Rasa: Alphanumeric slot & entity extraction
Rasa NLU version:0.8.5
Operating system (windows, osx, ...):10
Content of model configuration file:
Issue: How can we add a slot / entity for any random alphanumeric text like ABC21232244 , INC324344 etc in our rasa core agent so that if a user input's the mentioned alphanumeric string in middle of a sentence bot extracts the value and provide it seperately.
 NikhilBansal21
NikhilBansal21
All 28 comments
@NikhilBansal21 have you read over the docs for regex patterns? They get close to what you are after, though it's important that they aren't just regex matchers. Rather the regex is used as a feature ni training the CRF for entity extraction.
https://nlu.rasa.com/dataformat.html#regular-expression-features
 wrathagom
on 20 Apr 2018
wrathagom
on 20 Apr 2018
can you maybe provide us with your nlu training data for this? and also your domain file of slots/entites if possible
 akelad
on 24 Apr 2018
akelad
on 24 Apr 2018
@wrathagom i have followed the link you mentioned and updated that to my traning data but that was not working. Something is not setting right on my side it's all new for me maybe you guys can help me with that. I am sending you the training data + domain file
{
"rasa_nlu_data":{
"common_examples":[
{
"intent":"AdditionalInfoTicket",
"entities":[
],
"text":"Add comment"
},
{
"intent":"CreateNewTicket",
"entities":[
],
"text":"new incident"
},
{
"intent":"Default Welcome Intent - custom",
"entities":[
],
"text":"how are you?"
},
{
"intent":"Default Welcome Intent - yes",
"entities":[
{
"entity":"email",
"value":"[email protected]",
"start":25,
"end":36
}
],
"text":"my registered id will be [email protected]"
},
{
"intent":"Default Welcome Intent",
"entities":[
],
"text":"hola"
},
{
"intent":"EndingStep",
"entities":[
],
"text":"exit"
},
{
"intent":"helpIntent",
"entities":[
],
"text":"help"
},
{
"intent":"helpIntent",
"entities":[
],
"text":"please help"
},
{
"intent":"ITProblemReport - no",
"entities":[
],
"text":"no"
},
{
"intent":"ITProblemReport - yes",
"entities":[
],
"text":"yes, i want to report that my system stopped working"
},
{
"intent":"ITProblemReport",
"entities":[
],
"text":"I want to report an IT problem"
},
{
"intent":"ITProblemReport",
"entities":[
],
"text":"i want to report an issue to IT"
},
{
"intent":"ITProblemReport",
"entities":[
],
"text":"report a problem to IT"
},
{
"intent":"ITProblemReport",
"entities":[
],
"text":"reporting a problem"
},
{
"intent":"ITProblemReport",
"entities":[
],
"text":"reporting an issue"
},
{
"intent":"SelectedTicket - no",
"entities":[
],
"text":"I dont have an incident id"
},
{
"intent":"SelectedTicket - no",
"entities":[
],
"text":"what incident id?"
},
{
"intent":"SelectedTicket - no",
"entities":[
],
"text":"i dont know the incident id"
},
{
"intent":"SelectedTicketStatus",
"entities":[
{
"entity":"IncidentID",
"value":"SR12354566",
"start":39,
"end":49
}
],
"text":"please view my ticket with incident id SR12354566"
},
{
"intent":"SelectedTicket",
"entities":[
],
"text":"my incident detail please"
},
{
"intent":"ShowTickets",
"entities":[
],
"text":"show my tickets asap"
},
{
"intent":"TicketDescription",
"entities":[
],
"text":"yes i rebooted it"
},
{
"intent":"TicketSummary",
"entities":[
],
"text":"my mouse is not"
},
{
"intent":"TicketSummary",
"entities":[
],
"text":"my system's monitor working"
},
{
"intent":"UrgencyIncidentTicket",
"entities":[
],
"text":"set urgency of incident"
}
],
"regex_features":[
{
"name":"IncidentID" "pattern":"(?i)(sr)[0-9]*"
}
],
"entity_synonyms":[
{
"value":"incidentID",
"synonyms":[
"SR01089784",
]
}
]
}
}
domain file :-
slots:
email:
type: text
IncidentID:
type: text
intents:
- Default Welcome Intent
- Default Welcome Intent - yes
- ShowTickets
- SelectedTicket
- CreateNewTicket
- SelectedTicketStatus
- helpIntent
- EndingStep
- TicketSummary
- TicketDescription
entities:
- IncidentID
templates:
utter_ask_email:
- 'Please provide with a valid email id!'
actions:
- utter_ask_email
- actions.ActionWelcome
- actions.ActionGoodbye
- actions.Help
- actions.ActionHelp
- actions.ActionShowAllTickets
- actions.ActionSingleTicket
- actions.ActionCreateTicket
- actions.ActionTicketSummary
- actions.ActionTicketsDesc
- actions.ActionSingleTicketStatus
NikhilBansal21
on 24 Apr 2018
@NikhilBansal21 is that your complete training data or just a snippet of it? I see multiple JSON errors, which is why I am asking.
What are you trying to get from the entity_synonyms entry you have? as it exists right not it would replace the ID SR01089784 with the text IncidentID then that text would be passed to the core slot, which I don't think is what you want. I would recommend removing it entirely.
Also as a general comment, you are providing only a single training example for the incident ID. One example is not enough for the model to learn the behavior. You should provide at least 5-10 examples, maybe even more would be needed for good understanding.
wrathagom
on 25 Apr 2018
@wrathagom yes i edited my training data to make it short and simple to understand if you want i can send whole training data again.
Secondly entity_synonyms has nothing to do with me i didn't create it- i followed your advise and removed it from my training data.
The issue is i cannot figure out how come still incidentID slot is not picking up the ID SR01089784 from user phrase.
NikhilBansal21
on 26 Apr 2018
this is super hard to read, could you post it as a gist where it's properly formatted as well? as far as i can see though you have at least one "negative" example where the ID isn't labeled as an entity? this definitely shouldn't be the case.
akelad
on 26 Apr 2018
@akelad hope this helps https://gist.github.com/NikhilBansal21/03481cf181abe73622f03ec1d2b13ea2
NikhilBansal21
on 26 Apr 2018
that link is broken
akelad
on 1 May 2018
have you tried copy and paste the url?
NikhilBansal21
on 1 May 2018
try added a regex matching your possible numbers to the regex_features. Also you'll probably need more than just 15 entity examples
akelad
on 1 May 2018
@akelad what kind of possible numbers you are talking can you please tell are you talking about alphanumeric string pattern like this
"regex_features":[
{
"name":"IncidentID" "pattern":"(?i)(sr)[0-9]*"
}
],
and how many minimum number entity examples does rasa core requires ?
NikhilBansal21
on 1 May 2018
yes this is what i mean, but i assume your id number has a limited amount of numbers, so i'd specify that instead of just saying any amount of numbers.
i'd say maybe around 50 for that. Or try doubling it at least. And include the regex features and see how that helps.
akelad
on 3 May 2018
@NikhilBansal21 where you able to improve your model performance with regex?
wrathagom
on 4 May 2018
@wrathagom i didn't understand what are you trying to say can you please elaborate?
NikhilBansal21
on 4 May 2018
@akelad hi the solution worked pefectly. But i am getting the extracted text in small caps
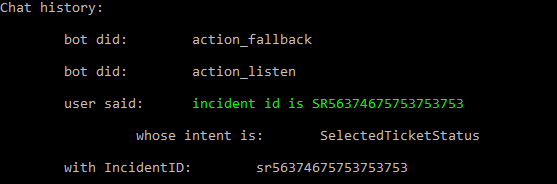
.
NikhilBansal21
on 7 May 2018
Is that a huge problem?
akelad
on 8 May 2018
@akelad yes it is because i have to pass this value in an api i know i can do workaround for this at my code side also but it will be better that the entered value should be directly passed to the api.
NikhilBansal21
on 8 May 2018
In that case would you not always need to make a check though? Because the user could enter it lowercased as well
akelad
on 14 May 2018
@akelad hi i am facing this issue again the issue is when passing an alphanumeric string i.e SR01134974 slot does not takes the value but if i enter like "my incident id is SR01134974" then slots takes up the alphanumeric value. Like you said i added like 30 entity values from dialogflow console and trained the agent with new nlu data but still i am facing this issue. It will be a great help to me as i am in a middle of my project in which rasa core bot is acting like a server & i have to make it stable for further use!
NikhilBansal21
on 5 Jun 2018
here is the updated gist for my training data file :-
https://gist.github.com/NikhilBansal21/03481cf181abe73622f03ec1d2b13ea2
NikhilBansal21
on 5 Jun 2018
I'm not sure why you still have a list of those strings in your synonyms. This just means those entities will be replaced with the word "incidentID" when they're extracted. Also have you added training examples of just the string? As in not in a sentence? If not, that's why it's not getting extracted.
akelad
on 6 Jun 2018
i worked this issue with single string also. But you are saying that a single alphanumeric string will not be picked up?? but not every time a user wants to type a whole sentence what will happen in that case? . Although now slot is picking up the single alphanumeric string now, i had to add alot of training phrases for that after that it started working fine.
NikhilBansal21
on 7 Jun 2018
@akelad there is one more thing the regex intent i added in the data set for the alphanumeric string is also taking email id format in the same intent. i have increased the training data for email id also. So do i have to provide regex pattern for email id also? or it is by default present in the rasa core like dialogflow contains a system generated entity for email id extraction??
NikhilBansal21
on 7 Jun 2018
This issue has been automatically marked as stale because it has not had recent activity. It will be closed if no further activity occurs. Thank you for your contributions.
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 5 Sep 2018
stale[bot]
on 5 Sep 2018
This issue has been automatically closed due to inactivity. Please create a new issue if you need more help.
stale[bot]
on 12 Sep 2018
@NikhilBansal21 were you successful in extracting the alphanumeric entity (eg. SR12354566) as uppercase instead of lowercase? The same thing happened to me.
 sagarigrandhi
on 18 Jan 2019
sagarigrandhi
on 18 Jan 2019
@Nisag @NikhilBansal21 were you two successful in converting it to uppercase? I am also facing same problem.
 priyankurs
on 6 Apr 2019
priyankurs
on 6 Apr 2019
Related issues
 edouardlp
·
3Comments
edouardlp
·
3Comments
 jahid-ict
·
3Comments
jahid-ict
·
3Comments
 rayush7
·
3Comments
rayush7
·
3Comments
 yondu22
·
3Comments
yondu22
·
3Comments
 connorbrinton
·
3Comments
connorbrinton
·
3Comments
Most helpful comment
In that case would you not always need to make a check though? Because the user could enter it lowercased as well