Rancher: Rancher Cattle Cluster Agent Could not Resolve Host
What kind of request is this (question/bug/enhancement/feature request): bug
Steps to reproduce (least amount of steps as possible):
Provision new HA cluster using RKE. The cluster.yml file should only have the nodes stanza. 3 nodes with all roles assigned. Delete one of the 3 rancher pods.
root@massimo-server:~# kubectl delete pod/rancher-6dc68bb996-95rbw -n cattle-system
Result:
The rancher pod is recreated due to the ReplicaSet but the cattle cluster agent fails and goes into CrashLoopBackOff state.
root@massimo-server:~# kubectl logs --follow \
pod/cattle-cluster-agent-7bcbf99f56-vdrbs -n cattle-system
INFO: Environment: CATTLE_ADDRESS=10.42.1.5 CATTLE_CA_CHECKSUM= CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-7bcbf99f56-vdrbs CATTLE_SERVER=https://massimo.rnchr.nl
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5
ERROR: https://massimo.rnchr.nl/ping is not accessible (Could not resolve host: massimo.rnchr.nl)
Using curl from outside of the cattle agent pod
root@massimo-server:~# curl https://massimo.rnchr.nl/ping
pong
Environment information
- Rancher version (
rancher/rancher/rancher/serverimage tag or shown bottom left in the UI):
rancher/rancher v2.1.1 - Installation option (single install/HA): HA
Cluster information
- Cluster type (Hosted/Infrastructure Provider/Custom/Imported): RKE provisioned
- Machine type (cloud/VM/metal) and specifications (CPU/memory): cloud, 2 CPU/4 GB
- Kubernetes version (use
kubectl version):
Client Version: version.Info{Major:"1", Minor:"12", GitVersion:"v1.12.2", GitCommit:"17c77c7898218073f14c8d573582e8d2313dc740", GitTreeState:"clean", BuildDate:"2018-10-24T06:54:59Z", GoVersion:"go1.10.4", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"11", GitVersion:"v1.11.3", GitCommit:"a4529464e4629c21224b3d52edfe0ea91b072862", GitTreeState:"clean", BuildDate:"2018-09-09T17:53:03Z", GoVersion:"go1.10.3", Compiler:"gc", Platform:"linux/amd64"}
- Docker (use
docker info):
Containers: 1
Running: 1
Paused: 0
Stopped: 0
Images: 1
Server Version: 17.03.2-ce
Storage Driver: aufs
Root Dir: /var/lib/docker/aufs
Backing Filesystem: extfs
Dirs: 5
Dirperm1 Supported: true
Logging Driver: json-file
Cgroup Driver: cgroupfs
Plugins:
Volume: local
Network: bridge host macvlan null overlay
Swarm: inactive
Runtimes: runc
Default Runtime: runc
Init Binary: docker-init
containerd version: 4ab9917febca54791c5f071a9d1f404867857fcc
runc version: 54296cf40ad8143b62dbcaa1d90e520a2136ddfe
init version: 949e6fa
Security Options:
apparmor
seccomp
Profile: default
Kernel Version: 4.4.0-138-generic
Operating System: Ubuntu 16.04.5 LTS
OSType: linux
Architecture: x86_64
CPUs: 2
Total Memory: 3.859 GiB
Name: massimo-server
ID: 747D:4N33:DFHF:IWOG:Z3RK:G22I:3663:ZSHQ:5HKF:SOGK:M3V4:EKQA
Docker Root Dir: /var/lib/docker
Debug Mode (client): false
Debug Mode (server): false
Registry: https://index.docker.io/v1/
Experimental: false
Insecure Registries:
127.0.0.0/8
Live Restore Enabled: false
WARNING: No swap limit support
gz#11051
 ghost
ghost
All 93 comments
Deleting the cattle cluster agent pod, fixes it. Why is the cattle cluster agent having issues resolving the host when a rancher pod is recreated?
ghost
on 5 Nov 2018
Here is the yaml file used to provision the cluster. All of the hosts are running Ubuntu 16.04 and using Docker 17.03.2-ce.
root@massimo-server:~# cat cluster.yml
nodes:
- address: 167.99.165.9
user: root
role:
- controlplane
- worker
- etcd
- address: 142.93.80.121
user: root
role:
- controlplane
- worker
- etcd
- address: 142.93.82.153
user: root
role:
- controlplane
- worker
- etcd
Helm was used with an already existing Let's Encrypt SSL cert.
helm install rancher-stable/rancher \
--name rancher \
--namespace cattle-system \
--set hostname=massimo.rnchr.nl \
--set ingress.tls.source=secret
root@massimo-server:~# kubectl -n cattle-system create secret tls tls-rancher-ingress \
--cert=fullchain.pem --key=privkey.pem
I had exactly the same issue with Ubuntu server 18.04 LTS and docker 18.06.1-ce. Cluster was created with rke. Deleting and recreating the cattle-cluster-agent pod did not help.
I set the CATTLE_SERVER env of cattle-cluster-agent to the configured rancher ingress service, so kube-dns can resolve it: rancher.cattle-system.svc.cluster.local or <service>.<namespace>.<cluster>
Afterwards the pod started, but I don't know if this is correct. Normally you would go over external LB? But in my case this did not work because my cluster dns domain overlaps with dns domain outside in real network...
 execthis
on 15 Dec 2018
execthis
on 15 Dec 2018
I have the same issue with rancher deployed on top of EKS (deployed with helm). During the import ui showed me this error failed with "waiting for server-url setting to be set" (https://github.com/rancher/rancher/issues/12350) but at the end cluster is (somehow) properly operational.
 dawidmalina
on 15 Jan 2019
dawidmalina
on 15 Jan 2019
I have the same issue on some clusters while others work perfectly fine while they are set up exactly the same and they are using the same rancher2 server. The server is located on external servers using a normal, official domain name (google's 8.8.8.8 resolves it for example). cattle-cluster-agent can still not resolve the hostname, while the cluster internal kube-dns can resolve it without problems, as well as the host system. When I switch dnsPolicy to "None" and manually add an external dns like this - everything works fine:
dnsPolicy: "None"
dnsConfig:
nameservers:
- 8.8.8.8
- 8.8.4.4
I've also noticed, that Events shows (no matter if it's working or not) Scaled down replica set cattle-cluster-agent-128cfc8df7 to 0 although state is "running" and I can execute a shell in the docker. So it's not scaled to 0.
 proligde
on 31 Jan 2019
proligde
on 31 Jan 2019
I had the same issue when the br_netfilter was not loaded. This caused some nat rules not to work, so the DNS clients where asking to the kube-dns cluster IP but got a response from the service IP which was rejected.
"modprobe br_netfilter" solved it for me.
 micw
on 24 Feb 2019
micw
on 24 Feb 2019
I have been having this issue as well. I think I have solved why this issue is happening and have found two temporary fixes for it. The real solution will be for rancher to change their deployment logic or to not specify a default cluster domain name.
This issue, at least for me has been being caused by specifying a domain in the rke config file like:
services:
kubelet:
cluster_domain: mycluster.com
The problem to the fact that the cattle-cluster-agent pod is querying kube-dns to resolve the name to your rancher cluster (let us say it is rancher.mycluster.com). Kube-dns does not have an entry for rancher.mycluster.com, and thanks to the cluster_domain specification in the RKE config file, believes it is authoritative for mycluster.com and answers cattle-cluster-agent that there are no records for that name. This causes the cattle-cluster-agent pod to bootloop and fail.
To fix this you can change the yml for cattle-cluster-agent and either edit the dnspolicy or the value the CATTLE_SERVER variable provides to the pod.
dnspolicy
If you change the dnspolicy to Default from ClusterFirst this will cause the pod to go to external dns servers (not kube-dns) for name resolution. This makes resolution of rancher.mycluster.com work, however this will break attempts by the cattle-cluster-agent pod to contact other pods (I do not know if it needs to do so)
CATTLE_SERVER
The other fix for this is to edit the yml entry for CATTLE_SERVER and change the value from https://rancher.mycluster.com to https://rancher. This make the pod send a request to kube-dns for resolution of "rancher" which it does have an entry for, as that is the pod name which is inserted into kube-dns thanks to the magic of kubernetes, resulting in a working pod.
Long term rancher should probably make the second fix presented here the default value for CATTLE_SERVER when it comes up by default. That should prevent this issue from occurring.
 scotthesterberg
on 7 Mar 2019
scotthesterberg
on 7 Mar 2019
@scotthesterberg That's greet.Would you tell us nginx.conf and conf.d/rancher.conf ?
 armanriazi
on 17 Mar 2019
armanriazi
on 17 Mar 2019
@armanriazi I am afraid I do not know where to locate conf.d/rancher.conf. Should is ve in a container (which)? Or on the host os? What are we trying to find?
scotthesterberg
on 17 Mar 2019
@scotthesterberg Well,you can configure nginx two way Host and Container that there isn't any diff.
I have question: How you configure LB kind of autogenerate so I dont't know what is this link(manual config)?
https://rancher.com/docs/rancher/v2.x/en/installation/ha/rke-add-on/layer-4-lb/#2-configure-load-balancer
armanriazi
on 18 Mar 2019
I solved value of server-url/v3/settings/cacerts and intermediate CA but I still getting this error (I saw issues similar but there was't full solver and I think it not granular nature system yet)
Thanks friends.
> INFO: Environment: CATTLE_ADDRESS=10.42.0.14 CATTLE_CA_CHECKSUM=f4400caeebc0e481b1edfa15e5ba19b9756bc132d0a9448dc82479b718f8cdc9 CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-88dbc897d-x9hp7 CATTLE_SERVER=https://rancher.nik.com CATTLE_SERVICE_PORT=tcp://10.43.131.37:80 CATTLE_SERVICE_PORT_443_TCP=tcp://10.43.131.37:443 CATTLE_SERVICE_PORT_443_TCP_ADDR=10.43.131.37 CATTLE_SERVICE_PORT_443_TCP_PORT=443 CATTLE_SERVICE_PORT_443_TCP_PROTO=tcp CATTLE_SERVICE_PORT_80_TCP=tcp://10.43.131.37:80 CATTLE_SERVICE_PORT_80_TCP_ADDR=10.43.131.37 CATTLE_SERVICE_PORT_80_TCP_PORT=80 CATTLE_SERVICE_PORT_80_TCP_PROTO=tcp CATTLE_SERVICE_SERVICE_HOST=10.43.131.37 CATTLE_SERVICE_SERVICE_PORT=80 CATTLE_SERVICE_SERVICE_PORT_HTTP=80 CATTLE_SERVICE_SERVICE_PORT_HTTPS=443
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5
**error : ERROR: https://rancher.nik.com/ping is not accessible** (Could not resolve host:)
error : ERROR: https://rancher.nik.com/ping is not accessible
I have tried to solve every solution but it dosn't work
solutions:
- Change cluster_domain
- Solved /etc/resolv.conf on Host and agent containers with internal org DNS and 8.8.8.8
- Update to v2.1.7
- Flush docker containers
- Change server_url to https://rancher and https://rancher.server.com
- Configure LB 4 and LB7 with different mode/solutions
- Solved CA private with intermedate CA
- Load modules modprobe br_netfilter
- Make sure fill https://rancher.nikafarinegan.ir/v3/settings/cacerts
- Allow Privilege Escalation to true on security policy restricted
- Configure authorization with none and rbac
"(Maybe there is different between pause:number version image -base on rancher with pause:v number image-amd64)"
Common configurations such as
docker 17.3.2
rke 0.1.17
kubectl 1.12.5
firewall disable on 3 nodes
target rancher HA with private images
ubuntu1604 (at least I've heard it's lack of systemd resolver dns 'systemd-resolved(ubuntu1804)' )
replace that systemd-resolved I used
https://pchelp.ricmedia.com/set-custom-dns-servers-linux-network-manager-resolv-conf/
when i ran this command
kubectl -n kube-system get pods -l k8s-app=kube-dns --no-headers -o custom-columns=NAME:.metadata.name,HOSTIP:.status.hostIP | while read pod host; do echo "Pod ${pod} on host ${host}"; kubectl -n kube-system exec $pod -c kubedns cat /etc/resolv.conf; done
It shows
nameserver nik.com
nameserver 8.8.8.8
nameserver 8.8.4.4tested before that is not related to current configured up
nameserver 172.18.3.70
nameserver 8.8.8.8
nameserver 8.8.4.4
and
nameserver 8.8.8.8
nameserver 8.8.4.4
nameserver 1.1.1.1
export DOMAIN=www.google.com; echo "=> Start DNS resolve test"; kubectl get pods -l name=dnstest --no-headers -o custom-columns=NAME:.metadata.name,HOSTIP:.status.hostIP | while read pod host; do kubectl exec $pod -- /bin/sh -c "nslookup $DOMAIN > /dev/null 2>&1"; RC=$?; if [ $RC -ne 0 ]; then echo $host cannot resolve $DOMAIN; fi; done; echo "=> End DNS resolve test"
=> Start DNS resolve test
=> End DNS resolve test
armanriazi
on 18 Mar 2019
Can I replace cattle pods ,deploy with adding manual Docker Swarm?
armanriazi
on 18 Mar 2019
Dear @armanriazi, did you find the solution for it?
I have the same problem.
 gatici
on 25 Mar 2019
gatici
on 25 Mar 2019
@gatici I am going to wait for new releases then change OS to 1804 and using kube V13 finally I thought I might have to use Tk8
armanriazi
on 6 Apr 2019
I'm having the same issue
 ryudice
on 13 May 2019
ryudice
on 13 May 2019
I'm having the same issue
 yangrubing
on 21 May 2019
yangrubing
on 21 May 2019
same issue
ubuntu: 18.04
docker: 18.09.6
 EvgenyKhaliper
on 24 Jun 2019
EvgenyKhaliper
on 24 Jun 2019
same issue
ubuntu: 18.04
docker: 18.9.7
 dbwest
on 30 Jun 2019
dbwest
on 30 Jun 2019
Same issue here:
ubuntu: 18.04
Docker version 18.09.7, build 2d0083d
This happens for me on 2 different machines when provisioning a new custom cluster through the Rancher UI with the long Docker install command.
 ironsalsa
on 18 Jul 2019
ironsalsa
on 18 Jul 2019
same issue
redhat 8
docker-ce-3:18.09.1-3.el7.x86_64
 ezequielarevalo-natgeo
on 1 Aug 2019
ezequielarevalo-natgeo
on 1 Aug 2019
having the same issue on RancherOS.
EDIT: Setting the CATTLE_SERVER to rancher fixes an issue <3 I had previously rancher.docker.zz and the DNS were correctly set up.
Love you @scotthesterberg :D No homo but really thanks for that! I tried to set up the cluster for a WEEK. Even after the full restart, the agent works which was a big issue for me.
GIVE HIM SOME MILK!
EDIT:
Now I have another problem:
ERROR: The environment variable CATTLE_CA_CHECKSUM is set but there is no CA certificate configured at rancher/v3/settings/cacerts
Reaching the endpoint shows the certificate there so I'm lost right now.
EDIT2:
Inside the container the command curl --insecure -s -fL $CATTLE_SERVER/v3/settings/cacerts returns empty string.
EDIT3:
I added the entry manually in config-maps/kube-system:coredns like follow:
docker.zz:53 {
errors
cache 30
forward . <ip of dns where docker.zz is stored>
}
Then change in first EDIT I reverted but looks like Rancher uses ingress.local certificate for outsite connections too.
 TheAifam5
on 2 Aug 2019
TheAifam5
on 2 Aug 2019
Glad it at least partly worked for you @TheAifam5! Always good to hear a post helps someone.
scotthesterberg
on 5 Aug 2019
same issue here:
I did manage to get it working by changing CATTLE_SERVER to another domain which I can resolve to the same rancher IP on my DNS server, don't know what the implications are though
EDIT:
cattle-cluster-agent is up but still getting some error logs (looking for the "correct" fqdn)
time="2019-08-08T18:11:03Z" level=info msg="Connecting to proxy" url="wss://rancher.xxx.xxx.xxxxxxxx.com/v3/connect/register"
time="2019-08-08T18:11:03Z" level=error msg="Failed to connect to proxy" error="dial tcp: lookup rancher.xxx.xxx.xxxxxxxx.com on 10.254.0.10:53: no such host"
time="2019-08-08T18:11:03Z" level=error msg="Failed to connect to proxy" error="dial tcp: lookup rancher.xxx.xxx.xxx.com on 10.254.0.10:53: no such host"
The issue seems to be having rancher on the same subdomain as the cluster, dns query dont fallback to other dns server after failing on kube-dns (10.254.0.10:53 in this case)
 ajboni
on 8 Aug 2019
ajboni
on 8 Aug 2019
I also have run into this issue after performing a restore from etcd snapshot. For me, cattle-cluster-agent is fine during cluster initialization, but after restoring from etcd snapshot, the cattle-cluster-agent will not be able to resolve the hostname.
It's a bit confusing because I am unsure how it was able to do so during cluster initialization. It is as if the agent uses Default dnsPolicy during cluster initialization but then afterward, if it is ever rebooted, it resorts to the default configuration of ClusterFirst dnsPolicy.
As a workaround, I edit the cattle-cluster-agent workload after initializing such that my dns nameservers are configured (could also just set dnsPolicy to Default)
Would be nice to see this as a possible configuration when configuring cluster at initialization.
 zbialik
on 16 Oct 2019
zbialik
on 16 Oct 2019
I changed dnsPolicy from clusterFirst to Default however, the pod still fails
INFO: Environment: CATTLE_ADDRESS=10.42.0.44 CATTLE_CA_CHECKSUM= CATTLE_CLUSTER=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-684f88c44c-j5xfr CATTLE_SERVER=https://rancher.mycompany.dev
INFO: Using resolv.conf: nameserver 213.133.100.100 nameserver 213.133.99.99 nameserver 213.133.98.98 search localdomain default.svc.cluster.local svc.cluster.local cluster.local
ERROR: https://rancher.mycompany.dev/ping is not accessible (Could not resolve host: rancher.mycompany.dev)
 papanito
on 21 Oct 2019
papanito
on 21 Oct 2019
It looks like when using Debian 10 it may be a problem with iptables. I followed this which solved the problem for me.
papanito
on 21 Oct 2019
For me, changing the CATTLE_SERVER solves at first, but other places seem to point to the same address inside the pod.
I fixed it by adding a host alias (/etc/hosts entries) to point to the internal IP address for both cattle-cluster-agent and cattle-node-agent.
Looks like rancher should have an internal IP setting that it should use for this. In AWS, this causes additional cost unnecessarily.
 nvivo
on 31 Oct 2019
nvivo
on 31 Oct 2019
@zbialik
It magically worked for me as well after changing dnsPolicy to Default, instead of ClusterFirst.
Thanks!
 presidenten
on 16 Nov 2019
presidenten
on 16 Nov 2019
Is there any fix for this at a higher level? Now the DigitalOcean Kubernetes distribution has this issue which I ran into on my local cluster, and my cluster is unable to check in to Rancher. For my local nodes I can just mess with the networking, but on managed providers I'm out of luck.
ironsalsa
on 28 Nov 2019
This is still an issue: https://github.com/rancher/rancher/issues/24311
 mariusstaicu
on 3 Dec 2019
mariusstaicu
on 3 Dec 2019
same problem
I found that the real reason is that my coredns didn't start up, none nodes matched the node selector...
 ryan4yin
on 31 Dec 2019
ryan4yin
on 31 Dec 2019
I also have run into this issue after performing a restore from etcd snapshot. For me, cattle-cluster-agent is fine during cluster initialization, but after restoring from etcd snapshot, the cattle-cluster-agent will not be able to resolve the hostname.
It's a bit confusing because I am unsure how it was able to do so during cluster initialization. It is as if the agent uses
DefaultdnsPolicy during cluster initialization but then afterward, if it is ever rebooted, it resorts to the default configuration ofClusterFirstdnsPolicy.As a workaround, I edit the cattle-cluster-agent workload after initializing such that my dns nameservers are configured (could also just set dnsPolicy to
Default)Would be nice to see this as a possible configuration when configuring cluster at initialization.
works for me, thanks much~
ryan4yin
on 31 Dec 2019
This ended up being DNS for me as well - the cattle-cluster-agent was constantly rebooting and not allowing for items like ingress to work properly. I had tried the dnsPolicy setting as suggested, tried putting in entries in the hosts file, tried variations on the host OS, Kubernetes version, and Rancher version, all to no avail.
What did work was setting up DNS "properly." Using the "roll your own / Custom" option in the Rancher Cluster Creation, not specifying any additional settings (such as private /public addresses), on a greenfield Ubuntu 18.04 setup (with both ipv4 and ipv6 addresses) / Rancher 2.3.3 / Kubernetes 1.16, I started by setting a DNS 'search' setting (in the netplan yaml, ethernets/eth0/nameservers/search) for all of the boxes in the mix. I then stood up an internal DNS server with a DNS zone to match, and then ensured that all of the boxes had host (A/AAAA) entries for both IPv4 and IPv6. With that in place, everything magically started working. Did NOT adjust the dnsPolicy setting in the end.
 DiApostola
on 2 Jan 2020
DiApostola
on 2 Jan 2020
We are having this issue too after an upgrade to k8s 1.16.4
Our _seemingly to work_ workaround was to setup a hostalias:
hostAliases:
- ip: "xx.xx.xx.xx"
hostnames:
- "my.host.name"
 torras
on 21 Jan 2020
torras
on 21 Jan 2020
Still experiencing this.
Impossible to add new custom nodes to a newly created cluster when it's happening obviously. Occurred in two different attempts at provisioning nodes on Rancher clusters. Glad I found this thread!
Overriding host entries via hostAliases for cattle-node-agent and cattle-cluster-agent brought them to life.
 hibouambigu
on 13 Feb 2020
hibouambigu
on 13 Feb 2020
Still same thing on the latest rancher, rke, rancheros....
cattle-node-agent works after setting the hostAliases, but cattle-cluster-agent still crashing even has the hostAliases set.
That's starts to be so annoying.
TheAifam5
on 24 Feb 2020
Hi
Having the same issue on a CentOS Linux release 7.7.1908 (Core). Nameserver in the cattle-cluster-agent is set to nameserver 10.43.0.10 when using the ClusterFirst.
Kernel version: 3.10.0-1062.9.1.el7.x86_64
RKE version: v1.0.4
Rancher version: v2.3.5
Kubernetes version:
Server Version: version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.3", GitCommit:"06ad960bfd03b39c8310aaf92d1e7c12ce618213", GitTreeState:"clean", BuildDate:"2020-02-11T18:07:13Z", GoVersion:"go1.13.6", Compiler:"gc", Platform:"linux/amd64"}
Docker version:
Client: Docker Engine - Community
Version: 19.03.5
API version: 1.40
Go version: go1.12.12
Git commit: 633a0ea
Built: Wed Nov 13 07:25:41 2019
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.5
API version: 1.40 (minimum version 1.12)
Go version: go1.12.12
Git commit: 633a0ea
Built: Wed Nov 13 07:24:18 2019
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.2.10
GitCommit: b34a5c8af56e510852c35414db4c1f4fa6172339
runc:
Version: 1.0.0-rc8+dev
GitCommit: 3e425f80a8c931f88e6d94a8c831b9d5aa481657
docker-init:
Version: 0.18.0
GitCommit: fec3683
Logs cattle-cluster-agent:
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5
ERROR: https://rancher-tooling/ping is not accessible (Could not resolve host: rancher-tooling)
Workaround
Changed the dnsPolicy from the cattle-cluster-agent deployment:
From:
dnsPolicy: ClusterFirst
To:
dnsPolicy: Default
Regards
Matthias
 matthiasdeblock
on 26 Feb 2020
matthiasdeblock
on 26 Feb 2020
On Debian 10, this issue is caused by the change from iptables to nftables.
This is resolved with:
update-alternatives --set iptables /usr/sbin/iptables-legacy
reboot
Regards
Jason
 JasonGantner
on 27 Feb 2020
JasonGantner
on 27 Feb 2020
yep, see https://github.com/rancher/rancher/issues/16454#issuecomment-544621587 ;-)
papanito
on 27 Feb 2020
This can happen also using the external and internal DNS.
extenal
ERROR: https://rancher.domain.com:443/ping is not accessible (Could not resolve host: rancher.domain.com)
internal
ERROR: https://cattle-system.svc.cluster.local:443/ping is not accessible (Could not resolve host: cattle-system.svc.cluster.local)
It also happen on my 2 different os Bottlerocket and AmazonLinux 2
NAME STATUS ROLES AGE VERSION INTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
ip-10-0-0-67.eu-west-1.compute.internal Ready <none> 39m v1.15.10 10.0.0.67 Bottlerocket OS 0.3.1 5.4.16 containerd://1.3.3+unknown
ip-10-0-10-161.eu-west-1.compute.internal Ready <none> 27h v1.15.10-eks-bac369 10.0.10.161 Amazon Linux 2 4.14.165-133.209.amzn2.x86_64 docker://18.9.9
docker & kubernetes version
Client Version: version.Info{Major:"1", Minor:"17", GitVersion:"v1.17.0", GitCommit:"70132b0f130acc0bed193d9ba59dd186f0e634cf", GitTreeState:"clean", BuildDate:"2019-12-07T21:20:10Z", GoVersion:"go1.13.4", Compiler:"gc", Platform:"linux/amd64"}
Server Version: version.Info{Major:"1", Minor:"15+", GitVersion:"v1.15.10-eks-bac369", GitCommit:"bac3690554985327ae4d13e42169e8b1c2f37226", GitTreeState:"clean", BuildDate:"2020-02-26T01:12:54Z", GoVersion:"go1.12.12", Compiler:"gc", Platform:"linux/amd64"
cattle-cluster-agent deployment
Name: cattle-cluster-agent
Namespace: cattle-system
CreationTimestamp: Mon, 16 Mar 2020 17:00:38 +0000
Labels: app=cattle-cluster-agent
Annotations: deployment.kubernetes.io/revision: 2
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"name":"cattle-cluster-agent","namespace":"cattle-system"},"spec"...
Selector: app=cattle-cluster-agent
Replicas: 1 desired | 1 updated | 1 total | 0 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=cattle-cluster-agent
Service Account: cattle
Containers:
cluster-register:
Image: rancher/rancher-agent:v2.3.5
Port: <none>
Host Port: <none>
Environment:
CATTLE_SERVER: https://cattle-system.svc.cluster.local:443
CATTLE_CA_CHECKSUM: b5b5eefc0bff6fc86164b9779b288f293e153ef77304531fc4728ecc823cc2a8
CATTLE_CLUSTER: true
CATTLE_K8S_MANAGED: true
Mounts:
/cattle-credentials from cattle-credentials (ro)
Volumes:
cattle-credentials:
Type: Secret (a volume populated by a Secret)
SecretName: cattle-credentials-5a098aa
Optional: false
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetAvailable
Available False MinimumReplicasUnavailable
OldReplicaSets: <none>
NewReplicaSet: cattle-cluster-agent-85f7d86f4f (1/1 replicas created)
Events: <none>
I have tested the @matthiasdeblock and it works, but I had to revert to the external DNS.
dnsPolicy: Default
Thanks!
 hugoprudente
on 16 Mar 2020
hugoprudente
on 16 Mar 2020
It's still there!
 jaggerwang
on 14 Apr 2020
jaggerwang
on 14 Apr 2020
same here on a sles15 sp1 with rke install.
 jehutyy
on 14 Apr 2020
jehutyy
on 14 Apr 2020
I can confirm it's on rancher 2.4.2 as well.
 shibumi
on 5 May 2020
shibumi
on 5 May 2020
I had this issue because I wanted to create _master_ node with controlplane + etcd only.
It seems that worker role is compulsory anyway.
So I've created _master_ node with the 3 roles and no more worries !
After I could create additional nodes with worker role only.
Then I tainted my master node to prevent new pods to be deployed on it.
I think Rancher should be more explicit about _roles_ requirements for RKE because it's an outstanding key feature but the UX is discutable for custom node creation.
 scndel
on 6 May 2020
scndel
on 6 May 2020
After open all ports to nodes in the same cluster, I fixed this problem, hope it helpful to some guys.
jaggerwang
on 6 May 2020
This happen to me when i add manually the cloudProvider to the cluster:
cloud_provider:
name: aws
But then i created a new cluster with the cloudProvider from rancher ui config, and add some labels to the cloud_provider:
cloud_provider:
awsCloudProvider:
global:
disable-security-group-ingress: false
disable-strict-zone-check: false
service_override: null
name: aws
And works without problems
 drog
on 17 May 2020
drog
on 17 May 2020
I ran into this issue when I used a pfsense firewall as a load balancer in front of my cluster. I was able to resolve it by changing my outbound NAT as recommended here in the pfsense docs:
https://docs.netgate.com/pfsense/en/latest/book/loadbalancing/troubleshooting-server-load-balancing.html#unable-to-reach-a-virtual-server-from-a-client-in-the-same-subnet-as-the-pool-server
Essentially the fact that my nodes were on the same subnet as my load balancer caused traffic to not route properly because of incorrect source and destination IPs. This led to the failure in deployment described in this issue even though I was able to use my cluster for the most part normally otherwise. It may not necessarily represent what others have seen here, but could be a potential item to look at for others.
Note: This change does result in you losing some information regarding what host traffic originates from in traffic that hits your load balancer. This was not important to me so I did not worry about that loss of information, but others may.
 velocity303
on 19 May 2020
velocity303
on 19 May 2020
Still there in v2.4.3 as well.
 vinothbellie
on 20 May 2020
vinothbellie
on 20 May 2020
Same issue.
I am using rancher v2.4.3 with latest RKE v1.2.0-rc1 and docker 19.03.9
 kz12123
on 25 May 2020
kz12123
on 25 May 2020
still here
 kubealex
on 13 Jun 2020
kubealex
on 13 Jun 2020
@kubealex looks like a networking problem for me, you can try the work around via setting "HostNetwork"
shibumi
on 13 Jun 2020
still here
Workaround
Changed the dnsPolicy from the cattle-cluster-agent deployment:
From:
dnsPolicy: ClusterFirst
To:
dnsPolicy: Default
kz12123
on 14 Jun 2020
in my case, coredns wasn't working due to a missing capability enabled in cri-o (NET_RAW)
kubealex
on 15 Jun 2020
same issue
Rancher 2.4.4
Kubernetes Version: v1.18.3
minikube 1.11
Docker 19.03.8
 Johnybe
on 15 Jun 2020
Johnybe
on 15 Jun 2020
Unbelievable that this is not resolved yet. I faced this issue more than 1 year back (I don't remember how I resolved back then). Now I am installing rancher 2.4 on a brand new Windwos 10 (docker-desktop) and Im facing the exact same issue.
Im installing using helm, and I cant find a way to use the workaround:
Workaround
Changed the dnsPolicy from the cattle-cluster-agent deployment:
From:
dnsPolicy: ClusterFirst
To:
dnsPolicy: Default
 brunobertechini
on 17 Jun 2020
brunobertechini
on 17 Jun 2020
@brunobertechini , it's really weird, whatever the provider aws, minikube, docker-desktop, I still have a host resolution error.
`INFO: Environment: CATTLE_ADDRESS=10.42.0.26 CATTLE_CA_CHECKSUM=04629d3294e6f84c25d055f13539346540170ad380a43375cbedf47f9aa5ca54 CATTLE_CLUSTER=true CATTLE_FEATURES=dashboard=true CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-6d85bc69d-fkx6r CATTLE_SERVER=https://k3s
INFO: Using resolv.conf: search home nameserver 192.168.64.1
ERROR: https://k3s/ping is not accessible (Could not resolve host: k3s)`
After changed the dnsPolicy from the cattle-cluster-agent deployment:
From:
dnsPolicy: ClusterFirst
To:
dnsPolicy: Default
I still got the same error from dns resolution from cattle-cluster-agent
https://k3s/ping is reachable by my browser i got a pong
Johnybe
on 17 Jun 2020
Update : I have no more errors as soon as I totally disable my firewall. In this case LittleSnitch on macOS with which I have a dnsPolicy : ClusterFirst
I will try again with providers like docker-desktop and AWS.
Johnybe
on 17 Jun 2020
We have the same issue on Rancher 2.4.2. As soon as a node from the local cluster gets deleted, we are getting error messages from all custom clusters that try to connect to the CATTLE_SERVER that is set on each of the cattle_cluster_agent. Same issue when the retries pass onto the cattle_node_agent after a few minutes. We tried to set the dnspolicy to "clusterfirst with host" and also tried to resolve the DNS Address internally. It seems like the only solution is to pass on the /etc/hosts/ alias file to each of the cattle cluster and node agents with the relevant dns entries to resolve this issue and then resolve it manually.
Additional Note:
The first deployment was only solely the etcd Node on local that we are trying to delete. We need to get this local node off and add 3 further nodes to expand the local system to HA.
Our procedure was the following:
- Add 3 nodes including all components to the local cluster with 1 Node. Everything works fine
- Add ingresses and deploy rancher to all the nodes
- Removed the one node from the local cluster that was provisioned before
- All custom clusters are not reachable anymore, with the following error:
{"log":"time=\"2020-06-17T12:18:25Z\" level=info msg=\"Connecting to proxy\" url=\"wss://replacedurl.com\"\n","stream":"stdout","time":"2020-06-17T12:18:25.738167056Z"}
{"log":"time=\"2020-06-17T12:18:25Z\" level=error msg=\"Failed to connect to proxy. Empty dialer response\" error=\"dial tcp replacedip:443: connect: connection refused\"\n","stream":"stdout","time":"2020-06-17T12:18:25.739445736Z"}
{"log":"time=\"2020-06-17T12:18:25Z\" level=error msg=\"Remotedialer proxy error\" error=\"dial tcp replacedip:443: connect: connection refused\"\n","stream":"stdout","time":"2020-06-17T12:18:25.739461749Z"}
{"log":"time=\"2020-06-17T12:18:35Z\" level=info msg=\"Connecting to wss://replacedurl.com/v3/connect with token replacedtoken\"\n","stream":"stdout","time":"2020-06-17T12:18:35.739883831Z"}
 RamazanKara
on 17 Jun 2020
RamazanKara
on 17 Jun 2020
I ran into this issue when I used a pfsense firewall as a load balancer in front of my cluster. I was able to resolve it by changing my outbound NAT as recommended here in the pfsense docs:
https://docs.netgate.com/pfsense/en/latest/book/loadbalancing/troubleshooting-server-load-balancing.html#unable-to-reach-a-virtual-server-from-a-client-in-the-same-subnet-as-the-pool-server
Essentially the fact that my nodes were on the same subnet as my load balancer caused traffic to not route properly because of incorrect source and destination IPs. This led to the failure in deployment described in this issue even though I was able to use my cluster for the most part normally otherwise. It may not necessarily represent what others have seen here, but could be a potential item to look at for others.
Note: This change does result in you losing some information regarding what host traffic originates from in traffic that hits your load balancer. This was not important to me so I did not worry about that loss of information, but others may.
I am using the loadbalancer on a Fortigate FW, and was facing the same issues. Velocity's comment jogged my memory, I have seen this same thing in prod with other VIPs. Since my cluster shares IP space with my LB VIP, I set up a hairpin for that traffic. At least this way I don't have to NAT and loose that data. Hairpinning is different between vendors, but at least it's a place to start.
 SmilinJoe
on 24 Jun 2020
SmilinJoe
on 24 Jun 2020
I'm using Rancher 2.4.4, K8s 1.17.6, Docker 19.03.8..same issue. I tried every solution here but no luck.
 rammaram06
on 25 Jun 2020
rammaram06
on 25 Jun 2020
I upgraded two separate Rancher clusters as follows and ran into this issue on one Rancher cluster:
Rancher: From 2.2.8 to 2.3.6
Rancher K8S: From 1.13.10 to 1.15.11
Docker: From 17.3.2 to 19.3.11
From my 3 Rancher nodes, I can no longer curl or telnet to my Rancher cluster DNS (myranchercluster.domain.com). But, when I stop Docker on one of the Rancher nodes curl and telnet atempts to my Rancher DNS work. This issue is causing the cluster and node agent pods to constantly restart.
ERROR: https://myranchercluster.domain.com/ping is not accessible (Failed to connect to myranchercluster.domain.com port 443: Connection timed out)
I upgraded both my Rancher clusters the same exact way - but only one cluster has this issue. It doesn't make sense what changes when I stop Docker on one Rancher node and then I can successfully curl and telnet to myranchercluster.domain.com:443.
 k8s42
on 27 Jun 2020
k8s42
on 27 Jun 2020
Same issue for me on a fresh install.
Resolved by changing the dnsPolicy from the cattle-cluster-agent deployment to Default and setting the appropriated records on the dns servers that are declared on the nodes, using hosts files did not work.
 NC-Alex
on 1 Jul 2020
NC-Alex
on 1 Jul 2020
Seeing the same issues on fresh installs from time to time, rancher itself is returning 404's on ping
 Kampe
on 1 Jul 2020
Kampe
on 1 Jul 2020
any solution?
 sunliusi
on 7 Jul 2020
sunliusi
on 7 Jul 2020
Unfortunately this issue is still there in 2.4.5
I am managing 3 clusters (1 is local) using rancher and 2 out of 3 had this problem. I didn't see this issue on my development cluster but both local and production had this issue (both of them are on AWS).
The workaround that we have applied is to edit the "cattle-cluster-agent" workload to give local IP for your rancher URL -
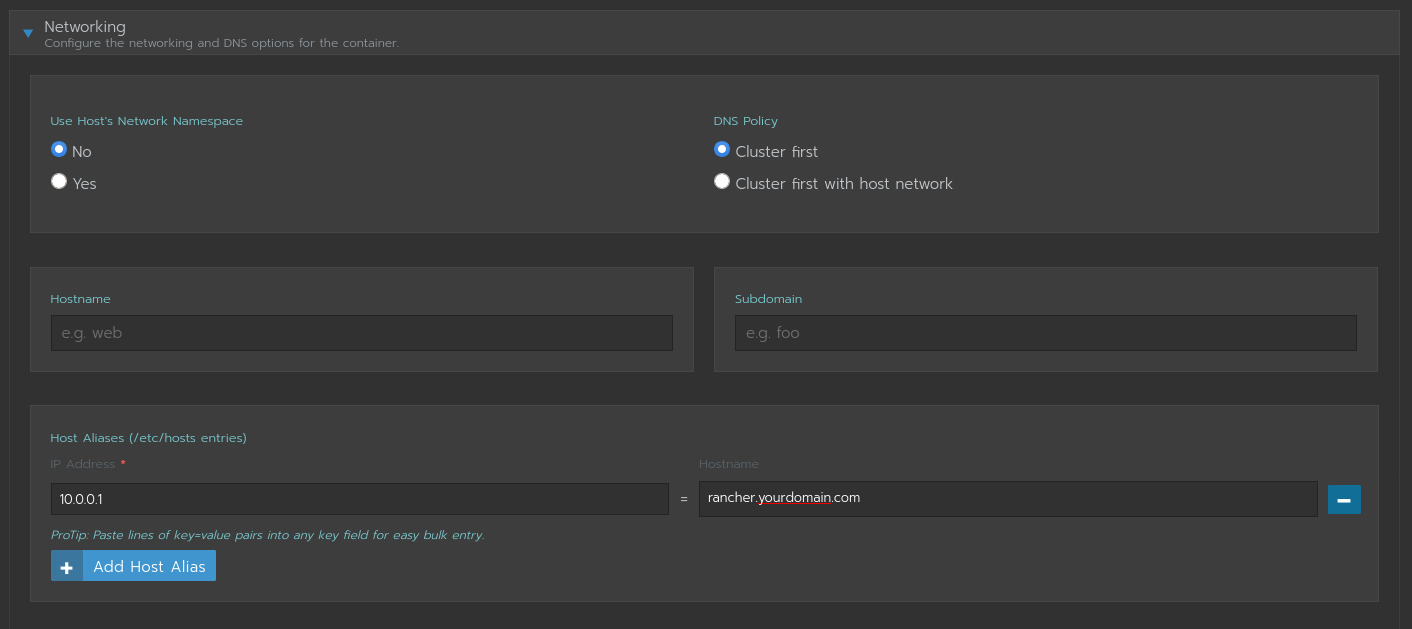
This worked like a charm for us and no more failure/restart of the cluster-agent were observed after that.
Hope this helps for you too !!!
 onkar-dhuri
on 7 Jul 2020
onkar-dhuri
on 7 Jul 2020
I'm able to fix issue on rhel8 after running below commands,
`
sudo iptables -P FORWARD ACCEPT
echo 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.d/50-docker-forward.conf
for mod in ip_tables ip_vs_sh ip_vs ip_vs_rr ip_vs_wrr; do sudo modprobe $mod; echo $mod | sudo tee -a /etc/modules-load.d/iptables.conf; done
sudo dnf -y install network-scripts
sudo systemctl enable network
sudo systemctl disable NetworkManager`
Got this from here https://github.com/superseb/rancher/commit/cacc5837ab50db42b078f32ac236dc3367130db1
rammaram06
on 15 Jul 2020
Im having the same problem currently for adding a local cluster, it happened both with kind and minikube so i dont think thats part of the problem.
it is a fresh install in centos 7
The thing is that in the yaml from rancher there's no dnsPolicy : ClusterFirst line inside the cattle-cluster-agent configuration, and even if i add it (either with ClusterFirst or Default), the problem persists.
 ju4nmg
on 3 Aug 2020
ju4nmg
on 3 Aug 2020
I have spent days troubleshooting this. I have ubuntu bionic VMs with dual NICs.
My cluster would only work if I deployed it by specifying cluster host addresses on the primary network interface of each host.
Changing default route from primary to secondary NICs does not resolve issue.
CNI is working, just cant resolve dns from within the pods. DNS resolution host side is fine on either NIC.
My only solution has been to remove the secondary interface and deploy on the primary.
 jmamma
on 4 Aug 2020
jmamma
on 4 Aug 2020
Oh my God,I'm tired, I re-run it now and then with a virtualbox VM and it still doesn't work the same way!
unbelievable
 dunhanson
on 4 Aug 2020
dunhanson
on 4 Aug 2020
I'm able to fix issue on rhel8 after running below commands,
`
sudo iptables -P FORWARD ACCEPTecho 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.d/50-docker-forward.conf
for mod in ip_tables ip_vs_sh ip_vs ip_vs_rr ip_vs_wrr; do sudo modprobe $mod; echo $mod | sudo tee -a /etc/modules-load.d/iptables.conf; done
sudo dnf -y install network-scripts
sudo systemctl enable network
sudo systemctl disable NetworkManager`
Got this from here superseb@cacc583
useful
dunhanson
on 4 Aug 2020
I'm able to fix issue on rhel8 after running below commands,
`
sudo iptables -P FORWARD ACCEPTecho 'net.ipv4.ip_forward = 1' | sudo tee -a /etc/sysctl.d/50-docker-forward.conf
for mod in ip_tables ip_vs_sh ip_vs ip_vs_rr ip_vs_wrr; do sudo modprobe $mod; echo $mod | sudo tee -a /etc/modules-load.d/iptables.conf; done
sudo dnf -y install network-scripts
sudo systemctl enable network
sudo systemctl disable NetworkManager`
Got this from here https://github.com/superseb/rancher/commit/cacc5837ab50db42b078f32ac236dc3367130db1
Didnt work for me
ju4nmg
on 6 Aug 2020
Same issue in v2.4.5
 datoracle
on 11 Aug 2020
datoracle
on 11 Aug 2020
can confirm with v.2.4.5. Setting dnsPolicy: Default fixed it though
 chuegel
on 14 Aug 2020
chuegel
on 14 Aug 2020
以下转自这个 issues
https://github.com/rancher/rancher/issues/18832#issuecomment-547728856
Adding host alias to the cattle agent can be done in this way:
kubectl -n cattle-system patch deployments cattle-cluster-agent --patch '{
"spec": {
"template": {
"spec": {
"hostAliases": [
{
"hostnames":
[
"{{ rancher_server_hostname }}"
],
"ip": "{{ rancher_server_ip }}"
}
]
}
}
}
}'
kubectl -n cattle-system patch daemonsets cattle-node-agent --patch '{
"spec": {
"template": {
"spec": {
"hostAliases": [
{
"hostnames":
[
"{{ rancher_server_hostname }}"
],
"ip": "{{ rancher_server_ip }}"
}
]
}
}
}
}'
 abserari
on 15 Aug 2020
abserari
on 15 Aug 2020
Hi,
same for me on "Custom Cluster" (on AWS but without Cloud Provider) => dnsPolicy to default seems to resolve the problem but is the cause for other problems (prometheus monitoring for example).
In fact what i have noticed is that there is no problem (with ClusterFirst dnspolicy and Prometheus...) if i'm modifying node scheduling policy to deploy on "etcd" node only => when cattle-cluster-agent is on controlplane node there is the connectivity problem.
any idea what could be the reason for that ?
Julien
 grinszju
on 4 Sep 2020
grinszju
on 4 Sep 2020
Hello,
This issue still persists without any concrete solution. I imported an EKS cluster to a Rancher server v 2.4.3 but the status of eks cluster on Rancher server was stuck on pending. I even patched the cluster agent deployment and node agent daemonset to replace the DNS name with the IP address but it didn't work. The only error message the logs show is:
ERROR: https://IP-address/ping is not accessible (Failed to connect to IP-address port 443: Connection timed out)
 hamad-yousif
on 4 Sep 2020
hamad-yousif
on 4 Sep 2020
I am on Rancher server v:2.4.8 and still have the same problem with running the quick-start install, the cattle cluster agent could not resolve the host name as found in my /etc/hosts file . I re-imaged my Linux and re-started the server container and I did 2 things that worked as a workaround
a. I added CATTLE_AGENT_IP=10.93.33.55 to the docker run command on the server.
b. I made sure when I did the initial login in the rancher gui I used the IP address (again) as the URL to connect to the server . Not the name, and the web gui said .. are you are you want to do this, it looks like a private ip. Yes. this perhaps is also a key point.
ps. before I re-installed I tried some of the suggestions to change the .yaml as mentioned above. that was only a partial fix.
pps. I would recommend installing kubectl on your master node.
 steve100
on 30 Sep 2020
steve100
on 30 Sep 2020
Unfortunately this issue is still there in 2.4.5
I am managing 3 clusters (1 is local) using rancher and 2 out of 3 had this problem. I didn't see this issue on my development cluster but both local and production had this issue (both of them are on AWS).
The workaround that we have applied is to edit the "cattle-cluster-agent" workload to give local IP for your rancher URL -
This worked like a charm for us and no more failure/restart of the cluster-agent were observed after that.
Hope this helps for you too !!!
I tried this option but the cattle-cluster-agent still failed to work. What IP address did you use? I did an nslookup of my rancher url and that's the IP I used. It didn't work. How do I get the correct IP address of the rancher url to you???
 michaelkasede
on 2 Oct 2020
michaelkasede
on 2 Oct 2020
@onkar-dhuri please help out on this. And if anyone from Rancher is reading this.... This is a problem so many people have had for a really long time. Can you dedicate a page in your docs to addresses thia 1 particular problem. It's a humble request. Thanks.
michaelkasede
on 2 Oct 2020
@onkar-dhuri please help out on this. And if anyone from Rancher is reading this.... This is a problem so many people have had for a really long time. Can you dedicate a page in your docs to addresses thia 1 particular problem. It's a humble request. Thanks.
Nslookup IP of your rancher URL won't work because it's a public IP. Try giving local IP which you can get by executing the command ifconfig on the machine which has rancher installed.
onkar-dhuri
on 3 Oct 2020
For me to get away from this issue was to add a local dns server in my lab environment. I know this is not something that will work for everyone, but thought of adding a comment here. I am also surprised to see this issue is still open since Nov 2018.
Here are the steps if anyone wants to follow:
- I created dns server and dns records in ubuntu 20.04 by following this youtube guide.
- Added dns server IP address to all kubernetes nodes.
Hope this helps someone who is still experiencing the issue. 👍
My suggestion to rancher dev team is to maybe add a global custom dns entry input/value in rancher ui settings that can allow everyone to customize host entries for cluster agent without going through kubectl patch workaround? In my case kubectl was not useful because my kubernetes nodes didnt have kubectl and cluster configurations available.
 tekspacedemo
on 19 Oct 2020
tekspacedemo
on 19 Oct 2020
I also ended up deploying a dns server in my local network.
chuegel
on 20 Oct 2020
I already have a DNS set up, so I enabled automatic DHCP hostname registration in DNS. Issue is not resolved even if I can nslookup from the host.
Docker container logs:
INFO: Environment: CATTLE_ADDRESS=10.42.0.6 CATTLE_CA_CHECKSUM=5bd5632b37de5f40b5ef0233aa01fe86ae081c22e2f6633dcb8fbde586a6e80a CATTLE_CLUSTER=true CATTLE_FEATURES= CATTLE_INTERNAL_ADDRESS= CATTLE_IS_RKE=true CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-7c56d97f45-wfx95 CATTLE_SERVER=https://rancher.<MY DOMAIN>
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local <MY DOMAIN> options ndots:5
ERROR: https://rancher.<MY DOMAIN>/ping is not accessible (The requested URL returned error: 404)
Ip address
$ ip a
2: ens192: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:50:56:88:a5:11 brd ff:ff:ff:ff:ff:ff
inet 192.168.10.176/24 brd 192.168.10.255 scope global dynamic ens192
valid_lft 5601sec preferred_lft 5601sec
inet6 fe80::250:56ff:fe88:a511/64 scope link
valid_lft forever preferred_lft forever
nslookup
```
$ nslookup srv01-node-1.
Server: 127.0.0.53
Address: 127.0.0.53#53
Non-authoritative answer:
Name: srv01-node-1.
Address: 192.168.10.176
```
 TomasTokaMrazek
on 25 Oct 2020
TomasTokaMrazek
on 25 Oct 2020
@TomasTokaMrazek - Your issue seems to be different then what most folks on this tread are experiencing. 404 error code means that dns is resolving and its having issue accessing the application. I would suggest using different tread or start a conversation in stackoverflow or slack channel with rancher.
tekspacedemo
on 27 Oct 2020
@tekspacedemo I am creating new issue, but I think that the root cause is the same. I have 404, becuase I actually use the same domain in homelab as in production. And since I have a public wildcard A DNS record for the domain, it gets resolved, but sends /ping to wrong address, see https://adamo.wordpress.com/2020/01/14/ranchers-cattle-cluster-agent-and-error-404/
In my opinion the root cause is the same, i.e. sending /ping to wrong address. I am verifying it by removing pulic DNS records.
TomasTokaMrazek
on 27 Oct 2020
Same issue for me on a fresh install.
Resolved by changing the dnsPolicy from the cattle-cluster-agent deployment to Default and setting the appropriated records on the dns servers that are declared on the nodes, using hosts files did not work.
How to change dmsPolicy. ? any Command to get into the POD?
 szapps
on 29 Oct 2020
szapps
on 29 Oct 2020
I upgraded two separate Rancher clusters as follows and ran into this issue on one Rancher cluster:
Rancher:
From 2.2.8 to 2.3.6
Rancher K8S:From 1.13.10 to 1.15.11
Docker:From 17.3.2 to 19.3.11From my 3 Rancher nodes, I can no longer curl or telnet to my Rancher cluster DNS (myranchercluster.domain.com). But, when I stop Docker on one of the Rancher nodes curl and telnet atempts to my Rancher DNS work. This issue is causing the cluster and node agent pods to constantly restart.
ERROR: https://myranchercluster.domain.com/ping is not accessible (Failed to connect to myranchercluster.domain.com port 443: Connection timed out)
I upgraded both my Rancher clusters the same exact way - but only one cluster has this issue. It doesn't make sense what changes when I stop Docker on one Rancher node and then I can successfully curl and telnet to myranchercluster.domain.com:443.
We resolve this issue by disabling session persistence/sticky sessions in the HA Rancher cluster's Azure load balancer.
k8s42
on 3 Nov 2020
this is mine (fix)
rancher server : 192.168.110.210 rancher.t.org

Edit ( button)
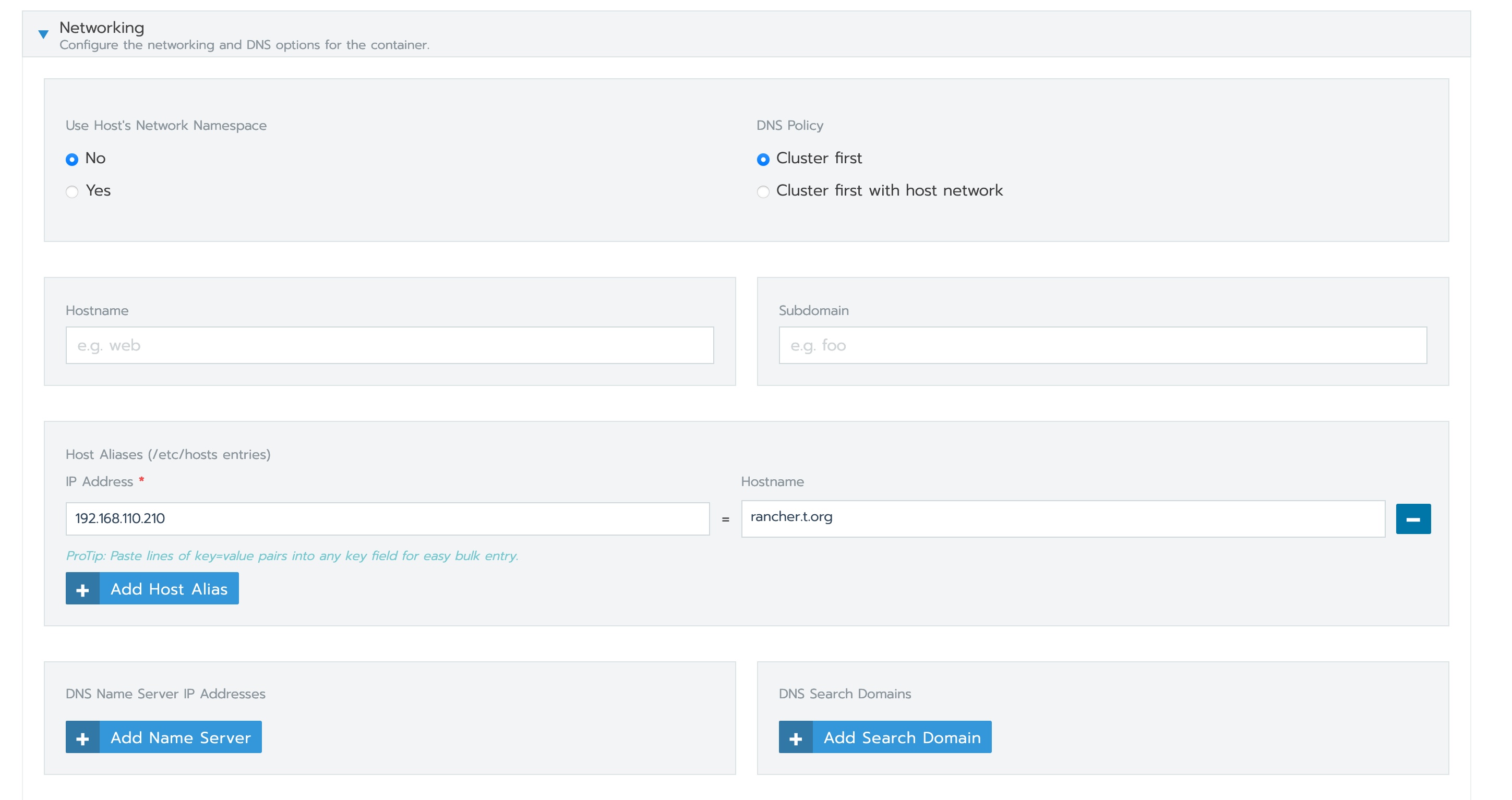
click save button
then return the Workload: cattle-cluster-agent
Success
 spacexnasa
on 20 Nov 2020
spacexnasa
on 20 Nov 2020
In my case i was able to solve it by removing any loopback IP (127.0.0.0/8) in the resolv.conf file (which is stated in rancher dns doc https://rancher.com/docs/rancher/v2.x/en/troubleshooting/dns/). on my ubuntu 18 machine i did it by disabling and stopping the systemd-resolved and rebooting the machine.
 stratus-clay
on 27 Nov 2020
stratus-clay
on 27 Nov 2020
I am facing the same problem and stuck for 2 days. I have tried everything suggested in this thread so far but nothing seems to work.
I have installed Rancher server (v2.5.2) on a 2 node K3S cluster. I am trying to create a custom cluster with all 3 components (etcd, control plane and worker) on a single VM.
The k8s_cluster-register_cattle-cluster-agent container is exiting in a loop as seen below:
~]$ docker container ls -a | grep register
e72a790daccc 444dfdf0ae3c "run.sh" About a minute ago Exited (1) About a minute ago k8s_cluster-register_cattle-cluster-agent-6c798f5596-x6b7w_cattle-system_8a2cceb2-70cd-4b39-9e5f-3d7446a5d54b_50
$ docker logs e72a790daccc
INFO: Environment: CATTLE_ADDRESS=10.42.6.203 CATTLE_CA_CHECKSUM=dddba4a71ddb84ea9ad5c88e2fd38a7df0e547676bc286a5303911040470f342 CATTLE_CLUSTER=true CATTLE_FEATURES= CATTLE_INTERNAL_ADDRESS= CATTLE_IS_RKE=true CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-6c798f5596-x6b7w CATTLE_SERVER=https://rancher.mydomain.com
INFO: Using resolv.conf: nameserver 10.43.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local options ndots:5
ERROR: https://rancher.mydomain.com/ping is not accessible (Could not resolve host: rancher.mydomain.com)
md5-676183e55ba31ce6c33e5df0040d0939
~]$ kubectl run -it --rm --restart=Never busybox --image=busybox:1.28 -- nslookup rancher.mydomain.com
Server: 10.43.0.10
Address 1: 10.43.0.10 kube-dns.kube-system.svc.cluster.local
Name: rancher.mydomain.com
Address 1: 10.53.198.176
Address 2: 10.53.198.175
pod "busybox" deleted
I have added DNS server name in /etc/resolv.conf on both, the Rancher server and downstream host.
From the Rancher UI, for Workload: rancher, Namespace: Cattle-system, under Networking, I have tried configuring Host alias, DNS server, dnsPolicy: Default, but nothing works.
Please let me know how I can investigate this further? Is there a way that I can run the k8s_cluster-register_cattle-cluster-agent container manually, so that I can troubleshoot the DNS failure reason.
Thanks.
 nikhilno1
on 2 Dec 2020
nikhilno1
on 2 Dec 2020
I observed that 5 containers inside /var/lib/docker/containers/ had their DNS server name as 10.43.0.10 in their resolv.conf files.
I manually changed that to the correct one. Now the k8s_cluster-register_cattle-cluster-agent is going a few steps further and exiting because of this error:
INFO: rancher.mydomain.com resolves to 10.53.198.176 10.53.198.175
INFO: Value from https://rancher.mydomain.com/v3/settings/cacerts is an x509 certificate
time="2020-12-02T09:46:30Z" level=info msg="Rancher agent version v2.5.2 is starting"
time="2020-12-02T09:46:30Z" level=info msg="Listening on /tmp/log.sock"
time="2020-12-02T09:46:30Z" level=info msg="Connecting to wss://rancher.mydomain.com/v3/connect/register with token xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"
time="2020-12-02T09:46:30Z" level=info msg="Connecting to proxy" url="wss://rancher.mydomain.com/v3/connect/register"
time="2020-12-02T09:46:30Z" level=info msg="Starting user controllers"
time="2020-12-02T09:47:00Z" level=fatal msg="Get \"https://10.43.0.1:443/apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions\": dial tcp 10.43.0.1:443: i/o timeout"
Not sure why it is timing out. If I try manually it seems to be working.
$ curl -k https://10.43.0.1:443/apis/apiextensions.k8s.io/v1beta1/customresourcedefinitions
{
"kind": "Status",
"apiVersion": "v1",
"metadata": {
},
"status": "Failure",
"message": "Unauthorized",
"reason": "Unauthorized",
"code": 401
I managed to solve the problem by doing the following procedure.
systemctl disable firewalld
systemctl stop firewalld
iptables -P FORWARD ACCEPT
modprobe br_netfilter
sysctl net.ipv4.ip_forward
sysctl net.bridge.bridge-nf-call-iptables=1
sysctl --system
sudo iptables -P FORWARD ACCEPT
set paramater : vi /etc/sysctl.d/50-docker-forward.conf
**
net.ipv4.ip_forward = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
**
for mod in ip_tables ip_vs_sh ip_vs ip_vs_rr ip_vs_wrr; do sudo modprobe $mod; echo $mod | sudo tee -a /etc/modules-load.d/iptables.conf; done
sudo systemctl enable network
sudo systemctl disable NetworkManager
reboot;
 ErdemERDOLU
on 30 Dec 2020
ErdemERDOLU
on 30 Dec 2020
Same problem here Imported EKS cluster:
Rancher 2.4.12
Ubuntu 20
Docker 19.03.8
Log for cattle-cluster-agent
INFO: Environment: CATTLE_ADDRESS=10.50.6.156 CATTLE_CA_CHECKSUM= CATTLE_CLUSTER=true CATTLE_FEATURES= CATTLE_INTERNAL_ADDRESS= CATTLE_K8S_MANAGED=true CATTLE_NODE_NAME=cattle-cluster-agent-754b8c6c8d-gq8wb CATTLE_SERVER=https://rch2.vetpro.us
INFO: Using resolv.conf: nameserver 172.20.0.10 search cattle-system.svc.cluster.local svc.cluster.local cluster.local vetpro.us options ndots:5
ERROR: https://rch2.vetpro.us/ping is not accessible (Could not resolve host: rch2.vetpro.us)
 cloudlady911
on 15 Jan 2021
cloudlady911
on 15 Jan 2021
Related issues
 johnrengelman
·
50Comments
johnrengelman
·
50Comments
 jiaqiluo
·
53Comments
jiaqiluo
·
53Comments
 gary-skwirrel
·
47Comments
gary-skwirrel
·
47Comments
 rcarmo
·
91Comments
rcarmo
·
91Comments
 jasonsoft
·
42Comments
jasonsoft
·
42Comments
Most helpful comment
Unfortunately this issue is still there in 2.4.5
I am managing 3 clusters (1 is local) using rancher and 2 out of 3 had this problem. I didn't see this issue on my development cluster but both local and production had this issue (both of them are on AWS).
The workaround that we have applied is to edit the "cattle-cluster-agent" workload to give local IP for your rancher URL -
This worked like a charm for us and no more failure/restart of the cluster-agent were observed after that.
Hope this helps for you too !!!