Ray: [rllib] How does the use_lstm option work?
I'm curious about the use_lstm option and the associated max_seq_len and lstm_cell_size options when configuring a model in RLlib. Specifically, how does the LSTM work and what values does it remember?
The documentation says that an LSTM cell further processes the original model's output which adds a linear layer at the end for final output. The diagram below illustrates my understanding:
state -> model -> LSTM -> action
Is my understanding of the LSTM correct? How does an LSTM at the output of the original model improve agent behavior? To me, it doesn't seem like the LSTM adds much information about the past states.
Thanks for the help, and sorry about the many questions! I'm fairly new to reinforcement learning.
 pschafhalter
pschafhalter
All 8 comments
cc @ericl
 richardliaw
on 2 Aug 2018
richardliaw
on 2 Aug 2018
What you're missing is the hidden state input and output of the LSTM. So a more complete diagram looks like this:
observation (o_t), hidden state (h_t)
---------\
o_0, h_0 / o_1, h_1 (inputs)
| | / | |
| | / | |
model | / model |
\ / / \ /
cell / cell etc...
| / | /
a_0, h_1 a_1, h_2 (outputs)
So the observation is first processed by the model, then the outputs of that and the LSTM hidden state are passed to the LSTM cell. The LSTM cell emits the new model outputs, and also the next hidden state.
During training, you view the entire sequence of evaluations as one large network, with some truncation (max_seq_len) for backpropagation.
The IMPALA paper has a nice figure:
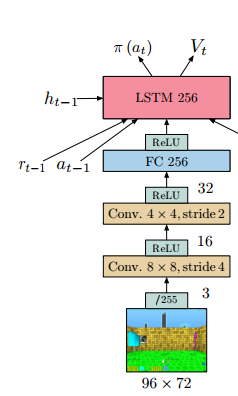
 ericl
on 2 Aug 2018
ericl
on 2 Aug 2018
Btw instead of using a LSTM, you can also use "preprocessor_pref": "deepmind" to enable framestacking. That works pretty well for atari.
ericl
on 2 Aug 2018
This clears a lot of things up, thanks for the explanation!
Is the lstm_cell_size the size of the hidden state?
pschafhalter
on 2 Aug 2018
That's right (see https://github.com/ray-project/ray/search?q=lstm_cell_size&unscoped_q=lstm_cell_size and https://www.tensorflow.org/api_docs/python/tf/contrib/rnn/BasicRNNCell).
ericl
on 2 Aug 2018
Thanks for the help!
pschafhalter
on 7 Aug 2018
Hi, sorry for digging this old issue. I am pretty new to machine learning in general, and this use_lstm option also bugs me. My main concern is why, with usual LSTM inputs, we input a 3D array (batch x time x features), but in all the exemples with use_lstm provided (such as https://github.com/ray-project/ray/blob/5d7afe8092f5521a8faa8cdfc916dcd9a5848023/rllib/examples/cartpole_lstm.py ), only a 2D array is provided.
 LucCADORET
on 31 Jan 2020
LucCADORET
on 31 Jan 2020
RLlib records the episode lengths in a separate seq_lens tensor, and
automatically adds the time dimension based on the sequence lengths prior
to passing the data to the LSTM.
On Fri, Jan 31, 2020, 1:17 AM LucCADORET notifications@github.com wrote:
Hi, sorry for digging this old issue. I am pretty new to machine learning
in general, and this use_lstm option also bugs me. My main concern is why,
with usual LSTM inputs, we input a 3D array (batch x time x features), but
in all the exemples with use_lstm provided (such as
https://github.com/ray-project/ray/blob/5d7afe8092f5521a8faa8cdfc916dcd9a5848023/rllib/examples/cartpole_lstm.py
), only a 2D array is provided.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/ray-project/ray/issues/2536?email_source=notifications&email_token=AAADUSQ2BVM2W4SDKH4LWHLRAPUDRA5CNFSM4FNNMLT2YY3PNVWWK3TUL52HS4DFVREXG43VMVBW63LNMVXHJKTDN5WW2ZLOORPWSZGOEKOAYOY#issuecomment-580652091,
or unsubscribe
https://github.com/notifications/unsubscribe-auth/AAADUSVPMCWJI3SNNFO4TB3RAPUDRANCNFSM4FNNMLTQ
.
ericl
on 31 Jan 2020
Related issues
 coreylowman
·
3Comments
coreylowman
·
3Comments
 AndreCNF
·
3Comments
AndreCNF
·
3Comments
 monocongo
·
3Comments
monocongo
·
3Comments
 robertnishihara
·
3Comments
robertnishihara
·
3Comments
 austinmw
·
3Comments
austinmw
·
3Comments
Most helpful comment
RLlib records the episode lengths in a separate seq_lens tensor, and
automatically adds the time dimension based on the sequence lengths prior
to passing the data to the LSTM.
On Fri, Jan 31, 2020, 1:17 AM LucCADORET notifications@github.com wrote: