Ray: [tune] How to checkpoint best model
What is your question?
So I just ran a tune experiment and got the following output:
| Trial name | status | loc | lr | weight_decay | loss | accuracy |
|--------------------+------------+-------+-------------+----------------+--------+------------|
| trainable_13720f86 | TERMINATED | | 0.00116961 | 0.00371219 | 0.673 | 0.7977 |
| trainable_13792744 | TERMINATED | | 0.109529 | 0.0862344 | 0.373 | 0.8427 |
| trainable_137ecd98 | TERMINATED | | 4.35062e-06 | 0.0261442 | 0.6993 | 0.7837 |
| trainable_1383f9d0 | TERMINATED | | 1.37858e-05 | 0.0974182 | 0.4538 | 0.8428 |
| trainable_13892f72 | TERMINATED | | 0.0335583 | 0.0403495 | 0.3399 | 0.8618 |
| trainable_138dd720 | TERMINATED | | 0.00858623 | 0.0695453 | 0.3415 | 0.8612 |
| trainable_1395570c | TERMINATED | | 4.6309e-05 | 0.0172459 | 0.39 | 0.8283 |
| trainable_139ce148 | TERMINATED | | 2.32951e-05 | 0.0787076 | 0.3641 | 0.8512 |
| trainable_13a848ee | TERMINATED | | 0.00431763 | 0.0341105 | 0.3415 | 0.8611 |
| trainable_13ad0a78 | TERMINATED | | 0.0145063 | 0.050807 | 0.3668 | 0.8398 |
| trainable_13b3342a | TERMINATED | | 5.96148e-06 | 0.0110345 | 0.3418 | 0.8608 |
| trainable_13bd4d3e | TERMINATED | | 1.82617e-06 | 0.0655128 | 0.3667 | 0.8501 |
| trainable_13c45a2a | TERMINATED | | 0.0459573 | 0.0224991 | 0.3432 | 0.8516 |
| trainable_13d561d0 | TERMINATED | | 0.00060595 | 0.092522 | 0.3389 | 0.8623 |
| trainable_13dcb962 | TERMINATED | | 0.000171044 | 0.0449039 | 0.3429 | 0.8584 |
| trainable_13e6fd32 | TERMINATED | | 0.000104752 | 0.089106 | 0.3497 | 0.8571 |
| trainable_13ecd2ac | TERMINATED | | 0.000793432 | 0.0477341 | 0.6007 | 0.8051 |
| trainable_13f27464 | TERMINATED | | 0.0750381 | 0.0685323 | 0.3359 | 0.8616 |
| trainable_13f80b40 | TERMINATED | | 1.3946e-06 | 0.0192844 | 0.5615 | 0.8146 |
| trainable_13fdf6e0 | TERMINATED | | 9.4748e-06 | 0.0542356 | 0.3546 | 0.8493 |
+--------------------+------------+-------+-------------+----------------+--------+------------+
But when I look into the individual results, I find that for the third trial (trainable_137ecd98) even though its final accuracy was low, it had an iteration with higher accuracy than the other trials (89.8%):

If I want to checkpoint and report on the highest accuracy reached (or best other metric) for a given trial, is the intent for the user to keep track of a best_metric for each trial, and to write custom checkpointing when best_metric is updated?
I see there is a checkpoint_at_end option in tune.run, but wouldn't the most common use case be checkpoint_if_best since the last training iteration for a trial is rarely the best?
Thanks!
Ray version and other system information (Python version, TensorFlow version, OS):
'0.9.0.dev0', python 3.7.4, Ubuntu 18.04
 ksanjeevan
ksanjeevan
All 11 comments
@ksanjeevan if you are checkpointing every training iteration you can do something like this:
analysis = tune.run(...)
# Gets best trial based on max accuracy across all training iterations.
best_trial = analysis.get_best_trial(metric="accuracy", mode="max", scope="all")
# Gets best checkpoint for trial based on accuracy.
best_checkpoint = analysis.get_best_checkpoint(best_trial, metric="accuracy")
 amogkam
on 24 Aug 2020
amogkam
on 24 Aug 2020
Your approach of keeping track of best_metric and checkpointing whenever it gets updated should work as well. Also thanks for this bringing this up; I would say the documentation is not great here and we'll update it with more info about how to export the best model.
amogkam
on 24 Aug 2020
There's also tune.run(keep_checkpoint_num=1, checkpoint_score_attr="accuracy") which is essentially "keep_if_best".
 richardliaw
on 24 Aug 2020
richardliaw
on 24 Aug 2020
Thanks for the quick response @amogkam @richardliaw, I'll give it a shot!
ksanjeevan
on 24 Aug 2020
@richardliaw your suggestion also needs checkpoint_freq != 0 for there to be model checkpointing right? I tried it this way but am getting some inconsistent results:
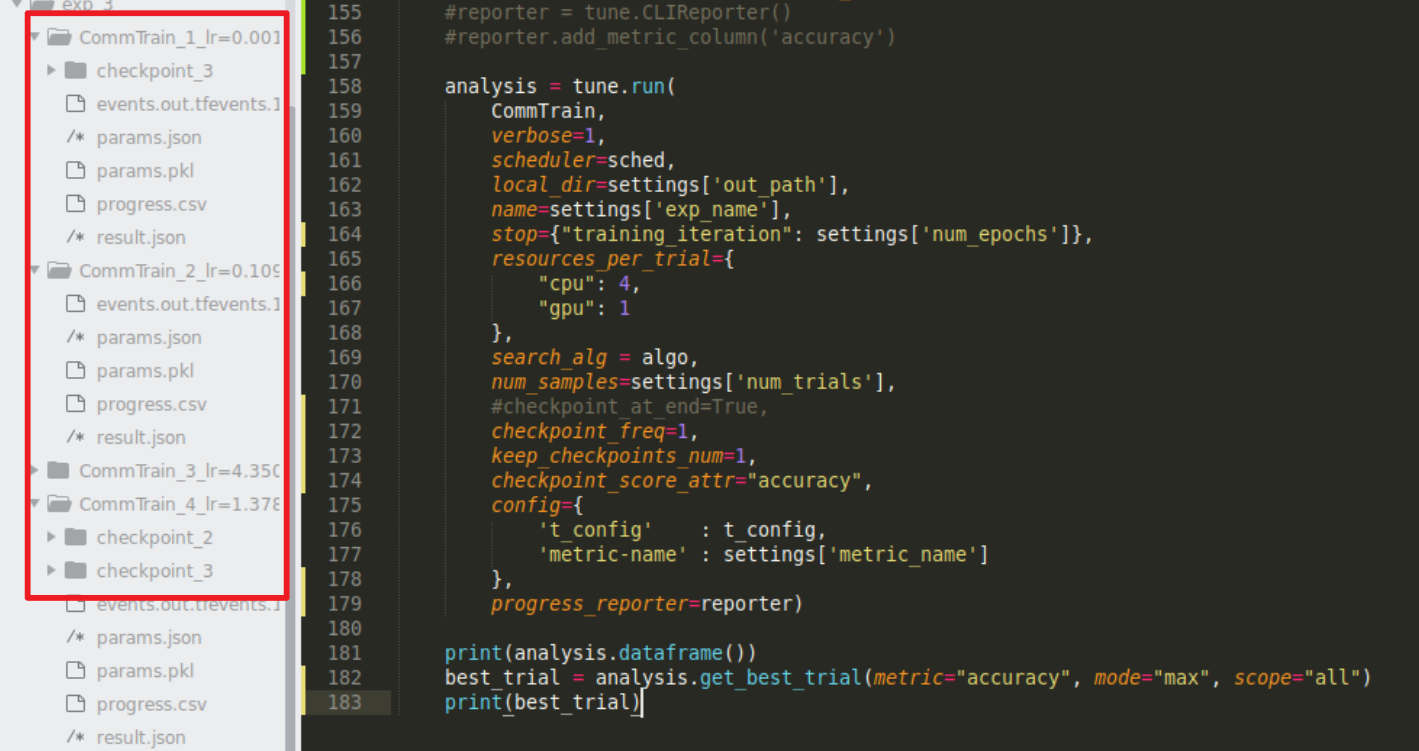
I saw Trial 1 overwrite the checkpoint dir when the accuracy improved (as expected) but then Trial 2 didn't do any checkpoints. Trial 3 had one iteration and a checkpoint but then trial 4 had multiple checkpoints despite keep_checkpoints_num=1.
@amogkam approach of saving all the checkpoints does work it just takes a lot of disk space and I wish I could just overwrite poorer performing weights...
Should I just do manual checkpointing for this use case? Especially if I want the reported metric for a trial to be the best metric and not the last (can keep track of best_metric using tune.Trainable and checking against it in step()?). I might be missing something for the checkpoint_score_attr so I'm unsure.
ksanjeevan
on 24 Aug 2020
@ksanjeevan yeah, you should also set checkpoint_at_end in that case.
richardliaw
on 24 Aug 2020
I'm still getting trials with multiple checkpoints despite keep_checkpoints_num=1 and some trials with no checkpoints at all. But even ignoring this the trial results with Analysis will have the accuracies from last while the checkpoints will be from best.
Even forgetting checkpointing, it would seem more reasonable to have each trial represented by the best metric, and then to compare across trials to get the best model? Especially since different hyperparameters can favour shorter/longer optimal training iterations. Sorry if I'm missing something obvious!
Thanks!
ksanjeevan
on 25 Aug 2020
@ksanjeevan sorry - did you end up setting the following:
analysis = tune.run(keep_checkpoints_num=1, checkpoint_at_end=True)
best_checkpoint = analysis.get_best_checkpoint(metric="...", mode="max", scope="all")
The analysis object has scope parameters, which allow you to choose the trial results from either the last or the best few. Does that make sense?
richardliaw
on 25 Aug 2020
@richardliaw no I did analysis = tune.run(..., keep_checkpoints_num=1, checkpoint_freq=1, checkpoint_score_attr="accuracy"). I also tried with and without checkpoint_at_end=True. This more or less does the job of only keeping the best checkpoint per trial (sometimes giving none, sometimes giving two which I wasn't expecting).
Regarding analysis.get_best_checkpoint(), I don't think it's in the nightly release yet. But even in master I only see
https://github.com/ray-project/ray/blob/6dc22a6d681afb7b3f51719cf9c8f3700483f528/python/ray/tune/analysis/experiment_analysis.py#L170
which requires a trial object (or dir).
ksanjeevan
on 25 Aug 2020
Ok maybe you meant to say get_best_trial() and then use that trial to call get_best_checkpoint(). That makes sense. I guess I'm a bit confused with representing trials in the logging, terminal and analysis.dataframe() with their last metrics (acc, loss, ...) instead of the best, which are what we're after. But I now understand how to get to them.
Appreciate the help!
ksanjeevan
on 25 Aug 2020
Ok so I finally found how to do this cleanly. Here is a toy example in case anyone else runs into this:
class MyTrainable(tune.Trainable):
def setup(self, config):
time.sleep(2)
self.best_acc = float('-inf')
def step(self):
time.sleep(10)
result = {'accuracy' : np.random.rand()}
if result['accuracy'] > self.best_acc:
result.update(should_checkpoint=True)
self.best_acc = result['accuracy']
return result
def save_checkpoint(self, checkpoint_dir):
checkpoint_path = os.path.join(checkpoint_dir, "model.pth")
f = open(checkpoint_path, 'w')
f.write("%s"%self.best_acc)
f.close()
return checkpoint_dir
analysis = tune.run(
MyTrainable,
scheduler=tune.schedulers.ASHAScheduler(metric='accuracy'),
verbose=1,
local_dir='TUNE-BEST-TEST',
name='test',
stop={"training_iteration": 20},
resources_per_trial={
"cpu": 2,
"gpu": 0
},
num_samples=20,
checkpoint_freq=0,
keep_checkpoints_num=1,
checkpoint_score_attr="accuracy",
config={})
So I found the key is to set checkpoint_freq=0 and manually keep track of the best metric in a trial as well as trigger a should_checkpoint=True if it's improved. Together with keep_checkpoints_num=1 only the best model in a trial is stored and it made the output size way more efficient for me.
ksanjeevan
on 17 Sep 2020
Related issues
 WangYiPengPeter
·
3Comments
WangYiPengPeter
·
3Comments
 0luhancheng0
·
3Comments
0luhancheng0
·
3Comments
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 ericl
·
3Comments
robertnishihara
·
3Comments
ericl
·
3Comments
robertnishihara
·
3Comments
Most helpful comment
Your approach of keeping track of
best_metricand checkpointing whenever it gets updated should work as well. Also thanks for this bringing this up; I would say the documentation is not great here and we'll update it with more info about how to export the best model.