Rocket.chat: Presence Broadcast leads to clients flood front-end with long pooling XHR requests with websocket correctly configured
Description:
I asked that question on open.rocket.chat but I need more details about that issue.
@bbrauns and @benedikt-wegmann adviced me here to implement sticky sessions because it is critical to Meteor. Now we experiencing a big performance issues with Rocket.Chat from time to time and we need to implement all features, that can improve stability and performance.
Right after last crash we enabled that sticky sessions in Nginx with ip_hash so one source IP is sticked to one upstream server.
We see in Nginx logs, that it is working fine.
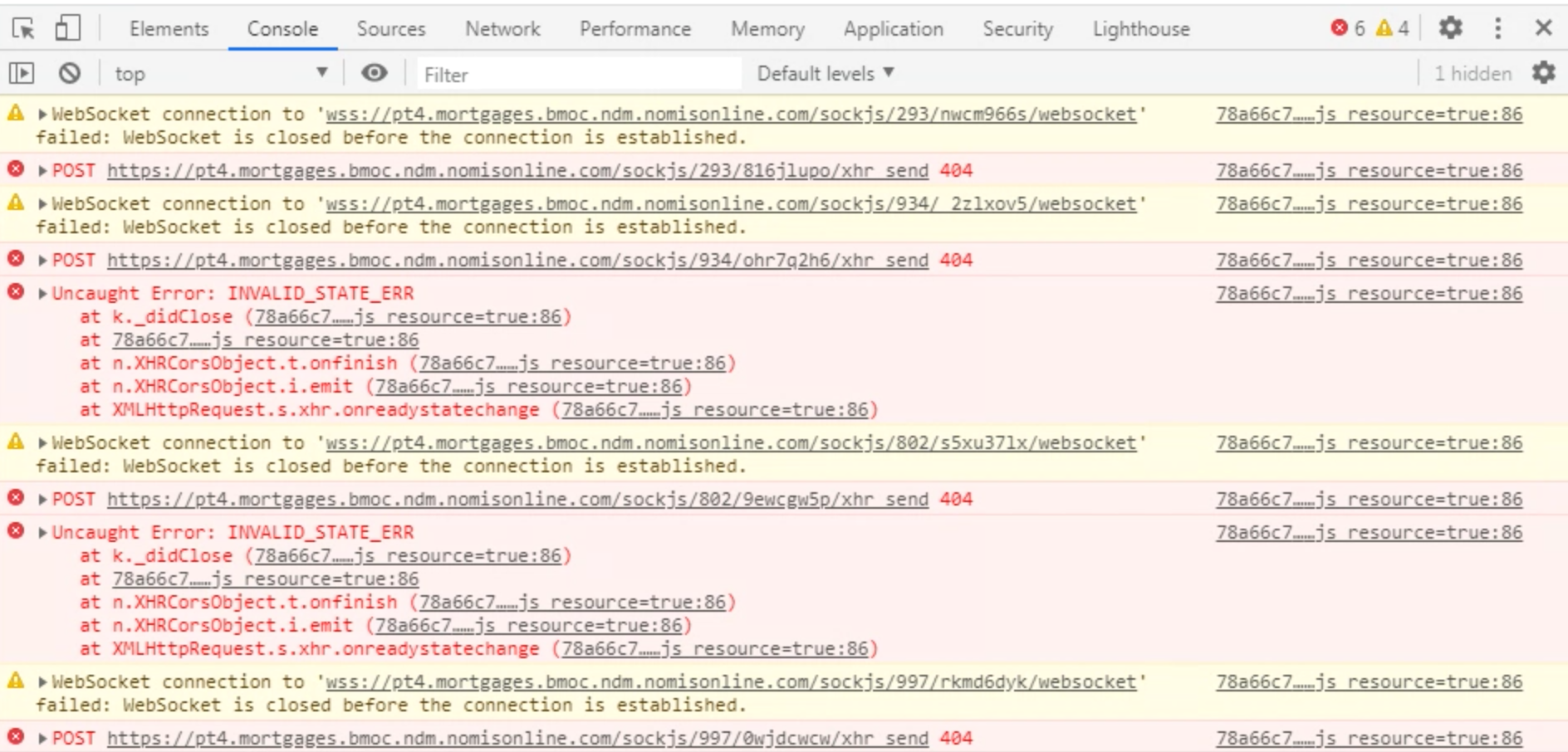
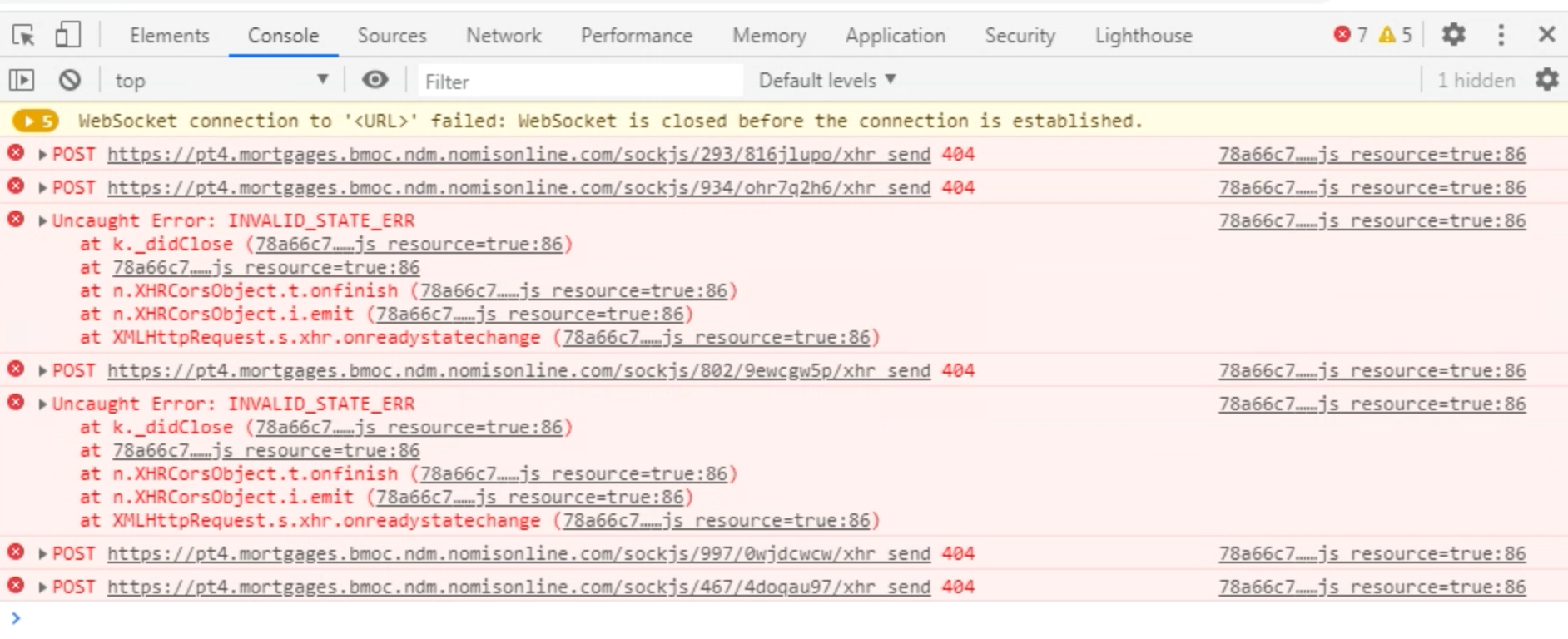
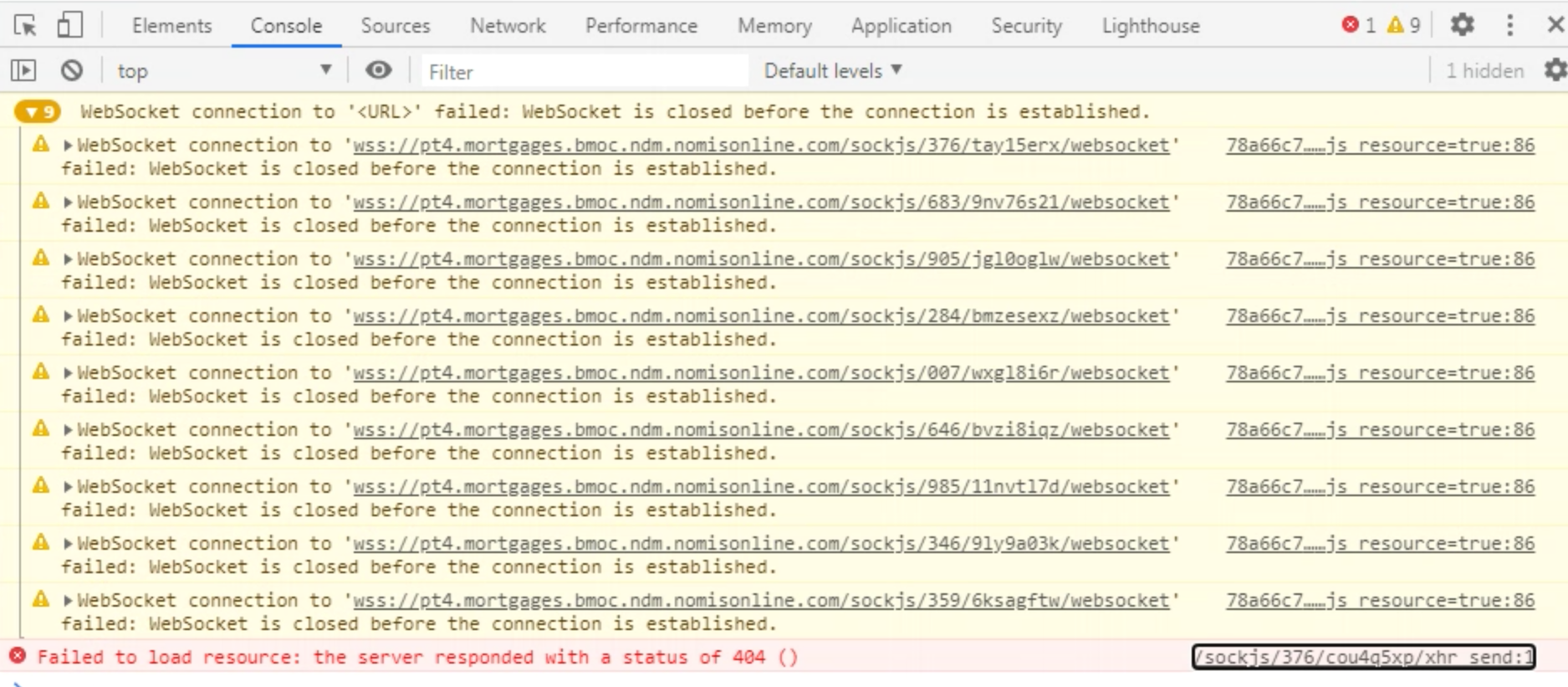
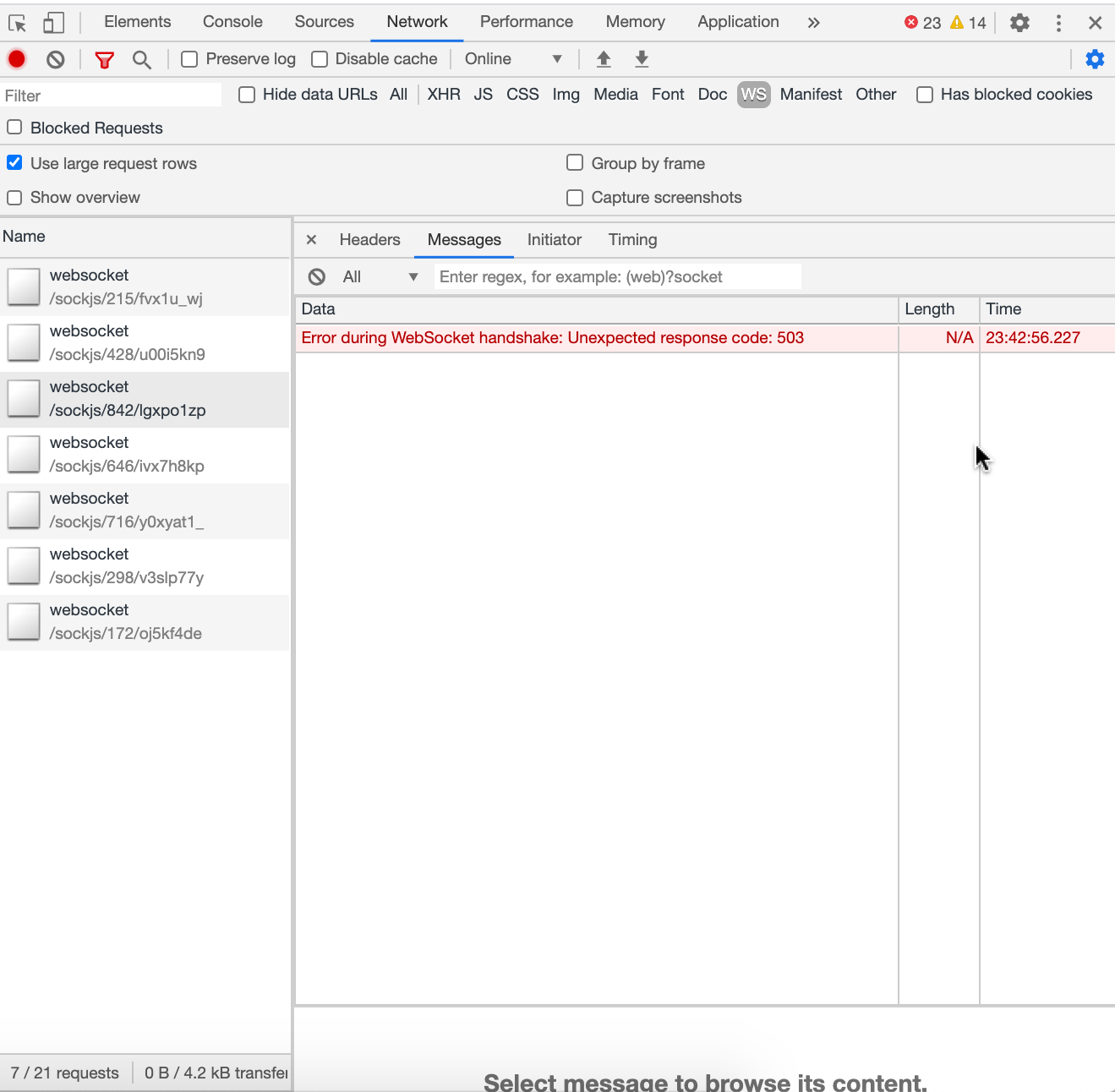
But we have about 300 clients that send every second request like this:
POST /sockjs/464/4sqavoxf/xhr HTTP/1.1
Host: rocketchat.company.com
Connection: keep-alive
Content-Length: 0
Origin: https://rocketchat.company.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Rocket.Chat/2.17.7 Chrome/78.0.3904.130 Electron/7.1.10 Safari/537.36
Accept: */*
Sec-Fetch-Site: same-origin
Sec-Fetch-Mode: cors
Referer: https://rocketchat.company.com/direct/iodE4TwMg4i729GoHy5RWQyYZLZBKRuhpt
Accept-Encoding: gzip, deflate, br
Accept-Language: ru
Cookie: rc_uid=y5RWQyYZLZBKRuhpt; rc_token=2O55h3bWfNex-_KiYgwsvcEanzyL-Qdr7bXptnKir6m
With response like this:
HTTP/1.1 200 OK
Server: nginx
Date: Thu, 07 May 2020 05:02:20 GMT
Content-Type: application/javascript; charset=UTF-8
Transfer-Encoding: chunked
Connection: keep-alive
Cache-Control: no-store, no-cache, no-transform, must-revalidate, max-age=0
Access-Control-Allow-Credentials: true
Access-Control-Allow-Origin: https://rocketchat.company.com
Vary: Origin
Access-Control-Allow-Origin: *.company.com
X-Frame-Options: SAMEORIGIN
X-XSS-Protection: 1; mode=block
X-Content-Type-Options: nosniff
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
So, it is defiantly not a websocket. But Rocket.Chat works pretty normal for such problem clients.
I don't why!
What is this? Is it some kind of compatibility to websocket or what? JavaScript Socket?
Steps to reproduce:
- Enable sticky sessions while clients was already connected to Rocket.Chat
- Check reverse proxy logs for flood of POST requests
Expected behavior:
All clients should successfully work via websocket, as most of clients do.
Actual behavior:
From problem client:
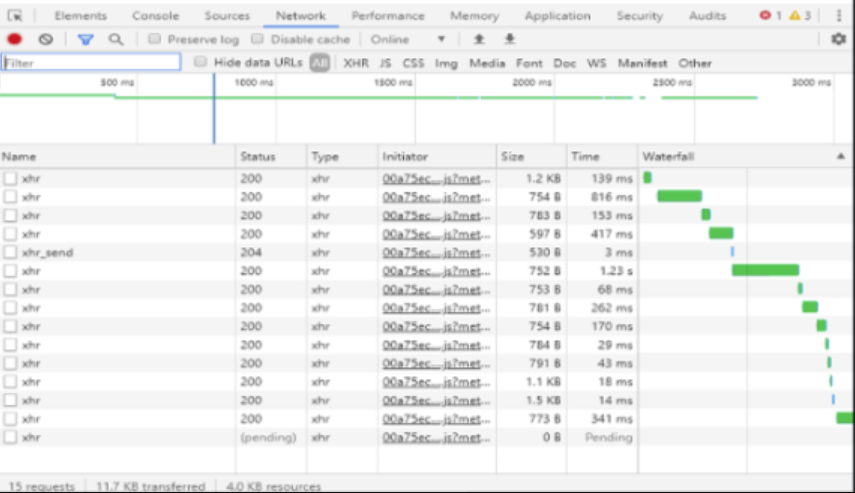
Server Setup Information:
- Version of Rocket.Chat Server: 3.1.1
- Operating System: CentOS7
- Deployment Method: docker
- Number of Running Instances: 12
- DB Replicaset Oplog: Enabled
- NodeJS Version: v12.16.1
- MongoDB Version: 4.0.17
Client Setup Information
- Desktop App: Most of problem clients are 2.17.7 Chrome
- Operating System: Windows 10 and Windows 7
Additional context
CTRL+R on client totally fixed that problem. Just after reload client successfully open websocket (response 101) and request flood stops.

But I want to know what exactly is the mode in which problem clients are working and how to fix it permanently?
And what developers think could be the reason for that behavior?
@tassoevan @sampaiodiego please check that issue.
 ankar84
ankar84
All 30 comments
sockjs supports multiple transports according to https://github.com/sockjs/sockjs-client#supported-transports-by-browser-html-served-from-http-or-https
It is not clear why in your case it falls back to xhr polling in the first place. You could try to reproduce the problem in chrome and export a HAR file https://developers.google.com/web/tools/chrome-devtools/network/reference#save-as-har to further investigate possible connectivity issues.
 bbrauns
on 7 May 2020
bbrauns
on 7 May 2020
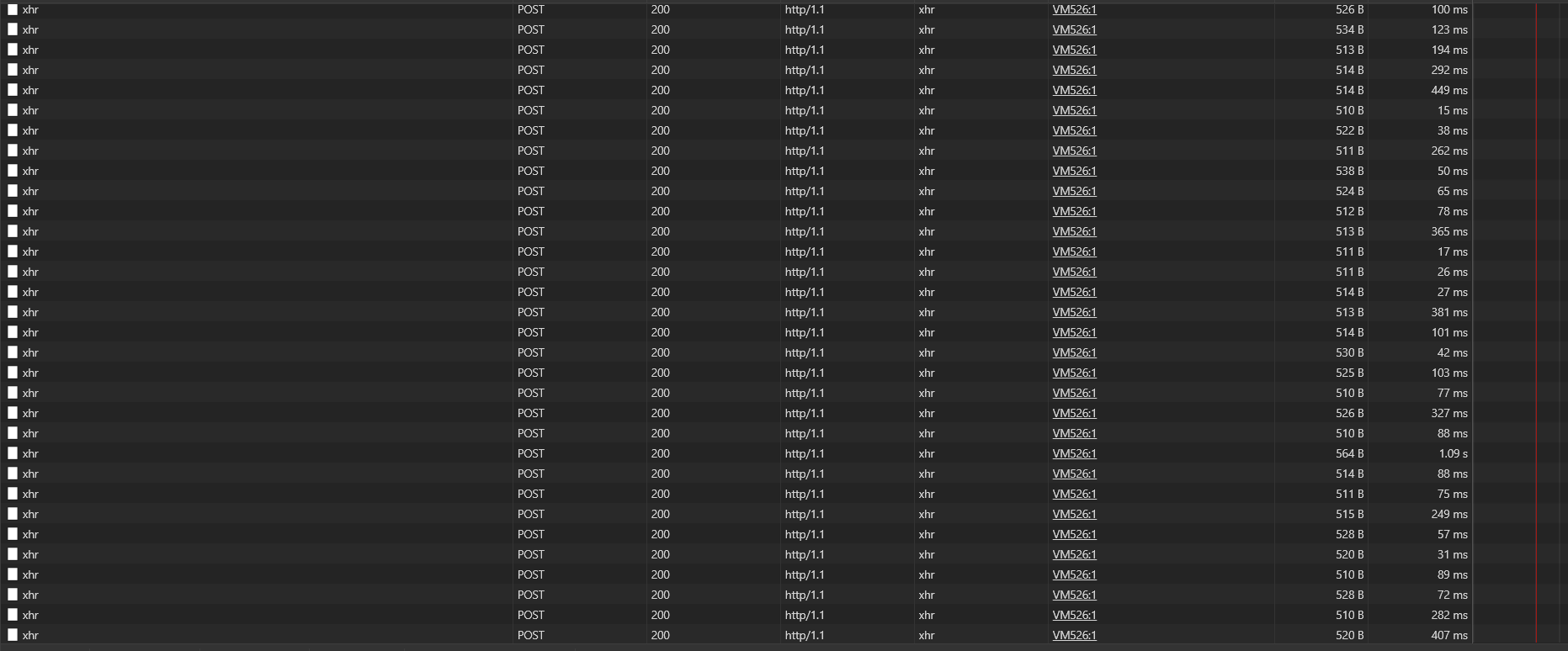
Seeing the same. We have always implemented sticky session in HaProxy however.
 Beeez
on 7 May 2020
Beeez
on 7 May 2020
in case browser cannot establish a web socket connection, Meteor automatically a falls back to long pooling XHR requests..
probably you'll need to check your reverse proxy websockets settings to find the root of this issue..
some links for reference:
https://forums.meteor.com/t/xhr-xhr-send-spam-on-production-server/43312/2
 sampaiodiego
on 7 May 2020
sampaiodiego
on 7 May 2020
Seems like it must be a bit hit or miss then. As OP says, it is all good after a refresh.
If it works _only sometimes_ I can't entirely see that still being a reverse proxy issue.
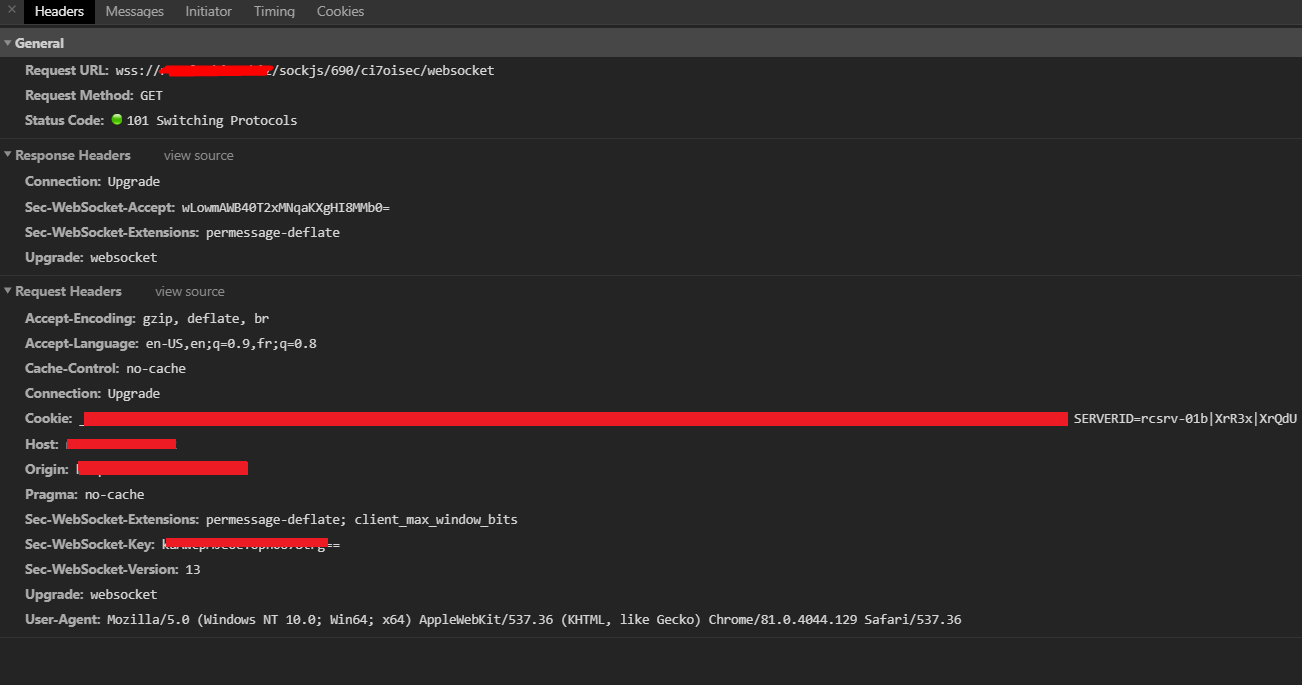
Beeez
on 7 May 2020
@sampaiodiego
Hi, Diego! And thanks for you attention!
probably you'll need to check your reverse proxy websockets settings to find the root of this issue..
As @Beeez noticed we have reverse proxy (Nginx) correct configured and a major of clients works perfect with websocket and problem clients do after refresh.
This is kind of client stuck on upgrade to websockets for some reason. And all we want to know that reason to fix it.
ankar84
on 8 May 2020
@sampaiodiego @tassoevan
Actually I think that root cause of that situation can be that clients try to connect to Rocket Chat servers while reboot or other unavailability moment (crash, maintenance) and after upgrade to websocket attempt was unsuccessful client fallback to sockjs, and stay with it until reboot.
I see 2 ways to fix that:
- Client should try to upgrade to websocket again from time to time while using sockjs
- Client can inform user, that connection to server not optimal and advice a refresh
First was can be not so good for users - for example they can lose their message on connection upgrade (I'm not sure they will, but anyway)
ankar84
on 8 May 2020
sticky sessions in Nginx with ip_hash so one source IP is sticked to one upstream server.
I do not see the advantage of using ip_hash over a cookie-based method.
We use HAProxy, but basically it uses Nginx "route" method with a cookie: https://nginx.org/en/docs/http/ngx_http_upstream_module.html#sticky
I cannot say whether this should make a difference, but I expect it to balance your users more evenly because every single connection is considered compared to just the originating IP address (which could mask users behind NAT).
 benedikt-wegmann
on 8 May 2020
benedikt-wegmann
on 8 May 2020
I expect it to balance your users more evenly because every single connection is considered compared to just the originating IP address (which could mask users behind NAT).
You are totally right about that. And we also have a proxy users in our organisation, so all of them are represented by single IP address, but
This directive is available as part of our commercial subscription
So we use free Nginx version with ip_hash for sticky sessions.
ankar84
on 8 May 2020
This directive is available as part of our commercial subscription
What a bummer, I did read to the end.
Should you need a (presumably) working HAProxy config I share mine.
benedikt-wegmann
on 8 May 2020
hould you need a (presumably) working HAProxy config I share mine.
Thanks a lot for that, by the way!
My colleagues think that Nginx is a proper solution for us, and we don't need to use HAProxy for sticky sessions, because we can do it with ip_hash in Nginx. They more fluent in UNIX magic then me, so I agree ;)
ankar84
on 8 May 2020
This directive is available as part of our commercial subscription
What a bummer, I did read to the end.
Should you need a (presumably) working HAProxy config I share mine.
Do you have any specific sections for websockets? Perhaps in ours we might be missing something - though again, since it works like 90% of the time i can't imagine it is a problem with our config.
Beeez
on 8 May 2020
@Beeez Not in HAProxy, no. My understanding is that Haproxy handles websocket connections transparently.
benedikt-wegmann
on 8 May 2020
So in one regard Rocket.Chat client is responding appropriately as concluded above. Some reason websocket isn't established and so falls back to the other way, basically assuming that the websocket must not work.
Ok so now ignoring that for now and focusing specifically on the websocket.
Can you determine how well your proxy is balancing among your Rocket.Chat instances?
Actually I think that root cause of that situation can be that clients try to connect to Rocket Chat servers while reboot or other unavailability moment (crash, maintenance) and after upgrade to websocket attempt was unsuccessful client fallback to sockjs, and stay with it until reboot.
Is this happening a lot? Are Rocket.Chat instances going unavailable? I'm not sure how nginx handles the sticky.. but does it add any sort of header on the response or a cookie so can see how its routing? Would be interesting to see if the websocket hits the same server as the xhr requests.
Do you have any sort of liveness check on your actual instances running? To make sure that they are actually responding? It could be some are stickied to an instance that is messed up in some way and when the xhr happens nginx is some how hitting a different instance?
 geekgonecrazy
on 8 May 2020
geekgonecrazy
on 8 May 2020
@geekgonecrazy We use Haproxy Stats page that can show availability and when the XHR flooding starts, I see no failing health checks, with 60-80 people on the same instance as I am. All of our backends have 3 days uptime (last automated rolling nightly reboots).
The sticky session cookie is the same as in the xhr headers.
We dont use nginx as @ankar84 does, but we still see the same issues.
Beeez
on 11 May 2020
with 60-80 people on the same instance as I am
Interesting.. what does the load look like on the others? I'm just trying to understand if something might be causing the websocket not to upgrade in the Rocket.Chat code base.
Also if you get others having this issue.. do they seem to have the same instance as you do?
geekgonecrazy
on 11 May 2020
Hi, @geekgonecrazy and thanks for your attention!
Can you determine how well your proxy is balancing among your Rocket.Chat instances?
Now we have 2 levels of reverse proxy - 3 proxy of second level behind first level proxy. And 4 RC instances behind second level proxy. Clients distributed to all 12 RC instances by using ip_hash nginx on all two levels of proxy.
Is this happening a lot?
Generally. not. But recently I had 2 big RC crash day by day, it's described here. Now we disabled DDP Rate Limiter and implemented sticky sessions and at that moment we have now RC crash.
Are Rocket.Chat instances going unavailable?
No, I don't see that in monitoring. All instances state is monitored:

Do you have any sort of liveness check on your actual instances running?
No, instances itself not monitored by some requests, but if Nginx will get 502 or some other bad response, that instance move out from balance pool temporary. First level proxies are monitored by http requests every 10 seconds.
It could be some are stickied to an instance that is messed up in some way and when the xhr happens nginx is some how hitting a different instance?
I think answer here is "No". And we see that xhr floods same instance. But after clients refresh (CTRL+R) that xhr flood fixed. And here I don't actually know how - maybe clients connects to different instance and start websocket normally, or maybe clients connects to same instance, but after reconnect upgrade to websocket successfully.
UPD. Colleague advice me that clients connect to same instance (ip_hash working)
We dont use nginx as @ankar84 does, but we still see the same issues.
Yes, it seems to my, that it's reverse proxy independent issue.
@geekgonecrazy what do you think about suggested solutions? Second way can be something like E2E banner.
I see 2 ways to fix that:
- Client should try to upgrade to websocket again from time to time while using sockjs
- Client can inform user, that connection to server not optimal and advice a refresh
ankar84
on 12 May 2020
@geekgonecrazy
Interesting.. what does the load look like on the others?
Across 12 instances, we have loadbalancing with leastconn. We have about 60 users per instance.
It is not anything that is stuck to just a single instance. It happens regardless of any single instance.
HaProxy for us is doing health checks every ms, so if there was even a single blip, we would know about it in our downtime tracker.
Beeez
on 12 May 2020
After another crash yesterday https://github.com/RocketChat/Rocket.Chat/issues/17473#issuecomment-627720544 amount of sockjs clients decreased.

Before all RC servers reboot we had about 100-150 request/second each of 3 Nginx servers.

ankar84
on 13 May 2020
in case browser cannot establish a web socket connection, Meteor automatically a falls back to long pooling XHR requests..
Hi, @sampaiodiego
Diego, how do you think, can we somehow force client not to use long pooling XHR requests and upgrade to websocket connection?
Can we do it with some nginx config?
Websocket in fact works perfect, despite clients think different.
ankar84
on 25 May 2020
Interesting.. what does the load look like on the others? I'm just trying to understand if something might be causing the websocket not to upgrade in the Rocket.Chat code base
Hi, @geekgonecrazy
Aaron, can something of these be implemented in RC code base to reso;ve such issue?
I see 2 ways to fix that:
- Client should try to upgrade to websocket again from time to time while using sockjs
- Client can inform user, that connection to server not optimal and advice a refresh
ankar84
on 25 May 2020
@geekgonecrazy @sampaiodiego
I think that issue can somehow be related with presence broadcast
Now for some reason I disabled Presence Broadcast in Admin UI - Troubleshoot and amount of that POST requests decreased immediately
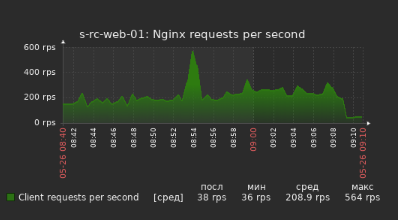

But websockets did not changed
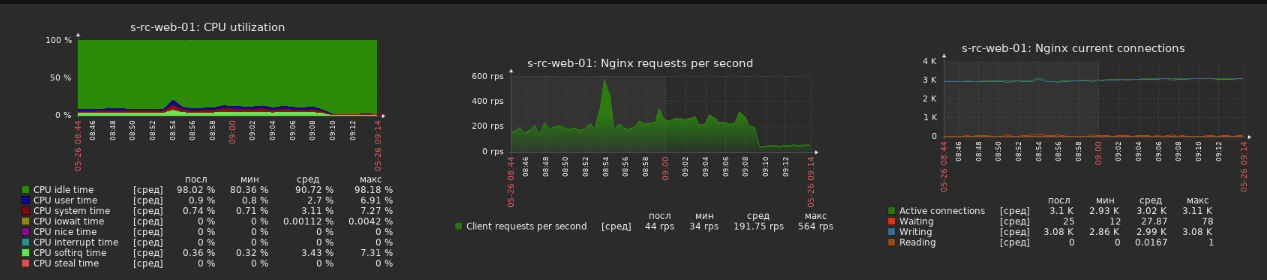
UPD.
At 11.18 I enabled Presence Broadcast and clients flood come back, so I'm pretty sure they related.


@Beeez can you try to reproduce that in your environment?
ankar84
on 26 May 2020
@Beeez @ankar84 thanks for all insights you shared. Just wanted to know if any of you figured out the root cause?
 summit2020
on 8 Jul 2020
summit2020
on 8 Jul 2020
@Beeez @ankar84 thanks for all insights you shared. Just wanted to know if any of you figured out the root cause?
Hi, @summit2020
And no, i don't know root cause of that issue and how to fix that.
ankar84
on 14 Jul 2020
@ankar84 , thanks for your reply.
I recently came to know that it could be a browser's max. WebSocket connections limit issue.
Example -
a. IE 11 has a max 6 connections limit.
b. Google Chrome has 30 connections limit.
c. Microsoft Edge has 30 connections limit.
What happens if IE has opened 6+ tabs per host?
Websocket connection would fail to establish a new connection and will downgrade to XHR data transportation which will further fail & this behavior keeps on going until you close that tab.
_But I see your issue may not be coming while opening tabs beyond the limit._
Also, if you are running your app on some load balancer then must try to reproduce the same issue with just one process.
Example - Suppose you have two app servers (app-server-1 & app-server-2), each server has 8 processes. Then just keep one process online within app-server-1.
_The reason I see different browsers keep this limit is just to save CPU performance since WebSocket keeps doing something._
summit2020
on 16 Jul 2020
I recently came to know that it could be a browser's max. WebSocket connections limit issue.
Example -
a. IE 11 has a max 6 connections limit.
b. Google Chrome has 30 connections limit.
c. Microsoft Edge has 30 connections limit.
Very interesting research, @summit2020
But I have 2 questions:
- Why Reload (CTRL+R on Windows desktop client) solve that issue for client?
- Why disable of Presence Broadcast in Admin UI - Troubleshoot solve that issue for all clients?
@geekgonecrazy @sampaiodiego any thoughts about that?
ankar84
on 16 Jul 2020
2. Why disable of Presence Broadcast in Admin UI - Troubleshoot solve that issue for all clients?
@geekgonecrazy @sampaiodiego I think I can explain that.
First RC client could not upgrade to websocket for some reason (still no idea why) and stand on XHR.
Broadcast presence does a lot of traffic and that XHR client do all presence updates with thousands such sockjs POST requests.
When we disable Presence Broadcast in Admin UI - Troubleshoot we see much less XHR requests - I think it's a regular message exchange (chatting) of such XHR clients.
When client do Reload (CTRL+R on Windows desktop client) - session upgrade to Websocket normally and continue working in Websocket (with presence exchange).
So only one question remain open - What cause client to downgrade to XHR?
Solution for that problem I suggested here
I see 2 ways to fix that:
- Client should try to upgrade to websocket again from time to time while using sockjs
- Client can inform user, that connection to server not optimal and advice a refresh
First was can be not so good for users - for example they can lose their message on connection upgrade (I'm not sure they will, but anyway)
ankar84
on 14 Aug 2020
I recently came to know that it could be a browser's max. WebSocket connections limit issue.
Example -
a. IE 11 has a max 6 connections limit.
b. Google Chrome has 30 connections limit.
c. Microsoft Edge has 30 connections limit.
@summit2020 thank you for your great research!
Do you know the limit of Rocket Chat desktop client?
I think it's on Electron, which is on Chrome, but don't know for sure.
Maybe @tassoevan can clarify that moment?
ankar84
on 14 Aug 2020
Could we make make use of --ignore-connections-limit?
 frdmn
on 21 Aug 2020
frdmn
on 21 Aug 2020
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 20 Oct 2020
github-actions[bot]
on 20 Oct 2020
That is a very important issue, please don't close it. Flood still here
ankar84
on 20 Oct 2020
Related issues
 marceloschmidt
·
3Comments
marceloschmidt
·
3Comments
 antn89
·
3Comments
antn89
·
3Comments
 brendanheywood
·
3Comments
brendanheywood
·
3Comments
 neha1deshmukh
·
3Comments
neha1deshmukh
·
3Comments
 Buzzele
·
3Comments
Buzzele
·
3Comments
Most helpful comment
Seems like it must be a bit hit or miss then. As OP says, it is all good after a refresh.
If it works _only sometimes_ I can't entirely see that still being a reverse proxy issue.