Runtime: Collect Optimization Candidates for Using Intel Hardware Intrinsics in mscorlib
Status of Intel hardware intrinsic work
At this time (12/13/2017), we have enabled all the infrastructures for Intel hardware intrinsic and certain scalar/SIMD intrinsics. The next step is to implement specific Intel hardware intrinsics.
Optimizing mscorlib using Intel hardware intrinsic
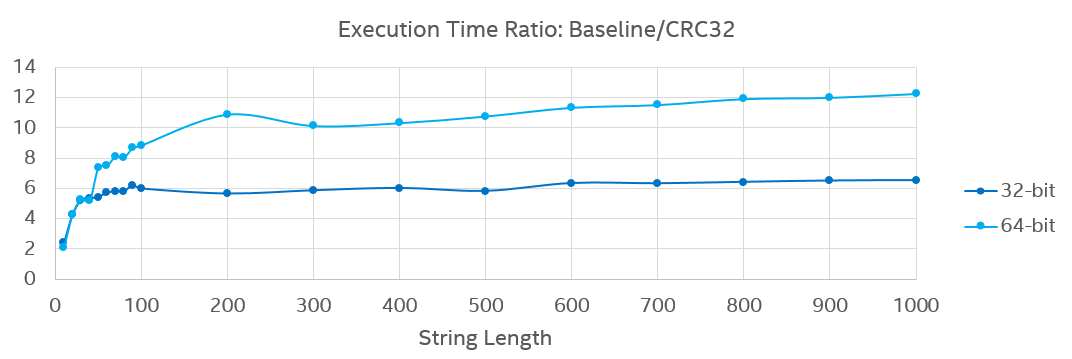
The base class library (mscorlib) is used by every .NET Core program, so its performance is critical, and we can use hardware intrinsics to improve performance of mscorlib by leveraging modern Intel Architecture instructions. For instance, we experimented rewriting the nonrandomized hash function of String with Sse42.Crc32 intrinsic in a micro-benchmark. The result showed that Crc32 version provided 2~5.5x(32-bit)/8.5x(64-bit) performance gain on short strings and 6.5x(32-bit)/12.3x(64-bit) gain hashing for longer strings.
Capturing optimization candidates
This issue attempts to capture a list of optimization candidates in mscorlib for taking advantage of Intel hardware intrinsics. We are looking for popular use cases from the community and mscorlib authors, and their input on how such methods could be optimized. For example, "we use method XYZ intensively, and if XYZ were to be optimized using intrinsic A and B, we may get X% performance gain". That kind of information could help steer subsequent intrinsic work, with highly demanded hardware intrinsics and many uses cases to have higher implementation priority. In addition, listed below are some general guidelines we plan to use when considering optimization candidates.
- We would prioritize 256-bit SIMD intrinsics (that operate over
Vector256<T>) higher because they have distinctive performance advantage over 128-bit SIMD intrinsics, and AVX/AVX2 machines (Sandy Bridge, Haswell, and above) are widely available and used. - We would prefer to fully implement an ISA class, then move to another one. When hardware intrinsics ship with the next release (.NET Core 2.1), "IsSupported" will be true only for fully implemented classes. For example, if we want
Sse42.Crc32available in .NET Core 2.1, other SSE4.2 intrinsics should also be implemented in CoreCLR.
 fiigii
fiigii
All 39 comments
cc @jkotas @CarolEidt @AndyAyersMS @stephentoub @eerhardt @tannergooding @benaadams @4creators
fiigii
on 13 Dec 2017
I don't think they are highly used, but System.Buffer.Memmove would likely benefit (adding non-temporal support for large buffers might also be useful).
System.Numerics.Vectors may benefit (although outside mscorlib)
Other general areas:
- System.String
- Regex
- Cryptography
 tannergooding
on 13 Dec 2017
tannergooding
on 13 Dec 2017
This isn't a specific answer, but I expect we'd see good wins if the methods on string (e.g. IndexOf, Equals, Compare, etc.) and on array (e.g. IndexOf, Sort if possible, etc.) were optimized with these intrinsics Those are used all over the place, including by other core types in corelib, e.g. List<T>.IndexOf uses Array.IndexOf.
 stephentoub
on 13 Dec 2017
stephentoub
on 13 Dec 2017
Not mscorlib but BitCount(long value) in Kestrel and CountBits in System.Reflection.Internal.BitArithmetic would work with popcnt (second could maybe be type forwarded?)
 benaadams
on 13 Dec 2017
benaadams
on 13 Dec 2017
@benaadams Popcnt is already implemented https://github.com/dotnet/coreclr/pull/14456. Would you like to give a try?
fiigii
on 13 Dec 2017
There are several implementations of performance critical functions for web based on SIMD both SSE2 - SSE42 and AVX2:
- Base64 encoding and decoding.
- General String search - String.Contains, String.IndexOf.
- Hash algorithms - there are specialized intrinsics like SHA but besides there are SSE/AVX2 optimized, reference implementations of major hashing algorithms including SHA3/Keccak.
- Pop count and leading/trailing zero count done faster even than intrinsics for longer streams (I do not recall threshold level though) realized in SSE/AVX2.
- Collections - Dictionaries/HashTables/Trees using latest algorithms - large group of new implementations on JVM mainly done in Scala world - not patented and open sourced under permissive licenses.
- Several new SSE/AVX imaging algorithms implementations ranging from image resizing (some are faster than Intel implementations in Intel Performance Primitives library) to color space conversions may suplement or replace some System.Drawing implementations - all open sourced with permissive licences.
- BigInteger arithmetic.
- Many more which I could not recall at the moment - will need to do some search in my collected articles.
 4creators
on 13 Dec 2017
4creators
on 13 Dec 2017
- General String search - String.Contains, String.IndexOf
- String encoding and decoding UTF8, UTF16, Base64
- GetHashCode() in string and other types
- Regex is a broad area to investigate and improve (.NET Core is 2 to 3 times slower than JVM)
 HFadeel
on 13 Dec 2017
HFadeel
on 13 Dec 2017
Encoding Utf8 <-> string, Ascii <-> string (vector widen/narrow)
benaadams
on 13 Dec 2017
.NET Core is 2 to 3 times slower than JVM
Is that still the case if you use a build from master with RegexOptions.Compiled? In 2.0 that flag did not do anything. If so, do you have a benchmark you could share?
@ViktorHofer is considering options for regex perf.
 danmosemsft
on 13 Dec 2017
danmosemsft
on 13 Dec 2017
Should have tagged @HFadeel for question above
danmosemsft
on 13 Dec 2017
fyi. @bartonjs @JeremyKuhne
danmosemsft
on 13 Dec 2017
@danmosemsft
I tried that out using @ViktorHofer's version of regex-redux https://github.com/ViktorHofer/CompiledRedux-Desktop-Vs-Core. I added the appropriate 2.2 preview SDK and the output is on par with the full framework.
Still it's roughly 2s slower than the original regex-redux java version from https://benchmarksgame.alioth.debian.org/u64q/program.php?test=regexredux&lang=java&id=3
BenchmarkDotNet=v0.10.11, OS=Windows 10 Redstone 3 [1709, Fall Creators Update] (10.0.16299.64)
Processor=Intel Core i7-4790K CPU 4.00GHz (Haswell), ProcessorCount=8
Frequency=3906248 Hz, Resolution=256.0001 ns, Timer=TSC
.NET Core SDK=2.2.0-preview1-007813
[Host] : .NET Core 2.1.0-preview1-26013-05 (Framework 4.6.26013.03), 64bit RyuJIT
Job-YJWDPO : .NET Framework 4.7 (CLR 4.0.30319.42000), 64bit RyuJIT-v4.7.2600.0
Job-IGBXGQ : .NET Core 2.0.3 (Framework 4.6.25815.02), 64bit RyuJIT
Job-XFRTQH : .NET Core 2.1.0-preview1-26013-05 (Framework 4.6.26013.03), 64bit RyuJIT
Jit=RyuJit Platform=X64 InvocationCount=1
LaunchCount=1 TargetCount=3 UnrollFactor=1
WarmupCount=1
| Method | Runtime | Toolchain | Mean | Error | StdDev | Gen 0 | Gen 1 | Gen 2 | Allocated |
|------- |-------- |-------------- |---------:|---------:|---------:|------------:|-----------:|-----------:|-----------:|
| Do | Clr | Default | 6.916 s | 0.6470 s | 0.0366 s | 385333.3333 | 64666.6667 | 11666.6667 | 2972.52 MB |
| Do | Core | .NET Core 2.0 | 10.523 s | 0.5107 s | 0.0289 s | 387000.0000 | 64000.0000 | 13000.0000 | 356.5 MB |
| Do | Core | .NET Core 2.1 | 6.439 s | 0.0590 s | 0.0033 s | 386000.0000 | 64333.3333 | 12333.3333 | 356.5 MB |
Java 9.0.1: 4,878875 s
 Tornhoof
on 14 Dec 2017
Tornhoof
on 14 Dec 2017
Thanks for measuring that. That's 30% slower than Java. Still plenty of room to improve, including perhaps intrinsics.
danmosemsft
on 14 Dec 2017
At the moment I am trying a few POCs on our codebase. I would really appreciate if I can make this algorithm to work for showcase purposes on a real workload :D
// This stops the JIT from accesing originalBuffer directly, as we know
// it is not mutable, this lowers the number of generated instructions
byte* originalPtr = (byte*)originalBuffer;
byte* modifiedPtr = (byte*)modifiedBuffer;
var zero = Avx.SetZero<byte>();
for (long i = 0; i < len; i += 32, originalPtr += 32, modifiedPtr += 32)
{
var o0 = Avx.Load(originalPtr);
var m0 = Avx.Load(modifiedPtr);
if (allZeros)
allZeros &= Avx.TestZ(m0, zero);
if (Avx.TestZ(o0, m0))
continue;
/// ...
/// Lots of stuff that I still don't know if it makes sense to try to go SIMD too.
/// Not interesting for the purposes of making this work :D
}
 redknightlois
on 22 Dec 2017
redknightlois
on 22 Dec 2017
@redknightlois Thank you so much to report this demand. I will implement SetZero and TestZ after the new year.
fiigii
on 22 Dec 2017
I tried popcnt in my RoaringBitmap implementation https://github.com/Tornhoof/RoaringBitmap/blob/netcore2.1/RoaringBitmap/Util.cs
Works fine, Benchmarks show a slight performance increase
Tornhoof
on 22 Dec 2017
@Tornhoof Popcnt is a 3-cycle latency instruction. Could you try to unroll the loop to leverage the CPU pipeline to maximize instruction-level parallelism?
for (int i = 0; i < XXX; i += 3)
{
res1 += Popcnt.PopCount(data[i]);
res2 += Popcnt.PopCount(data[i + 1]);
res3 += Popcnt.PopCount(data[i + 2]);
}
res = res1 + res2 + res3;
Here is my Crc32 example https://gist.github.com/fiigii/60e01e9f68628a08f1b8b9cfa40d0011#file-crcbench-cs-L118-L123.
fiigii
on 22 Dec 2017
@fiigii Thank you for your advise, the unrolling increased the performance by another 1-4% (depending on benchmark). This is consistent with a direct benchmark of both variants, where the unrolled one is 5% faster.
https://github.com/Tornhoof/RoaringBitmap/blob/netcore2.1/RoaringBitmap/BitmapContainer.cs#L450-L466
Tornhoof
on 22 Dec 2017
@Tornhoof Your code has additional data dependency in the loop. I guess the code below maybe faster.
if (Popcnt.IsSupported && Environment.Is64BitProcess)
{
long longResult = 0;
long p1 = 0, p2 = 0, p3 = 0;
for (int i = 0; i + 3 <= BitmapLength; i += 3)
{
p1 += Popcnt.PopCount(xArray[i]);
p2 += Popcnt.PopCount(xArray[i + 1]);
p3 += Popcnt.PopCount(xArray[i + 2]);
}
longResult += p1 + p2 + p3 + Popcnt.PopCount(xArray[BitmapLength - 1]);
return (int) longResult;
}
@fiigii Yes your method is faster, apparently it's even faster to simply add up the counts without any additional variables ark https://gist.github.com/Tornhoof/a35f0bc652aad038556d22dcdd478ef7
Tornhoof
on 23 Dec 2017
@fiigii Here is a microbenchmark I was implementing as a first step. https://github.com/Corvalius/ravendb/commit/48e0516f3a4ecace6de4abd0fecc7ec2e426dde5
Given I couldn't run them I am not entirely sure they would work as expected, they look about right but I may have made a few mistakes here and there. There are both SSE and AVX implementations there. I will be on vacations until the 15th, but I wanted to give you access to the actual code to work on.
Hoping you are having a great time in yours. Cy
EDIT: I could use Prefetch for another of the POCs I am working on :)
redknightlois
on 26 Dec 2017
I put up https://github.com/dotnet/corefx/pull/26190 for using popcnt in System.Reflection.Metadata. Thanks for the suggestion @benaadams.
 eerhardt
on 5 Jan 2018
eerhardt
on 5 Jan 2018
Regarding string.Compare(), see the pcmpxstrx instructions in SSE4.2. Some more info here:
How the JVM compares your strings using the craziest x86 instruction you've never heard of
 colgreen
on 7 Jan 2018
colgreen
on 7 Jan 2018
@colgreen I was going to request the following instructions cause I have a use case that I am testing that could use them (both AVX and SSE4.2):
int _mm_cmpistri (__m128i a, __m128i b, const int mode);
int _mm_cmpistra (__m128i a, __m128i b, const int mode);
int _mm_cmpistrc (__m128i a, __m128i b, const int mode);
int _mm_cmpistro (__m128i a, __m128i b, const int mode);
int _mm_cmpistrs (__m128i a, __m128i b, const int mode);
int _mm_cmpistrz (__m128i a, __m128i b, const int mode);
So I second your request!!
redknightlois
on 17 Jan 2018
@redknightlois They are comming https://github.com/dotnet/coreclr/blob/abe3c4635e2fcfcc928aa01903b873c2fca2a614/src/mscorlib/src/System/Runtime/Intrinsics/X86/Sse42.cs#L91-L109
 Suchiman
on 17 Jan 2018
Suchiman
on 17 Jan 2018
Just to let you know the goodies are at test already :D
Some algorithmic changes and PopCount :)
// * Summary *
BenchmarkDotNet=v0.10.12, OS=Windows 10 Redstone 3 [1709, Fall Creators Update] (10.0.16299.192)
Intel Core i7-7700 CPU 3.60GHz (Kaby Lake), 1 CPU, 8 logical cores and 4 physical cores
Frequency=3515623 Hz, Resolution=284.4446 ns, Timer=TSC
.NET Core SDK=2.2.0-preview1-007987
[Host] : .NET Core 2.1.0-preview2-26128-03 (Framework 4.6.26127.01), 64bit RyuJIT
Job-RAXYHW : .NET Core 2.1.0-preview2-26128-03 (Framework 4.6.26127.01), 64bit RyuJIT
Jit=RyuJit Platform=X64 Runtime=Core
Method | KeySize | Mean | Error | StdDev | StdErr | Min | Q1 | Median | Q3 | Max | Op/s | Scaled | ScaledSD |
----------------------------------- |-------- |-----------:|----------:|----------:|----------:|------------:|------------:|-----------:|-----------:|-----------:|--------------:|-------:|---------:|
Original_NoCacheMisses | 1024 | 55.616 ns | 0.9335 ns | 0.8732 ns | 0.2255 ns | 53.9232 ns | 54.9808 ns | 55.480 ns | 56.252 ns | 57.268 ns | 17,980,533.5 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 1024 | 36.711 ns | 0.3075 ns | 0.2876 ns | 0.0743 ns | 36.1463 ns | 36.5031 ns | 36.620 ns | 36.997 ns | 37.216 ns | 27,239,765.1 | 0.66 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 127 | 9.596 ns | 0.0089 ns | 0.0069 ns | 0.0020 ns | 9.5845 ns | 9.5903 ns | 9.598 ns | 9.600 ns | 9.609 ns | 104,210,221.2 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 127 | 8.735 ns | 0.0456 ns | 0.0381 ns | 0.0106 ns | 8.6846 ns | 8.6974 ns | 8.735 ns | 8.760 ns | 8.804 ns | 114,480,657.9 | 0.91 | 0.00 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 128 | 7.922 ns | 0.0138 ns | 0.0108 ns | 0.0031 ns | 7.9021 ns | 7.9155 ns | 7.923 ns | 7.927 ns | 7.941 ns | 126,236,708.8 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 128 | 7.711 ns | 0.0080 ns | 0.0075 ns | 0.0019 ns | 7.7016 ns | 7.7051 ns | 7.711 ns | 7.717 ns | 7.729 ns | 129,676,552.9 | 0.97 | 0.00 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 15 | 1.848 ns | 0.0186 ns | 0.0155 ns | 0.0043 ns | 1.8324 ns | 1.8359 ns | 1.847 ns | 1.857 ns | 1.889 ns | 541,117,189.4 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 15 | 2.152 ns | 0.0036 ns | 0.0032 ns | 0.0009 ns | 2.1467 ns | 2.1490 ns | 2.153 ns | 2.154 ns | 2.158 ns | 464,690,065.0 | 1.16 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 16 | 2.200 ns | 0.0210 ns | 0.0197 ns | 0.0051 ns | 2.1721 ns | 2.1897 ns | 2.198 ns | 2.219 ns | 2.238 ns | 454,611,633.0 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 16 | 1.001 ns | 0.0022 ns | 0.0019 ns | 0.0005 ns | 0.9978 ns | 0.9997 ns | 1.002 ns | 1.003 ns | 1.003 ns | 998,716,960.3 | 0.46 | 0.00 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 2048 | 108.962 ns | 1.8411 ns | 1.7221 ns | 0.4447 ns | 106.3051 ns | 107.2436 ns | 108.730 ns | 110.405 ns | 111.689 ns | 9,177,474.2 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 2048 | 77.508 ns | 1.3582 ns | 1.2704 ns | 0.3280 ns | 75.3437 ns | 76.5977 ns | 77.157 ns | 78.636 ns | 79.678 ns | 12,901,877.6 | 0.71 | 0.02 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 24 | 3.237 ns | 0.0178 ns | 0.0157 ns | 0.0042 ns | 3.2104 ns | 3.2270 ns | 3.233 ns | 3.242 ns | 3.266 ns | 308,932,500.2 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 24 | 1.302 ns | 0.0207 ns | 0.0193 ns | 0.0050 ns | 1.2723 ns | 1.2774 ns | 1.311 ns | 1.314 ns | 1.324 ns | 768,338,295.6 | 0.40 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 256 | 13.536 ns | 0.1513 ns | 0.1415 ns | 0.0365 ns | 13.3550 ns | 13.4065 ns | 13.490 ns | 13.719 ns | 13.733 ns | 73,878,672.1 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 256 | 11.965 ns | 0.0724 ns | 0.0642 ns | 0.0172 ns | 11.8509 ns | 11.9356 ns | 11.962 ns | 12.025 ns | 12.046 ns | 83,578,643.6 | 0.88 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 31 | 2.640 ns | 0.0089 ns | 0.0070 ns | 0.0020 ns | 2.6333 ns | 2.6343 ns | 2.638 ns | 2.640 ns | 2.655 ns | 378,845,016.7 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 31 | 2.710 ns | 0.0223 ns | 0.0174 ns | 0.0050 ns | 2.6649 ns | 2.7058 ns | 2.709 ns | 2.716 ns | 2.740 ns | 369,033,127.7 | 1.03 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 32 | 4.168 ns | 0.0621 ns | 0.0550 ns | 0.0147 ns | 4.0813 ns | 4.1316 ns | 4.158 ns | 4.205 ns | 4.299 ns | 239,904,312.4 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 32 | 1.803 ns | 0.0069 ns | 0.0058 ns | 0.0016 ns | 1.7946 ns | 1.7989 ns | 1.803 ns | 1.805 ns | 1.815 ns | 554,582,507.5 | 0.43 | 0.01 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 4096 | 207.283 ns | 2.4131 ns | 2.2572 ns | 0.5828 ns | 204.6044 ns | 205.3470 ns | 206.709 ns | 208.680 ns | 211.741 ns | 4,824,316.3 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 4096 | 146.092 ns | 2.9256 ns | 3.2518 ns | 0.7460 ns | 141.8235 ns | 143.9715 ns | 145.151 ns | 148.145 ns | 152.890 ns | 6,845,016.5 | 0.70 | 0.02 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 64 | 4.147 ns | 0.0445 ns | 0.0416 ns | 0.0107 ns | 4.1005 ns | 4.1105 ns | 4.135 ns | 4.180 ns | 4.247 ns | 241,159,532.8 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 64 | 3.762 ns | 0.1109 ns | 0.1403 ns | 0.0292 ns | 3.5834 ns | 3.6689 ns | 3.710 ns | 3.838 ns | 4.071 ns | 265,814,756.9 | 0.91 | 0.03 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 7 | 1.546 ns | 0.0279 ns | 0.0247 ns | 0.0066 ns | 1.5197 ns | 1.5237 ns | 1.535 ns | 1.565 ns | 1.591 ns | 646,696,994.8 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 7 | 1.746 ns | 0.0275 ns | 0.0258 ns | 0.0067 ns | 1.7078 ns | 1.7272 ns | 1.746 ns | 1.757 ns | 1.796 ns | 572,879,975.3 | 1.13 | 0.02 |
| | | | | | | | | | | | | |
Original_NoCacheMisses | 8 | 1.583 ns | 0.0036 ns | 0.0021 ns | 0.0007 ns | 1.5790 ns | 1.5822 ns | 1.583 ns | 1.585 ns | 1.586 ns | 631,583,575.7 | 1.00 | 0.00 |
ScalarCmpXorPopCount_NoCacheMisses | 8 | 1.036 ns | 0.0042 ns | 0.0037 ns | 0.0010 ns | 1.0306 ns | 1.0333 ns | 1.036 ns | 1.039 ns | 1.045 ns | 964,827,465.7 | 0.65 | 0.00 |
I now need PREFETCH and I can fix the CacheMisses version too :)
redknightlois
on 29 Jan 2018
@redknightlois Thank you for the data. PREFETCH intrinsics are comming https://github.com/dotnet/coreclr/pull/15923
fiigii
on 30 Jan 2018
Just for reference, so we can close it when done: https://github.com/dotnet/coreclr/issues/5025
redknightlois
on 1 Feb 2018
@fiigii Just to let you know that we have put the PREFETCH instruction to the test already ;)

Interestingly enough, it appears we are running as fast as we can.

Unless of course using bigger registers also prime the prefetcher in a different way, therefore I can only concentrate prefetches over the L3 cache instead.
EDIT: For the record the code this is the code from dotnet/runtime#5869 with a reworked algorithm to be more cache efficient. The original had a two modes distribution on the 15Gb/sec and 1Gb/sec :)
redknightlois
on 16 Feb 2018
@redknightlois Thank you so much for the data. I will implement AVX/SSE4.1 TestZ as soon as possible (probably after next week).
fiigii
on 16 Feb 2018
@redknightlois, was this using the Sse.Prefetch instruction?
tannergooding
on 16 Feb 2018
@tannergooding yes a mixture of prefetches to L3 from DRAM and per loop prefetching 256 bytes ahead.
redknightlois
on 16 Feb 2018
We are still not there yet, but @zpodlovics comment on thread: https://github.com/dotnet/coreclr/issues/916#issuecomment-366562117 is also true for us. I mentioned @fiigii out-of-band that we are looking into that particularly in the mid-term but makes sense to make it explicit here too.
redknightlois
on 19 Feb 2018
@fiigii With the prefetch instruction we should provide a way to know the stride and that the JIT would convert that value straight into a constant when using it.
7.6.3.3 Determine Prefetch Stride
The prefetch stride (see description of CPUID.01H.EBX) provides the length of the region that the
processor will prefetch with the PREFETCHh instructions (PREFETCHT0, PREFETCHT1, PREFETCHT2 and
PREFETCHNTA). Software will use the length as the stride when prefetching into a particular level of the
cache hierarchy as identified by the instruction used. The prefetch size is relevant for cache types of Data
Cache (1) and Unified Cache (3); it should be ignored for other cache types. Software should not assume
that the coherency line size is the prefetch stride.
If the prefetch stride field is zero, then software should assume a default size of 64 bytes is the prefetch
stride. Software should use the following algorithm to determine what prefetch size to use depending on
whether the deterministic cache parameter mechanism is supported or the legacy mechanism:
- If a processor supports the deterministic cache parameters and provides a non-zero prefetch size,
then that prefetch size is used.
- If a processor supports the deterministic cache parameters and does not provides a prefetch size
then default size for each level of the cache hierarchy is 64 bytes.
- If a processor does not support the deterministic cache parameters but provides a legacy prefetch
size descriptor (0xF0 - 64 byte, 0xF1 - 128 byte) will be the prefetch size for all levels of the cache
hierarchy.
- If a processor does not support the deterministic cache parameters and does not provide a legacy
prefetch size descriptor, then 32-bytes is the default size for all levels of the cache hierarchy.
@redknightlois, I think it might be generally useful to expose access to CPUID (via hardware intrinsics) so that users can make queries about the system directly and so we don't need to worry about exposing an API for each bit added in the future (C/C++ commonly provide a CPUID intrinsic themselves).
tannergooding
on 20 Feb 2018
@tannergooding While I agree, there is a performance angle why certain constants would be pretty useful to continue being constants for performance purposes.
EDIT: In a sense they are late binding constants, but the runtime has no concept for those.
redknightlois
on 20 Feb 2018
I'm definitely interested in the string operations (IndexOf, Equals, Compare, GetHashCode) and also String.Split (or, better, an overload of split which didn't make new strings).
There's no CLR method today, but I also do array search (both equality and range queries) with SIMD instructions with huge performance gains. It'd be nice to have something like "BitVector Array.IndexOfAll(Operator op, T value)" which used SIMD underneath.
 ScottLouvau
on 27 Mar 2018
ScottLouvau
on 27 Mar 2018
(or, better, an overload of split which didn't make new strings
@vScottLouvau
Pretty sure that has already been achieved as part of the work around Span
colgreen
on 28 Mar 2018
A lot of this was implemented already or there are specific issues opened. Let's close this issue and start tracking this area via specific issues.
 jkotas
on 8 Jul 2019
jkotas
on 8 Jul 2019
Related issues
jkotas
·
3Comments
 jchannon
·
3Comments
jchannon
·
3Comments
 nalywa
·
3Comments
nalywa
·
3Comments
 v0l
·
3Comments
v0l
·
3Comments
 EgorBo
·
3Comments
EgorBo
·
3Comments
Most helpful comment
Encoding
Utf8 <-> string, Ascii <-> string (vector widen/narrow)