Ray: [Tune] Why I always get the tune result (iter=1)?
`config_space = CS.ConfigurationSpace()
config_space.add_hyperparameter(
CS.UniformIntegerHyperparameter('hidden_size_1', lower=30, upper=45))
config_space.add_hyperparameter(
CS.UniformIntegerHyperparameter('hidden_size_2', lower=15, upper=30))
config_space.add_hyperparameter(
CS.UniformFloatHyperparameter("lr", lower=1e-4,upper =1e-2,log=True))
config_space.add_hyperparameter(
CS.UniformFloatHyperparameter("weight_decay", lower=1e-7,upper =1e-3,log=True))
config_space.add_hyperparameter(
CS.CategoricalHyperparameter('activation', choices=['selu', 'leaky_relu', 'elu',"prelu"]))
algo = TuneBOHB(config_space,
max_concurrent=3,
metric="test_mae",mode="min")
sched = HyperBandForBOHB(
time_attr='training_iteration',
metric='test_mae',
mode='min',
max_t=1000)
analysis = tune.run(
TrainRegression,
search_alg =algo ,
scheduler=sched,
loggers=Custom_Loggers ,
name="train_regression",
num_samples=1000,
resources_per_trial={"cpu": 1},
verbose = -1,
stop={
"test_mae": 0.0001,
"training_iteration": 100
},
)`
Ray version and other system information (Python version, TensorFlow version, OS):
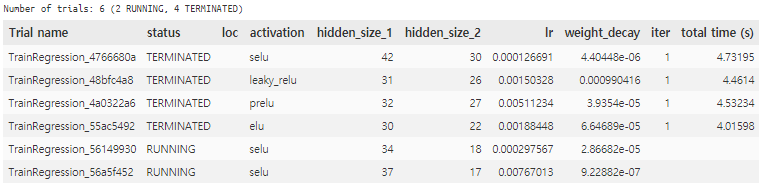
and i always get the training_iteration=1
how can fix this?
thanks you
 sungreong
sungreong
All 7 comments
Hi @sungreong, can you also share the code for TrainRegression please? Thanks
 amogkam
on 13 Aug 2020
amogkam
on 13 Aug 2020
Hi Thank you for your quick response!
now my ray version is 0.8.6
i read the github source.
https://github.com/ray-project/ray/blob/d35f0e40d07bab06b41ce5493c2f50b6725a1857/python/ray/tune/trainable.py
Will this be solved by upgrading the version(0.8.7)?
class TrainRegression(tune.Trainable) :
def _setup(self,config:dict) :
input_dim = config.get("input_dim")
output_dim = config.get("output_dim")
self.config = config
h1 = config.get("hidden_size_1", 25)
h2 = config.get("hidden_size_2", 15)
h3 = config.get("hidden_size_3", 10)
lr = config.get("lr", 0.1)
weight_decay = config.get("weight_decay", 1e-5)
activation = config.get("activation", "selu")
self.train_data_loader = get_data_loader(tr_x, tr_y,batch_size=16)
self.model = torch_model(input_dim,output_dim,
act = activation,
hidden_size=[h1,h2,h3])
self.optimizer = torch.optim.AdamW(self.model.parameters(),
lr=lr,weight_decay=weight_decay)
self.best_metric = np.inf
def _train(self) :
report = collections.defaultdict(list)
arbitrary_folder = os.path.join(cur_path , folder_name ,randomString(10))
make_dir(arbitrary_folder)
for epoch in range(1000) :
for i , (input_) in enumerate(self.train_data_loader) :
self.optimizer.zero_grad()
y_hat = self.model(input_[0])
loss = self.model.criterion(y_hat , input_[1])
loss.backward()
self.optimizer.step()
eval_x , eval_y = iter(self.train_data_loader).next()
result_dict = self._eval(eval_x, eval_y,"train")
if self.best_metric > result_dict["test_mae"] :
top_result = result_dict
best_result = { "folder" : arbitrary_folder, "report" : report}
best_result.update(top_result)
return best_result
def _eval(self, x , y, prefix = "train") :
pred = self.model(x)
pred = pred.detach().numpy()
y_ = y.detach().numpy()
result_dict = Check_Performance(self.y_transformer.inverse_transform(y_),
self.y_transformer.inverse_transform(pred),
threshold = 0.05 ,
prefix = prefix)
return result_dict
def save(self, checkpoint_dir= "./y_models/y1_model.pth") :
checkpoint_dir = make_dir(checkpoint_dir)
checkpoint_dir = self.save_checkpoint(checkpoint_dir)
checkpoint_path = os.path.join(checkpoint_dir,"model.pth")
#raise Exception(type(checkpoint_dir))
return checkpoint_dir
def save_checkpoint(self, checkpoint_dir= "./y_models/y1_model.pth") :
checkpoint_path = os.path.join(checkpoint_dir,"model.pth")
torch.save({
'model_state_dict': self.model.state_dict(),
'optimizer_state_dict': self.optimizer.state_dict(),
'hyper-parameter' : self.config
}, checkpoint_path)
return checkpoint_dir
def load_checkpoint(self, checkpoint_path):
checkpoint = torch.load(checkpoint_path)
self.model.load_state_dict(checkpoint["model_state_dict"])
def _restore(self, checkpoint_path):
print(f"ID: {self.trial_name}: Looking for checkpoint at - {checkpoint_path}")
self.load_checkpoint(checkpoint_path)
def save_to_object(self):
return None
My hunch is that test_mae is already at 0.0001 after the first training iteration, and since this is in your stopping conditions, the trial terminates. Can you confirm that this is the case? If you want to print additional metrics in the console output you can add a reporter to your tune.run:
from ray.tune import CLIReporter
reporter = CLIReporter()
reporter.add_metric_column("test_mae")
tune.run(TrainRegression, progress_reporter=reporter,...)
Yeah; stop assumes that the metrics are increasing. If test_mae > 0.001, the trial would stop.
 richardliaw
on 14 Aug 2020
richardliaw
on 14 Aug 2020
Yeah;
stopassumes that the metrics are _increasing_. If test_mae > 0.001, the trial would stop.
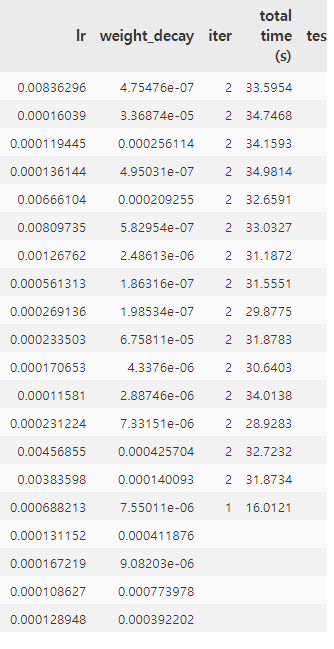
Thanks you! I Change the metric(increasing) and then it is work!
but now iter is only 2
actually i don't know meaning of training_iteration
please tell me about this?
sungreong
on 14 Aug 2020
training_iteration gets incremented every time _train is called. In your example 1 training iteration is actually doing 1000 epochs of training. You might want to have _train just train for 1 epoch and then do validation and return those results.
amogkam
on 14 Aug 2020
Addressed in documentation!
richardliaw
on 16 Sep 2020
Related issues
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
robertnishihara
·
3Comments
robertnishihara
·
3Comments
 Khalilsqu
·
3Comments
Khalilsqu
·
3Comments
 ericl
·
3Comments
robertnishihara
·
3Comments
ericl
·
3Comments
robertnishihara
·
3Comments