Runtime: Performance regression: float.ToString(format) 20% to 3x slower
After the changes introduced to numbers formatting the vast majority of the operations is faster. However, this is not true for float.ToString(format)which is 20% to 3x slower.
Repro
git clone https://github.com/dotnet/performance.git
cd performance
# if you don't have cli installed and want python script to download the latest cli for you
py .\scripts\benchmarks_ci.py -f netcoreapp2.2 netcoreapp3.0 --filter System.Tests.Perf_Single.ToStringWithFormat
# if you do
dotnet run -p .\src\benchmarks\micro\MicroBenchmarks.csproj -c Release -f netcoreapp2.2 --filter System.Tests.Perf_Single.ToStringWithFormat --runtimes netcoreapp2.2 netcoreapp3.0
BenchmarkDotNet=v0.11.3.1003-nightly, OS=Windows 10.0.18362
Intel Xeon CPU E5-1650 v4 3.60GHz, 1 CPU, 12 logical and 6 physical cores
.NET Core SDK=3.0.100-preview8-013262
[Host] : .NET Core 2.2.6 (CoreCLR 4.6.27817.03, CoreFX 4.6.27818.02), 64bit RyuJIT
Job-BYJCMJ : .NET Core 2.2.6 (CoreCLR 4.6.27817.03, CoreFX 4.6.27818.02), 64bit RyuJIT
Job-JSSCYO : .NET Core 3.0.0-preview8-27916-02 (CoreCLR 4.700.19.36302, CoreFX 4.700.19.36514), 64bit RyuJIT
| Method | Toolchain | value | format | Mean | Ratio | Allocated Memory/Op |
|------------------- |-------------- |-------------- |------- |-----------:|------:|--------------------:|
| ToStringWithFormat | netcoreapp2.2 | -3,402823E+38 | E | 154.8 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | -3,402823E+38 | E | 193.7 ns | 1.25 | 56 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | -3,402823E+38 | F50 | 447.2 ns | 1.00 | 208 B |
| ToStringWithFormat | netcoreapp3.0 | -3,402823E+38 | F50 | 1,475.5 ns | 3.31 | 208 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | -3,402823E+38 | G | 152.7 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | -3,402823E+38 | G | 215.2 ns | 1.41 | 56 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | -3,402823E+38 | G17 | 160.2 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | -3,402823E+38 | G17 | 238.2 ns | 1.49 | 72 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | -3,402823E+38 | R | 245.7 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | -3,402823E+38 | R | 216.4 ns | 0.88 | 56 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 12345 | E | 166.6 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | E | 213.2 ns | 1.28 | 48 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 12345 | F50 | 318.9 ns | 1.00 | 144 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | F50 | 448.9 ns | 1.41 | 136 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 12345 | G | 146.6 ns | 1.00 | 40 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | G | 183.4 ns | 1.25 | 32 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 12345 | G17 | 161.9 ns | 1.00 | 40 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | G17 | 349.4 ns | 2.16 | 32 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 12345 | R | 172.8 ns | 1.00 | 40 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | R | 185.1 ns | 1.07 | 32 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 3,402823E+38 | E | 149.5 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | 3,402823E+38 | E | 188.5 ns | 1.26 | 48 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 3,402823E+38 | F50 | 437.2 ns | 1.00 | 208 B |
| ToStringWithFormat | netcoreapp3.0 | 3,402823E+38 | F50 | 1,523.3 ns | 3.48 | 208 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 3,402823E+38 | G | 151.5 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | 3,402823E+38 | G | 212.8 ns | 1.40 | 48 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 3,402823E+38 | G17 | 157.9 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | 3,402823E+38 | G17 | 237.0 ns | 1.50 | 72 B |
| | | | | | | |
| ToStringWithFormat | netcoreapp2.2 | 3,402823E+38 | R | 243.0 ns | 1.00 | 56 B |
| ToStringWithFormat | netcoreapp3.0 | 3,402823E+38 | R | 213.8 ns | 0.88 | 48 B |
/cc @danmosemsft @tannergooding
category:cq
theme:floating-point
skill-level:expert
cost:large
 adamsitnik
adamsitnik
All 45 comments
I had already gone over this with @billwert over an e-mail. For reference:
Yes, this is expected.
The previous implementation didn’t properly respect precision specifiers above 17 (15 in many cases) and would actually just fill in the positions with zero, even if valid digits existed. This meant is was actually not doing the work and so it will generally show to be faster because of this.
The other factor here is that many values, like `float.MaxValue`, are really edge-case values (much like subnormal numbers like `float.Epsilon`) and so they represent extreme cases where the computation may be more expensive than the common case and so they may have regressed slightly.
For reference, over half of all representable floats are in the range of -1.0 to +1.0 and, ignoring the gap of subnormal values (which is representable values between +/- 1.175492107*10^-38, excluding +/- zero), I had seen the results to be generally faster. – This is why many applications try to normalize results to between -1.0 and +1.0.
For the R case (which is roundtripping and is used in serializers/etc) we should be faster 100% of the time, as we are now always returning the shortest string, rather than trying 15, parsing the result back, checking if it was equivalent, and then trying again at 17 if it wasn’t equivalent (and so we are always doing less work).
For the default case (‘G’, and ‘ToString’) we will be often faster, but slower in a few cases. The cases where we are slower are where the algorithm needs to do additional computation to compute more than 15 digits (the previous implementation was equivalent to G15 and so would return non-roundtrippable results in some cases; roundtripping requires computing up to 17 digits, so in some cases we will be slower).
- 15 and 17 are for double. You can largely replace these with 6 and 9 for single.
 tannergooding
on 16 Jul 2019
tannergooding
on 16 Jul 2019
For the default case (‘G’, and ‘ToString’) we will be often faster, but slower in a few cases. The cases where we are slower are where the algorithm needs to do additional computation to compute more than 15 digits
@tannergooding, how does that map to these results in the above chart?
| Method | Toolchain | value | format | Mean | Ratio | Allocated Memory/Op |
|------------------- |-------------- |-------------- |------- |-----------:|------:|--------------------:|
| ToStringWithFormat | netcoreapp2.2 | 12345 | G | 146.6 ns | 1.00 | 40 B |
| ToStringWithFormat | netcoreapp3.0 | 12345 | G | 183.4 ns | 1.25 | 32 B |
 stephentoub
on 16 Jul 2019
stephentoub
on 16 Jul 2019
how does that map to these results in the above chart?
I'll profile, but this is likely related to the fact that it is 5 digits and float was previously defaulting to 7, so this is approaching the upper limit of exactly representable integers.
tannergooding
on 16 Jul 2019
Looks like this happens to be a case where we are hitting a set of code paths where the JIT isn't producing codegen that is as nice as the C++ codegen was.
The majority of time is being spent in Grisu3.TryDigitGenShortest.
- There look to be a few methods which the JIT isn't inlining when it might be better if it was.
Math.DivRemis used in a loop and the JIT still can't rationalize it to a singledivinstruction, and so it incurs an additional multiplication instead to avoid incurring twodivs.
There are also some minor places where codegen isn't as nice, but those don't look to be as impactful and would need further investigation.
tannergooding
on 16 Jul 2019
@AndyAyersMS
 danmosemsft
on 17 Jul 2019
danmosemsft
on 17 Jul 2019
this happens to be a case
I take it "this" means the various runs involving 12345, and we care less about the extremes...?
Any sense of how much the jit codegen impacts the perf here? Is it likely to be all of the regression? Some?
 AndyAyersMS
on 17 Jul 2019
AndyAyersMS
on 17 Jul 2019
I'll try to get more exact details tomorrow. A direct comparison is tough as the 2.2 code was C++ and the 3.0 code is C#. I don't think it is regressions in the JIT, just rather places where the JIT doesn't emit as nice of code.
tannergooding
on 17 Jul 2019
Math.DivRem is used in a loop and the JIT still can't rationalize it to a single div instruction, and so it incurs an additional multiplication instead to avoid incurring two divs
That's something that should be measured in isolation, it seems unlikely that when a 20-30 cycles DIV gets generated the extra 3-4 cycles MUL will have a significant impact. Especially considering that there's other code in the loop and that the value computed by DivRem is not loop carried.
 mikedn
on 17 Jul 2019
mikedn
on 17 Jul 2019
The only inline I see in TryDigitGenShortest that we might contemplate is BiggestPowerTen
Inlines into 060015A7 Grisu3:TryDigitGenShortest(byref,byref,byref,struct,byref,byref):bool
[1 IL=0019 TR=000013 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[2 IL=0040 TR=000025 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[3 IL=0049 TR=000033 0600159F] [profitable inline] DiyFp:Subtract(byref):struct:this
[4 IL=0019 TR=000449 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[5 IL=0076 TR=000053 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[0 IL=0136 TR=000092 060015A5] [FAILED: unprofitable inline] Grisu3:BiggestPowerTen(int,int,byref):int
[6 IL=0158 TR=000116 060003FB] [below ALWAYS_INLINE size] Math:DivRem(int,int,byref):int
[7 IL=0235 TR=000200 0600159F] [profitable inline] DiyFp:Subtract(byref):struct:this
[8 IL=0019 TR=000531 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[0 IL=0269 TR=000234 060015AA] [FAILED: too many il bytes] Grisu3:TryRoundWeedShortest(struct,int,long,long,long,long,long):bool
[9 IL=0323 TR=000271 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[10 IL=0410 TR=000353 0600159F] [profitable inline] DiyFp:Subtract(byref):struct:this
[11 IL=0019 TR=000592 0600159C] [below ALWAYS_INLINE size] DiyFp:.ctor(long,int):this
[0 IL=0438 TR=000383 060015AA] [FAILED: noinline per IL/cached result] Grisu3:TryRoundWeedShortest(struct,int,long,long,long,long,long):bool
It is currently about 4x away from being considered profitable by the jit.
Inline candidate has an arg that feeds a constant test. Multiplier increased to 1.
Inline candidate callsite is boring. Multiplier increased to 2.3.
calleeNativeSizeEstimate=1198
callsiteNativeSizeEstimate=145
benefit multiplier=2.3
threshold=333
Native estimate for function size exceeds threshold for inlining 119.8 > 33.3 (multiplier = 2.3)
Things might be different with IBC data, but I don't know offhand if this code gets hit in our IBC scenarios. Even if it did, IBC would only help the R2R codegen so eventually we'd tier away from it and lose any benefit IBC might provide.
I also don't see a lot of potential benefit from inlining BiggestPowerTen. It is only called once and has a loop that does not look like it would become any simpler if it was inlined.
AndyAyersMS
on 17 Jul 2019
As far as other codegen issues -- had thought perhaps the large number of in and out params here was a contributor, but changing the DiyFp to by-value (implicit by-ref) doesn't do much. Maybe the implicit byref struct promotion rules need tweaking. Will look more closely. Likewise having out int kappa control the first loop is not great, would be slightly better perhaps to modify the sources so as to have kappa be the return value, but that would require a bunch of changes elsewhere.
The allocator splits a loop backedge on the first loop and so we end up with a return block BB06 the first loop. Would be nice to be able to avoid this as we took pains earlier to move the return out of the loop, but not sure how much it really matters. cc @CarolEidt for an example where edge splitting puts non-loop code back into a loop.
fgFindInsertPoint(regionIndex=0, putInTryRegion=true, startBlk=BB01, endBlk=BB00, nearBlk=BB05, jumpBlk=BB00, runRarely=false)
fgNewBBinRegion(jumpKind=6, tryIndex=0, hndIndex=0, putInFilter=false, runRarely=false, insertAtEnd=false): inserting after BB06
New Basic Block BB10 [0021] created.
Splitting edge from BB05 to BB05; adding BB10
BB10 bottom: move V51 from rax to STK (Critical)
...
BB08 [0019] 2 BB02,BB04 4 [098..0E4)-> BB07 ( cond ) i target bwd LoopPH LIR
BB04 [0003] 1 BB08 4 0 [113..123)-> BB08 ( cond ) i label target bwd LIR
BB05 [0005] 3 BB02,BB04,BB10 4 [123..193)-> BB10 ( cond ) i Loop Loop0 label target bwd bwd-target LIR
BB06 [0006] 1 BB05 0.50 [193..1BC) (return) i gcsafe LIR
BB10 [0021] 1 BB05 2 [???..???)-> BB05 (always) internal target bwd LIR
I'm going to mark this as future -- nothing obvious for 3.0 jumps out here. I'll keep looking though.
AndyAyersMS
on 17 Jul 2019
VTune reports the following:
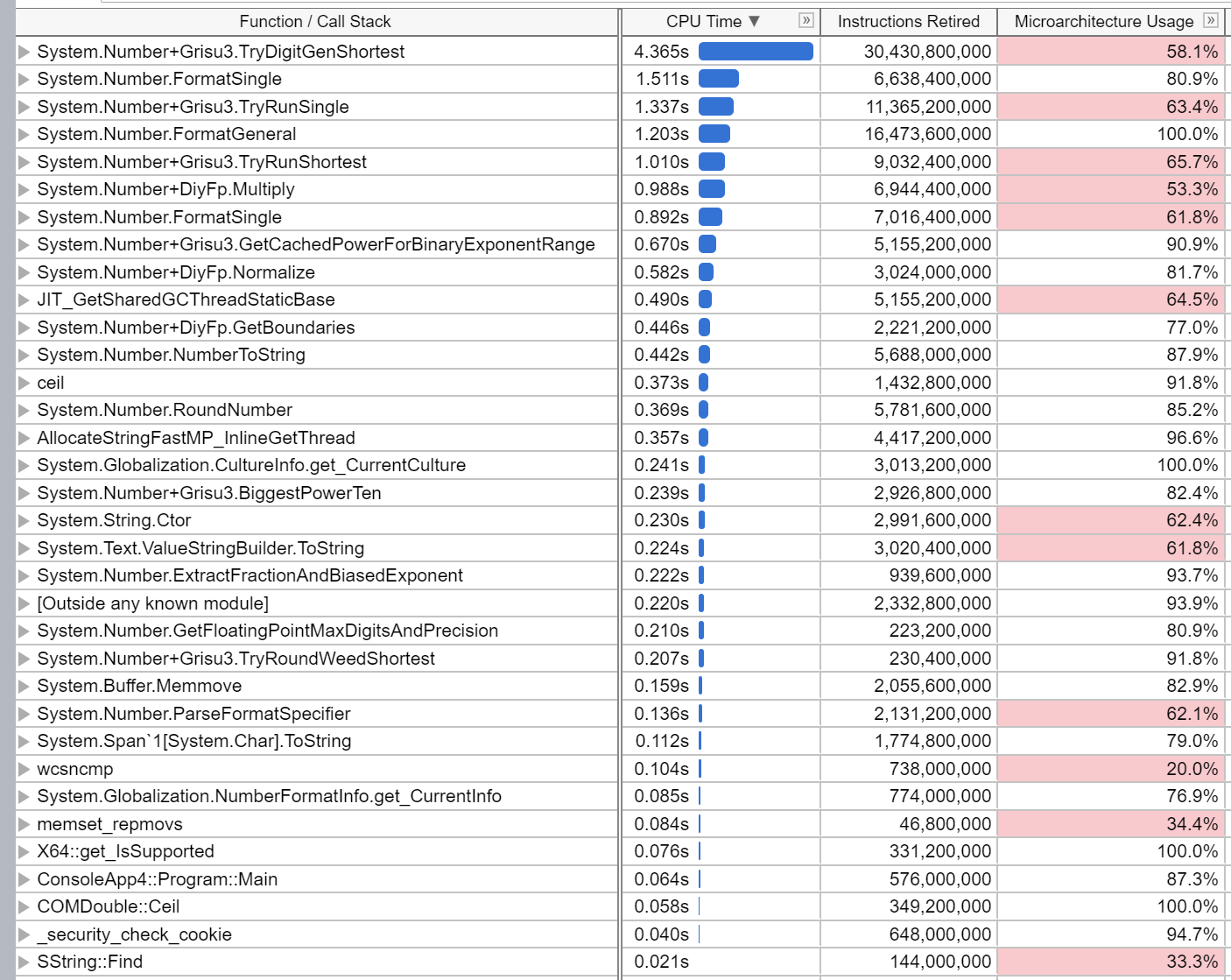
tannergooding
on 17 Jul 2019
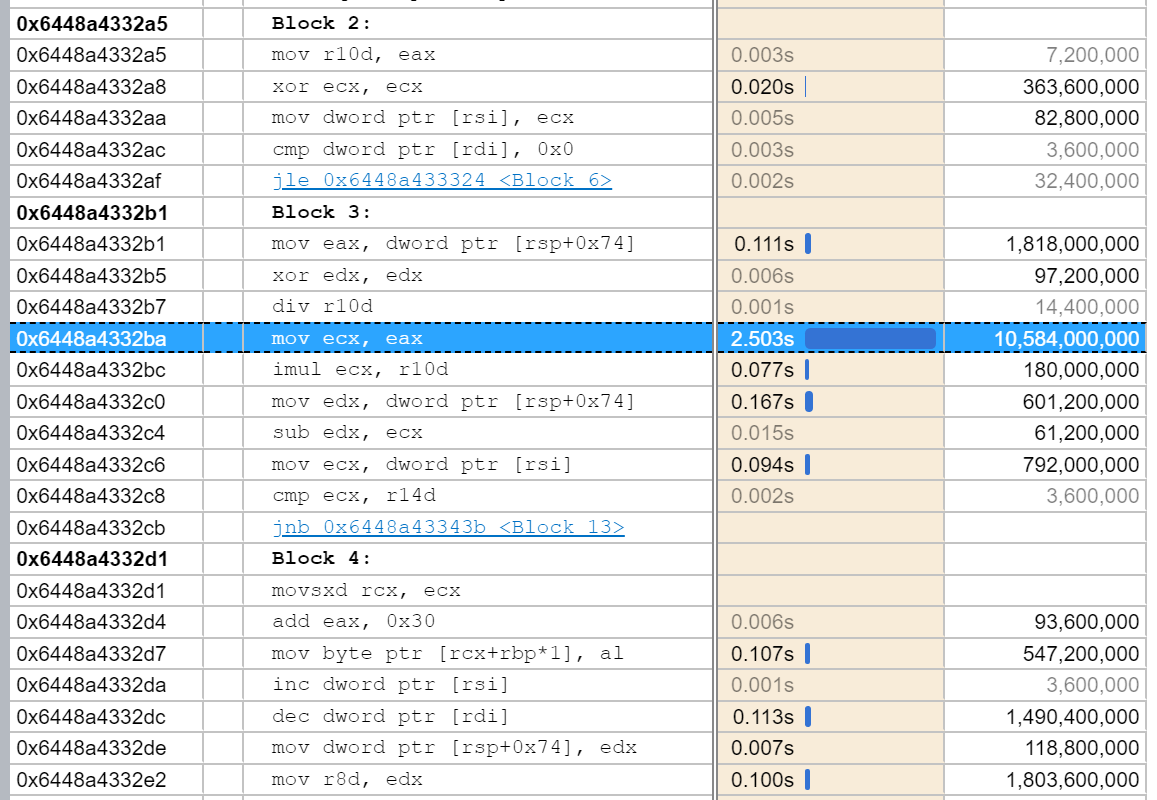
In, TryDigitRunShortest, the longest portion of time is naturally the div, which is taking 2.5s of the measured time. However, the additional imul is adding an additional .15 seconds of time:
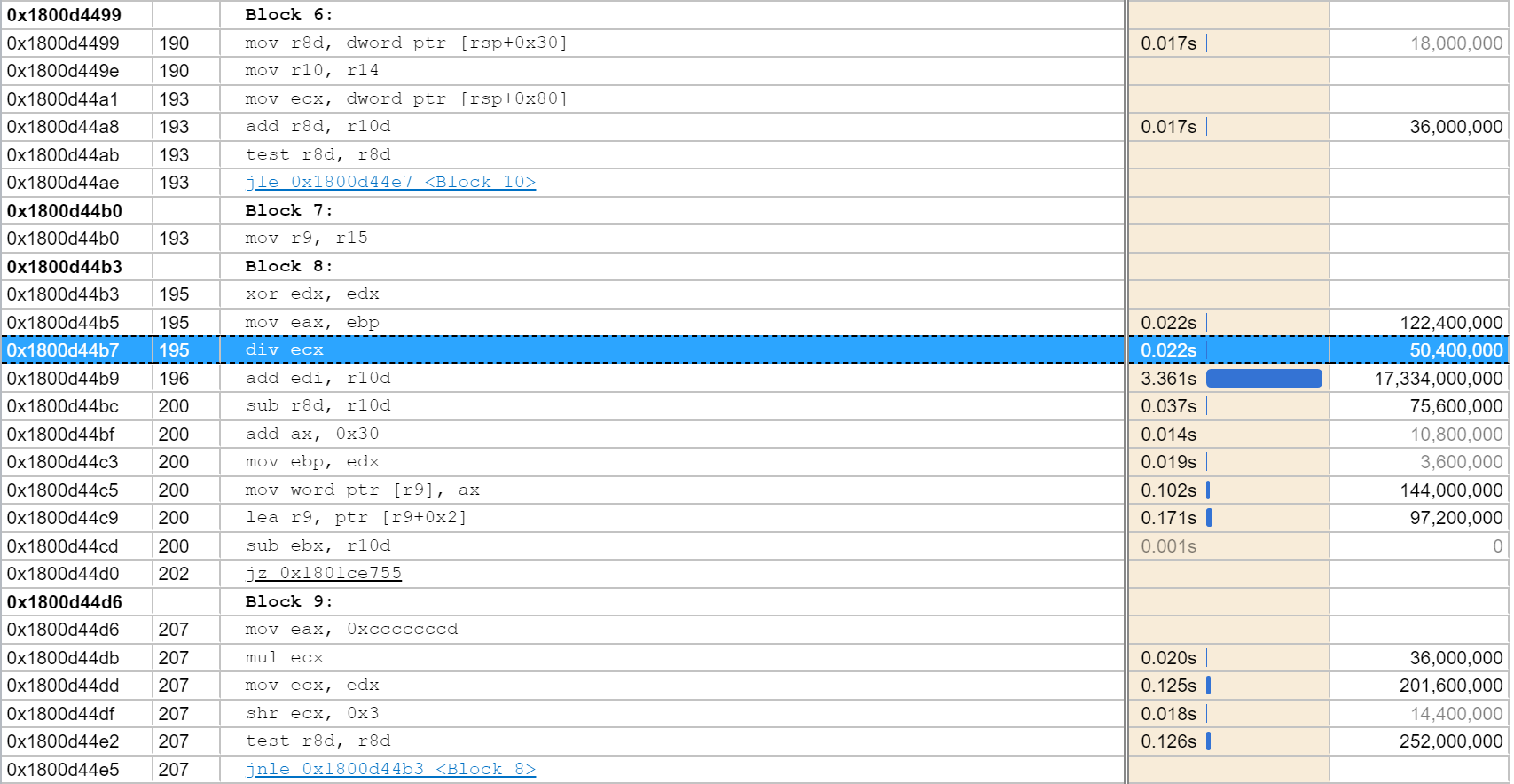
The same section from the 2.2 code in written in C++ is:
tannergooding
on 17 Jul 2019
The second most expensive function, FormatSingle, is spending just over half a second clearing out a buffer:
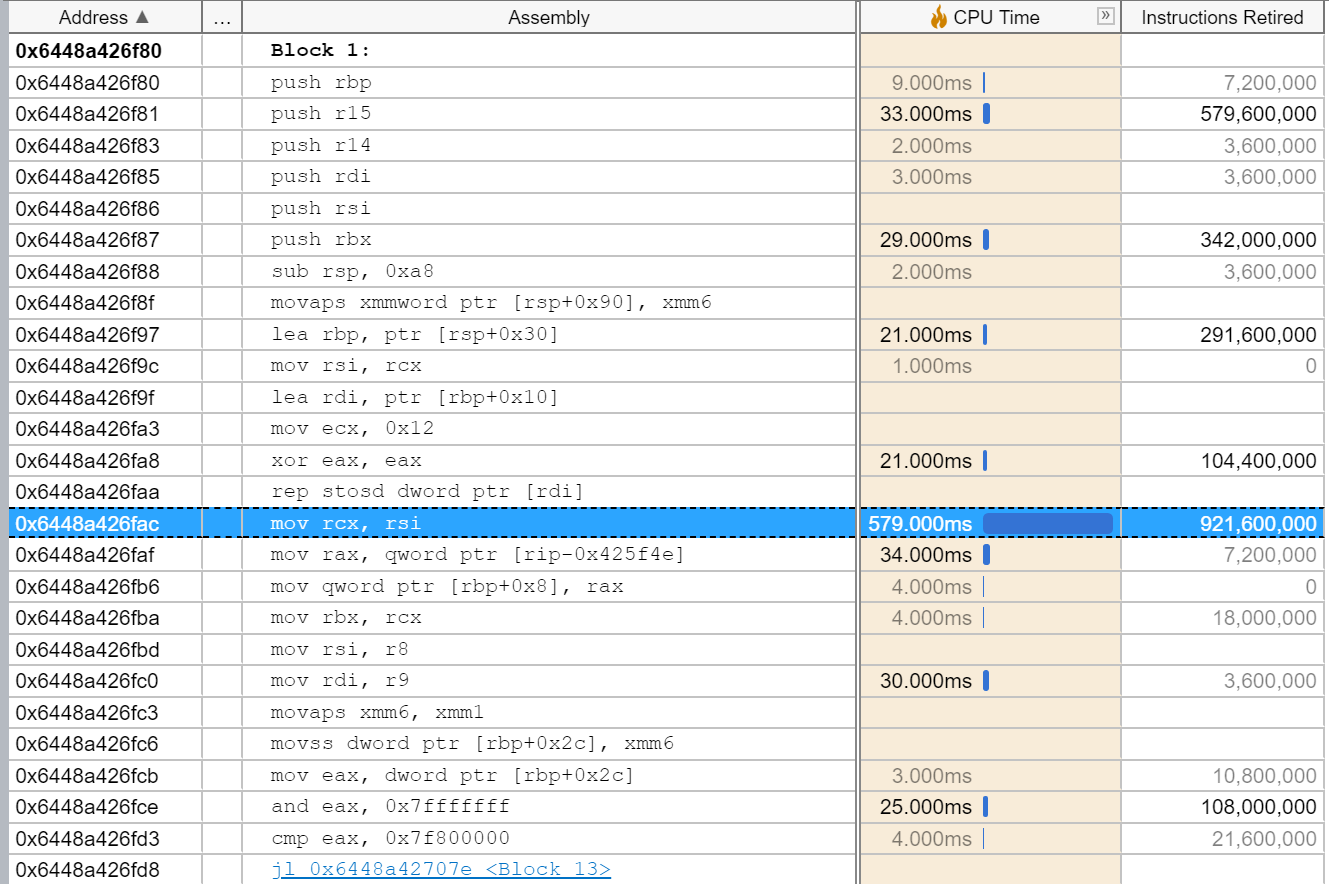
Likewise for the other FormatSingle and the TryRunSingle call that is happening
tannergooding
on 17 Jul 2019
Leaving aside the feasibility of improving this for 3.0, how impactful do we expect it to be to customers? Is formatting of typical numbers (eg 12345) with default setting (which I think is "G") potentially 25% slower? I'm guessing in some scenarios that would be quite noticeable?
danmosemsft
on 17 Jul 2019
Most .NET code likely uses double, rather than float (this includes things like WPF, WinForms, the default System.Math class), etc.
tannergooding
on 17 Jul 2019
@billwert any concerns about taking this regression in 3.0?
I didn't notice it didn't affect double, if that's the case I agree it's less interesting.
danmosemsft
on 17 Jul 2019
apisof.net indicates, 26.9% of apps run through API Port and 1.3% of apps on nuget.org use double.ToString(). Compare this to 14.4% and 0.4% for float. There are similar numbers for the other overloads.
tannergooding
on 17 Jul 2019
Looking at this in a future release is reasonable to me.
 billwert
on 18 Jul 2019
billwert
on 18 Jul 2019
@AndyAyersMS, for the bits that are cropping up due to genZeroInitFrame, has there been any considerations around using a small unrolled loop instead of rep stosd and are there any conditions under which genZeroInitFrame will be elided (I was looking and I didn't see an over-arching condition that would skip it)...
tannergooding
on 18 Jul 2019
I did some tweaking of the zero-init sequence for xarch in dotnet/coreclr#23498 to use straight-line codegen more often, and more could probably be done here.
Zero init in the prolog can be avoided when all GC refs are tracked. A common cause of untracked GC refs is passing GC ref locals or GC struct locals by-ref and/or using local GC structs that are too large to promote.
AndyAyersMS
on 18 Jul 2019
A common cause of untracked GC refs is passing GC ref locals or GC struct locals by-ref and/or using local GC structs that are too large to promote.
Would ref struct or Span<T> cause that?
For example, it was being done for both of the FormatSingle methods, one of which is simply:
https://github.com/dotnet/coreclr/blob/d9d31e6b03758abdd1621cf9da6fdd35b778a6fa/src/System.Private.CoreLib/shared/System/Number.Formatting.cs#L588-L593
tannergooding
on 18 Jul 2019
The other FormatSingle method a few lines down is quite a bit more complex, but almost all of these methods are only using value types to avoid allocations.
tannergooding
on 18 Jul 2019
Would
ref structorSpan<T>cause that?
Yes. The passing of ValueStringBuilder explicitly by ref qualifies, and in the above, the format string is implicitly converted at the call site to a span, and this span is passed implicitly by-ref.
Both structs have GC ref fields (1 in the span, and 2 in the VSB). The jit has some logic (perhaps not well motivated) to decide if zeroing the entire struct make sense even if only some fields are GC refs. Here it evidently decides it makes sense.
So there is a span struct of 16 bytes for the call arg, and the string builder struct is 32 bytes, both of which are entirely zeroed, and thus 48 bytes get zeroed in the prolog.
AndyAyersMS
on 18 Jul 2019
@tannergooding btw, any idea how gcc calculates the rem here https://godbolt.org/z/KlGMAR ? I don't get it 🙁
 EgorBo
on 18 Jul 2019
EgorBo
on 18 Jul 2019
GCC simply reuses the reminder returned by the DIV instruction.
mikedn
on 18 Jul 2019
So there is a span struct of 16 bytes for the call arg, and the string builder struct is 32 bytes, both of which are entirely zeroed, and thus 48 bytes get zeroed in the prolog.
Have we measured the impact of a call to memset vs the use of rep stosd? rep stosd has the setup overhead and is already not great performance for small arrays...
This would likely be a case where 3 16-byte stores would be beneficial to do, if possible. That is currently blocked, however, because we don't support setting GC refs via SIMD registers, correct? Is that something that could be special cased for genZeroInitFrame?
As an alternative fix, could probably not use ValueStringBuilder and switch back to passing the raw pointer. Based on the VTune numbers, there was at least ~1.5s being spent on these rep stosd calls, and I don't think that is great for something that is otherwise only taking ~15s to run.
tannergooding
on 18 Jul 2019
We're in the prolog, so making calls is problematic. It requires special care and usually some kind of bespoke calling convention (some native compilers do this for stack checks, for instance).
There's nothing blocking us from generating different code to zero the slots. We are not GC live at this point so can use whatever instructions will work. But we also would like to minimize the set of registers used and any shuffling needed around the zeroing sequence. For example REP STOS needs RCX which is usually live at this point -- so almost certainly the current heuristic is underestimating the cost of this kind of loop. It is worse on SysV.
So I think the way forward is
- review heuristics for when to generate block stores for prolog zeroing, especially cases when there are structs with both GC and non-GC fields. Likely we should be generating inline sequences for more cases than we do now.
- enable use of wider stores (say via XMM) to zero slots (which can decrease cost of inline sequences and make their use even more widespread) and update the heuristic accordingly.
- reconsider whether all these stack slots really need to be untracked lifetimes. In some cases we might be able to defer the zeroing until sometime later in the method, or avoid it all together.
The extra prolog costs that come up because a struct is used somewhere in the method can make it hard to reason about struct perf.
AndyAyersMS
on 18 Jul 2019
That sounds good/reasonable to me. It will also likely improve perf of various methods that are attempting to utilize things like Span/ValueStringBuilder as a perf optimization.
tannergooding
on 18 Jul 2019
@mikedn Is it worth to make DivRem intrinsic then? (I guess in my previous godot link LLVM just didn't recognize % operation). Or it's better to implement it in JIT (I wonder how difficult is that)
var z = x / y;
var r = x % y;
// to
var z = x / y;
var r = [mov]
Is it worth to make DivRem intrinsic then? (I guess in my previous godot link LLVM just didn't recognize % operation). Or it's better to implement it in JIT (I wonder how difficult is that)
See dotnet/runtime#4155. In short, even if you try to make it an intrinsic there are some problems with representing an operation that returns 2 values in JIT's IR (and even more advanced compilers can have problems with this kind of stuff). But at least with an intrinsic you avoid the need to recognize this pattern, which is a special case of redundancy that doesn't match anything the JIT does today.
Besides, DivRem was already improved by something like 80% when the % is used to do was replaced by multiplication which was a trivial thing to do. Now we're supposed to get the other 20% improvement by doing a costly JIT change? That's rather difficult to swallow.
mikedn
on 18 Jul 2019
@adamsitnik, should these issues be tracked in dotnet/runtime or dotnet/performance?
Do we know if they are still showing up in daily runs?
tannergooding
on 5 Mar 2020
Do we know if they are still showing up in daily runs?
Do you mean if we still can see the regression?
When I use the command from the issue description I get the following numbers:
git clone https://github.com/dotnet/performance.git
cd performance
py .\scripts\benchmarks_ci.py -f netcoreapp2.1 netcoreapp5.0 --filter System.Tests.Perf_Single.ToStringWithFormat
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
Intel Xeon CPU E5-1650 v4 3.60GHz, 1 CPU, 12 logical and 6 physical cores
.NET Core SDK=5.0.100-preview.2.20155.14
[Host] : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
Job-HMCHLD : .NET Core 2.1.11 (CoreCLR 4.6.27617.04, CoreFX 4.6.27617.02), X64 RyuJIT
Job-THWVBE : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
| Method | Runtime | value | format | Mean | Ratio | Allocated |
|------------------- |-------------- |--------------- |------- |-----------:|------:|----------:|
| ToStringWithFormat | .NET Core 2.1 | -3.4028235E+38 | E | 158.1 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | -3.4028235E+38 | E | 152.3 ns | 0.96 | 56 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | -3.4028235E+38 | F50 | 432.4 ns | 1.00 | 208 B |
| ToStringWithFormat | .NET Core 5.0 | -3.4028235E+38 | F50 | 1,326.5 ns | 3.07 | 208 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | -3.4028235E+38 | G | 152.7 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | -3.4028235E+38 | G | 176.5 ns | 1.16 | 56 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | -3.4028235E+38 | G17 | 171.4 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | -3.4028235E+38 | G17 | 201.0 ns | 1.17 | 72 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | -3.4028235E+38 | R | 256.9 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | -3.4028235E+38 | R | 177.5 ns | 0.69 | 56 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 12345 | E | 172.7 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | 12345 | E | 174.1 ns | 1.01 | 48 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 12345 | F50 | 324.9 ns | 1.00 | 144 B |
| ToStringWithFormat | .NET Core 5.0 | 12345 | F50 | 347.9 ns | 1.07 | 136 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 12345 | G | 144.6 ns | 1.00 | 40 B |
| ToStringWithFormat | .NET Core 5.0 | 12345 | G | 147.9 ns | 1.02 | 32 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 12345 | G17 | 162.5 ns | 1.00 | 40 B |
| ToStringWithFormat | .NET Core 5.0 | 12345 | G17 | 216.0 ns | 1.33 | 32 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 12345 | R | 170.7 ns | 1.00 | 40 B |
| ToStringWithFormat | .NET Core 5.0 | 12345 | R | 148.1 ns | 0.87 | 32 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 3.4028235E+38 | E | 149.8 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | 3.4028235E+38 | E | 149.6 ns | 1.00 | 48 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 3.4028235E+38 | F50 | 432.3 ns | 1.00 | 208 B |
| ToStringWithFormat | .NET Core 5.0 | 3.4028235E+38 | F50 | 1,344.8 ns | 3.11 | 208 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 3.4028235E+38 | G | 155.9 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | 3.4028235E+38 | G | 175.4 ns | 1.13 | 48 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 3.4028235E+38 | G17 | 162.8 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | 3.4028235E+38 | G17 | 200.9 ns | 1.23 | 72 B |
| | | | | | | |
| ToStringWithFormat | .NET Core 2.1 | 3.4028235E+38 | R | 249.3 ns | 1.00 | 56 B |
| ToStringWithFormat | .NET Core 5.0 | 3.4028235E+38 | R | 176.4 ns | 0.71 | 48 B |
adamsitnik
on 6 Mar 2020
On my AMD box, I currently see:
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET Core SDK=5.0.100-preview.2.20156.4
[Host] : .NET Core 2.1.11 (CoreCLR 4.6.27617.04, CoreFX 4.6.27617.02), X64 RyuJIT
Job-BQDCZY : .NET Core 2.1.11 (CoreCLR 4.6.27617.04, CoreFX 4.6.27617.02), X64 RyuJIT
PowerPlanMode=00000000-0000-0000-0000-000000000000 Runtime=.NET Core 2.1 Toolchain=netcoreapp2.1
IterationTime=250.0000 ms MaxIterationCount=20 MinIterationCount=15
WarmupCount=1
| Method | value | format | Mean | Error | StdDev | Median | Min | Max | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------------------- |-------------- |------- |---------:|--------:|--------:|---------:|---------:|---------:|-------:|------:|------:|----------:|
| ToStringWithFormat | -3.402823E+38 | E | 135.3 ns | 1.32 ns | 1.24 ns | 135.5 ns | 133.6 ns | 137.4 ns | 0.0336 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | F50 | 371.2 ns | 3.22 ns | 3.01 ns | 371.4 ns | 364.2 ns | 375.0 ns | 0.1241 | - | - | 208 B |
| ToStringWithFormat | -3.402823E+38 | G | 133.9 ns | 3.04 ns | 2.85 ns | 132.6 ns | 131.1 ns | 139.6 ns | 0.0337 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | G17 | 140.9 ns | 1.38 ns | 1.29 ns | 141.2 ns | 137.9 ns | 143.0 ns | 0.0332 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | R | 207.5 ns | 4.18 ns | 4.29 ns | 206.7 ns | 200.7 ns | 215.8 ns | 0.0332 | - | - | 56 B |
| ToStringWithFormat | 12345 | E | 139.9 ns | 1.88 ns | 1.76 ns | 139.1 ns | 137.8 ns | 142.9 ns | 0.0332 | - | - | 56 B |
| ToStringWithFormat | 12345 | F50 | 256.9 ns | 2.92 ns | 2.73 ns | 256.8 ns | 253.0 ns | 263.0 ns | 0.0862 | - | - | 144 B |
| ToStringWithFormat | 12345 | G | 121.5 ns | 1.23 ns | 1.15 ns | 121.4 ns | 119.6 ns | 123.2 ns | 0.0237 | - | - | 40 B |
| ToStringWithFormat | 12345 | G17 | 132.3 ns | 1.53 ns | 1.43 ns | 131.9 ns | 129.8 ns | 134.9 ns | 0.0236 | - | - | 40 B |
| ToStringWithFormat | 12345 | R | 142.0 ns | 1.98 ns | 1.85 ns | 141.7 ns | 139.9 ns | 146.1 ns | 0.0236 | - | - | 40 B |
| ToStringWithFormat | 3.402823E+38 | E | 134.9 ns | 1.03 ns | 0.96 ns | 134.7 ns | 133.1 ns | 136.5 ns | 0.0333 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | F50 | 367.0 ns | 2.83 ns | 2.64 ns | 366.4 ns | 361.0 ns | 370.5 ns | 0.1239 | - | - | 208 B |
| ToStringWithFormat | 3.402823E+38 | G | 132.8 ns | 2.57 ns | 2.40 ns | 132.7 ns | 128.7 ns | 138.0 ns | 0.0336 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | G17 | 140.7 ns | 0.84 ns | 0.75 ns | 140.7 ns | 139.2 ns | 141.8 ns | 0.0335 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | R | 208.2 ns | 4.10 ns | 4.03 ns | 206.4 ns | 203.5 ns | 214.9 ns | 0.0332 | - | - | 56 B |
vs
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET Core SDK=5.0.100-preview.2.20156.4
[Host] : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
Job-HVAISZ : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
PowerPlanMode=00000000-0000-0000-0000-000000000000 Runtime=.NET Core 5.0 Toolchain=netcoreapp5.0
IterationTime=250.0000 ms MaxIterationCount=20 MinIterationCount=15
WarmupCount=1
| Method | value | format | Mean | Error | StdDev | Median | Min | Max | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------------------- |--------------- |------- |-----------:|---------:|--------:|-----------:|---------:|-----------:|-------:|------:|------:|----------:|
| ToStringWithFormat | -3.4028235E+38 | E | 126.6 ns | 0.90 ns | 0.70 ns | 126.6 ns | 125.0 ns | 127.6 ns | 0.0067 | - | - | 56 B |
| ToStringWithFormat | -3.4028235E+38 | F50 | 1,004.0 ns | 7.04 ns | 6.59 ns | 1,003.6 ns | 993.4 ns | 1,014.5 ns | 0.0240 | - | - | 208 B |
| ToStringWithFormat | -3.4028235E+38 | G | 153.4 ns | 1.20 ns | 1.12 ns | 153.5 ns | 151.7 ns | 155.8 ns | 0.0062 | - | - | 56 B |
| ToStringWithFormat | -3.4028235E+38 | G17 | 162.7 ns | 3.29 ns | 3.66 ns | 165.1 ns | 155.7 ns | 167.2 ns | 0.0084 | - | - | 72 B |
| ToStringWithFormat | -3.4028235E+38 | R | 154.4 ns | 0.78 ns | 0.73 ns | 154.2 ns | 153.2 ns | 155.8 ns | 0.0063 | - | - | 56 B |
| ToStringWithFormat | 12345 | E | 139.5 ns | 1.09 ns | 1.02 ns | 139.5 ns | 137.8 ns | 141.0 ns | 0.0057 | - | - | 48 B |
| ToStringWithFormat | 12345 | F50 | 292.7 ns | 3.88 ns | 3.62 ns | 294.0 ns | 286.6 ns | 299.2 ns | 0.0155 | - | - | 136 B |
| ToStringWithFormat | 12345 | G | 119.9 ns | 1.41 ns | 1.32 ns | 120.1 ns | 118.1 ns | 122.1 ns | 0.0035 | - | - | 32 B |
| ToStringWithFormat | 12345 | G17 | 183.7 ns | 1.93 ns | 1.81 ns | 183.5 ns | 179.6 ns | 186.9 ns | 0.0038 | - | - | 32 B |
| ToStringWithFormat | 12345 | R | 120.3 ns | 2.00 ns | 1.87 ns | 119.3 ns | 118.2 ns | 123.1 ns | 0.0034 | - | - | 32 B |
| ToStringWithFormat | 3.4028235E+38 | E | 125.0 ns | 1.64 ns | 1.53 ns | 125.3 ns | 122.8 ns | 127.2 ns | 0.0052 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | F50 | 981.6 ns | 10.11 ns | 9.46 ns | 979.8 ns | 970.0 ns | 1,000.6 ns | 0.0233 | - | - | 208 B |
| ToStringWithFormat | 3.4028235E+38 | G | 150.8 ns | 1.00 ns | 0.94 ns | 150.9 ns | 149.1 ns | 152.3 ns | 0.0056 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | G17 | 159.7 ns | 3.04 ns | 3.12 ns | 159.7 ns | 155.6 ns | 166.7 ns | 0.0084 | - | - | 72 B |
| ToStringWithFormat | 3.4028235E+38 | R | 151.2 ns | 1.08 ns | 1.01 ns | 151.3 ns | 148.5 ns | 153.3 ns | 0.0055 | - | - | 48 B |
tannergooding
on 6 Mar 2020
A couple of these take longer because they aren't equivalent anymore:
E- Faster or on par with across the boardF50- Can't be compared accurately, the previous version cutoff at 15/17 digits. We now compute the full 50G- Not equivalent, the previous version was always G15. We now compute the minimum number needed for roundtripping (which might be less and might be more)G17- This one probably warrants a bit of investigation, I'd expect the same or similar timesR- Faster across the board, the previous version did more work by checking both G15 and G17
tannergooding
on 6 Mar 2020
I guess the whole float/double.ToString() thing will be significantly improved once we implement Ryu algorithm (https://github.com/dotnet/runtime/issues/10939) 🙂
EgorBo
on 6 Mar 2020
Actually, looking back over the comments from the last investigation I think it will likely be significantly improved by @benaadams https://github.com/dotnet/runtime/pull/32538 changes.
I'll need to build locally to test, however.
tannergooding
on 6 Mar 2020
Helps a bit, but still not quite on par for G17
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET Core SDK=5.0.100-preview.2.20154.3
[Host] : .NET Core 5.0.0 (CoreCLR 42.42.42.42424, CoreFX 42.42.42.42424), X64 RyuJIT
Job-EGMEOL : .NET Core 5.0.0 (CoreCLR 42.42.42.42424, CoreFX 42.42.42.42424), X64 RyuJIT
PowerPlanMode=00000000-0000-0000-0000-000000000000 Runtime=.NET Core 5.0 Toolchain=netcoreapp5.0
IterationTime=250.0000 ms MaxIterationCount=20 MinIterationCount=15
WarmupCount=1
| Method | value | format | Mean | Error | StdDev | Median | Min | Max | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------------------- |--------------- |------- |-----------:|--------:|--------:|-----------:|-----------:|-----------:|-------:|------:|------:|----------:|
| ToStringWithFormat | -3.4028235E+38 | E | 126.0 ns | 1.07 ns | 1.00 ns | 126.0 ns | 124.3 ns | 127.6 ns | 0.0062 | - | - | 56 B |
| ToStringWithFormat | -3.4028235E+38 | F50 | 1,015.8 ns | 9.27 ns | 8.67 ns | 1,014.7 ns | 1,004.3 ns | 1,032.4 ns | 0.0242 | - | - | 208 B |
| ToStringWithFormat | -3.4028235E+38 | G | 144.4 ns | 1.77 ns | 1.66 ns | 144.5 ns | 141.3 ns | 147.0 ns | 0.0065 | - | - | 56 B |
| ToStringWithFormat | -3.4028235E+38 | G17 | 164.4 ns | 1.25 ns | 1.04 ns | 164.5 ns | 162.2 ns | 166.2 ns | 0.0086 | - | - | 72 B |
| ToStringWithFormat | -3.4028235E+38 | R | 142.2 ns | 1.64 ns | 1.53 ns | 142.1 ns | 139.9 ns | 144.3 ns | 0.0065 | - | - | 56 B |
| ToStringWithFormat | 12345 | E | 137.0 ns | 1.23 ns | 1.15 ns | 137.0 ns | 135.5 ns | 138.6 ns | 0.0056 | - | - | 48 B |
| ToStringWithFormat | 12345 | F50 | 292.1 ns | 5.66 ns | 5.29 ns | 292.1 ns | 283.5 ns | 299.3 ns | 0.0156 | - | - | 136 B |
| ToStringWithFormat | 12345 | G | 118.2 ns | 1.14 ns | 1.06 ns | 118.6 ns | 116.4 ns | 119.9 ns | 0.0034 | - | - | 32 B |
| ToStringWithFormat | 12345 | G17 | 181.8 ns | 3.19 ns | 2.99 ns | 182.1 ns | 176.7 ns | 186.9 ns | 0.0036 | - | - | 32 B |
| ToStringWithFormat | 12345 | R | 111.9 ns | 0.95 ns | 0.89 ns | 111.8 ns | 110.6 ns | 113.7 ns | 0.0037 | - | - | 32 B |
| ToStringWithFormat | 3.4028235E+38 | E | 126.1 ns | 2.29 ns | 2.14 ns | 126.3 ns | 123.0 ns | 131.0 ns | 0.0056 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | F50 | 1,002.5 ns | 7.36 ns | 6.88 ns | 1,005.5 ns | 988.8 ns | 1,009.5 ns | 0.0239 | - | - | 208 B |
| ToStringWithFormat | 3.4028235E+38 | G | 142.7 ns | 1.30 ns | 1.21 ns | 142.3 ns | 141.2 ns | 145.2 ns | 0.0052 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | G17 | 161.7 ns | 2.12 ns | 1.98 ns | 162.2 ns | 157.1 ns | 163.7 ns | 0.0086 | - | - | 72 B |
| ToStringWithFormat | 3.4028235E+38 | R | 143.2 ns | 2.09 ns | 1.85 ns | 142.9 ns | 140.3 ns | 147.5 ns | 0.0052 | - | - | 48 B |
tannergooding
on 6 Mar 2020
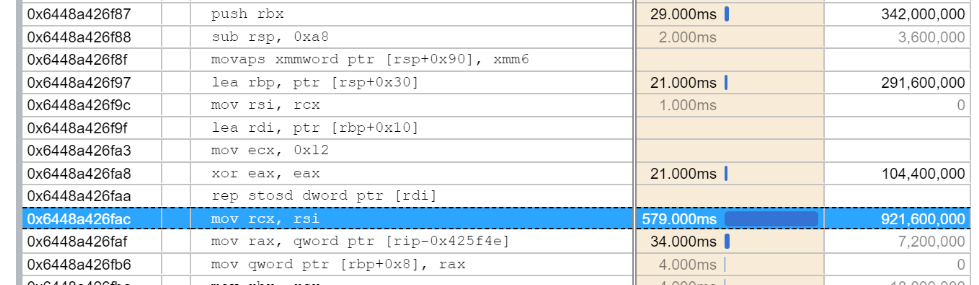
Looking at the FormatSingle the rep sosd looks like it comes from a different source than the prolog zeroing; so would still be emitted?
 benaadams
on 6 Mar 2020
benaadams
on 6 Mar 2020
Ah, actually I know why the numbers weren't making sense. This is for float and 2.1 clamped float precision requests to no more than 9 (defaulting to 7). If you request more than 9 digits, we have to do additional work as the underlying representation may not be fully exhausted.
If we look at the appropriate numbers for float, you'll see that the 7 and 9 digit cases are faster.
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET Core SDK=5.0.100-preview.2.20156.4
[Host] : .NET Core 2.1.11 (CoreCLR 4.6.27617.04, CoreFX 4.6.27617.02), X64 RyuJIT
Job-BQDCZY : .NET Core 2.1.11 (CoreCLR 4.6.27617.04, CoreFX 4.6.27617.02), X64 RyuJIT
PowerPlanMode=00000000-0000-0000-0000-000000000000 Runtime=.NET Core 2.1 Toolchain=netcoreapp2.1
IterationTime=250.0000 ms MaxIterationCount=20 MinIterationCount=15
WarmupCount=1
| Method | value | format | Mean | Error | StdDev | Median | Min | Max | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------------------- |-------------- |------- |---------:|--------:|--------:|---------:|---------:|---------:|-------:|------:|------:|----------:|
| ToStringWithFormat | -3.402823E+38 | G | 146.8 ns | 1.69 ns | 1.58 ns | 145.9 ns | 145.2 ns | 149.8 ns | 0.0335 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | G15 | 145.6 ns | 2.39 ns | 2.23 ns | 146.2 ns | 141.0 ns | 149.9 ns | 0.0336 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | G17 | 145.2 ns | 2.46 ns | 2.30 ns | 145.0 ns | 141.3 ns | 149.0 ns | 0.0336 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | G7 | 144.3 ns | 1.78 ns | 1.66 ns | 144.6 ns | 141.3 ns | 146.8 ns | 0.0337 | - | - | 56 B |
| ToStringWithFormat | -3.402823E+38 | G9 | 143.8 ns | 2.34 ns | 2.19 ns | 143.9 ns | 139.4 ns | 146.9 ns | 0.0334 | - | - | 56 B |
| ToStringWithFormat | 12345 | G | 120.4 ns | 0.86 ns | 0.80 ns | 120.5 ns | 118.9 ns | 121.5 ns | 0.0241 | - | - | 40 B |
| ToStringWithFormat | 12345 | G15 | 133.8 ns | 1.12 ns | 1.04 ns | 133.9 ns | 132.4 ns | 135.6 ns | 0.0238 | - | - | 40 B |
| ToStringWithFormat | 12345 | G17 | 133.5 ns | 0.96 ns | 0.85 ns | 133.7 ns | 131.9 ns | 135.0 ns | 0.0239 | - | - | 40 B |
| ToStringWithFormat | 12345 | G7 | 124.7 ns | 1.03 ns | 0.96 ns | 124.7 ns | 122.9 ns | 126.3 ns | 0.0237 | - | - | 40 B |
| ToStringWithFormat | 12345 | G9 | 132.9 ns | 1.61 ns | 1.51 ns | 133.2 ns | 129.8 ns | 135.1 ns | 0.0239 | - | - | 40 B |
| ToStringWithFormat | 3.402823E+38 | G | 143.6 ns | 2.80 ns | 2.62 ns | 143.7 ns | 139.5 ns | 147.6 ns | 0.0336 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | G15 | 146.0 ns | 2.91 ns | 2.72 ns | 146.1 ns | 140.6 ns | 150.4 ns | 0.0334 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | G17 | 143.5 ns | 1.68 ns | 1.57 ns | 143.3 ns | 141.5 ns | 146.7 ns | 0.0334 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | G7 | 143.7 ns | 3.02 ns | 3.48 ns | 145.3 ns | 137.0 ns | 148.4 ns | 0.0332 | - | - | 56 B |
| ToStringWithFormat | 3.402823E+38 | G9 | 146.1 ns | 1.84 ns | 1.72 ns | 146.2 ns | 143.3 ns | 149.5 ns | 0.0335 | - | - | 56 B |
vs
BenchmarkDotNet=v0.12.0, OS=Windows 10.0.18363
AMD Ryzen 9 3900X, 1 CPU, 24 logical and 12 physical cores
.NET Core SDK=5.0.100-preview.2.20156.4
[Host] : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
Job-HVAISZ : .NET Core 5.0.0 (CoreCLR 5.0.20.15501, CoreFX 5.0.20.15501), X64 RyuJIT
| Method | value | format | Mean | Error | StdDev | Median | Min | Max | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------------------- |--------------- |------- |---------:|--------:|--------:|---------:|---------:|---------:|-------:|------:|------:|----------:|
| ToStringWithFormat | -3.4028235E+38 | G | 152.3 ns | 2.56 ns | 2.40 ns | 152.2 ns | 147.9 ns | 155.7 ns | 0.0061 | - | - | 56 B |
| ToStringWithFormat | -3.4028235E+38 | G15 | 160.4 ns | 2.37 ns | 2.21 ns | 161.0 ns | 156.7 ns | 163.1 ns | 0.0072 | - | - | 64 B |
| ToStringWithFormat | -3.4028235E+38 | G17 | 164.4 ns | 2.80 ns | 2.62 ns | 164.6 ns | 160.3 ns | 170.1 ns | 0.0081 | - | - | 72 B |
| ToStringWithFormat | -3.4028235E+38 | G7 | 132.0 ns | 1.40 ns | 1.31 ns | 131.9 ns | 129.8 ns | 134.0 ns | 0.0054 | - | - | 48 B |
| ToStringWithFormat | -3.4028235E+38 | G9 | 137.7 ns | 2.78 ns | 2.98 ns | 138.4 ns | 131.4 ns | 143.4 ns | 0.0066 | - | - | 56 B |
| ToStringWithFormat | 12345 | G | 119.7 ns | 0.71 ns | 0.63 ns | 119.7 ns | 118.6 ns | 120.7 ns | 0.0034 | - | - | 32 B |
| ToStringWithFormat | 12345 | G15 | 188.6 ns | 2.71 ns | 2.54 ns | 188.5 ns | 185.5 ns | 194.6 ns | 0.0038 | - | - | 32 B |
| ToStringWithFormat | 12345 | G17 | 182.6 ns | 3.60 ns | 3.54 ns | 182.1 ns | 176.6 ns | 188.8 ns | 0.0037 | - | - | 32 B |
| ToStringWithFormat | 12345 | G7 | 120.0 ns | 1.25 ns | 1.17 ns | 119.8 ns | 118.3 ns | 122.0 ns | 0.0034 | - | - | 32 B |
| ToStringWithFormat | 12345 | G9 | 130.7 ns | 0.84 ns | 0.79 ns | 130.6 ns | 129.5 ns | 132.1 ns | 0.0038 | - | - | 32 B |
| ToStringWithFormat | 3.4028235E+38 | G | 152.6 ns | 1.17 ns | 1.10 ns | 152.5 ns | 149.8 ns | 154.5 ns | 0.0057 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | G15 | 155.0 ns | 2.57 ns | 2.40 ns | 155.3 ns | 150.6 ns | 158.5 ns | 0.0076 | - | - | 64 B |
| ToStringWithFormat | 3.4028235E+38 | G17 | 160.7 ns | 2.60 ns | 2.43 ns | 160.9 ns | 156.2 ns | 165.2 ns | 0.0080 | - | - | 72 B |
| ToStringWithFormat | 3.4028235E+38 | G7 | 127.2 ns | 1.59 ns | 1.49 ns | 127.3 ns | 123.7 ns | 129.4 ns | 0.0056 | - | - | 48 B |
| ToStringWithFormat | 3.4028235E+38 | G9 | 136.7 ns | 2.44 ns | 2.28 ns | 136.3 ns | 132.9 ns | 141.4 ns | 0.0065 | - | - | 56 B |
tannergooding
on 6 Mar 2020
And for reference from 2.1:
tannergooding
on 6 Mar 2020
Looking at the FormatSingle the rep sosd looks like it comes from a different source than the prolog zeroing; so would still be emitted
Ah, that's a bit unfortunate. I wonder which part of the system is emitting this one 🤔
tannergooding
on 6 Mar 2020
@adamsitnik, would a correct fix here be to update the Perf.Single test to cover G9, which is a more accurate comparison for floats?
tannergooding
on 6 Mar 2020
My mistake, looks like it did pick it up
G_M61719_IG01:
push rbp
push r15
push r14
push rdi
push rsi
push rbx
sub rsp, 168
movaps qword ptr [rsp+90H], xmm6
lea rbp, [rsp+30H]
xorps xmm4, xmm4
movaps xmmword ptr [rbp+10H], xmm4
movaps xmmword ptr [rbp+20H], xmm4
movaps xmmword ptr [rbp+30H], xmm4
movaps xmmword ptr [rbp+40H], xmm4
xor rax, rax
mov qword ptr [rbp+50H], rax
mov rax, qword ptr [(reloc)]
mov qword ptr [rbp+08H], rax
mov rbx, rcx
mov rsi, r8
mov rdi, r9
movaps xmm6, xmm1
would a correct fix here be to update the Perf.Single test to cover G9, which is a more accurate comparison for floats
sure, if this makes more sense to you then we should do that
adamsitnik
on 8 Jul 2020
Related issues
 yahorsi
·
3Comments
yahorsi
·
3Comments
 jzabroski
·
3Comments
jzabroski
·
3Comments
 bencz
·
3Comments
bencz
·
3Comments
 matty-hall
·
3Comments
matty-hall
·
3Comments
 sahithreddyk
·
3Comments
sahithreddyk
·
3Comments
Most helpful comment
We're in the prolog, so making calls is problematic. It requires special care and usually some kind of bespoke calling convention (some native compilers do this for stack checks, for instance).
There's nothing blocking us from generating different code to zero the slots. We are not GC live at this point so can use whatever instructions will work. But we also would like to minimize the set of registers used and any shuffling needed around the zeroing sequence. For example REP STOS needs RCX which is usually live at this point -- so almost certainly the current heuristic is underestimating the cost of this kind of loop. It is worse on SysV.
So I think the way forward is
The extra prolog costs that come up because a struct is used somewhere in the method can make it hard to reason about struct perf.