if it is part of the C# run time but a user library using these intrisics will not accepted in Cosmos (that is will not compile).
fanoI
on 8 Aug 2017
Better to be 2% slower than C/C++ but retain at least a little of safety, right?
Probably needs some array/span overloads?
Vector256<T> AVX.Load(T value)
Vector256<T> AVX.Load(ReadOnlySpan values)
Vector256<T> AVX.Load(T[] values)
Vector256<T> AVX.Load(T[] values, int index)
However unaligned load wouldn't be able to be supported this way
benaadams
on 8 Aug 2017
@fanoI, this is not expected to be used by application authors. Instead, it is meant to be used by framework authors so that core functionality can be written in managed code and can achieve the best performance possible.
This will likely be used by things like:
- System.String
- System.Math & MathF
- System.Numerics.Vector
, Vector2, Vector3, Vector4 - etc
It would also be used by people writing things like multimedia application engines or interop code
Framework authors would use these APIs when implementing their own APIs and would likely wrap all the unsafe bits internally. My view is:
- An app developer consuming an API that uses intrinsics should not need to know (or be able to tell from the API itself) that it is using intrinsics.
- An app developer should never have to touch any of the types in
System.Runtime.CompilerServices.Intrinsics.
Cosmos does not accept unsafe / unverifiable code outer the lowest ring
This is a perfectly fine stance to have, as long as you also accept that it cuts out many core APIs that CoreFX exposes. For example, string.IndexOf(char) is "safe", but itself calls the unsafe overload (https://source.dot.net/#System.Private.CoreLib/src/System/String.Searching.cs,eb06d6d166f6a3d9,references).
You must also be willing to accept that just because the verifier thinks its unverifiable, doesn't mean that it is: https://github.com/dotnet/roslyn/pull/21269. In the case linked, peverify doesn't know how to handle some of the optimizations the compiler emits for ref readonly. The emitted code is actually safe and verifiable, but the verification tool doesn't know how to recognize this.
We maybe can do an exception if it is part of the C# run time
None of these APIs are or will be C# specific (there isn't really a "C# Runtime"). They are part of the Core Runtime and Core Framework and therefore will be accessible by any almost any language that compiles down to IL code (at least any language that supports ref or pointers at least).
It is also the case that these features depends entirely on the runtime they are running on. CoreCLR will recognize these instructions and emit code one way, but another runtime (Mono, for example) might do it differently.
tannergooding
on 8 Aug 2017
@fanoI @mellinoe
Essentially the very same problem arises in safe system programming language like Rust. One can not express all low level operations required in several libraries in Rust safe syntax therefore Rust provides unsafe context where ownership, borrowing and other safety features are lifted. Very interesting description of the problem is shown in an article:
Rust employs a strong, ownership-based type system, but then extends the expressive power
of this core type system through libraries that internally use unsafe features
Essentially it means that sometimes it is impossible to write secure programs using only secure constructs. The way to proceed as was stated by @mellinoe is to use unsafe constructs in a safe way to create safe frameworks or libraries.
4creators
on 9 Aug 2017
@4creators I think @tannergooding said that, but yes 😄 . Unsafe code is fundamental to many of the core libraries of .NET.
mellinoe
on 9 Aug 2017
I think a good summary of discussions so far is:
- The feature is, essentially, universally loved/adored
refvspointersseems to need further thought/discussions for the API surface- No software fallback seems to resonate positively
- Determining how to expose these without bloating the lowest layer, but still making APIs useable from every layer seems to need more discussion
Some of the open questions still seem to be:
- What will the APIs for Scalars (i.e.
sqrtssormovss) look like and how do they coincide with the Vector APIs? - Is exposing a small subset of helper functions (such as generic
load/store) worthwhile?
- If we don't think these will be used by CoreFX itself, then exposing in a 3rd party library is probably best.
- Can we get a repo up (in CoreFX) so people can start working on this in their spare time?
tannergooding
on 9 Aug 2017
@tannergooding Thank you so much for the summary, and let's discuss these topics in .Net Design Reviews next week.
What will the APIs for Scalars (i.e. sqrtss or movss) look like and how do they coincide with the Vector APIs?
Our intrinsic API design (we will submit the PR after this proposal gets approved) has included certain scalar instructions (e.g. crc32, popcnt, etc.), but these ones you mentioned (most from SSE/SSE2) do not yet.
These SSE/SSE2 scalar float point instructions have been covered by RyuJIT codegen currently. Do you think it is necessary to expose them as intrinsics? If yes, could you provide more details about use cases?
fiigii
on 9 Aug 2017
popcnt in particular is something that we would really want to have
ayende
on 9 Aug 2017
One, both or a combined form of BSF, TZCNT
One or both of BSR, LZCNT
benaadams
on 9 Aug 2017
@fiigii, (maybe @mellinoe could chime in on this as well?)
Interop with other intrinsic code
Realistically, there is no difference between Vector128<T> and double other than:
- Potentially how the value is passed on the stack
- Which form of the instruction is called (
sdvspd) - Whether the intrinsic is explicit or implicit
As a framework author, I shouldn't have to worry about converting Vector128<T> to double, just to call another method (Math.Sqrt), and then take the result and convert it back to Vector128<T> (I should just be able to call SSE2.SqrtScalar instead).
I also shouldn't have to rely on assuming that the JIT will definitely treat my Math.Sqrt call as intrinsic and will produce optimal code that fits in with my algorithm.
Implementing System.Math and System.MathF in managed code
Today, the System.Math and System.MathF APIs are mostly implemented as FCALLs into the CRT implementation of the corresponding method (System.Math.Cos calls cos in libm).
There are already perf differences between the platforms (https://github.com/dotnet/coreclr/issues/9373), but there are also differences in input/outputs for some of the values that are not dictated by IEEE 754.
Without the scalar intrinsics, the only way to implement these using the intrinsics is to replicate the output to all registers and pull out the lowest value once complete (effectively Vector4 v = new Vector4(value); return Vector4.Cos(v).X;). This can potentially make the algorithm more complex and cause use of additional registers that would otherwise not be required.
Consistency
I still think it is a great idea to isolate all runtime intrinsics (including the ones the RyuJIT codegen currently covers) and isolate them to System.Runtime.CompilerServices.Intrinsics. The functions that previously had special intrinsic tracking (like Math.Sqrt, Math.Cos, etc: https://github.com/dotnet/coreclr/blob/7590378d8a00d7c29ade23fada2ce79f4495b889/src/inc/corinfo.h#L913) should then be rewritten to call the System.Runtime.CompilerServices.Intrinsic API.
I don't know what the opinion on this from the runtime/framework folks is, but I would believe that this would significantly simplify the porting of these APIs across runtimes (to things like CoreRT, Mono, etc).
It should, ideally, also simplify the amount of native code that has to be maintained for these APIs (where performance does matter) and it should increase maintainability of the code and consumability of the fixes (as it requires framework changes, rather than runtime changes to improve).
tannergooding
on 9 Aug 2017
I still think it is a great idea to isolate all runtime intrinsics (including the ones the RyuJIT codegen currently covers) and isolate them to System.Runtime.CompilerServices.Intrinsics.
I do not think it is a good idea. It is actually not even possible for some of existing ones, e.g. because of they are virtual methods.
jkotas
on 9 Aug 2017
The Intel hardware intrinsics are really helpful to library implementation. As I know, however, mscorlib cannot rely on other managed assemblies (i.e. CoreFX). If we want these intrinsics to be used in mscorlib (i.e. System.Math/MathF), do we have to change the organization of intrinsics or something of runtime inside?
fiigii
on 9 Aug 2017
The intrinsics need to be implemented in System.Private.CoreLib ("mscorlib"). Fundamentally, they need to be implemented in the runtime itself anyways -- there is no feasible way to implement these "out of band." As discussed above (or perhaps in another issue somewhere), System.Private.CoreLib can't depend on any other assemblies, because it is the core assembly. We want to be able to use these intrinsics within System.Private.CoreLib itself (on fundamental types like String, etc.). Therefore, they need to be implemented in System.Private.CoreLib.
mellinoe
on 9 Aug 2017
@mellinoe Do you expect that all intrinsics will be implemented in System.Private.CoreLib?
If yes this would require several thousand methods - full support for AVX512 only would take around 2k methods (including overloads). If later ARM SVE intrinsics would be added for all vector sizes (16 different vectors) we would get into combinatorial explosion.
4creators
on 9 Aug 2017
Does ARM have individual instructions for each vector size or is it a length parameter?
benaadams
on 9 Aug 2017
Currently ARM ISA SIMD implementation supports only 128 bits register size and 1 to 1 vector - instruction relationship. I would suppose that while finalising SVE design they could go different ways i.e. like Intel where prefix (VEX, EVEX) are used to differentiate instructions plus register data which are encoded in some parts of the instruction. Currently we do not know that.
However this should not have any impact on this analysis since API should differentiate between vector sizes at the method level, therefore one would expect to have 16 methods for adding byte vectors, 16 methods for adding word vectors etc. etc. It is a scheme in which every operation for given underlying type i.e. byte needs one method overload for each supported vector size.
4creators
on 10 Aug 2017
Depends what the instructions are, if they are all the same but with param in register or as argument, it could be Load(* , n) to opaque armRegister type; then functions taking armRegister
benaadams
on 10 Aug 2017
@4creators Yes, the "naive" design is to simply implement them all in System.Private.CoreLib. But by "all", we really mean "all of the instructions that we deemed important enough or received a contribution for". There are certainly many instructions that are not useful or interesting to expose directly, and in any case this feature requires that each individual intrinsic be recognized specially and specifically in the JIT. We will certainly start with a smaller subset than "everything" -- most likely the functions we need to implement key things like Math(F), String, Vector2/3/4, etc.
Given that System.Private.CoreLib is already platform-specific (e.g. we have different binaries for x86, x64, ARM), I can envision a different design where we are able to omit inapplicable intrinsic function stubs for other platforms. E.g. System.Private.CoreLib.x64.dll would not include the ARM function stubs. But this would require even more special handling in the runtime, and is ultimately an implementation optimization -- one which isn't clearly needed at this stage.
mellinoe
on 10 Aug 2017
we really mean "all of the instructions that we deemed important enough or received a contribution for"
@mellinoe
My impression was that there are two sets of instructions being discussed:
- Those needed for internal use in
System.Private.CoreLib - Those which are exposed via external assembly and which comprise majority or all of SIMD and other special instructions
For runtime developers the first set is most important for developers working on domain specific libraries it would be the availability of all or almost all intrinsics which is important. When we go through several algorithms which could be vectorized it is hard to imagine their implementation with limited set of SIMD or without specialised instructions.
4creators
on 10 Aug 2017
@4creators Even in that second category, the "real" functionality itself will need to be implemented in the JIT and runtime -- there's no way to do it outside of the coreclr repository, or "out-of-band" in any way. You can define function stubs wherever you want, but it doesn't matter unless they are understood by the JIT/runtime. Because of that, I don't see a lot of value in allowing them to be defined in some other assembly. It just makes things more complicated, IMO.
mellinoe
on 10 Aug 2017
So what is needed to make this thing reality? I think this is be BIG for C#... it is one of the "excuses" to use C++ and this make it go away.
The work on experimental features must be done on CoreFxLabs?
fanoI
on 12 Aug 2017
@fanoI, I don't think anything can be "started" until the API is reviewed and approved.
Based on @fiigii's comment, the design review will be this upcoming Tuesday (https://www.youtube.com/watch?v=52Fjrhx7pKU)
Once the API is approved, I imagine that work can actually start.
Maybe @jkotas or @mellinoe could comment, but I would imagine the CoreFX/CoreCLR team should do the initial work for at least 1-2 intrinsics and should write up documentation detailing the step-by-step process of what to do for other intrinsics. Once that is available, it could be opened for the general community to step-in. Community members could "sign-up" for a set of intrinsics to implement, and then start working away.
tannergooding
on 12 Aug 2017
Ah OK the official discussion should yet start... so we need to wait :-)
fanoI
on 12 Aug 2017
A few thoughts on this proposal and discussion:
Generic vs. non-generic (e.g. Add<T> vs. Add<float>):
- I'm a bit confused by this discussion. Since this is an internal intrinsic, and won't have an implementation, I see little advantage in exploding the number of declarations. As this is intended for developers who "know what they're doing", having a comment indicating what types are supported for the current target ISA should provide sufficient information.
Would it be useful to have a standard API for querying "best alignment" for a given type and/or obtaining aligned memory? I would not necessarily assume that, as we go toward larger vector sizes, it will always be the case that the best alignment (barring page faults) is necessarily the size of the vector.
For the constant arguments, what behavior are we expecting from the IL compiler (AOT or JIT) when a non-constant is passed? For the AOT, an error would be useful, but for the JIT should it be treated as illegal IL, or should it generate code to throw an exception, or ...?
I think we need to be very crisp about the strategy for evolution of the set of supported intrinsics. As there are multiple runtimes and IL compilers, it seems like there's a not-insignificant compat story where the proposed IsSupported properties or methods will actually imply different things over time.
Property vs. method for IsSupported: I think the sentiment is already leaning in the property direction, but I will add my vote for that. Checking for hardware support is not really an "action". This is really returning a property of the target.
Regarding AOT compilation and the checking of IsSupported: I think that a good AOT compiler should be able to aggregate and optimize the checking and associated code. That is, the burden should not be on the developer to unnaturally structure their code such that the checks that logically belong in low-level code are bubbled up to a level where their cost will be amortized.
Performance penalties due to mixed usage of SSE2 and AVX forms: RyuJIT currently delays actual encoding until late, and instructions that have both AVX and SSE encodings have a unified representation - the determination of which encoding to use is based on whether the VM tells the JIT that AVX2 is available.
Note that currently we require AVX2 in order to use AVX encoding. This is simply to reduce the test/support/implementation matrix, since AVX2 provides more uniform support for 256-bit vectors. It would be fairly straightforward to use AVX encodings any time either:
- AVX2 is available and
Vector<T>is used, or - AVX is available and AVX intrinsics are used
- AVX2 is available and
- The above will, however, increase the test and support burden - but I think we're already down that path!
 CarolEidt
on 15 Aug 2017
CarolEidt
on 15 Aug 2017
It would be fairly straightforward to use AVX encodings any time either:
- AVX2 is available and Vector
is used, or - AVX is available and AVX intrinsics are used
So, I have realized that obviously this is a non-starter. We can't change the target after seeing an AVX intrinsic. So, I think we will need to change the code generation strategy to target AVX whenever it is available (not just when AVX2 is available).
CarolEidt
on 15 Aug 2017
We should also coordinate with https://github.com/dotnet/roslyn/issues/11475
 tmat
on 16 Aug 2017
tmat
on 16 Aug 2017
Disagree. These are unrelated proposals.
 jaredpar
on 16 Aug 2017
jaredpar
on 16 Aug 2017
They are somewhat related:
- Both need an attribute to mark the intrinsic. We should coordinate naming to avoid confusion/collision.
- Some of the compiler intrinsics require argument to be a literal, similarly to the hardware intrinsics. We might consider having a single concept in the compiler. For the hardware intrinsics this property would be encoded in metadata, for the compiler intrinsics it would be implied by the intrinsic name.
There might be other similarities.
tmat
on 16 Aug 2017
Both need an attribute to mark the intrinsic.
Disagree. The runtime intrinsic may use a modreq in places but don't see a need for an additional attribute. Certainly not one that the compiler is going to be processing.
Some of the compiler intrinsics require argument to be a literal, similarly to the hardware intrinsics.
Sure. But if we add the literal requirement for runtime intrinsics it would be done in a general way.
There might be other similarities.
I think they're quite different. This is about adding runtime intrisicts. The compiler has almost 0 participation here other than a feature request for literal enforcement. The compiler intrisics is a proposal that is all about the compiler ability to emit new IL instructions.
jaredpar
on 16 Aug 2017
Disagree. The runtime intrinsic may use a modreq in places but don't see a need for an additional attribute. Certainly not one that the compiler is going to be processing.
The above proposal uses attribute [Intrinsic]. I'm not suggesting the compiler needs to understand that attribute. The compiler intrinsics proposal also introduces an attribute CompilerIntrinsic -- this one the compiler understands. If we named both attributes just Intrinsic and put them in the same namespace that would be a problem. So all I'm saying is that we should coordinate the naming -- I would prefer the runtime intrinsic to use attribute RuntimeIntrinsic.
tmat
on 16 Aug 2017
hence I would prefer the runtime intrinsic to use attribute RuntimeIntrinsic.
It should not matter what the attribute used by runtime is going to be. I expect that it will be internal - it won't be public or part of the public surface. In fact, it would be fine to not have attribute for it at all and use some alternative mechanism to recognize these in the runtime.
jkotas
on 16 Aug 2017
@jkotas BTW, visibility wouldn't matter. If there was an attribute and the name was the same as the one for compiler intrinsics it would break build of the CoreFX library that uses the attribute internally.
tmat
on 16 Aug 2017
Hi all, I have updated this API proposal based on above discussion and the design review meeting. Please see the Update section for detials. All the changes are applied to our API source code as well. Once this proposal gets approved, we will submit the complete API design.
fiigii
on 18 Aug 2017
@fiigii was there any clarity on why
Vector128<float> CompareVector128(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
and not
Vector128<float> Compare(Vector128<float> left, Vector128<float> right, const FloatComparisonMode mode)
A nit would be that Compare doesn't need to be repeated in enum name and enum value so it could be shortened?
public enum FloatComparisonMode : byte
{
EqualOrderedNonSignaling,
LessThanOrderedSignaling,
LessThanOrEqualOrderedSignaling,
UnorderedNonSignaling,
NotEqualUnorderedNonSignaling,
NotLessThanUnorderedSignaling,
NotLessThanOrEqualUnorderedSignaling,
OrderedNonSignaling,
......
}
Otherwise LGTM
benaadams
on 18 Aug 2017
@benaadams Sorry, that is my mistake. CompareVector* has been changed to Compare throughout.
fiigii
on 18 Aug 2017
Wouldn't clash e.g.
FloatComparisonMode.CompareEqualOrderedNonSignaling
to
FloatComparisonMode.EqualOrderedNonSignaling
StringComparisonMode.CompareEqualOrderedNonSignaling
to
StringComparisonMode.EqualOrderedNonSignaling
benaadams
on 18 Aug 2017
A nit would be that Compare doesn't need to be repeated in enum name and enum value so it could be shortened?
Wouldn't clash e.g.
FloatComparisonMode.CompareEqualOrderedNonSignaling
to
FloatComparisonMode.EqualOrderedNonSignaling
Good point. This change makes sense.
fiigii
on 18 Aug 2017
Add Span
overloads to the most common memory-access intrinsics (Load, Store, Broadcast), but leave other alignment-aware or performance-sensitive intrinsics with original pointer version.
👎 I really think this is the worst of the options for this. Having just ref T versions would be naturally useable for both native/pinned and managed memory, now we are left with something that is less than ideal for managed memory unless you already use Span. And two overloads, instead of just a single method. Additionally some overloads are simply only available in pointer version leaving no other solution that having to pin memory, which is also undesireable.
nietras
on 18 Aug 2017
are applied to our API source code
@fiigii is this available anywhere?
nietras
on 18 Aug 2017
@nietras I am working on building the intrinsic API source code into System.Private.CoreLib, will submit the PR later.
fiigii
on 19 Aug 2017
Update: replace Span<T> overloads by ref T overloads.
fiigii
on 23 Aug 2017
Hi all, the intrinsic API source code has been submitted as PR dotnet/corefx#23489.
fiigii
on 23 Aug 2017
Where are the scalars versions? They are need to implement trigonometric operations for example...
fanoI
on 24 Aug 2017
@fanoI This proposal does not include the hardware instructions that have been covered by current RyuJIT codegen.
fiigii
on 24 Aug 2017
sqrtss and sqrtsd that are for example required to implement Math.Sqrt() are generated by the current RyuJit codegen? I had understood they were part of this proposal too...
How you do this otherwise: https://dtosoftware.wordpress.com/2013/01/07/fast-sin-and-cos-functions/ ?
fanoI
on 24 Aug 2017
@fiigii, I thought they were discussed briefly during the API review?
In either case, if they are not part of this proposal, I would like to know so I can submit a new proposal covering them.
Providing scalar instructions will be required for implementing certain algorithms (such as implementing System.Math and System.MathF APIs in C#). It will also be useful/required in certain high-performance algorithms for other scenarios.
tannergooding
on 24 Aug 2017
Doesn't RyuJIT already generate sqrtss for MathF.Sqrt()?
It also looks like sqrtsd is supported by RyuJIT, but I can't think of anything that uses it from C# unless the implementation of Math.Sqrt() changed since I last looked
 saucecontrol
on 24 Aug 2017
saucecontrol
on 24 Aug 2017
@saucecontrol, RyuJIT treats both Math.Sqrt and MathF.Sqrt as intrinsic (via CORINFO_INTRINSIC_Sqrt).
However, the remaining Math and MathF functions fallback to the corresponding C Runtime calls (they are all FCALLs, technically Math.Sqrt and MathF.Sqrt are the same). This leads to both performance and result inconsistencies between Mac, Linux, and Windows, and between ARM and x86. Ideally, this (or a new proposal) will add the scalar overloads so we can readily implement those methods in managed code and ensure that all platforms/architectures are consistent.
tannergooding
on 24 Aug 2017
@fiigii If you think about it, it would actually make sense to eventually get rid of most of what RyuJIT has to do itself. If the surface is covered, you dont need to handle case-by-case with all the complexity inside the JIT code.
redknightlois
on 24 Aug 2017
Created a proposal explicitly covering the scalar overloads: https://github.com/dotnet/corefx/issues/23519
tannergooding
on 24 Aug 2017
This API looks really great. There is one thing I would like to see changed however. Could we support a software fallback?
I know I'm very late to this discussion, but I'd like to make the case for this.
I can see the momentum in this discussion is for not having any software fallback, but I don't see any in-depth discussion of the pros and cons of this. For pros, I see someone mention that any code that runs a would-be software fallback mode would be a performance bug, and it would be better to to crash in the scenario for easier debugging. That's certainly true, but I would argue that this is not a very .NET way of doing things. Many aspects of .NET have graceful performance degradation in place of throwing exceptions and I'm sure it's written somewhere that this is part of the .NET philosophy. Better for code to run slower than to crash outright, unless the programmer specifies this is what they want to happen. This is something I like about the the old Vector
I think part of the argument for no software fallback is partly based on the fact that the audience for this API is for pretty low level developers who are used to using SIMD extensions from C++ and assembler and whatnot, and having the code crash outright when the real instruction sets are not available is a more comfortable development environment for them. And while I believe this will be true for 98% of developers who use this API, I don't think we should forget the more typical .NET developer and assume they would never want to explore this stuff to see if it could benefit them. In general, I think it's a mistake to design an API like this and assume only a certain type of developer will want to use it. Especially something baked into .NET.
Here’s some of the pros I consider a software fallback would provide:
Better development experience: I'll accept the point that crashing when a used extension is not present has some advantages, but consider the benefits of a software fallback also. A software fallback provides a way of reliably exploring the use of all instruction set classes, including ones not supported on the developer’s machine. This may not excite many in this discussion, but it does provide a nice way of developers to test algorithms ensuring they are logically sound before deciding if they are worth testing on real hardware. Some debugging scenarios are easier. As an example, if a user of a library reports a bug when they run it on ARM devices because of a bug in code that uses NEON, a developer on that library has the possibly of fixing this from an x86 machine as they can reproduce and fix the the bug using the NEON software fallback. Of course it would be better if the developer had NEON hardware to debug with, but this is not always practical and the developer is empowered to improve their code much more easily in less time than they would otherwise. A software fallback would also provide much better potential for unit tests that can test code path for all instruction set classes no matter what the local dev machine supports.
More reliable code: Certainly any code that runs in software fallback mode where there exists usable extensions that would run faster, or a handwritten software algorithm can be considered a performance bug. However, in the real world it is inevitable that developers have limited time to write and debug code. It is inevitable that mistakes will be made and that developers will simply opt not to bother writing code that does not expect a certain set of extensions to be present. .NET excels in allowing developers to write code that works reliably quickly, and then optimize that code to run faster at their preference. Given a code base where the developer makes use of these extensions but does not have the time and resources to ensure that their code runs appropriately on any platform, then for the consumer of the library or application it is much more preferable that that code run much slower than completely crash. I believe this is something that will affect developers consuming libraries written with this API, and end-users who potentially face complete crashes because an application was written without being tested with instruction sets available on the user’s CPU.
In general, I think a software fallback would provide little if any disadvantage to developers who feel they would not benefit from it, but at the same time make the API much more accessible to regular .NET developers.
I don't expect this to change given how late I am to this, but I thought I'd at at least put my thoughts on the record here.
 battlebottle
on 2 Jan 2018
battlebottle
on 2 Jan 2018
I agree that having software fallback capability would be nice. However, given that it is just a nice-to-have feature and can also be implemented by individual developers on a need-to-have basis, or as a third-party library, I think it should be placed towards the bottom of the to-do list. I would rather see that energy being directed towards having full AVX-512 support which is already available on server-grade CPUs for a while and on its way to consumer CPUs.
 skesgin
on 16 Jan 2018
skesgin
on 16 Jan 2018
Ping on AVX512 news?
 oscarbg
on 12 Apr 2018
oscarbg
on 12 Apr 2018
We have still some ISAs to implement before already accepted APIs will be finished - some AVX2 intrinsics and whole of AES, BMI1, BMI2, FMA, PCMULQDQ. My expectation is that after this work is finished and implementation is stabilized we will start working on AVX512. However, in the meantime we still have a lot to do with Arm64 implementations.
@fiigii could probably provide more info on future plans.
4creators
on 12 Apr 2018
I agree that having software fallback capability would be nice.
This API looks really great. There is one thing I would like to see changed however. Could we support a software fallback?
The current thinking around implementation of Hardware intrinsics is that we provide low level intrinsics which allow assembly like programming plus several helper intrinsics which should make developer life easier.
Implementation which provides more abstraction and software fallback is partially available already in System.Numerics namespace with Vector<T>. The expectation is that Hardware intrinsics will allow to expand functionality of Vector<T> implementation by adding new functionality backed by software fallback. Vector<T> implementation should be viewed than as a higher level programming interface which could be used on all hardware platforms due to software fallback.
The above, however, is a personal view of community member.
4creators
on 12 Apr 2018
Ping on AVX512 news?
After finish these APIs (e.g., AVX2, FMA, etc.), I think we have to investigate more potential performance issues (e.g., calling conversion, data alignment) before we move to the next step because these issues may blow up with wider SIMD architectures. Meanwhile, I prefer to improve/refactor the JIT backend (emitter, codgen, etc.) implementation before extending it to AVX-512. Yes, we definitely need to extend this plan to AVX-512 in the future, but now it is better to focus on enhancing 128/256-bit intrinsics.
fiigii
on 12 Apr 2018
Personally I don’t see software fallback as worth spending developer effort on, as the consumer can easily implement software feedback themselves if they want to have it, and besides it works better at the algorithm level than having software fallback at the intrinsic level.
Actually implementing all the dozens of intrinsics that exist out there for all targeted platforms is not something the consumer can do themselves and so I personally would prefer to have higher priority.
Great stuff by the way, I’m very much looking forward to having all these intrinsics available.
 Jorenkv
on 13 Apr 2018
Jorenkv
on 13 Apr 2018
Minor API enhancement suggestion from my side:
Add Count property to all vector VTs which would be similar to System.Numerics.Vector.Count, albeit would give the static value based solely on Vector64/128/256/etc<T>'s generic type argument.
The implementation could be something that looks like Unsafe.SizeOf<Vector128<T>>() / Unsafe.SizeOf<T>().
The reason for this proposal is - when the generic type argument is known aforehead (eg. concrete type like ushort, int, etc), then the vector dimension could be just hardcoded into source code. But this is not the case for the code that uses approach with generics - the dimension must be recalculated in source code often when required (again).
 voinokin
on 22 May 2018
voinokin
on 22 May 2018
Q. Is there any chance this functionality ever be available in .NET Standard?
I maintain a code library/nuget that would benefit from using these hardware intrinsics, but it currently targets .NET Standard to provide good portability.
Ideally I'd like to continue to offer portability, but also improved performance if the runtime platform/environment provides these intrinsics. Right now it seems my choice is either speed or portability, but not both - is this likely to change in the future?
 colgreen
on 25 May 2018
colgreen
on 25 May 2018
@colgreen This was discussed in https://github.com/dotnet/corefx/issues/24346. I recommend moving the discussion there.
jkotas
on 25 May 2018
Where can we find documentation on how to use intrinsics? I can see that the [Intrinsic] attribute is used in Vector2_Intrinsics.cs, but also in Vector2.cs, and I'm not sure why / how it works.
 aaronfranke
on 31 May 2019
aaronfranke
on 31 May 2019
@aaronfranke I don't know how much you know already, but it is my understanding that the IntrinsicAttribute is applied to a few methods where the compiler is supposed to replace the usual instructions with specially generated instructions. This is only possible since you distribute IL code to run on different platforms, and if a platform has the popcnt instruction, it is handled as a special case.
My example is a not a real one, but you can probably find real examples over at CoreCLR if you search for usages of IntrinsicAttribute.
 Genbox
on 1 Jun 2019
Genbox
on 1 Jun 2019
IntrinsicAttribute is an internal implementation detail. You do not need to worry about it to use the intrinsics.
https://devblogs.microsoft.com/dotnet/using-net-hardware-intrinsics-api-to-accelerate-machine-learning-scenarios/ describes good examples of real hardware intrinsic uses.
jkotas
on 1 Jun 2019
If you already have SIMD or low-level programming experience in C/C++, the comment of API source would be sufficient.
If not, this article Hardware intrinsic in .NET Core 3.0 - Introduction would be a good start.
fiigii
on 2 Jun 2019
Related issues
 nvivo
·
174Comments
nvivo
·
174Comments
 galvesribeiro
·
185Comments
galvesribeiro
·
185Comments
 ebickle
·
318Comments
ebickle
·
318Comments
 ericstj
·
152Comments
ericstj
·
152Comments
 hqueue
·
155Comments
hqueue
·
155Comments
Most helpful comment
I agree that having software fallback capability would be nice. However, given that it is just a nice-to-have feature and can also be implemented by individual developers on a need-to-have basis, or as a third-party library, I think it should be placed towards the bottom of the to-do list. I would rather see that energy being directed towards having full AVX-512 support which is already available on server-grade CPUs for a while and on its way to consumer CPUs.