Rubberduck: Parse tree visualizer for Visual Studio
Justification
This wiki page recommends installing Eclipse and an Eclipse plugin in order to view the parse tree. Writing a debugging visualizer for Visual Studio is relatively straightforward.
Description
I would consider writing a custom debugging visualizer for this purpose (I've done something comparable already).
Additional context
Questions:
- To which type(s) should such a debugging visualizer be attached?
- What information should be shown?
It might also be possible to reuse any controls developed for the visualizer, in Rubberduck itself.
 zspitz
zspitz
All 28 comments
I would absolutely love to see this available natively in Visual Studio. Having to install Eclipse and getting the plugin is a huge PITA in itself, especially for those unfamiliar with Eclipse's idiosyncrasies.
I'm not 100% sure whether the same visualizer would be used between the Visual Studio (e.g. the contributors of Rubberduck project) and the Rubberduck's end users. I don't think the parse tree is that terribly useful to those unfamiliar with the ANTLR, and there are far much more nodes than what would be interesting to those users. I can see the users wanting something akin to a Code Map whereas contributors would want the parse tree visualizers for conceptualizing the tree and writing an inspection on it.
I suspect the parse tree visualizer will be useful to any projects that uses C# port of ANTLR, so it wouldn't be just the Rubberduck contributors who would benefit from having such visualizer.
We presently use WPF containers so if the visualizer is written in WPF, we would be able to re-expose it in Rubberduck, and if the results can be filtered we might be able to use a simplified representation of the parse tree to reduce the amount of noise for the end users who are more likely to be interested in procedures, arguments, and variables as opposed to individual syntactical elements and language constructs.
So I think a visualizer that allows us to specify which nodes we want to display would probably have the maximum reach, benefiting both type of audiences discussed.
 bclothier
on 4 Jun 2019
bclothier
on 4 Jun 2019
A setting to allow control of the level of detail visible in RD would be most helpful to those who write VBA but don't have a full, complete, in-depth understanding of what's going on. This could be a learning/teaching tool in addition!
 daFreeMan
on 4 Jun 2019
daFreeMan
on 4 Jun 2019
And visually see why inspections suggested by RD reflect a change in programming practice too.
 PeterMTaylor
on 4 Jun 2019
PeterMTaylor
on 4 Jun 2019
I envision the visualizer as targeting a specific type from Antlr4.Runtime, and to have the following parts in a minimum working version:
- Treeview, showing nodes of the parse tree
The default item template would be to show the type name of the node, but I think this ought to be customizable - Source, with selection of the tree node selecting the corresponding source, and vice versa
- Properties -- Because the target type may have many derived types, each with different information, there has to be some way to see additional properties for a given node.
Things to add in later:
- Customizable item templates for the tree view
- Filtering which node types should be shown in the tree view. This involves building a list of concrete types that inherit from / implement the target type(s), and allowing the user to select which ones to show.
- Persistence of settings -- I still haven't found a good way to persist settings between visualizer sessions.
I still need to resolve what type(s) the visualizer should target. It can be a base type, and could also be an interface; all derived types could use the visualizer. IParseTree? RuleContext?
@bclothier @daFreeMan @PeterMTaylor what do you think?
zspitz
on 29 Aug 2019
My suspicion is that we'd want RuleContext as that has more specifics that we might be interested in. Because we are using Sam's fork in where the rule contexts are auto-regenerated from the .g4 files on build, you'd likely need to discover all derived types of RuleContext at runtime.
Given that it becomes a tree in the end, simply being able to specify a certain rule context type would suffice for creating filtered subtrees. Not to say that it would be sufficient in all scenario (I can see us wanting to filter to a specific rule context of a certain type and having so and so in their properties).
@MDoerner might have some more opinions on this matter.
bclothier
on 29 Aug 2019
First, let me join in into the chorus that I would love to see some antlr4 parse tree visualization in VS.
That out of the way, I guess IParseTree is the best basis for the nodes. This combines the three possible node types, RuleNode (for rule invocations like ParserRuleContext), ITerminalNode (for explicit tokens) and IErrorNode (for error recovery tokens).
All three are relevant, but would benefit from different visualization. For ParserRuleContexts, the type name of the context is probably the most relevant information. However, for terminal nodes, the most interesting piece is the actual text.
 MDoerner
on 29 Aug 2019
MDoerner
on 29 Aug 2019
I've set up a repo with an initial version (really alpha) at https://github.com/zspitz/ANTLR4ParseTreeVisualizer. The compiled DLLs are available at the releases page.
zspitz
on 30 Aug 2019
@MDoerner How does this look?
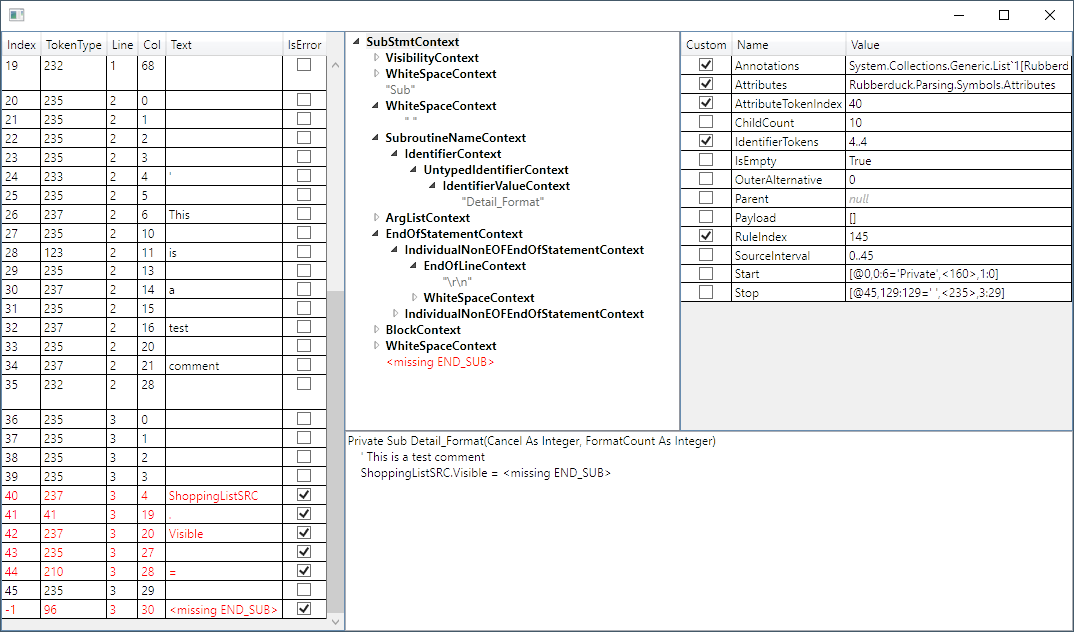
zspitz
on 1 Sep 2019
Very nice!
2 questions:
1) Can we have text instead of number for Token Type? I fortunately don't memorize what they correlate to. Off the cuff, I don't think ANTLR tells us what it is but it's supposed to be linked to the rule defined, or something like that.
2) since you have the line & column, will you highlight it in the text section to show which is the token covering?
bclothier
on 1 Sep 2019
@bclothier
Thanks for the feedback. It's really important to me to get this sort of information from people who have extensive experience with ANTLR.
- AFAICT neither the token type or the rule name (for which the instance's type name is a poor alternative --
SubStmtContextvssubStmt) is directly available. Instead, the parser class has twostring[]properties --TokenNamesandRuleNames-- which return the name corresponding to the token type and rule index respectively. The problem is that when investigating a rule context, I don't have direct access to the parser. I guess I'll have to resolve the parser class as described here. - Yes, I definitely want to do this, as well as synchronizing selection between the token list and the treeview. IOW, when selecting a token in the token list, it should be scrolled-into-view in the treeview and selected; and when selecting a treeview node, the range of tokens should be selected in the token list. I've described my thinking here.
zspitz
on 1 Sep 2019
I had a thought - we have _lots_ of unit tests with the source as a string. Would it be able to visualize the string as a parse tree rather than trying to find the parse class deep within the mock parser?
bclothier
on 1 Sep 2019
Parts of autocompletion features use the VBACodeStringParser.Parse static method that might be of use here:
You give it a string, it gives you a parse tree and a rewriter in a tuple. ParserStartRule is a delegate type for a function that takes a VBAParser argument and returns any IParseTree:
Its uses look like this:
 retailcoder
on 1 Sep 2019
retailcoder
on 1 Sep 2019
I had a thought - we have lots of unit tests with the source as a string. Would it be able to visualize the string as a parse tree rather than trying to find the parse class deep within the mock parser?
I don't follow. What is the goal here?
@retailcoder Currently, the visualizer only requires Antlr.Runtime and I'd prefer to keep it that way. In order to use Rubberduck-specific functionality (such as static methods defined in Rubberduck), I'd have to implement some kind of plugin system; I don't know how to do that yet.
zspitz
on 1 Sep 2019
The idea is that I would be able to click on a string variable/literal, and visualize the created parse tree from the string’s contents. That would make it to open the visualizer because I only need to have a string variable rather than creating a parser then visualize from there. If you look at our unit tests, we use a mock parser which does a lot of things before we getbto the actual parser class.
bclothier
on 1 Sep 2019
OK. Once there's some sort of way to resolve which parser class to use (https://github.com/zspitz/ANTLR4ParseTreeVisualizer/issues/10), this could be done. I would even like to see a non-debugging window, more like how the Eclipse plugin works -- you could provide it with an assembly location containing a parser class, and some source code, and it would generate the parse tree and visualize it.
zspitz
on 1 Sep 2019
Selection sync is working: 😎
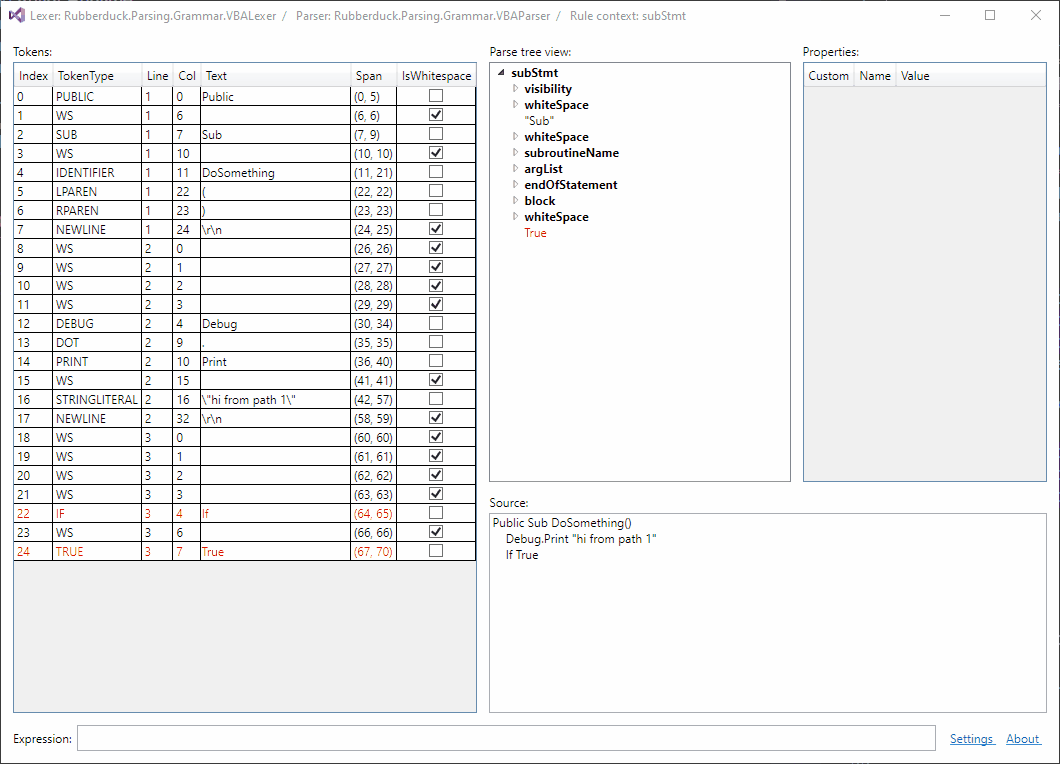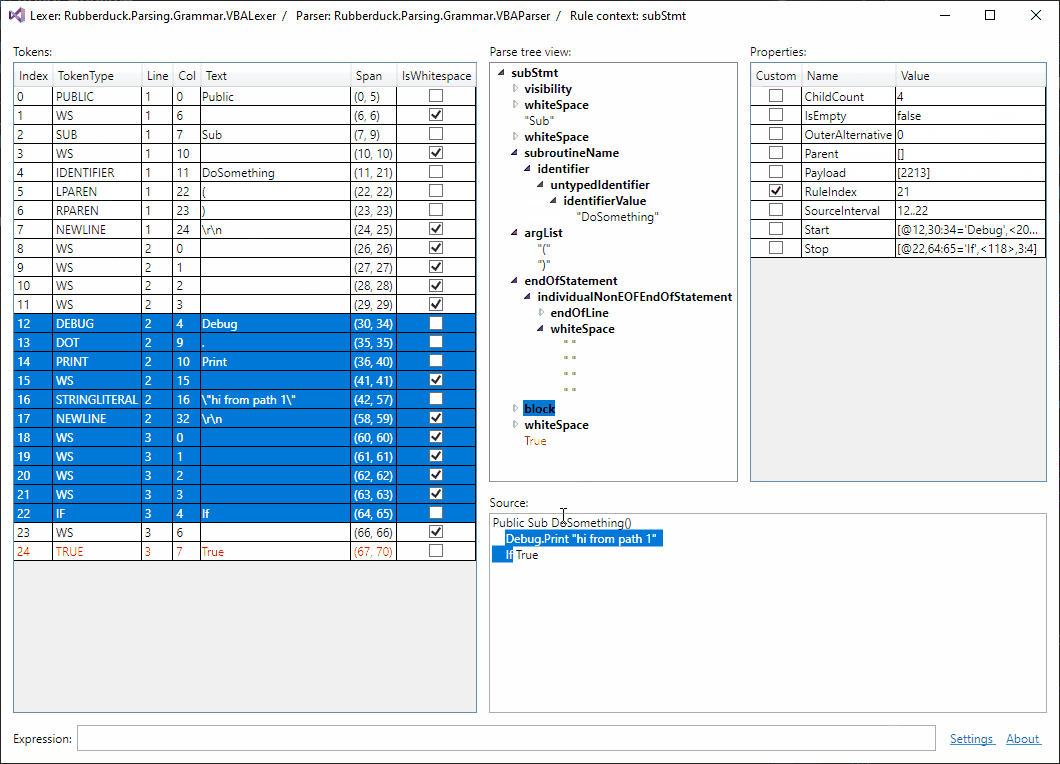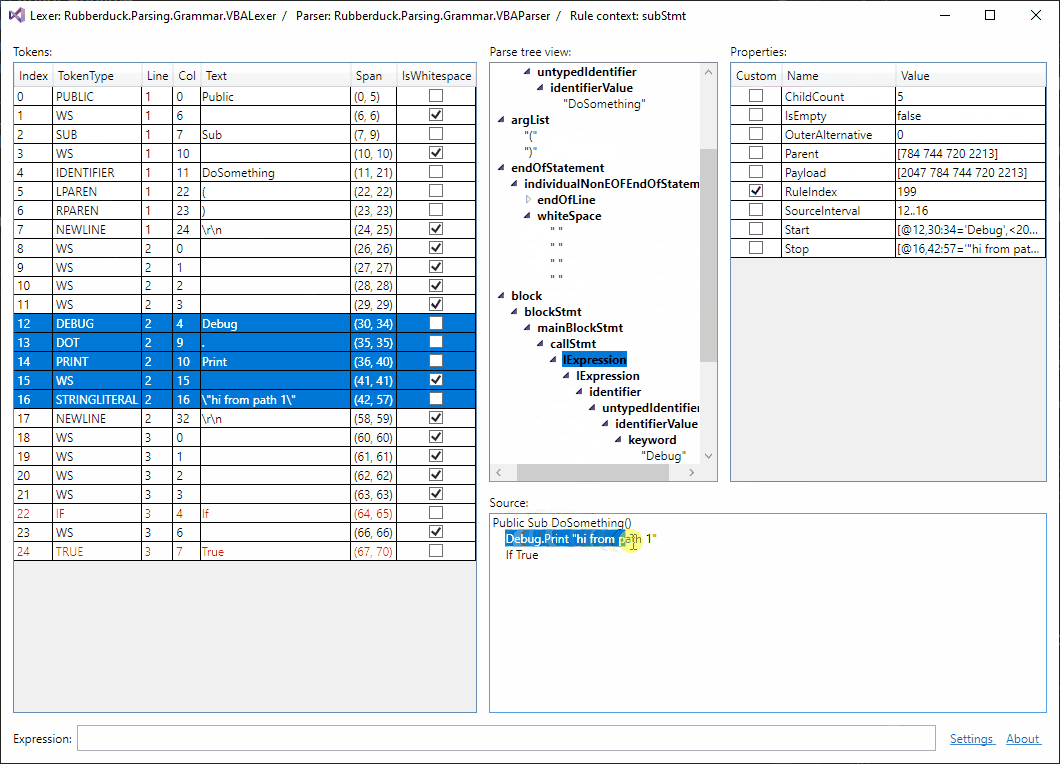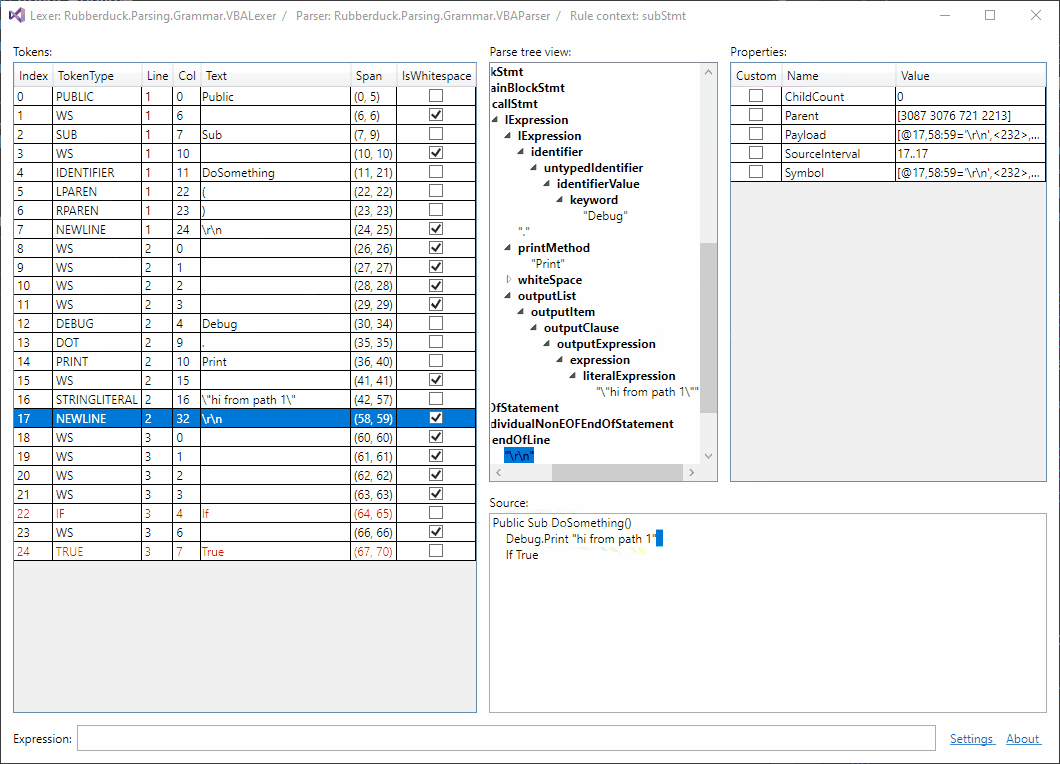
Should I be posting updates here?
zspitz
on 2 Sep 2019
Nobody's going to complain! This looks awesome!
 Hosch250
on 2 Sep 2019
Hosch250
on 2 Sep 2019
What @Hosch250 sez
bclothier
on 2 Sep 2019
By choosing the correct parser from referenced assemblies, the visualizer will now display the actual rule names and token names:
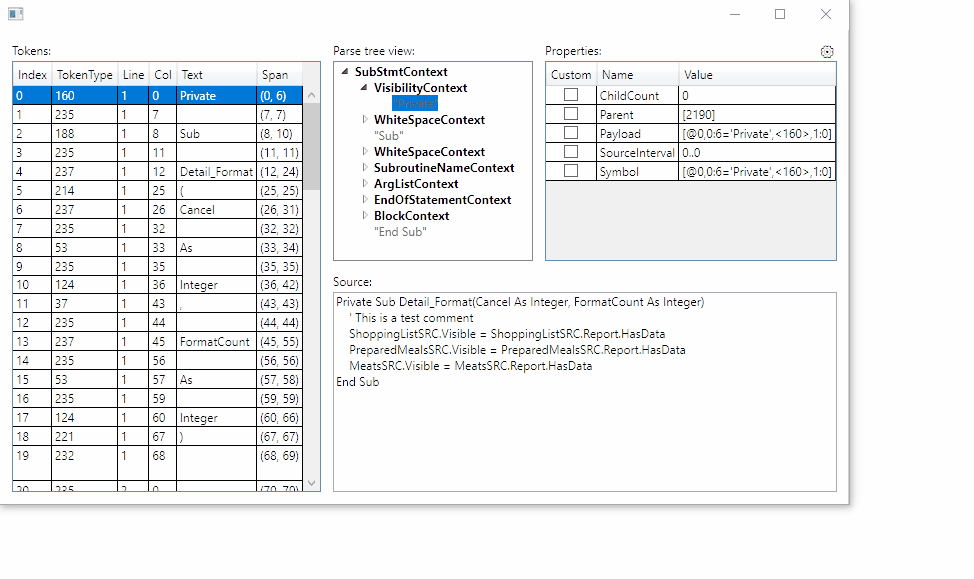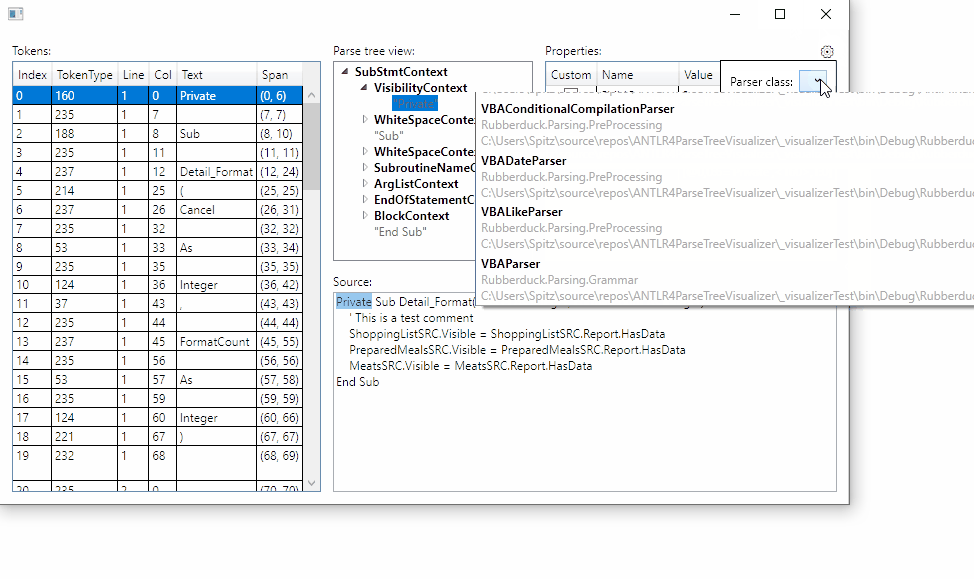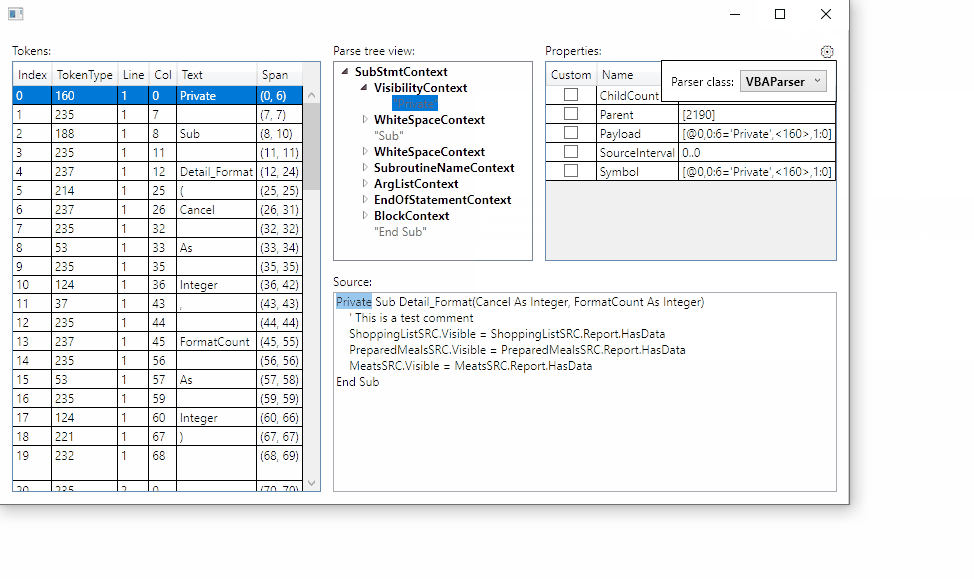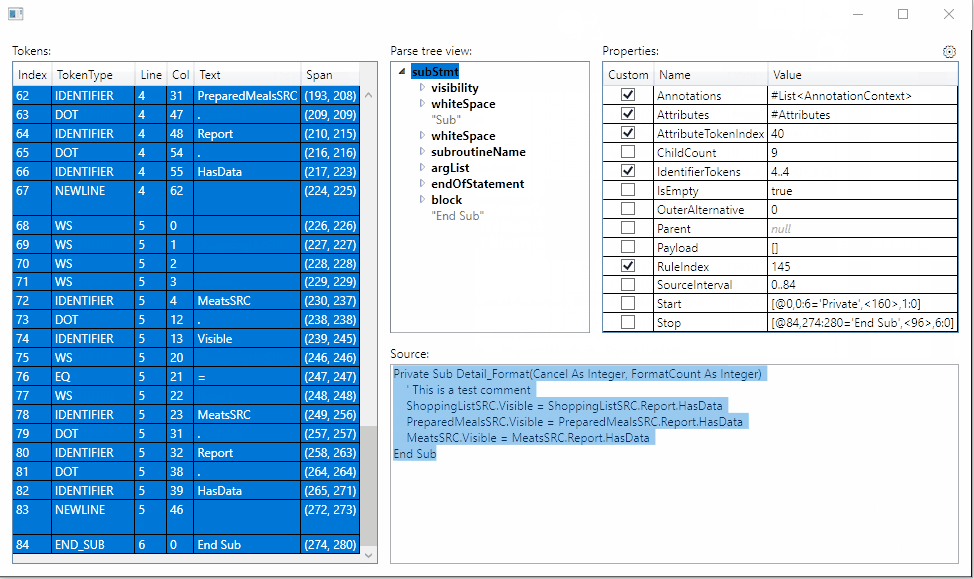
Still working on how to persist the selection between visualizer sessions.
(CC @bclothier)
zspitz
on 5 Sep 2019
Encouraging news...
PeterMTaylor
on 5 Sep 2019
The selected parser class is now persisted across visualizer sessions, as long as the type of the inspected object is from the same assembly.
Is it time yet to update the wiki?
zspitz
on 8 Sep 2019
Token filtering:
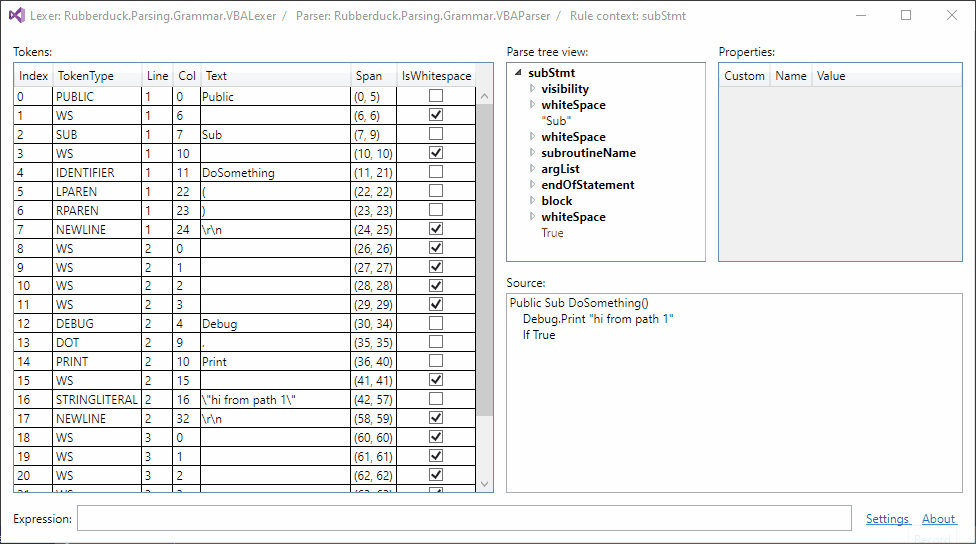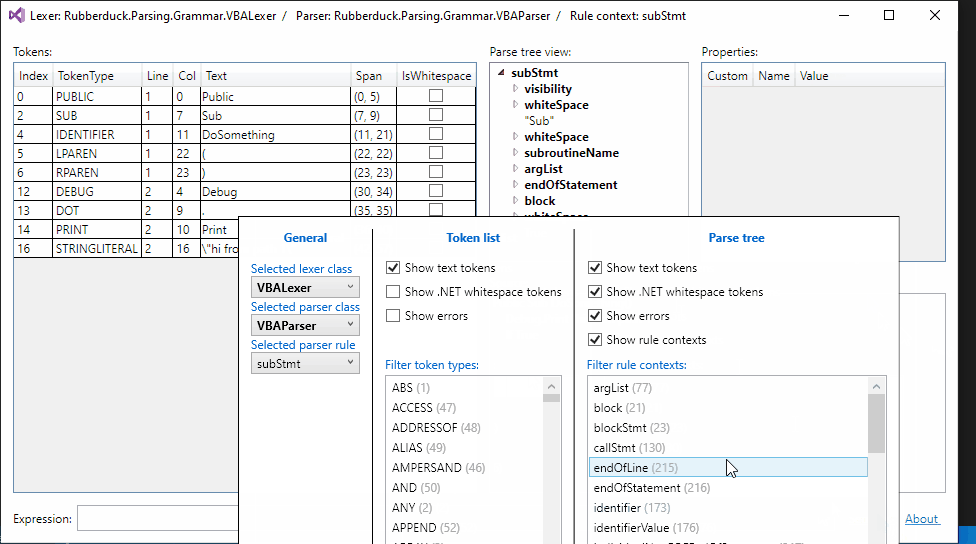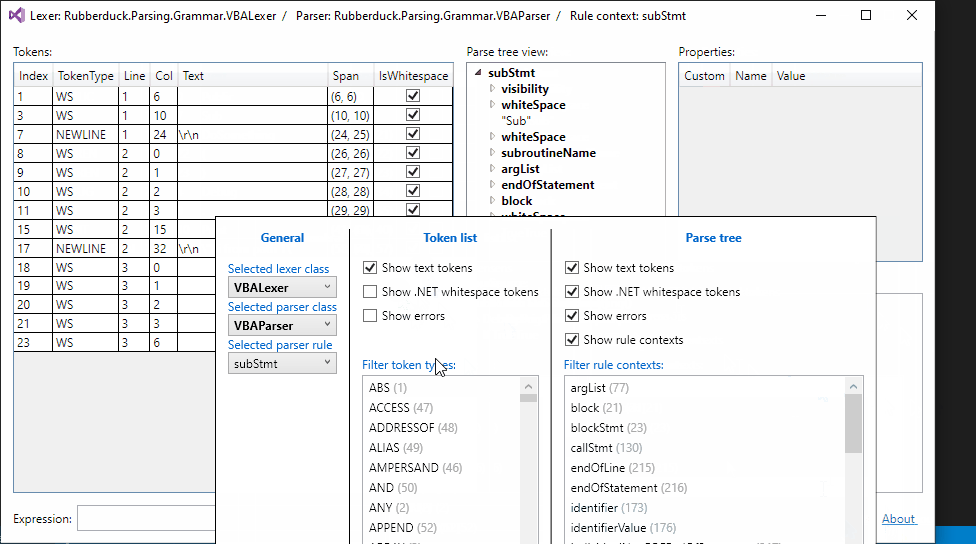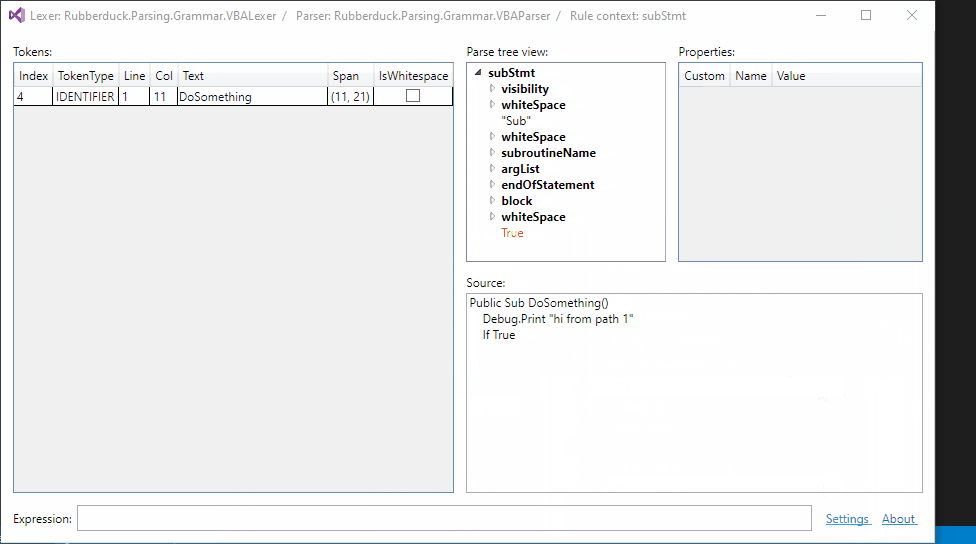
Up next: parser rule filtering...
zspitz
on 12 Sep 2019
This will help those like myself that struggle with concepts. Seeing a live example like this is game changing for me.
 IvenBach
on 15 Sep 2019
IvenBach
on 15 Sep 2019
Parse tree filtering, just landed:
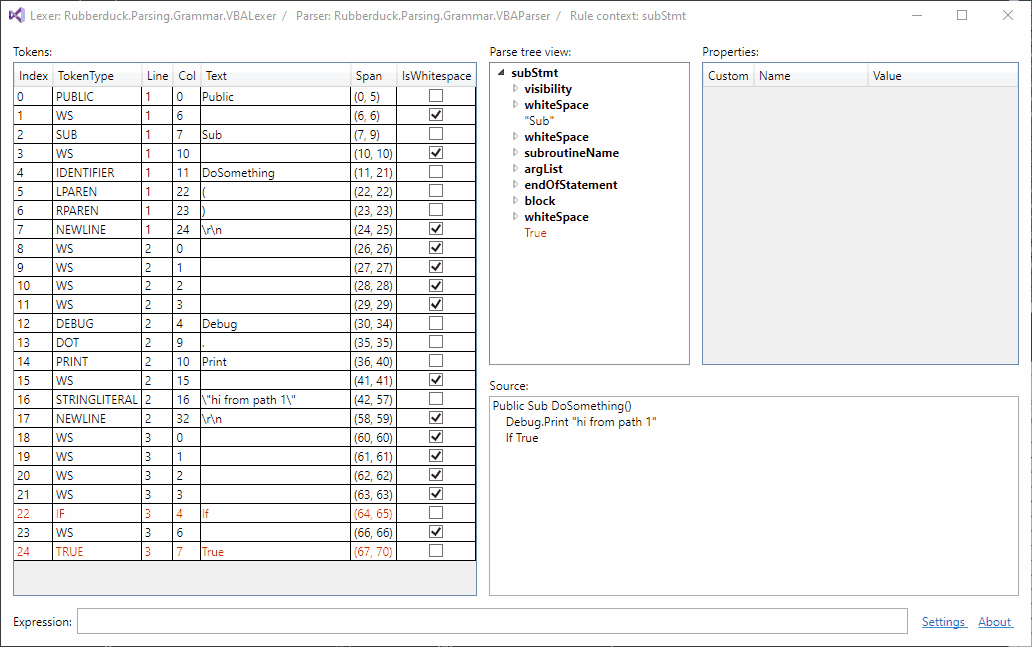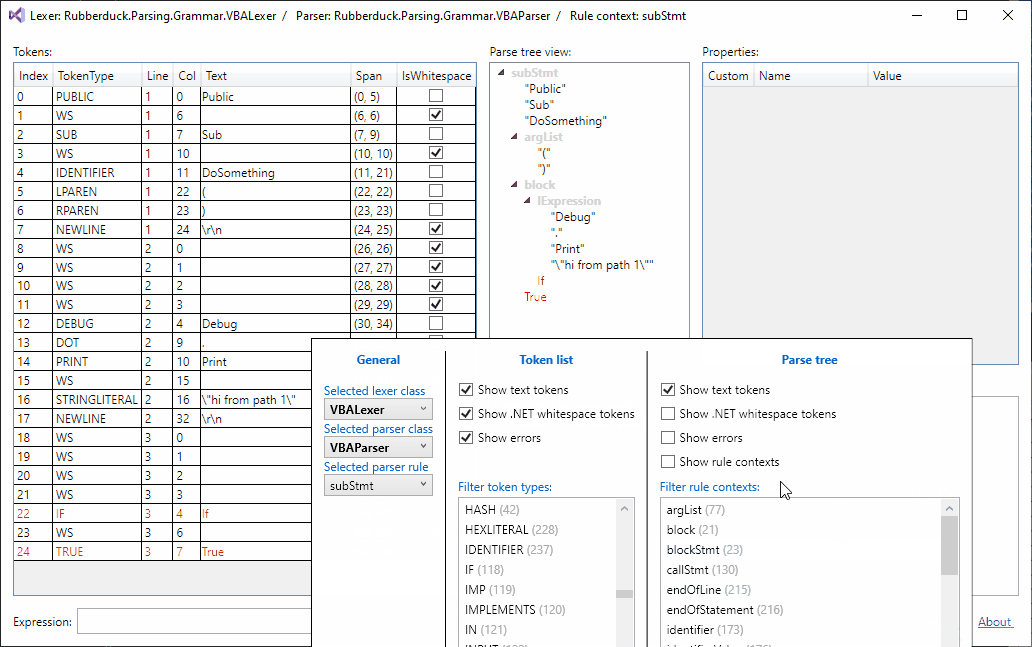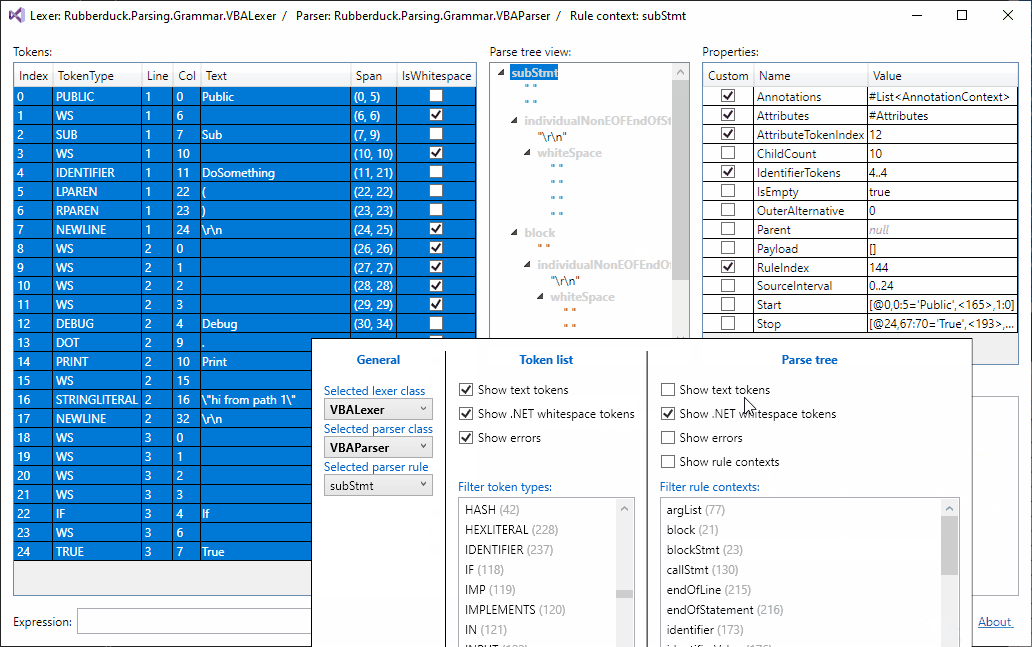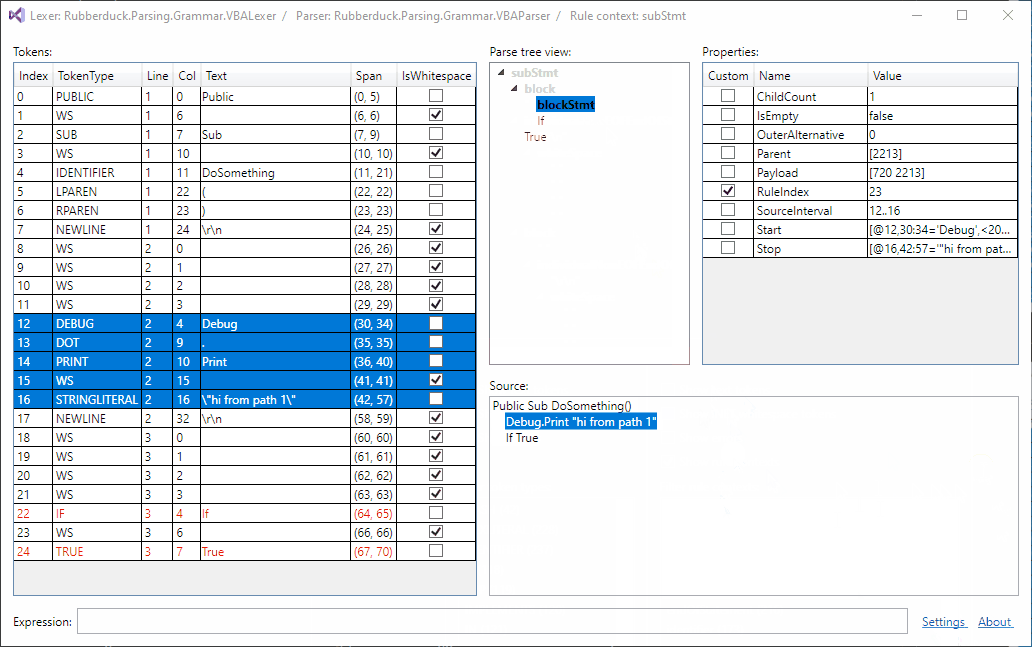
Currently, the token list filter and the tree filter are independent from one another.
Should I also allow filtering the tree by token type as well?
zspitz
on 20 Sep 2019
Set a node as root, or open as root in new window:

zspitz
on 23 Sep 2019
The visualizer now targets three types (and their derived types):
string, and optionally choose a lexer class, a parser class, and the rule, to get a full treeBufferedTokenStream, and optionally choose a parser class and rule to get a full treeParseRuleContext
The visualizer now works with both Antlr.Runtime 4.6.6 (the old C#-optimized version; currently used by RD) and the newer Antlr.Runtime.Standard 4.7.2 (the official new version).
A picture being worth a thousand words:
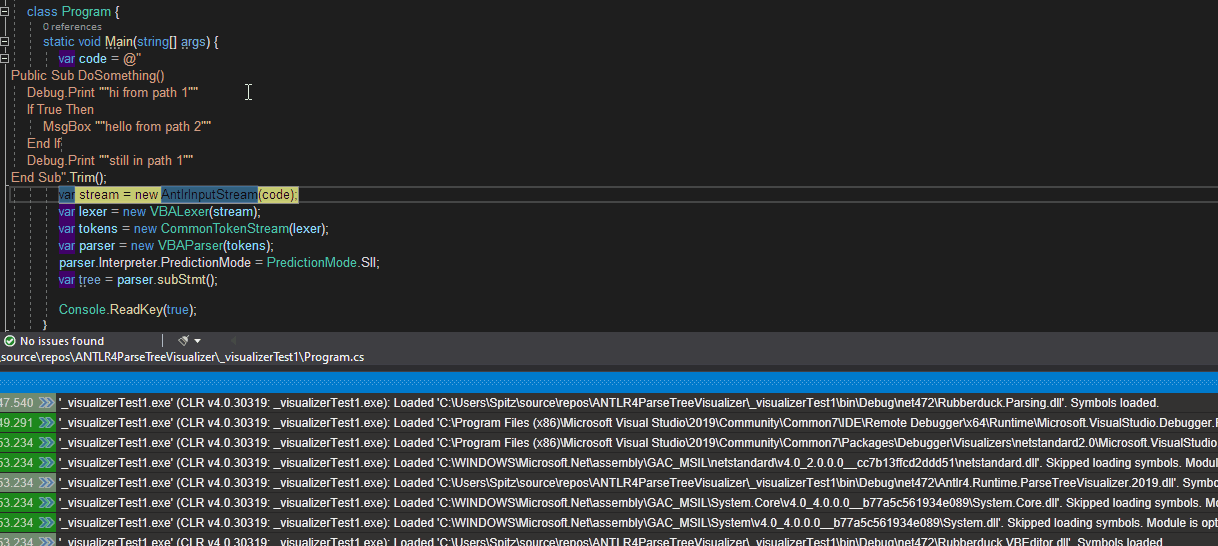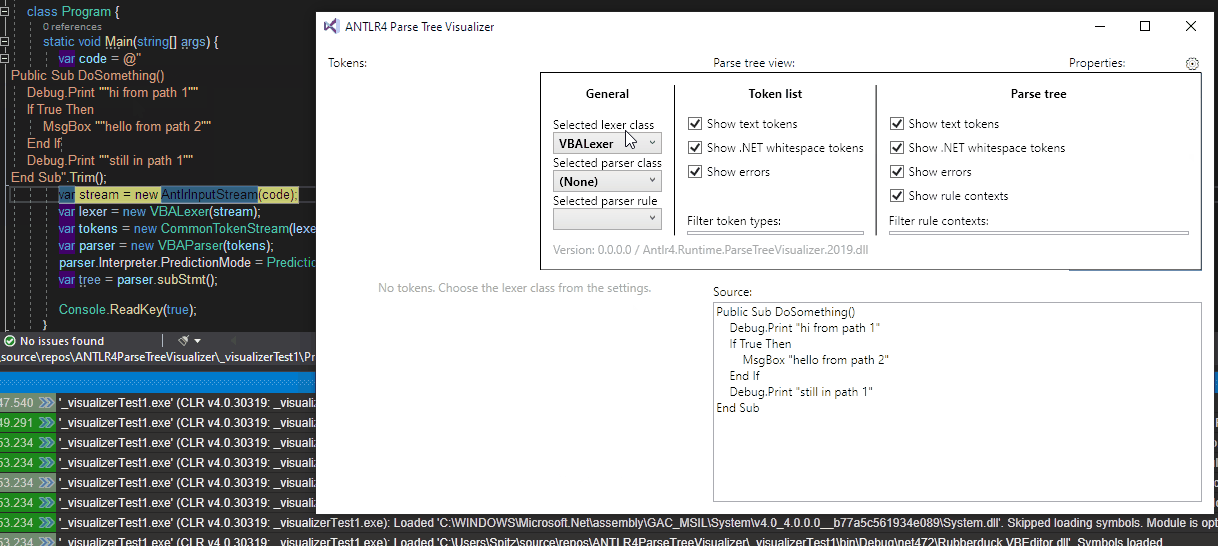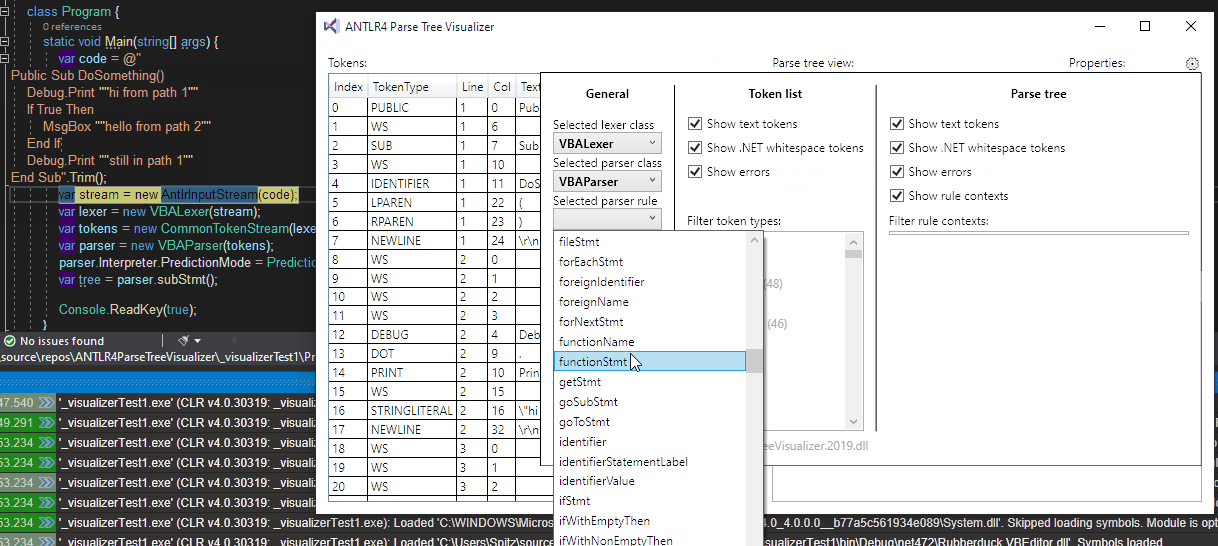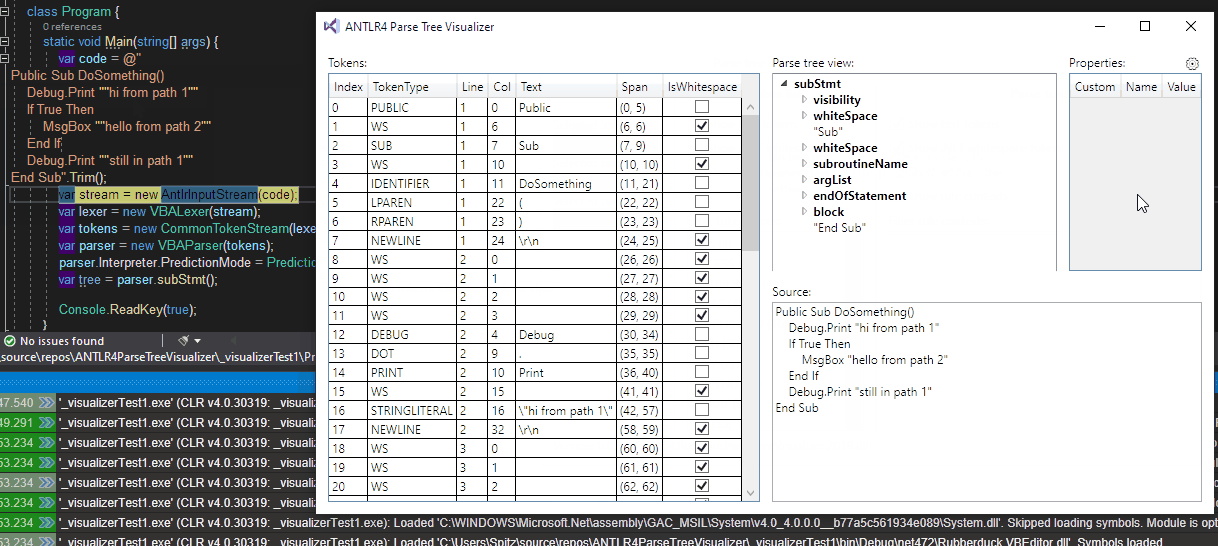
zspitz
on 28 Oct 2019
I had a thought - we have _lots_ of unit tests with the source as a string. Would it be able to visualize the string as a parse tree rather than trying to find the parse class deep within the mock parser?
@bclothier This is now possible.
zspitz
on 31 Oct 2019
This is becoming so awesome, I'm considering this issue closed :smiley:
retailcoder
on 31 Oct 2019
Related issues
bclothier
·
3Comments
 Inarion
·
3Comments
Inarion
·
3Comments
 eteichm
·
4Comments
eteichm
·
4Comments
 SteGriff
·
3Comments
SteGriff
·
3Comments
 ghost
·
3Comments
ghost
·
3Comments
Most helpful comment
Selection sync is working: 😎
Should I be posting updates here?