Ray: [tune] Saving checkpoint and fetching result get confused in trial_runner
What is the problem?
See error log.
Ray v0.8.4 (worked with 0.7.x)
Python v3.8.2
Archlinux
Error log
100%|██████████| 250/250 [00:00<00:00, 398.50it/s, loss=0.123]2020-04-19 18:20:53,151 ERROR trial_runner.py:547 -- Trial resnet_0: Error handling checkpoint {'timesteps_this_iter': 300, 'CUDA_MEMORY_ALLOCATED': 0, 'CUDA_UTILISATION': 0, 'should_checkpoint': True, 'training/average_roc_auc': 0.8637025256844217, 'training/loss': 0.22345851089566954, 'primary_validation/loss': 0.12281804829835892, 'primary_validation/average_roc_auc': 0.9956737849779087, 'secondary_validation:1/loss': 0.12281804829835892, 'secondary_validation:1/average_roc_auc': 0.9956737849779087, 'secondary_validation:2/loss': 0.12281804829835892, 'secondary_validation:2/average_roc_auc': 0.9956737849779087, 'done': False, 'timesteps_total': 1500, 'episodes_total': None, 'training_iteration': 5, 'experiment_id': 'ce39bdbb87c54b08bc0437b597711491', 'date': '2020-04-19_18-20-53', 'timestamp': 1587320453, 'time_this_iter_s': 6.834269046783447, 'time_total_s': 47.1423065662384, 'pid': 1288, 'hostname': 'runner-8zuylzx-project-12382037-concurrent-0579dt', 'node_ip': '10.48.15.46', 'config': {'training_dataset_id': ObjectID(ffffffffffffffffffffffff0100008801000000), 'primary_validation_dataset_id': ObjectID(ffffffffffffffffffffffff0100008802000000), 'secondary_validation_datasets_id': ObjectID(ffffffffffffffffffffffff0100008803000000), 'pipeline': {'processor': {'type': 'image_classification', 'config': {'image_size': (29, 29), 'mean': (0.617, 0.585, 0.542), 'std': (0.204, 0.212, 0.226), 'brightness': 0.7, 'contrast': 0.7, 'saturation': 10, 'hue': 10, 'greyscale_p': 0.1, 'random_crop_lower_bound': 0.444191940949548, 'use_color_jitter': False}}, 'model': {'type': 'resnet', 'config': {'num_categories': 2, 'version': 18}}, 'optimizer': {'type': 'adam', 'config': {'learning_rate': 3.106821726610642e-05, 'weight_decay': 4.574627219367876e-10}}, 'loss': {'type': 'cross_entropy_probabilistic', 'config': {'categories': ['0 - zero', '1 - one'], 'class_weights': {'0 - zero': 1.0, '1 - one': 1.0}}}}, 'training_dataset_sampler_id': None}, 'time_since_restore': 6.834269046783447, 'timesteps_since_restore': 300, 'iterations_since_restore': 1}
Traceback (most recent call last):
File "/builds/luminovo/lumi/.venv/lib/python3.8/site-packages/ray/tune/trial_runner.py", line 544, in _process_trial_save
trial.on_checkpoint(trial.saving_to)
File "/builds/luminovo/lumi/.venv/lib/python3.8/site-packages/ray/tune/trial.py", line 439, in on_checkpoint
if not os.path.exists(checkpoint.value):
File "/usr/local/lib/python3.8/genericpath.py", line 19, in exists
os.stat(path)
TypeError: stat: path should be string, bytes, os.PathLike or integer, not dict
2020-04-19 18:20:53,318 ERROR trial_runner.py:521 -- Trial resnet_0: Error processing event.
Traceback (most recent call last):
File "/builds/luminovo/lumi/.venv/lib/python3.8/site-packages/ray/tune/trial_runner.py", line 478, in _process_trial
self._total_time += result.get(TIME_THIS_ITER_S, 0)
AttributeError: 'str' object has no attribute 'get'
For some reason the checkpoint.value is not the path returned by Trainable._save but the dict returned by Trainable._train. This leads to the TypeError above, which leads to the AttributeError. It seems that result = self.trial_executor.fetch_result(trial) is suddenly out of sync and returns the checkpoint path when it should return the train result dict and vice versa.
I tried to debug this but I am not sure why it suddenly saves the checkpoint although it should probably process the trial result. Some screenshots from PyCharm:
trial.is_saving == True
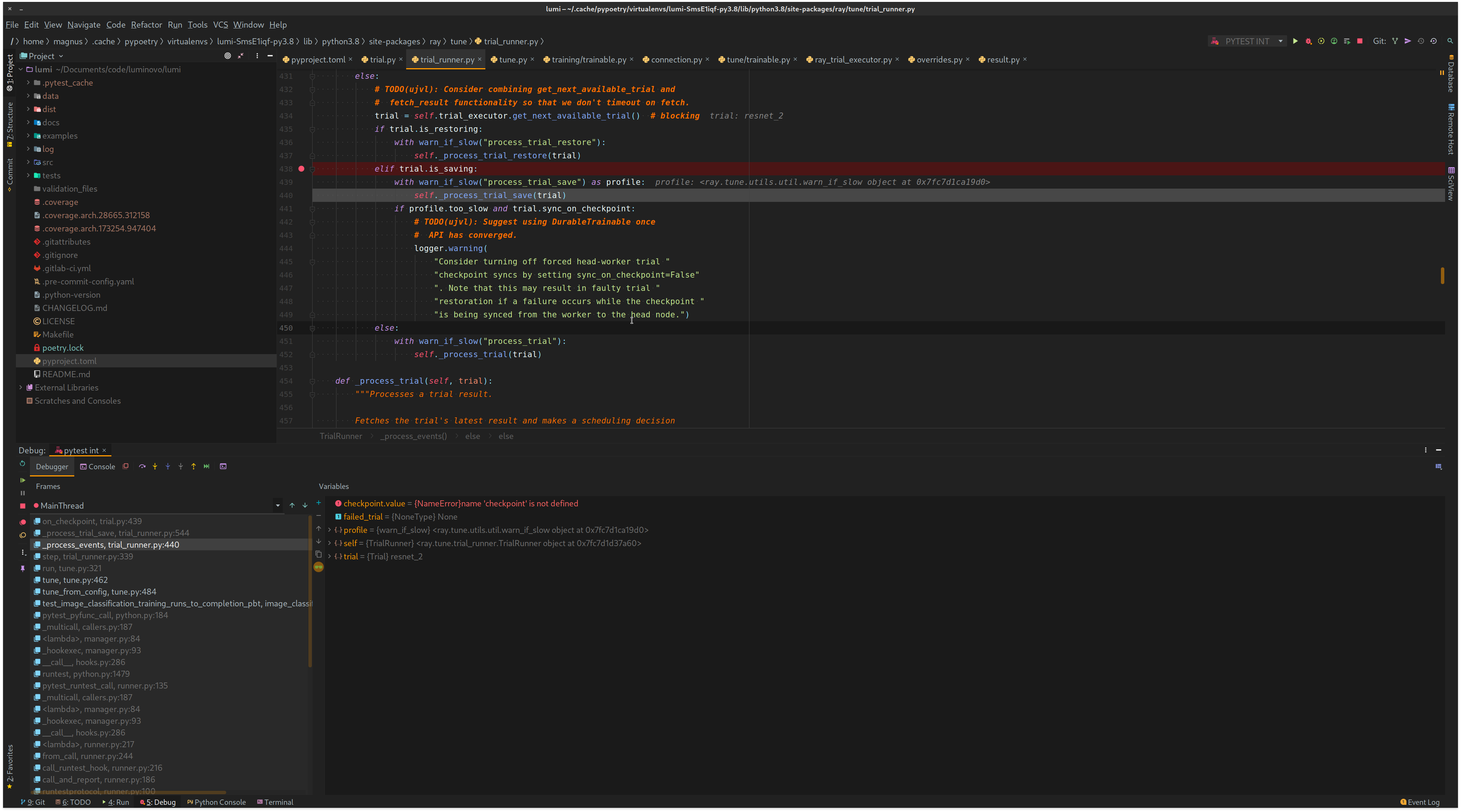
The trial_executor.fetch_result returns the dict from Trainable._train and sets checkpoint_value to that dict (which is wrong?)
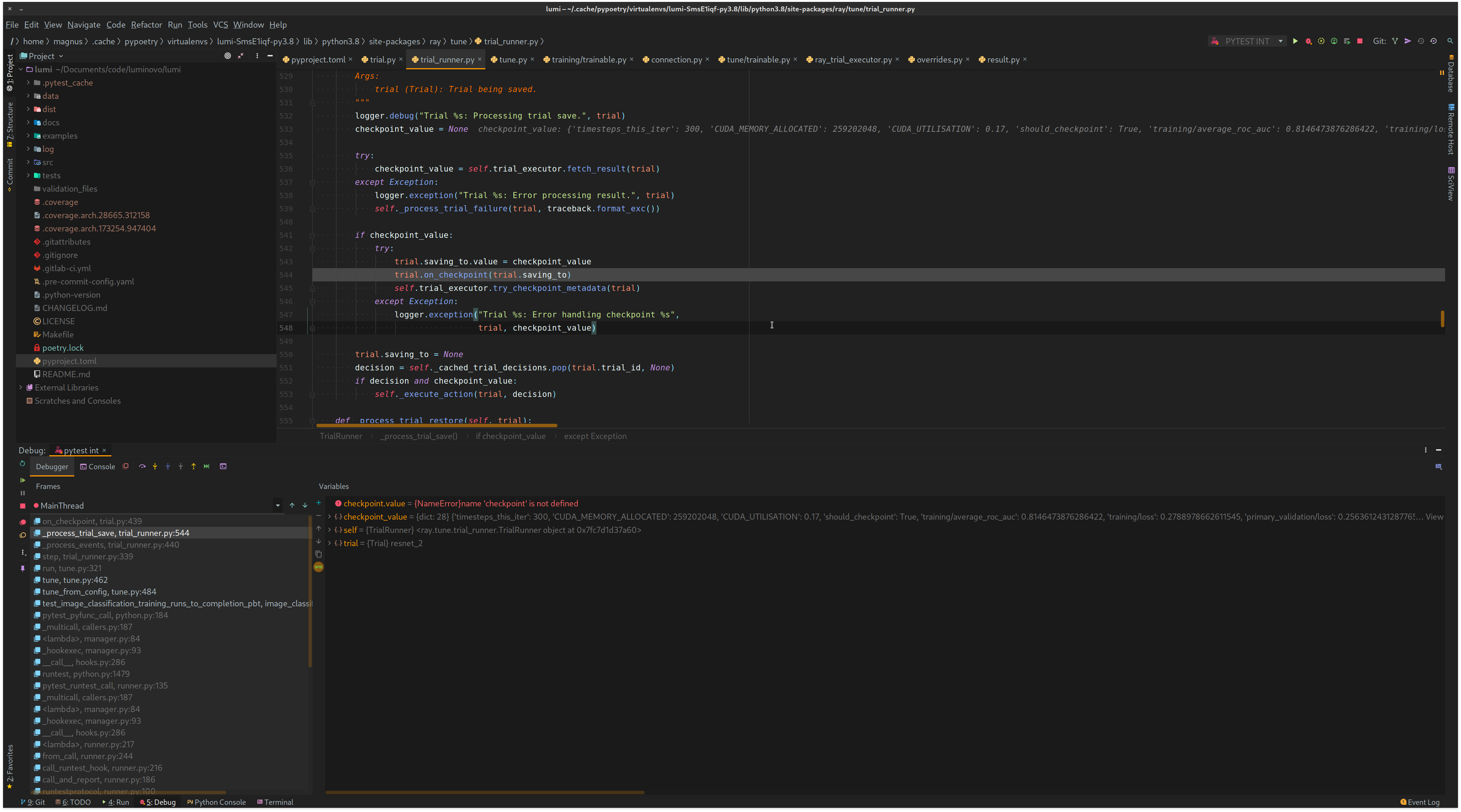
The checkpoint_value is a dict and therefore the run crashes.
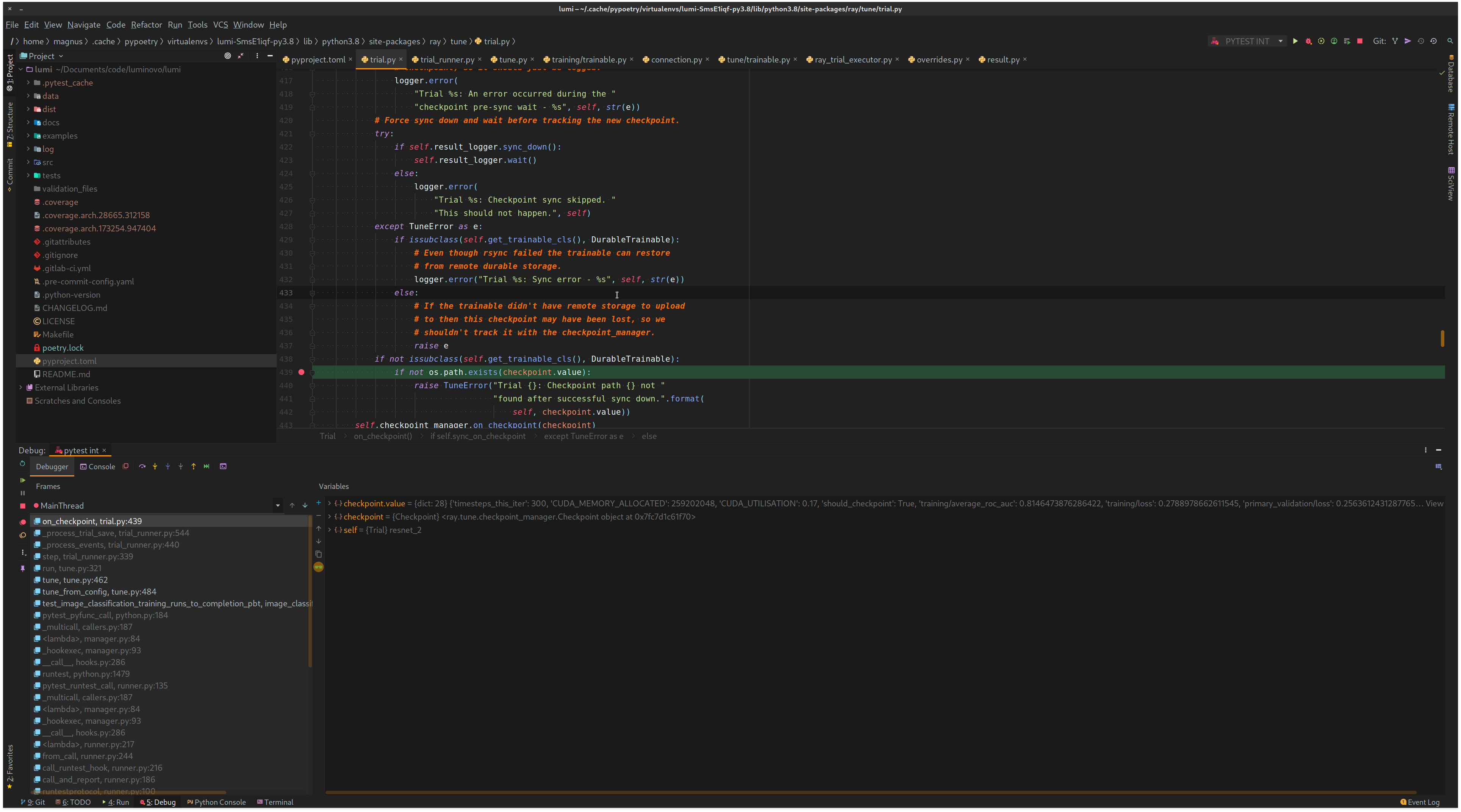
Interestingly enough is that this works a couple of training/validation iterations but at some point crashes.
Excerpt from our trainable:
class LumiTrainable(Trainable, ABC):
"""A trainable skeleton that is missing the `_setup(self, config)` method,
which should be added to the derived classes. Most likely by the builder.
"""
def _set_trainer(self, trainer: Trainer):
self._trainer = trainer
@abstractmethod
def _setup(self, config):
"""Setup the Trainable."""
raise NotImplementedError
@overrides
def _train(self):
"""Run one epoch of tune.
NOTE: during this _train call the self._iteration is not yet incremented.
In order to match the iteration numbers passed to callbacks and reported by ray,
we use `self._iteration+1` instead. This is not applicable outside this
training loop.
Returns:
ray_logs: dict containing data that will be automatically logged by ray
"""
(
train_metrics,
num_datapoints_trained,
utilisation,
memory,
) = self._trainer.train_one_iteration()
val_metrics = self._trainer.evaluate()
return {
TIMESTEPS_THIS_ITER: num_datapoints_trained,
"CUDA_MEMORY_ALLOCATED": memory,
"CUDA_UTILISATION": utilisation,
SHOULD_CHECKPOINT: True,
**train_metrics,
**val_metrics,
}
@overrides
def _save(self, checkpoint_dir):
checkpoint_dir = Path(checkpoint_dir)
if not checkpoint_dir.exists():
log.warning(
"Log directory does not exist! Making directory {}".format(
checkpoint_dir
)
)
checkpoint_dir.mkdir()
lumi_checkpoint_dir = checkpoint_dir / "lumi-checkpoint-{}".format(uuid.uuid4())
lumi_checkpoint_dir.mkdir(parents=True)
self._trainer.save(lumi_checkpoint_dir)
return str(lumi_checkpoint_dir)
 magnusja
magnusja
All 6 comments
Taking a look now..
 richardliaw
on 20 Apr 2020
richardliaw
on 20 Apr 2020
@magnusja are you using PBT by any chance, or a different algorithm?
 ujvl
on 20 Apr 2020
ujvl
on 20 Apr 2020
Hey there,
yes we are using PBT.
magnusja
on 20 Apr 2020
ah okay this is a known issue we'll merge a fix asap
ujvl
on 20 Apr 2020
@magnusja we've just merged a fix. Can you try this out on the Nightly Snapshots of master tomorrow (https://ray.readthedocs.io/en/latest/installation.html)?
Please let me know if you still see an issue - Thanks!
richardliaw
on 21 Apr 2020
Yes this is working perfectly, thanks a lot guys!! :)
magnusja
on 21 Apr 2020
Related issues
 ericl
·
3Comments
ericl
·
3Comments
 timonbimon
·
3Comments
timonbimon
·
3Comments
 austinmw
·
3Comments
austinmw
·
3Comments
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 heavyinfo
·
3Comments
heavyinfo
·
3Comments