Ray: [Tune] why only one trial RUNNING and other trials PENDING in each iteration(question)
System information
- OS Platform and Distribution Linux Ubuntu 16.04):
- *Ray installed from source *:
- Ray version: 0.5.3:
- Python version: 3.6.6:
Describe the problem
as title.
Source code / logs
here is my related code:
def data_generator(train_X, train_y, batch_size):
# set data dtype
train_next, train_last, train_this = pd.get_dummies(train_X.iloc[:, 68:]), pd.get_dummies(
train_X.iloc[:, 4:68]), pd.get_dummies(train_X.iloc[:, :4])
batches = (train_X.shape[0] + batch_size - 1) // batch_size
while (True):
for i in range(batches):
X_train_1 = train_next.iloc[i * batch_size: (i + 1) * batch_size, :]
X_train_2 = train_last.iloc[i * batch_size: (i + 1) * batch_size, :]
X_train_3 = train_this.iloc[i * batch_size: (i + 1) * batch_size, :]
Y_train = train_y.iloc[i * batch_size: (i + 1) * batch_size, :]
yield [X_train_1, X_train_2, X_train_3], Y_train
def train_model_tune(config, reporter):
# read_data
data = pd.read_csv(r'/home/zhouhao/Downloads/temp/X.csv', index_col=0)
y = pd.read_csv(r'/home/zhouhao/Downloads/temp/y.csv', index_col=0)
columns = data.columns.values
#to_category type
cat1 = columns[3]
cat2 = columns[12:20]
cat3 = columns[76:84]
data.loc[:, cat1] = data.loc[:, cat1].astype(dtype='category', inplace=True)
data.loc[:, cat2] = data.loc[:, cat2].astype(dtype='category', inplace=True)
data.loc[:, cat3] = data.loc[:, cat3].astype(dtype='category', inplace=True)
batch_size = config['batch_size']
# split data
train_X, test_X, train_y, test_y = train_test_split(
data, y, test_size=0.05, random_state=2018)
test_next, test_last, test_this = pd.get_dummies(test_X.iloc[:, 68:]), pd.get_dummies(
test_X.iloc[:, 4:68]), pd.get_dummies(test_X.iloc[:, :4])
#model
model = prediction_model(config)
# set callback
tensorBoard = TensorBoard(log_dir=r'/home/zhouhao/Downloads/traffic_prediction/model',
histogram_freq=1, write_graph=True, write_images=TabError, write_grads=True)
earlyStopping = EarlyStopping(
monitor='val_loss', min_delta=0, patience=15, verbose=2, mode='auto')
filepath = r"/home/zhouhao/Downloads/temp/model/weights-improvement-{epoch:02d}-{val_loss:.2f}.hdf5"
check_point = ModelCheckpoint(
filepath, monitor='val_loss', mode='auto', verbose=1, save_best_only=True)
#training model on batch
for i, (x_batch, y_batch) in enumerate(data_generator(train_X, train_y, batch_size)):
model.fit(x_batch, y_batch,
batch_size=batch_size,
verbose=1,
callbacks=[earlyStopping, tensorBoard, check_point],
validation_data=([test_next, test_last, test_this], test_y))
if i % 5 == 0:
last_checkpoint = "/home/zhouhao/Downloads/temp/model/traffic_predict_model_weights_{}.h5".format(i)
model.save_weights(last_checkpoint)
loss = model.evaluate(x_batch, y_batch)
reporter(mean_loss=loss, # Change me
timesteps_total=i,
checkpoint=last_checkpoint)
here is the training status:
/home/zhouhao/.conda/envs/py36/bin/python /home/zhouhao/PycharmProjects/ML_nn/traffic_prediction_dense_tune.py
Using TensorFlow backend.
Process STDOUT and STDERR is being redirected to /tmp/raylogs/.
Waiting for redis server at 127.0.0.1:21826 to respond...
Waiting for redis server at 127.0.0.1:58818 to respond...
Starting the Plasma object store with 26.00 GB memory.
Starting local scheduler with the following resources: {'CPU': 10, 'GPU': 2}.
Failed to start the UI, you may need to run 'pip install jupyter'.
== Status ==
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 150.000: None | Iter 50.000: None
Bracket: Iter 150.000: None
Bracket:
tpe_transform took 0.018963 seconds
TPE using 0 trials
/home/zhouhao/.local/lib/python3.6/site-packages/ray/tune/logger.py:183: FutureWarning: Conversion of the second argument of issubdtype from float to np.floating is deprecated. In future, it will be treated as np.float64 == np.dtype(float).type.
if np.issubdtype(value, float):
/home/zhouhao/.local/lib/python3.6/site-packages/ray/tune/logger.py:185: FutureWarning: Conversion of the second argument of issubdtype from int to np.signedinteger is deprecated. In future, it will be treated as np.int64 == np.dtype(int).type.
if np.issubdtype(value, int):
tpe_transform took 0.016496 seconds
TPE using 1/1 trials with best loss inf
tpe_transform took 0.013365 seconds
TPE using 2/2 trials with best loss inf
tpe_transform took 0.012837 seconds
TPE using 3/3 trials with best loss inf
tpe_transform took 0.015328 seconds
TPE using 4/4 trials with best loss inf
tpe_transform took 0.014770 seconds
TPE using 5/5 trials with best loss inf
tpe_transform took 0.014560 seconds
TPE using 6/6 trials with best loss inf
tpe_transform took 0.014756 seconds
TPE using 7/7 trials with best loss inf
tpe_transform took 0.014358 seconds
TPE using 8/8 trials with best loss inf
tpe_transform took 0.014783 seconds
TPE using 9/9 trials with best loss inf
Created LogSyncer for /home/zhouhao/ray_results/traffic prediction/train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160_2018-11-23_20-21-50zwji2gc5 ->
== Status ==
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 150.000: None | Iter 50.000: None
Bracket: Iter 150.000: None
Bracket:
Resources requested: 10/10 CPUs, 2/2 GPUs
Result logdir: /home/zhouhao/ray_results/traffic prediction
PENDING trials:
- train_model_tune_2_e=204800,t=0.4,1=224,2=128,t=160,r=0.0005,t=0.7,1=288,2=256,t=256,t=0.4,1=256,2=224: PENDING
- train_model_tune_3_e=102400,t=0.6,1=416,2=224,t=256,r=0.005,t=0.7,1=480,2=128,t=128,t=0.6,1=352,2=128: PENDING
- train_model_tune_4_e=409600,t=0.7,1=192,2=192,t=160,r=1e-05,t=0.6,1=416,2=160,t=192,t=0.6,1=480,2=192: PENDING
- train_model_tune_5_e=204800,t=0.3,1=224,2=224,t=128,r=0.001,t=0.7,1=448,2=160,t=160,t=0.4,1=352,2=192: PENDING
- train_model_tune_6_e=409600,t=0.8,1=384,2=192,t=224,r=0.005,t=0.4,1=288,2=160,t=256,t=0.8,1=480,2=224: PENDING
- train_model_tune_7_e=102400,t=0.7,1=384,2=224,t=256,r=1e-05,t=0.4,1=352,2=128,t=224,t=0.6,1=416,2=192: PENDING
- train_model_tune_8_e=25600,t=0.4,1=128,2=128,t=128,r=0.001,t=0.4,1=448,2=128,t=256,t=0.7,1=352,2=256: PENDING
- train_model_tune_9_e=12800,t=0.4,1=512,2=192,t=160,r=0.005,t=0.8,1=352,2=224,t=160,t=0.6,1=256,2=128: PENDING
- train_model_tune_10_e=12800,t=0.8,1=320,2=192,t=192,r=1e-05,t=0.5,1=512,2=256,t=192,t=0.3,1=512,2=160: PENDING
RUNNING trials: - train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160: RUNNING
Using TensorFlow backend.
/home/zhouhao/.conda/envs/py36/lib/python3.6/site-packages/numpy/lib/arraysetops.py:472: FutureWarning: elementwise comparison failed; returning scalar instead, but in the future will perform elementwise comparison
mask |= (ar1 == a)
train_X:(4666873, 132)
Train on 12800 samples, validate on 245625 samples
2018-11-23 20:23:23.566946: I tensorflow/core/platform/cpu_feature_guard.cc:141] Your CPU supports instructions that this TensorFlow binary was not compiled to use: AVX2 FMA
2018-11-23 20:23:23.760398: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 0 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.721
pciBusID: 0000:06:00.0
totalMemory: 10.91GiB freeMemory: 10.75GiB
2018-11-23 20:23:23.890120: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1432] Found device 1 with properties:
name: GeForce GTX 1080 Ti major: 6 minor: 1 memoryClockRate(GHz): 1.721
pciBusID: 0000:05:00.0
totalMemory: 10.91GiB freeMemory: 10.62GiB
2018-11-23 20:23:23.892008: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1511] Adding visible gpu devices: 0, 1
2018-11-23 20:23:24.233047: I tensorflow/core/common_runtime/gpu/gpu_device.cc:982] Device interconnect StreamExecutor with strength 1 edge matrix:
2018-11-23 20:23:24.233078: I tensorflow/core/common_runtime/gpu/gpu_device.cc:988] 0 1
2018-11-23 20:23:24.233083: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 0: N Y
2018-11-23 20:23:24.233086: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1001] 1: Y N
2018-11-23 20:23:24.233481: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 10398 MB memory) -> physical GPU (device: 0, name: GeForce GTX 1080 Ti, pci bus id: 0000:06:00.0, compute capability: 6.1)
2018-11-23 20:23:24.233725: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 10269 MB memory) -> physical GPU (device: 1, name: GeForce GTX 1080 Ti, pci bus id: 0000:05:00.0, compute capability: 6.1)
Epoch 1/1
12800/12800 [==============================] - 1s 89us/step - loss: 20758.0859 - val_loss: 6029.8121
Epoch 00001: val_loss improved from inf to 6029.81209, saving model to /home/zhouhao/Downloads/temp/model/weights-improvement-01-6029.81.hdf5
12800/12800 [==============================] - 1s 42us/step
Train on 12800 samples, validate on 245625 samples
Result for train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160:
checkpoint: /home/zhouhao/Downloads/temp/model/traffic_predict_model_weights_0.h5
date: 2018-11-23_20-25-30
done: false
experiment_id: 18ce2f2a746f46a99e70b60fb430e0b0
hostname: zhouhaoPC
iterations_since_restore: 1
mean_loss: 5680.058518676758
neg_mean_loss: -5680.058518676758
node_ip: 192.168.3.104
pid: 721
time_since_restore: 217.86471009254456
time_this_iter_s: 217.86471009254456
time_total_s: 217.86471009254456
timestamp: 1542975930
timesteps_since_restore: 0
timesteps_this_iter: 0
timesteps_total: 0
training_iteration: 1
== Status ==
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 150.000: None | Iter 50.000: None
Bracket: Iter 150.000: None
Bracket:
Resources requested: 10/10 CPUs, 2/2 GPUs
Result logdir: /home/zhouhao/ray_results/traffic prediction
PENDING trials:
- train_model_tune_2_e=204800,t=0.4,1=224,2=128,t=160,r=0.0005,t=0.7,1=288,2=256,t=256,t=0.4,1=256,2=224: PENDING
- train_model_tune_3_e=102400,t=0.6,1=416,2=224,t=256,r=0.005,t=0.7,1=480,2=128,t=128,t=0.6,1=352,2=128: PENDING
- train_model_tune_4_e=409600,t=0.7,1=192,2=192,t=160,r=1e-05,t=0.6,1=416,2=160,t=192,t=0.6,1=480,2=192: PENDING
- train_model_tune_5_e=204800,t=0.3,1=224,2=224,t=128,r=0.001,t=0.7,1=448,2=160,t=160,t=0.4,1=352,2=192: PENDING
- train_model_tune_6_e=409600,t=0.8,1=384,2=192,t=224,r=0.005,t=0.4,1=288,2=160,t=256,t=0.8,1=480,2=224: PENDING
- train_model_tune_7_e=102400,t=0.7,1=384,2=224,t=256,r=1e-05,t=0.4,1=352,2=128,t=224,t=0.6,1=416,2=192: PENDING
- train_model_tune_8_e=25600,t=0.4,1=128,2=128,t=128,r=0.001,t=0.4,1=448,2=128,t=256,t=0.7,1=352,2=256: PENDING
- train_model_tune_9_e=12800,t=0.4,1=512,2=192,t=160,r=0.005,t=0.8,1=352,2=224,t=160,t=0.6,1=256,2=128: PENDING
- train_model_tune_10_e=12800,t=0.8,1=320,2=192,t=192,r=1e-05,t=0.5,1=512,2=256,t=192,t=0.3,1=512,2=160: PENDING
RUNNING trials: - train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160: RUNNING [pid=721], 217 s, 1 iter, 0 ts, 5.68e+03 loss
Epoch 1/1
12800/12800 [==============================] - 1s 41us/step - loss: 23765.1250 - val_loss: 6017.1088
Epoch 00001: val_loss improved from 6029.81209 to 6017.10883, saving model to /home/zhouhao/Downloads/temp/model/weights-improvement-01-6017.11.hdf5
12800/12800 [==============================] - 1s 41us/step
Train on 12800 samples, validate on 245625 samples
Result for train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160:
checkpoint: /home/zhouhao/Downloads/temp/model/traffic_predict_model_weights_0.h5
date: 2018-11-23_20-27-33
done: false
experiment_id: 18ce2f2a746f46a99e70b60fb430e0b0
hostname: zhouhaoPC
iterations_since_restore: 2
mean_loss: 5819.795842285156
neg_mean_loss: -5819.795842285156
node_ip: 192.168.3.104
pid: 721
time_since_restore: 340.99321818351746
time_this_iter_s: 123.1285080909729
time_total_s: 340.99321818351746
timestamp: 1542976053
timesteps_since_restore: 1
timesteps_this_iter: 1
timesteps_total: 1
training_iteration: 2
== Status ==
Using AsyncHyperBand: num_stopped=0
Bracket: Iter 150.000: None | Iter 50.000: None
Bracket: Iter 150.000: None
Bracket:
Resources requested: 10/10 CPUs, 2/2 GPUs
Result logdir: /home/zhouhao/ray_results/traffic prediction
PENDING trials:
- train_model_tune_2_e=204800,t=0.4,1=224,2=128,t=160,r=0.0005,t=0.7,1=288,2=256,t=256,t=0.4,1=256,2=224: PENDING
- train_model_tune_3_e=102400,t=0.6,1=416,2=224,t=256,r=0.005,t=0.7,1=480,2=128,t=128,t=0.6,1=352,2=128: PENDING
- train_model_tune_4_e=409600,t=0.7,1=192,2=192,t=160,r=1e-05,t=0.6,1=416,2=160,t=192,t=0.6,1=480,2=192: PENDING
- train_model_tune_5_e=204800,t=0.3,1=224,2=224,t=128,r=0.001,t=0.7,1=448,2=160,t=160,t=0.4,1=352,2=192: PENDING
- train_model_tune_6_e=409600,t=0.8,1=384,2=192,t=224,r=0.005,t=0.4,1=288,2=160,t=256,t=0.8,1=480,2=224: PENDING
- train_model_tune_7_e=102400,t=0.7,1=384,2=224,t=256,r=1e-05,t=0.4,1=352,2=128,t=224,t=0.6,1=416,2=192: PENDING
- train_model_tune_8_e=25600,t=0.4,1=128,2=128,t=128,r=0.001,t=0.4,1=448,2=128,t=256,t=0.7,1=352,2=256: PENDING
- train_model_tune_9_e=12800,t=0.4,1=512,2=192,t=160,r=0.005,t=0.8,1=352,2=224,t=160,t=0.6,1=256,2=128: PENDING
- train_model_tune_10_e=12800,t=0.8,1=320,2=192,t=192,r=1e-05,t=0.5,1=512,2=256,t=192,t=0.3,1=512,2=160: PENDING
RUNNING trials: - train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160: RUNNING [pid=721], 340 s, 2 iter, 1 ts, 5.82e+03 loss
Epoch 1/1
12800/12800 [==============================] - 1s 42us/step - loss: 22130.4453 - val_loss: 6006.1089
Epoch 00001: val_loss improved from 6017.10883 to 6006.10893, saving model to /home/zhouhao/Downloads/temp/model/weights-improvement-01-6006.11.hdf5
12800/12800 [==============================] - 1s 42us/step
Train on 12800 samples, validate on 245625 samples
Result for train_model_tune_1_e=12800,t=0.8,1=320,2=224,t=160,r=1e-06,t=0.4,1=288,2=256,t=160,t=0.7,1=288,2=160:
checkpoint: /home/zhouhao/Downloads/temp/model/traffic_predict_model_weights_0.h5
date: 2018-11-23_20-29-36
done: false
experiment_id: 18ce2f2a746f46a99e70b60fb430e0b0
hostname: zhouhaoPC
iterations_since_restore: 3
mean_loss: 6045.423405151367
neg_mean_loss: -6045.423405151367
node_ip: 192.168.3.104
pid: 721
time_since_restore: 464.17469453811646
time_this_iter_s: 123.181476354599
time_total_s: 464.17469453811646
timestamp: 1542976176
timesteps_since_restore: 2
timesteps_this_iter: 1
timesteps_total: 2
training_iteration: 3
Any advise? thank you~
 chjq201410695
chjq201410695
All 11 comments
Did you set resources properly ?https://ray.readthedocs.io/en/latest/tune-usage.html#using-gpus-resource-allocation
 ericl
on 23 Nov 2018
ericl
on 23 Nov 2018
yes. I have set trial_resources .
here is related code:
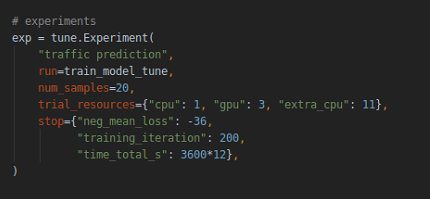
chjq201410695
on 24 Nov 2018
I don't know if the reason come from for loop of data_generator:
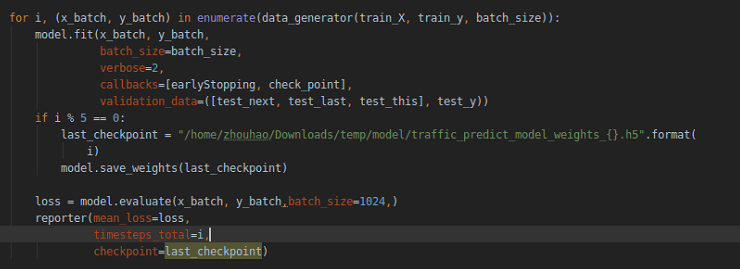
chjq201410695
on 24 Nov 2018
Did you set resources properly ?https://ray.readthedocs.io/en/latest/tune-usage.html#using-gpus-resource-allocation
yes. though I set extral cpu and extral gpu, only one cpu and one gpu are working.
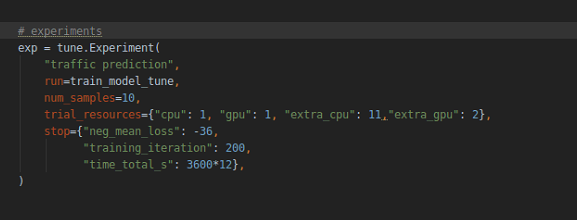
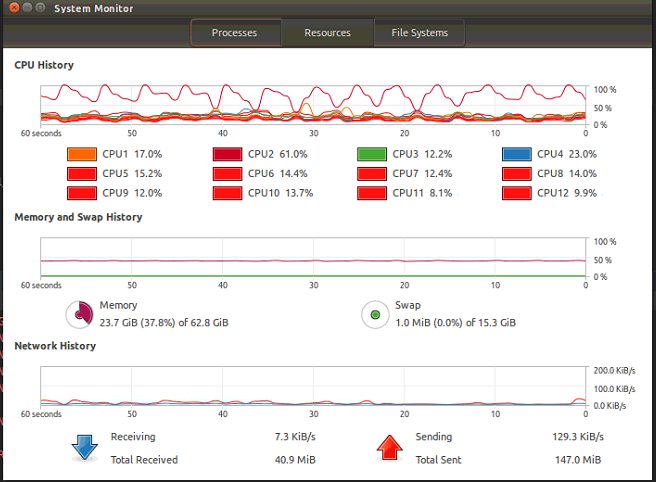
it seems like trails are training one by one;, not parallelly.
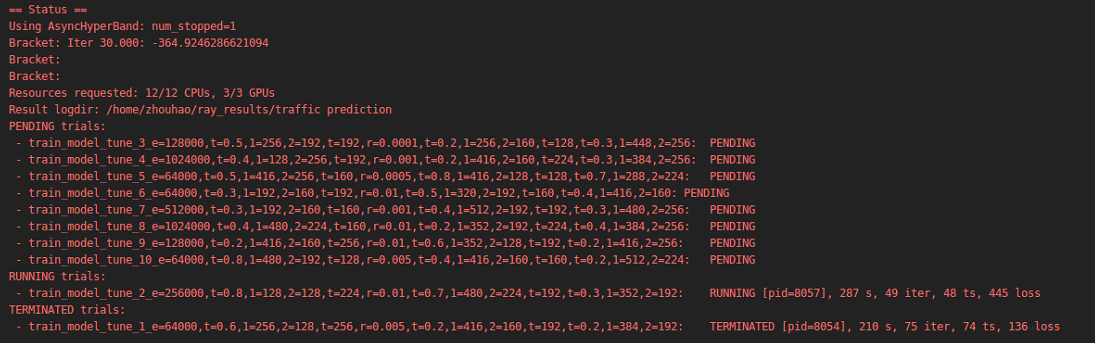
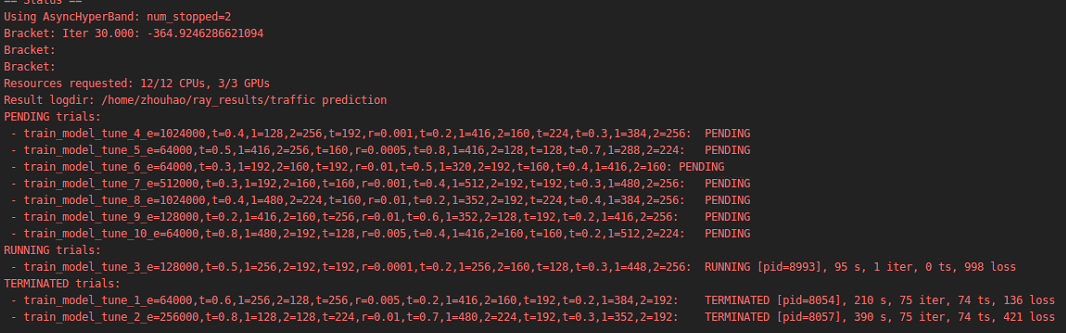
chjq201410695
on 24 Nov 2018
extra_cpus actually is assigned to the same trial, rather than indicating what is the number of resources allocated to the experiment in total.
If you turn off extra_cpus and set gpu: 0.5 or something, you should see multiple runs in parallel.
Let me know if that works.
 richardliaw
on 24 Nov 2018
richardliaw
on 24 Nov 2018
extra_cpusactually is assigned to the same trial, rather than indicating what is the number of resources allocated to the experiment in total.If you turn off extra_cpus and set
gpu: 0.5or something, you should see multiple runs in parallel.Let me know if that works.
ah, I misunderstood it. get it ! it works! thanks :)
another question:
if the following error means resource not enough, and I need allocating more source to each trail, i.e. from gpu:0.5 to gpu:1
Check failed: state->available_gpus.size() >= resource_quantity
* Check failure stack trace: *
@ 0x49976a google::LogMessage::Fail()
@ 0x4996b6 google::LogMessage::SendToLog()
@ 0x49903a google::LogMessage::Flush()
@ 0x498e49 google::LogMessage::~LogMessage()
@ 0x48a030 ray::RayLog::~RayLog()
@ 0x4300ee acquire_resources()
@ 0x432ff0 assign_task_to_worker()
@ 0x43c2db dispatch_tasks()
@ 0x440681 handle_task_scheduled()
@ 0x4306de handle_task_scheduled_callback()
@ 0x45d3ec redis_task_table_subscribe_callback()
@ 0x48b536 redisProcessCallbacks
@ 0x466f47 aeProcessEvents
@ 0x4671eb aeMain
@ 0x42def7 main
@ 0x7f9d9c0f5830 __libc_start_main
@ 0x42f101 (unknown)
chjq201410695
on 24 Nov 2018
Hm, maybe try the newest version of Ray from the latest wheels? https://ray.readthedocs.io/en/latest/installation.html
richardliaw
on 24 Nov 2018
Hm, maybe try the newest version of Ray from the latest wheels? https://ray.readthedocs.io/en/latest/installation.html
OK, but it works well as I set gpu from 0.5 to 1. and 3 trails work parallelly. if I turn off gpu. only set cpu as 1. 10 trails work parallelly, but out of memory will arise.
chjq201410695
on 24 Nov 2018
Sure; the data loaded is probably too large to be done 10 times at the same time. Setting GPU to 0.5 will allow you to run 6 trials in parallel while utilizing the GPU so that your trials run faster.
richardliaw
on 24 Nov 2018
Sure; the data loaded is probably too large to be done 10 times at the same time. Setting GPU to 0.5 will allow you to run 6 trials in parallel while utilizing the GPU so that your trials run faster.
Thank you very much!
chjq201410695
on 24 Nov 2018
How to set the number of trials running in parallel?? https://docs.ray.io/en/master/tune/api_docs/execution.html
Setting gpu=0.5 can start 2 trials while setting gpu=0.1 can start 10 trials. But what if I want to start 20 trials? setting gpu=0.05 does not work. Besides, setting gpu to a decimal number is unclear to me...
Is there explicit instruction on how to set the number of trials in parallel? and specifically more than 10 trials.
 guoxuxu
on 27 Jul 2020
guoxuxu
on 27 Jul 2020
Related issues
 thedrow
·
3Comments
thedrow
·
3Comments
 dragon28
·
3Comments
dragon28
·
3Comments
 austinmw
·
3Comments
austinmw
·
3Comments
 0luhancheng0
·
3Comments
0luhancheng0
·
3Comments
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
Most helpful comment
How to set the number of trials running in parallel?? https://docs.ray.io/en/master/tune/api_docs/execution.html
Setting gpu=0.5 can start 2 trials while setting gpu=0.1 can start 10 trials. But what if I want to start 20 trials? setting gpu=0.05 does not work. Besides, setting gpu to a decimal number is unclear to me...
Is there explicit instruction on how to set the number of trials in parallel? and specifically more than 10 trials.