Ray: [feature request] PPO compute_action deterministic
I am requesting the ability to grab a PPO agent trained for a stochastic distribution. and add the capability to compute_actions in a deterministic manner, as pointed here.
This feature will allow using rollouts to compare agent behavior on small scales, in a comparable and contained environment, to see to what extent has the agent learnt, without the action's randomness.
 Guilherme-B
Guilherme-B
All 5 comments
I'm not sure to what extent this is going to address the question, but one workaround for discrete action spaces might be to pick the action corresponding to the argmax of the logits.
policy = agent.get_policy()
action, _, info = policy.compute_single_action(observation)
logits = info['logits']
best_action_id = logits.argmax() # deterministic
 FedericoFontana
on 28 Mar 2019
FedericoFontana
on 28 Mar 2019
I did consider doing that, and I'll probably do it, problem is, its only for discrete action spaces - it is a solution for now nonetheless.
Thanks for your help @FedericoFontana
Guilherme-B
on 28 Mar 2019
Ran some preliminary tests. Seems to be working, although something rather odd is happening:
- For most observations, the agent selects the exact same action. This is likely to be an indicator of the agent not being to long-term plan (perhaps due to a small amount of training iterations, 500 for an environment of 3.000 possible actions and a MultiDiscrete(250,11) environment - where 11 is disaster).
Guilherme-B
on 28 Mar 2019
btw for continuous spaces, you can set only the second half of the logits to zero in a custom model (those happen to parameterize the standard deviation).
 ericl
on 28 Mar 2019
ericl
on 28 Mar 2019
Sorry for the long delay, took me a while to get AWS to approve the new instances. Ran tests for a few more training iterations - about 5.5k - and the result is rather odd.
I recorded the actions under custom metrics, to see their evolution throughout time, so I can plot them and get some understanding of what it is learning.
Here is the chart (sorry for the ugly thing, just using excel to make it faster):
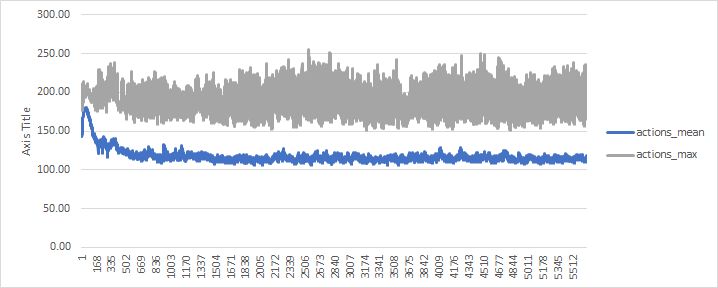
Despite the average of rewards being around 110, what the agent selects on rollout is always in the 240-260 range (the maximum of the selected actions during that period). Is this expected? Can it simply be caused by high entropy factors since it is early in training (I guess 5.5k is not enough for PPO to learn)? Fact is, it should be around 100-ish or lower, should the environment be learning, which it seems to be based on the episode's average action selection.
I am using a checkpoint at 5500 since I interrupted training before it actually completed - I assumed it was enough to prove the point.
Guilherme-B
on 14 Apr 2019
Related issues
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 1beb
·
3Comments
1beb
·
3Comments
 zhaokang1228
·
3Comments
zhaokang1228
·
3Comments
 WangYiPengPeter
·
3Comments
WangYiPengPeter
·
3Comments
 thedrow
·
3Comments
thedrow
·
3Comments
Most helpful comment
I'm not sure to what extent this is going to address the question, but one workaround for discrete action spaces might be to pick the action corresponding to the argmax of the logits.