Aim: Able to track change in performance of our ML algorithms across multiple datasets.
Assumptions:
- This is only applicable to PRs which can affect the model performance.
- By model performance we mean the accuracy of the model, irrespective of the metric used.
- We only measure performance for NLU models right now.
Proposal:
Any PR which affects the model performance in our algorithms should be tested for performance on multiple datasets before merging them into master.
- We test a predefined set of configurations on a few identified datasets.
- This test is run as Github actions inside the PR of the proposed change.
- The author can trigger the test by one of(proposed options, left to the implementor to pick whichever is the easiest.) -
- Posting a comment in the PR. Can be a two step comment, where the first comment is to trigger another comment which is like a configuration selector(resembling the screenshot below).
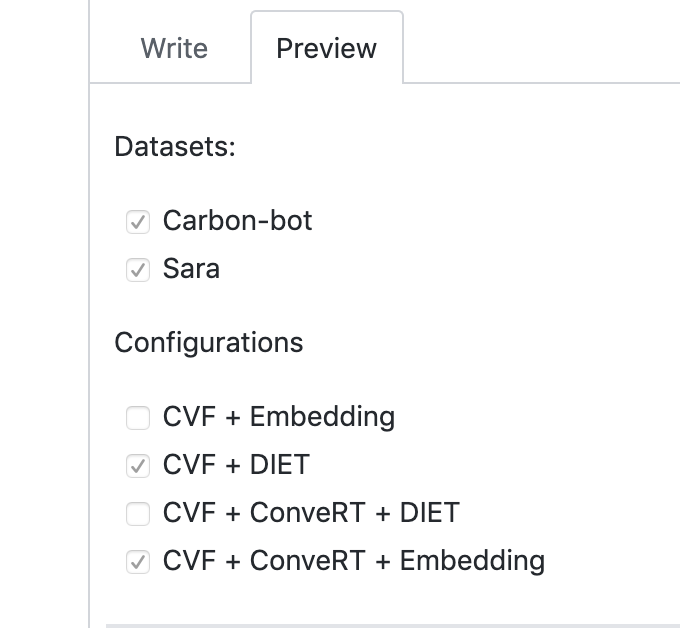
Add multiple labels to the PR where each label corresponds either to a unique dataset or a configuration.
- Author of the PR adds a meta configuration file which declares which datasets and configurations should be tested. This file is not merged into the target branch.
Since every PR may not affect performance on all datasets across all configurations, the author of the PR should be able to select which set of configurations and datasets should be tested.
- Can be run in CPU(Github provided runners) or GPU(gcloud hosted runner) mode.
- The results are posted as a comment in the PR.
- The author and reviewer of the PR decide if the regression(if any) is acceptable.
- We should also run a weekly test build of the master branch which is scheduled to run every Saturday -
- Can be done by scheduling GH as mentioned here
- This build should test all configurations and datasets.
- Results of these builds should be recorded in a central place, for example - Segment.
Where do the datasets and configurations reside?
- Datasets will be part of the internal training data repo. Predefined train/test splits will be available.
- All configurations applicable on that dataset will be available as a sub-folder inside the folder of that dataset.
 dakshvar22
dakshvar22
All 10 comments
@wochinge @tczekajlo Assigned you folks so that you can track the issue in the next sprint. Please feel free to re-assign as the squad decides.
dakshvar22
on 15 May 2020
@tczekajlo I put it to the backlog. Please bring it up when plan the sprint on Monday in case you have capacity and wanna handle this one.
 wochinge
on 15 May 2020
wochinge
on 15 May 2020
@dakshvar22 Can you put here a summary of our call from last week if you have a minute? Which information from results are relevant, where I can find them, exceptions, and so on.
Thanks in advance! :)
 tczekajlo
on 25 May 2020
tczekajlo
on 25 May 2020
Sure! As we discussed, we would run rasa train and rasa test on individual train-test splits with the predefined configurations. The results that are relevant from rasa test are as follows -
Intent prediction scores are always available in a file intent_report.json. The relevant keys are - accuracy, macro avg and weighted avg. For macro avg and weighted avg we need to extract precision,recall and f1-score. Sample relevant section from the file -
....
"accuracy": 0.974757281553398,
"macro avg": {
"precision": 0.9665627429559319,
"recall": 0.9455026455026454,
"f1-score": 0.9508581412205658,
"support": 515
},
"weighted avg": {
"precision": 0.9783462419465906,
"recall": 0.974757281553398,
"f1-score": 0.973715281816813,
"support": 515
}
...
Entity prediction scores are available in either CRFEntityExtractor_report.json or DIETClassifier_report.json(whichever exists in the report folder). The relevant keys are - micro avg, macro avg and weighted avg. For all three, we need to extract precision,recall and f1-score.
...
"micro avg": {
"precision": 0.839851024208566,
"recall": 0.8606870229007634,
"f1-score": 0.8501413760603204,
"support": 524
},
"macro avg": {
"precision": 0.7677268276733015,
"recall": 0.7453114393561578,
"f1-score": 0.7238996935417682,
"support": 524
},
"weighted avg": {
"precision": 0.8539698344512735,
"recall": 0.8606870229007634,
"f1-score": 0.8455616151330498,
"support": 524
}
...
Response Selection scores are always available in a file response_selection_report.json. The relevant keys are - accuracy, macro avg and weighted avg. For macro avg and weighted avg we need to extract precision,recall and f1-score.
...
"accuracy": 0.7284768211920529,
"macro avg": {
"precision": 0.5284053395164506,
"recall": 0.5665784832451499,
"f1-score": 0.5252984412510644,
"support": 151
},
"weighted avg": {
"precision": 0.6249416514317178,
"recall": 0.7284768211920529,
"f1-score": 0.6540384226204917,
"support": 151
}
...
Let me know if you need any more information.
dakshvar22
on 25 May 2020
@dakshvar22 regarding datasets to use, after seeing this forum thread we should really make sure that the datasets don't just cover multiple languages, but also all Rasa Open Source features.
 amn41
on 27 May 2020
amn41
on 27 May 2020
@dakshvar22 I've put all pieces together and here is result :)
In the #5866 you can find everything related to tests. Let's have a call tomorrow to discuss if you wanna change something and stuff like that.
tczekajlo
on 27 May 2020
@tczekajlo Discussion notes and observations in this sheet https://docs.google.com/spreadsheets/d/18NrGV0KNIUKTLovyz6eLJ0Jj_jnxB7zjkoFPGRu9tVI/edit?usp=sharing
dakshvar22
on 2 Jun 2020
@tczekajlo Summary of our call and next steps:
- Displaying the help message every time we add the required labels.
- Constructing a syntax for having a shortcut command to run the complete matrix.
- Changing the help message to reflect (2)
- Updating the notion page about where the configurations and mappings between configurations and datasets are being pulled from.
- Change the field for event in Metabase.
- Before merge, lets clean up the existing events in segment(related to model regression tests only ofcourse 😄 )
- Make names of columns in report table consistent -
Intent Classification Micro F1,Entity Recognition Micro F1,Response Selection Micro F1.
dakshvar22
on 17 Jun 2020
All changes from the previous comment are ready to review in the PR #5866.
tczekajlo
on 26 Jun 2020
@dakshvar22 👋 What is the current status? Is there something critical to fix/improve or we can move forward?
tczekajlo
on 30 Jun 2020
Related issues
 connorbrinton
·
3Comments
connorbrinton
·
3Comments
 lomarceau
·
3Comments
lomarceau
·
3Comments
 nicolasfarina
·
3Comments
nicolasfarina
·
3Comments
 johnson7788
·
3Comments
johnson7788
·
3Comments
 alonsopg
·
3Comments
alonsopg
·
3Comments