Rescript-compiler: unicode string literal support
I have three proposals:
1.
"你好“ [@u8]
So we will decode it as utf8, this is compatible with existing ocaml byte string
2.
"\x122" [@bytes]
So that all string literals will be validated as utf8 string, if users want to write non-utf8
string literal, it has to be annotated
3.
file level config
[@@@config {unicode}], it will default to utf8,
so we will decode string literal as unicode in the file level.
together we will have an option "-bs-unicode utf8", so the question is what's
the default option, if the default encoding is buffer, it will be compatible with
existing ocaml libs, but it seems to be less friendly to new users, kinda of legacy inherited from OCaml?
==================
Js.log [%bs "你好"]
would expect output
”你好"
Note "你“ --> in ocaml lexer -> "\228\189\160" --> utf16le --> "20320" -> "\u4f60"
(20320).toString(16)
"4f60"
"\u4f60"
"你"
existing ocaml uutf library: https://github.com/dbuenzli/uutf/blob/master/src/uutf.ml
 bobzhang
bobzhang
All 12 comments
it's okay to to not have first class string processing support, but it is necessary to display, query, compare correctly
"公;司".split(";")
["公", "司"]
links:
http://stackoverflow.com/questions/24379446/utf-8-to-utf-16le-javascript
http://stackoverflow.com/questions/27318715/blob-url-with-utf-16le-encoding
https://mathiasbynens.be/notes/javascript-escapes
bobzhang
on 24 Sep 2016
other syntax:
let x = "你好" [@u16]
note that maybe we don't even need the annotation if we are ok to break some minor compatiblity with native backend
bobzhang
on 25 Sep 2016
to avoid breaking String.length "你", we can introduce such syntax:
{bs|你好|bs}
Note that we can do even better to support string interpolation, but the downside is the syntax is a bit heavy(only heavy for non-ascii)
bobzhang
on 26 Sep 2016
links: https://github.com/joliss/js-string-escape/blob/master/index.js.
Note that
print_string "\201" (dec)
\301 (octal)
we should also be careful of string concatenation {bs|你好|bs} ^ "hello"
bobzhang
on 26 Sep 2016
After consulting golang design, I think the current ocaml string as byte sequence is fine. Here is my proposal to allow unicodes in {j| |j} or {js| |js}. {j| |j}` is like ES6 template strings (no escaping at all), and we support limited string interpolation as below:
let f x = {j|
你好$x
|j}
which will be converted to
var f = x => "你好" + x
I find that bucklescript replaces (some) unicode characters with \x<nn> escape sequences where nn is in UTF-8.
But Javascript wants nn to be latin-1.
This might not happen for Chinese characters, but it happens for characters such as æøå (which are included in latin-1).
 malthe
on 5 Dec 2017
malthe
on 5 Dec 2017
Can you give me an example?
bobzhang
on 6 Dec 2017
If I put a string "æøå" in my source code, i.e.
let s = "æøå" in Js.log(s)
(UTF-8 encoded. Which I think is what we want to assume.)
Then the output contains a \x<nn>-encoded string literal:
console.log("\xc3\xa6\xc3\xb8\xc3\xa5");
The browser then shows the following:
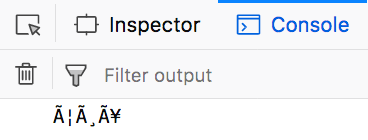
The reason is that those \x<nn> codes actually should be recoded to latin-1 because that's what Javascript requires. Or they should be unicode-coded, e.g. \u<nnnn>.
malthe
on 6 Dec 2017
I've got the same issue, see here: https://bucklescript.github.io/bucklescript-playground/?gist=a1963fb605e0d807f54eeee05e989b29.
A character like å (U+00E5) should _not_ be serialized into the string \xC3\xA5, but rather \u00E5. This might break compatibility with native OCaml even more, but I don't know how problematic that is given that the OCaml String module and Js.String already behaves differently on non-ASCII strings.
I know that I can use {j| |j} or {js| |js} and I am using them whenever possible. The problem is that it's very easy to sneak in a non-ASCII character and then get broken text without even knowing it - even a compiler option to give warnings/errors on non-ASCII characters would be preferable to the current situation.
 mhallin
on 12 Feb 2018
mhallin
on 12 Feb 2018
I have the same issue with letters ÆØÅ/æøå - we're getting hit quite hard by this in Scandinavian languages.
 eirslett
on 6 Apr 2018
eirslett
on 6 Apr 2018
This is also an issue for us, strings like "What’sNew" get converted into something that isn't even JSON.parse-able.
 arnihermann
on 19 Jul 2019
arnihermann
on 19 Jul 2019
@arnihermann I created a separate issue
bobzhang
on 19 Jul 2019
Related issues
 tanaka-de-silva
·
5Comments
tanaka-de-silva
·
5Comments
 frank-dspeed
·
4Comments
bobzhang
·
4Comments
frank-dspeed
·
4Comments
bobzhang
·
4Comments
 wyze
·
3Comments
wyze
·
3Comments
 cknitt
·
5Comments
cknitt
·
5Comments
Most helpful comment
I have the same issue with letters ÆØÅ/æøå - we're getting hit quite hard by this in Scandinavian languages.