Ray: The `experiment_checkpoint` operation took X seconds to complete, which may be a performance bottleneck
As in the title, when running my Trainable object the tune is very slow because X is large (300-500s)
This is the tune.run() call (I don't use ray.init()):
analysis = tune.run(model, name=my_name,
verbose=2, local_dir=local_dir,
stop=Stopper(debug=False),
export_formats=[tune.trial.ExportFormat.MODEL],
checkpoint_score_attr="accuracy",
checkpoint_freq=0, checkpoint_at_end=True,
keep_checkpoints_num=None,
num_samples=400, config=search_space,
resources_per_trial={'cpu': 1, 'gpu': 0.25})
Note that the model is small, a PyTorch CNN with less than 4k parameters.
I've also tried with checkpoint_freq=5 and keep_checkpoints_num=10, without any consistent change.
Ray 0.8.2 (Python 3.7.6, PyTorch 1.4.0, Ubuntu Server 18.04):
 aretor
aretor
All 9 comments
Do you need experiment level fault tolerance? If not, consider setting global_checkpoint_freq=0
 richardliaw
on 24 Mar 2020
richardliaw
on 24 Mar 2020
Hi Richard, I've included this option along with the others, but it seems it's not present, not even in the latest version. Perhaps you were meaning global_checkpoint_period?
aretor
on 24 Mar 2020
In the latter case, the training is still slow. Below is the verbose output printed every X seconds.
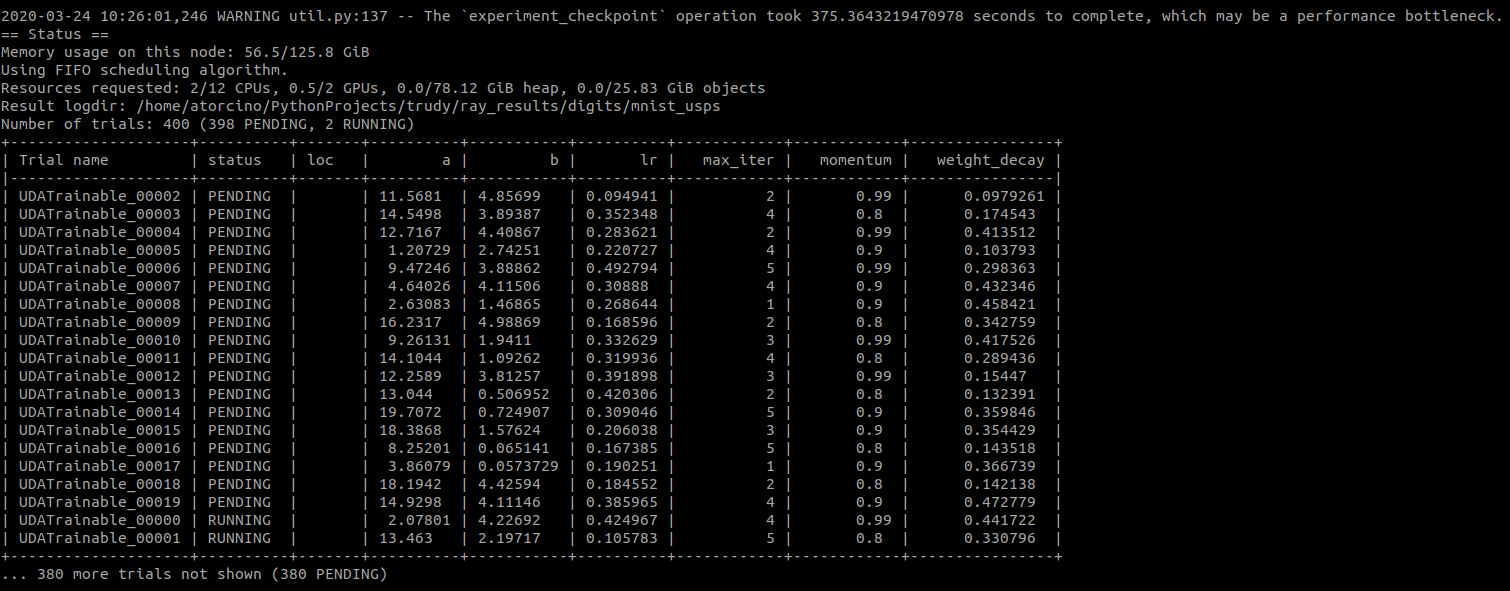
aretor
on 24 Mar 2020
after trying a few ways without success, i just (yesterday) commented def checkpoint(self, force=False): and re-compiled the code.
 MohammadJamali
on 24 Mar 2020
MohammadJamali
on 24 Mar 2020
Ah, do global_checkpoint_period=np.inf.
richardliaw
on 24 Mar 2020
@richardliaw, in the end, that's what I did. By leaving checkpoint_at_end to True, it should be still able to save the final model right (not the best one)? That said, I wonder why checkpointing during training was taking so long.
aretor
on 24 Mar 2020
Yeah; global_checkpint_period is not needed for saving the final models.
richardliaw
on 24 Mar 2020
Closing this for now, but I recognize that this is an issue (for more discussion, go to #7608.)
richardliaw
on 26 Mar 2020
I may possibly have found the solution to my problem.
I was using the config parameter to pass additional parameters such as the model and the dataloaders, which are quite heavy, with respect to the real hyperparameters I search over. By removing them I was able to improve consistently the speed of the hpo process.
aretor
on 26 Mar 2020
Related issues
 WangYiPengPeter
·
3Comments
WangYiPengPeter
·
3Comments
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 coreylowman
·
3Comments
coreylowman
·
3Comments
 zhaokang1228
·
3Comments
zhaokang1228
·
3Comments
 xudongliao
·
3Comments
xudongliao
·
3Comments
Most helpful comment
Ah, do
global_checkpoint_period=np.inf.