Pytorch: Improved Tensor subclassing support, preserving subclasses on function/method calls
🚀 Feature
Related: #22402
This feature proposes passing through Tensor subclasses via __torch_function__.
Desired Behaviour
Example desired behavior would be:
class MyTensor(torch.Tensor):
_additional_attribute = "Kartoffel"
a = MyTensor([0, 1, 2, 3])
# b should be a MyTensor object, with all class attributes passed through.
b = torch_function(a)
Goals
Quoting #22402
These are _potential_ goals that have been collected from the above referenced PRs, other PyTorch issues (referenced in the relevant sections), as well as from discussions with mainly Edward Yang, and also other PyTorch and NumPy maintainers:
- Support subclassing
torch.Tensorin Python- Preserve
Tensorsubclasses when callingtorchfunctions on them- Preserve
Tensorsubclasses when callingnumpyfunctions on them- Use the NumPy API with PyTorch tensors (i.e. NumPy API calls dispatch to
torchfunctions)- Use the PyTorch API with
torch.Tensor-like objects that are _not_Tensorsubclasses- Reuse NumPy ufunc implementations directly from PyTorch
- Allow operations on mixed array types, e.g.
tensor + ndarray
Additionally, from https://github.com/pytorch/pytorch/issues/28361#issuecomment-544520934:
- Preserve
Tensorsubclasses when callingTensormethods- Propagating subclass instances correctly also with operators, using views/slices/etc.
Rough Sketch of Implementation
Anything with a type like a built-in tensor will bypass __torch_function__ via their fast path (although they will have a default implementation) but anything else defined by an external library will have the option to allow it.
The following code snippet shows what the default __torch_function__ on TensorBase would look like.
class Tensor:
def __torch_function__(self, f, t, a, kw):
if not all(issubclass(ti, TensorBase) for ti in t):
return NotImplemented
result = f._wrapped(*a, **kw)
return type(self)(result)
cc @ezyang @gchanan @zou3519 @jerryzh168 @jph00 @rgommers
 hameerabbasi
hameerabbasi
All 74 comments
Can you explain what exactly the delta from this proposal and #22402 is? Or is this just a pattern that subclasses of Tensor can use to implement extensions?
 ezyang
on 21 Oct 2019
ezyang
on 21 Oct 2019
@ezyang Please see the update to the issue, I've added more details on how this can be made automatic. I've also added an example use-case.
It basically sets out how (if we allow __torch_function__ on subclasses), we can, by a simple extension, create a default __torch_function__ that will make passing through subclasses automatic.
hameerabbasi
on 21 Oct 2019
@hameerabbasi I'd suggest editing the description some more. The relevant goals are:
- Support subclassing
torch.Tensorin Python - Preserve
Tensorsubclasses when calling torch functions on them - Preserve
Tensorsubclasses when callingTensormethods - Propagating subclass instances correctly also with operators, using views/slices/etc.
Can you explain what exactly the delta from this proposal and #22402 is?
There's no delta, we just need an issue for this topic for discussion (and reporting) that's not mixed with the multi-topic gh-22402. That issue is basically implementable in three parts: __torch_function__ (close to ready for review), this subclassing topic (just started), and NumPy protocol support (lowest prio, not started).
 rgommers
on 21 Oct 2019
rgommers
on 21 Oct 2019
OK, sgtm. @jph00 how does this look to you?
ezyang
on 21 Oct 2019
Thanks gang. I have no comment on the proposed implementation, but the goals look great. :)
Although it's covered already implicitly by the stated goals, I should mention that we've had trouble getting __getitem__ working correctly in subclasses - so this might be something to make sure you test carefully. E.g. be sure to test passing tensors of various types as indices, including bool mask tensors and subclasses.
 jph00
on 21 Oct 2019
jph00
on 21 Oct 2019
Thanks @jph00, that's exactly the type of input we need.
rgommers
on 21 Oct 2019
It seems like variable and no-argument methods do not parse self in their list of arguments:
and
PythonArgParser also does not take self: https://github.com/prasunanand/pytorch/blob/torch_function/torch/csrc/utils/python_arg_parser.h#L102
It might be good for the purposes of this issue to allow self as an argument to PythonArgParser. However, I'm not sure what the overhead of parsing an argument is.
hameerabbasi
on 15 Nov 2019
Also, would it be better to have an expected method on subclasses for the default __torch_function__ a.la. __array_wrap__ (instead called __torch_wrap__, for mirroring NumPy), or just call the default constructor with the output tensor?
Examples:
class TensorSubclass(Tensor):
def __init__(self, *a, **kw):
if len(a) == 1 and len(kw) == 0 and isinstance(a[0], torch.Tensor):
# Do conversion here
vs
class TensorSubclass(Tensor):
def __torch_wrap__(self, tensor):
# Do conversion here
@jph00 Thoughts?
hameerabbasi
on 15 Nov 2019
It's hard to talk about a very specific implementation problem without seeing more about the planned implementation. In particular, why does PythonArgParser need self?
ezyang
on 15 Nov 2019
Here's my line of reasoning:
- We need a default
__torch_function__onTensor(see issue description), which has to be applied toselfas well. - We need to make it work with methods as well, for this to work.
selfneeds to be in the list of parsed arguments, because most of the__torch_function__logic is insidePythonArgParser.
The other option is to refactor/rewrite the logic separately for self, i.e.
if type(self) is not Tensor and hasattr(self, '__torch_function__'):
# Process things here, separately.
Any opinions on which path to take?
hameerabbasi
on 15 Nov 2019
I have a WIP branch up at https://github.com/Quansight/pytorch/tree/subclassing, I've added tests at: https://github.com/Quansight/pytorch/blob/a68761ef8942041089d5da4815db07f020667260/test/test_subclassing.py
hameerabbasi
on 16 Nov 2019
We need to make it work with methods as well, for this to work.
OK, let's talk about this for a moment. In the __torch_function__ PR I mentioned about whether or not it would make sense to have some sort of magic method for overriding both functions and methods, but we decided it was out of scope for this issue. Let's drop the question of default tensor function preserving subclasses for a moment, and ask a simpler question: how exactly does the extension to __torch_function__ to support methods work?
ezyang
on 18 Nov 2019
how exactly does the extension to
__tensor_function__to support methods work?
Okay, so my vision is the following: __torch_function__ has the signature (func, args, kwargs) (from the previous PR). In traditional Python style, if it's called on a Tensor _method_, then func will be the method itself e.g. Tensor.__add__, and args/kwargs would also contain self, in addition to the other explicitly passed-in arguments. In this example, args will contain both self and other.
hameerabbasi
on 19 Nov 2019
OK, this sounds plausible to me. However, it sounds like this is different from the way Numpy handles arrays in __array_function__. Can you compare this refinement to the Numpy approach?
Also, we have to be careful about this change because if I define both def __add__ and def __torch_function__, which one "wins"?
ezyang
on 19 Nov 2019
Can you compare this refinement to the Numpy approach?
__array_function__ in NumPy doesn't apply to ndarray methods. NumPy, in order to handle subclassing behaviour, does ret = ret.view(subclass) at the end of every method, and then in addition calls ret.__array_finalize__(self) (assuming it exists).
Also, we have to be careful about this change because if I define both
def __add__anddef __torch_function__, which one "wins"?
__add__ wins, because of Python's __mro__, subclasses come before superclasses. NumPy has the same problem and model.
hameerabbasi
on 19 Nov 2019
On Tue, Nov 19, 2019, at 8:43 AM, Hameer Abbasi wrote:
Can you compare this refinement to the Numpy approach?
__array_function__in NumPy doesn't apply tondarraymethods. NumPy, in order to handle subclassing behaviour, doesret = ret.view(subclass)at the end of every method, and then in addition callsret.__array_finalize__(self)(assuming it exists).
This is also how fastai v2 works BTW - we call retain_types() at the end of Transform.encodes and various other places (automatically, in most cases).
jph00
on 19 Nov 2019
The option of using __array_finalize__ was discussed in gh-22402, the issue is that it's slow.
NumPy, in order to handle subclassing behaviour, does
ret = ret.view(subclass)at the end of every method
This actually doesn't work for PyTorch because Tensor.view behaves quite differently from ndarray.view. We had tests in the __torch_function__ branch that used it (adapted from NumPy) but they didn't work so we changed to only use the regular Python way of creating and instantiating a subclass.
rgommers
on 19 Nov 2019
This actually doesn't work for PyTorch because
Tensor.viewbehaves quite differently fromndarray.view. We had tests in the__torch_function__branch that used it (adapted from NumPy) but they didn't work so we changed to only use the regular Python way of creating and instantiating a subclass.
Maybe it could be called .cast instead?
jph00
on 19 Nov 2019
Maybe it could be called
.castinstead?
I find a number of discussions on the behavior of view, so I think it has been considered before and rejected. cast implies a dtype change I'd think rather than a shape change. view is basically equivalent to reshape in NumPy. Or Tensor.reshape, except that that also works for mismatching shapes.
rgommers
on 20 Nov 2019
On Tue, Nov 19, 2019, at 4:43 PM, Ralf Gommers wrote:
Maybe it could be called
.castinstead?
I find a number of discussions on the behavior of
view, so I think it has been considered before and rejected.castimplies a dtype change I'd think rather than a shape change.viewis basically equivalent toreshapein NumPy. OrTensor.reshape, except that that also works for mismatching shapes.
Possibly one of us is misunderstanding something (and it could well be me!)
In numpy, view does exactly that: it's a dtype change, not a shape change. That's why I suggested cast as the name for the equivalent functionality in pytorch.
jph00
on 20 Nov 2019
There's a bit more to view in NumPy:
>>> import numpy as np
>>> class subarray(np.ndarray):
... newattr = "I'm here!"
...
>>> x = np.arange(4)
>>> x.view(subarray)
subarray([0, 1, 2, 3])
>>> y = x.view(subarray)
>>> isinstance(y, subarray)
True
>>> y.newattr
"I'm here!"
EDIT: I'd use astype for a dtype change
rgommers
on 20 Nov 2019
On Tue, Nov 19, 2019, at 4:55 PM, Ralf Gommers wrote:
There's a bit more to
viewin NumPy:
Yes, true, but that doesn't invalidate the basic point I think :)
jph00
on 20 Nov 2019
This actually doesn't work for PyTorch because
Tensor.viewbehaves quite differently fromndarray.view.
Yes, true, but that doesn't invalidate the basic point I think :)
Agreed, the point was to demonstrate NumPy behaviour, and as this is a PyTorch issue tracker I should have mentioned that the equivalent for Tensor would have to be created or discovered. Perhaps @ezyang can specify whether this is feasible, and a couple of guidelines on how.
hameerabbasi
on 20 Nov 2019
@hameerabbasi you may want to browse through the diff in gh-22235, it's incomplete and part of a set of PRs that were a little confused, but for preserving subclasses in methods it kind of does what view + __array_finalize__ does. So at least good to see what parts of the code it had to touch.
That's of course an alternative direction to your original "parse self + use __torch_function__" idea. Hard to predict which one is cleaner/faster.
rgommers
on 20 Nov 2019
__add__wins, because of Python's__mro__, subclasses come before superclasses. NumPy has the same problem and model.
What if I, in my subclass, define both __add__ and __torch_function__? Then MRO doesn't give guidance, IIUC?
ezyang
on 20 Nov 2019
I'd use astype for a dtype change
Yes, this name seems better
ezyang
on 20 Nov 2019
What if I, in my subclass, define both __add__ and __torch_function__? Then MRO doesn't give guidance, IIUC?
Python always looks for __add__ when + is used, so that always takes precedence.
hameerabbasi
on 20 Nov 2019
Python always looks for
__add__when+is used, so that always takes precedence.
I don't think this resolves my problem. A better comparison is comparing __add__ and __getattr__, both of which are ways you could overload the behavior of +. My understanding is that Python's rules mean that once I define __add__ in ANY superclass, __getattr__ will never be considered, even if I redefine it in a subclass.
class A:
def __add__(self, other):
return 1
class B(A):
def __getattr__(self, attr):
return lambda other: 2
print(B() + B())
macbook-pro-116:~ ezyang$ python3.7 fof.py
1
But the stated desired behavior above is that I can subclass Tensor, with no extra code, and subclasses are then preserved.
class MyTensor(Tensor):
pass
MyTensor() + MyTensor() # results in MyTensor
but MyTensor.__add__ is defined, and so arguably it will be processed before __torch_function__. I haven't seen an explanation of how you plan to resolve this ambiguity!
ezyang
on 20 Nov 2019
I suppose one way to solve the problem is to require users to explicitly define __torch_function__ to call your "preserve subclasses" implementation. This seems workable to me, although it's inconsistent with how __getattr__ works.
ezyang
on 20 Nov 2019
I suppose one way to solve the problem is to require users to explicitly define
__torch_function__to call your "preserve subclasses" implementation. This seems workable to me, although it's inconsistent with how__getattr__works.
There will be a default __torch_function__ implementation, which will, in essence, be skipped for torch.Tensor, which would do the right thing, but if users define a __add__, it will be up to them to do the right thing.
hameerabbasi
on 20 Nov 2019
@hameerabbasi had a brief call. I presented two problems with Hameer's implementation:
- Suppose that I define
__torch_function__andaddon a subclass. Ifaddcallssuper().add()as part of its implementation,__torch_function__will get invoked later! That's weird. - Suppose that
__torch_function__is only invoked ifaddis not overridden (which fixes (1)). Then we lose "compositionality of subclassing": you can subclass Tensor into MyTensor and have subclasses preserved, but if you have DiagonalTensor (extending Tensor), and then subclass it into MyDiagonalTensor, subclass isn't preserved. (This is because, even if DiagonalTensor.add calls super(), we won't call__torch_function__because add is overridden)
ezyang
on 20 Nov 2019
I want to point out another use case of this functionality that surfaced in our conversations with OpenAI. What OpenAI wants to do is insert hooks at a per operator level, so they can inspect the tensors that are flowing through each operation (right now, they are hooking in at the module level, but sometimes there are more fine grained operations they need to hook into).
__torch_function__ is tantalizingly close to providing what you need for this, but:
- We need subclass preservation, so our hooks keep getting run (this issue)
- We need away to insert code that operates on both functions and methods uniformly (so we can write a single function that overrides all operators)
Let's make sure we can hit this case too!
cc @suo @orionr @NarineK who were present for this conversation.
ezyang
on 21 Nov 2019
Some constraints:
- Numpy compatibility: our thing should work the same way as numpy, or we should have a good argument why numpy was wrong and we've fixed the problem (a note about Numpy: if you have A + B, it will return A, and if you do B + A, it returns B, if there is no subclass relationship between A and B)
- Overriding methods by just defining them on the subclass should work
- And super calls should do the right thing
Non-constraint:
- I don't mind if we have
__torch_function__and ANOTHER magic method to do both function and method overrides (I don't know if it's necessary)
ezyang
on 2 Dec 2019
One more constraint: Parameter is a subclass of Tensor, and it shouldn't preserve subclasses (and maybe generally, preserving subclasses may need to be opt-in to preserve BC.)
@hameerabbasi and I had another call, and we have an interesting problem: suppose your have:
class ATensor(Tensor):
def add(self, other):
super().add(other)
class BTensor(ATensor):
def __torch_function__(self):
# pass through
class CTensor(BTensor):
def add(self, other):
super().add(other)
What order should the methods be called? It should be CTensor.add, BTensor.__torch_function__, ATensor.add!! This suggests that we must automatically define a method BTensor.add (via a metaclass) to make this work, if we want to make this work. (And this method should do CLASS based dispatch to __torch_function__.)
Some other scratch notes:
Current thinking: if we did the subclass preservation completely separately from torch function, then add wouldn't call into super. Super calls should do the right thing, that's in general an issue. For that, we have to get the reference implementation, the one on Tensor itself, right. That is true regardless of whether or not we go for the torch function approach or not. If super().add() should do the right thing... is there a way to test if you're passed a super object, rather than the basic? (Can't just test for Tensor, because it's not composable).
What if we don't use super? Do something else. (This doesn't actually help: you're going to have to use super either way).
Alternative: For __torch_function__, we forbid super. This is essentially what Numpy does: it forbids super inside __array_function__, but what instead does, there were proposals to do it, it should allow the wrapped implementation (the non-dispatching implementation) to be available. Which is just torch_function with a super colon. This was one of the ideas from numpy.
Idea: __array_function__ should be a classmethod. There are a few problems with this. If there is metadata on the instance, that gets lost. That's still available in the function arguments, but it's lost on self.
Need a way to tell where in the MRO we are. Hope that Python natively supports this.
Take in another argument of the class. (not on classmethod)
ezyang
on 2 Dec 2019
I'd use astype for a dtype change
Sorry @rgommers I shouldn't have said "a dtype change". I meant something like "a change to self.__class__". I see the cause of the confusion now! :)
Basically, this is what numpy's view() does. So in this issue, what's the current proposal for how exactly to do the equivalent thing in pytorch?
jph00
on 3 Dec 2019
There's not a proposal yet. @hameerabbasi will submit a specific proposal for consideration.
ezyang
on 3 Dec 2019
Tensor subclassing proposal
__torch_function__ and methods
We pass all methods through __torch_function__, where the first passed-in argument will be self. So, for example, for MySubTensor.__add__ will (if not overridden), call MySubTensor.__torch_function__(Torch.__add__, (self, other), {}). __torch_function__ will be changed to a class method for dispatching reasons, and gain an additional argument arrays which will contain the passed-in arrays.
Adding Tensor.as_subclass(other_class)
Tensor will gain a new method, Tensor.as_subclass(other_class) that will view the Tensor object as another class with all data intact. Subclasses should be callable in the form MySubTensor(tensor_object), which will copy the attributes over from another Tensor (or subclass) object. Tensor itself will gain support for this pattern. This will be a _view_ of the data rather than a copy.
Alternatives
If this is unsupported or undoable for some reason, a classmethod MySubTensor.from(tensor_obj) can also be considered.
Dispatching specific methods
There is the drawback that calling super() in MySubTensor.__add__ could call back into MySubTensor.__torch_function__. However, this is expected behaviour, as __torch_function__ inspects all its arguments for non-Tensor types, including MySubTensor. (NumPy has the same problem). The _correct_ way to call super from __add__ would be to view all arguments that have to be "removed from dispatch" as Tensor, and _then_ call super().__add__.
Implementation
Tensor would gain a default implementation for __torch_function__ which would:
- Inspect all arguments to see if
getattr(t, "__torch_function__", Tensor.__torch_function__) is not Tensor.__torch_function__. If such an argument exists,return NotImplemented. - Perform the operation
- Do
return Minimal_Subclass.from(ret)at the end.
Unrelated type trees will raise an error.
hameerabbasi
on 3 Dec 2019
Thanks @hameerabbasi . I'll change fastai2 to use as_subclass for this as well, so we'll be compatible in the future.
jph00
on 3 Dec 2019
@jph00 Just to be clear, that method doesn't exist yet. We'll have to add it.
hameerabbasi
on 4 Dec 2019
Yes no problem - I've already patched it in though:
@patch
def as_subclass(self:Tensor, typ):
"Cast to `typ` (should be in future PyTorch version, so remove this then)"
return torch.Tensor._make_subclass(typ, self)
BTW one thing that doesn't work with this approach is that any additional attrs are lost. It would be nice if this were fixed, since we rely on it - for now we'll add this manually to our patched version. Here's an example (based on the above implementation):
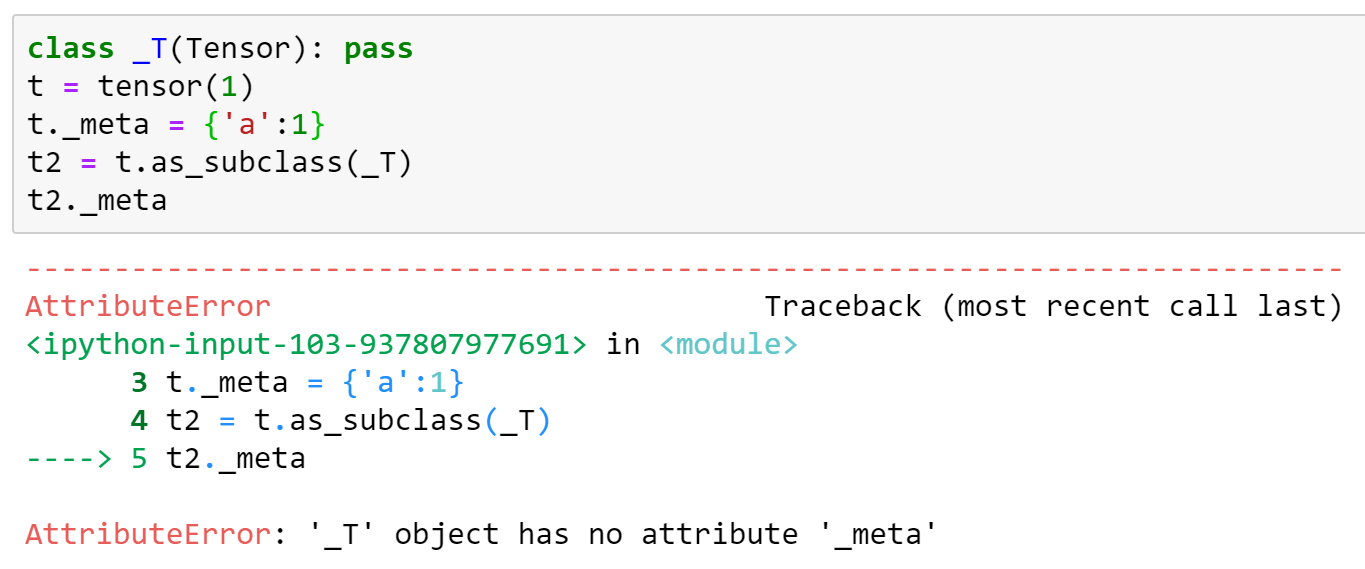
jph00
on 4 Dec 2019
Yes, you'll have to define a __torch_function__ that copies those things over, and that should do it for all arrays.
hameerabbasi
on 4 Dec 2019
Why not have as_subclass do it? Casting shouldn't delete attributes, should it?
jph00
on 4 Dec 2019
That seems fair, yes, we can copy over everything in the object's __dict__.
hameerabbasi
on 4 Dec 2019
__torch_function__ will be changed to a class method for dispatching reasons
Can you say more clearly what this means?
gain an additional argument arrays which will contain the passed-in arrays
Do you mean tensors?
This proposal means breaking from the API that @ngoldbaum established. We are only very recently adding __torch_function__ so we still have the opportunity to make changes, but I'd like to see some argument in the proposal on why we should make these changes. In particular, why should we do it differently than Numpy?
copy the data
Really a copy? Or will they share storage?
Tensor.from(other_class)
Are you proposing to name this from or as_subclass?
The correct way to call super from
__add__would be to view all arguments that have to be "removed from dispatch" as Tensor, and then callsuper().__add__.
This is pretty different from what we have discussed, and I want to push back on this proposal a little.
Suppose you have:
class ATensor(Tensor):
a: SomeAMetaData
class BTensor(ATensor):
b: SomeBMetaData
def __add__(self, other):
...
You have stated that in the __add__ definition, we are obligated to other.as_subclass(ATensor) so as to remove BTensor from the dispatch hierarchy. OK, seems fair enough. But as you have seen in discussion with @jph00, this means we must COPY over SomeAMetaData into the A-view of the tensor when we drop to the next definition. This seems super sketchy to me, because you have basically reimplemented C++ object slicing in Python (https://stackoverflow.com/questions/274626/what-is-object-slicing). And everyone hates object slicing.
Furthermore, you still haven't solved the problem that arises in this case:
class ATensor(Tensor):
def __add__(self, other):
...
class BTensor(ATensor):
def __torch_function__(self, ...):
...
By method resolution rules, BTensor.__add__ will directly invoke ATensor.__add__, bypassing __torch_function__ entirely. Bad!
ezyang
on 4 Dec 2019
Sorry if this is a dumb question - but why copy __dict__ instead of just using a reference? (In fastai2 I'm just using a reference at the moment, since when we cast we wouldn't normally expect to get a copy, but rather a different view of the same data, including metadata.)
jph00
on 4 Dec 2019
By method resolution rules,
BTensor.__add__will directly invokeATensor.__add__, bypassing__torch_function__entirely. Bad!
Okay, I'm going to go out on a limb here and claim that Tensor.__add__ and Tensor.__torch_function__ know how to handle any subclasses for which Subclass.__torch_function__ is Tensor.__torch_function__. So ATensor.__add__ can call super without worrying too much, or "removing anything from dispatch", or worrying about any kind of subclassing. Great!
Now comes the second part. After ATensor.__add__ does its magic and calls super, Tensor.__add__ notices that there are still BTensor objects in there, and BTensor.__torch_function__ is not Tensor.__torch_function__! So it falls back there (with all objects as-is), handling it correctly.
Now flow comes back into ATensor.__add__. It notices that isinstance(super().__add__(self, other), ATensor)! It performs any further post-processing and returns the value.
Are you proposing to name this
fromoras_subclass?
I've changed it to be consistent.
Do you mean tensors?
This proposal means breaking from the API that @ngoldbaum established. We are only very recently adding
__torch_function__so we still have the opportunity to make changes, but I'd like to see some argument in the proposal on why we should make these changes. In particular, why should we do it differently than Numpy?
I suppose we don't have to. I thought it was necessary, but thinking it through once more, with your example, I was wrong.
Really a copy? Or will they share storage?
Changed this to be consistent as well.
hameerabbasi
on 5 Dec 2019
Sorry if this is a dumb question - but why copy
__dict__instead of just using a reference? (In fastai2 I'm just using a reference at the moment, since when we cast we wouldn't normally expect to get a copy, but rather a different view of the same data, including metadata.)
I meant a shallow copy, not a deep copy, but as @ezyang points out, this is problematic, and better handled in the __torch_function__ of the subclass.
hameerabbasi
on 5 Dec 2019
Now comes the second part. After ATensor.__add__ does its magic and calls super, Tensor.__add__ notices that there are still BTensor objects in there, and BTensor.__torch_function__ is not Tensor.__torch_function__! So it falls back there (with all objects as-is), handling it correctly.
This flow seems completely backwards to me. If BTensor is a subclass of ATensor, I expect B to get processed first before I get to A. OOP 101
ezyang
on 5 Dec 2019
This flow seems completely backwards to me. If
BTensoris a subclass ofATensor, I expectBto get processed first before I get toA. OOP 101
While I agree, virtual methods are what they are, unfortunately, and the only way around this I can think of is the metaclass approach we discussed, the one that patch/use __torch_function__ for every single method... Which could lead to even weirder behaviour: A.__add__ getting ignored.
hameerabbasi
on 5 Dec 2019
One thing I can think of here is to use the following design: use B.__torch_function__(B.__add__, (self, other), {}) as a default, but that might mess up any dictionary-based dispatch that may exist.
hameerabbasi
on 5 Dec 2019
A quick meta point: if we can't think of a good way (not a "way around") to do this, we should stop doing this, or change our underlying constraints until there is a good way.
ezyang
on 5 Dec 2019
Okay, the other alternative here is to use __tensor_wrap__ and __tensor_finalize__. What these two protocols do is essentially pre- and post-processing when "wrapping into a subclass".
However, cautionary note: These have exactly the same problem with super that we just discussed (i.e. things will be processed in the wrong order in your example).
or change our underlying constraints until there is a good way.
How about this: use a metaclass that injects the following in:
One thing I can think of here is to use the following design: use
B.__torch_function__(B.__add__, (self, other), {})as a default, but that might mess up any dictionary-based dispatch that may exist.
If B.__add__ is not Tensor.__add__, I claim that dictionary-based dispatch should fail, and one should use func.__name__ instead.
If this option is not feasible, then we should change the constraints.
hameerabbasi
on 7 Dec 2019
What is meant here by "dictionary-based dispatch"? I am a bit lost now.
ezyang
on 8 Dec 2019
Dictionary-based dispatch is where, inside __torch_function__, one uses a dictionary to look up func and decide the implementation of the function. This will fail as B.__add__ is not Tensor.__add__, and if a class dispatches on the latter, it won't be found in the dict. But I claim this is correct behavior, because using cls.__add__ would produce the correct behaviour. If a class is B or one of its descendants which don't override __add__, then B.__add__ is the correct method to use, and looking up Tensor.__add__ is incorrect anyway.
hameerabbasi
on 9 Dec 2019
@hameerabbasi I would suggest to add the __add__ interaction with multiple subclasses to the test cases in your branch. The discussion is really hard to follow like this; I'd like to be able to figure out more easily if this is a showstopper or a corner case.
A quick meta point: if we can't think of a good way (not a "way around") to do this, we should stop doing this, or change our underlying constraints until there is a good way.
Each "constraint" should be a separate test case.
To make progress more easily, it may be useful to add a slow mechanism analogous to NumPy's __array_finalize__ that meets all the constraints, and then assess what goes wrong if it's replaced with something faster (whether metaclass or __torch_function__ based or other).
Also, this mechanism is independent of public API changes like as_subclass, so would be useful to be able to look at those as well - they shouldn't need changes after.
rgommers
on 10 Dec 2019
To make progress more easily, it may be useful to add a slow mechanism analogous to NumPy's
__array_finalize__that meets all the constraints, and then assess what goes wrong if it's replaced with something faster (whether metaclass or__torch_function__based or other).
This will have the same composition issue, unfortunately. I pointed that out here:
Okay, the other alternative here is to use
__tensor_wrap__and__tensor_finalize__. What these two protocols do is essentially pre- and post-processing when "wrapping into a subclass".However, cautionary note: These have exactly the same problem with
superthat we just discussed (i.e. things will be processed in the wrong order in your example).
Also, this mechanism is independent of public API changes like
as_subclass, so would be useful to be able to look at those as well - they shouldn't need changes after.
@ezyang Would you have an idea of what needs to be done for such a function, what data needs copying and what needs views and so on?
hameerabbasi
on 10 Dec 2019
@hameerabbasi I'm actually not to sure what the precise semantics of as_subclass are (yes I know it views the tensor as a subclass, but this is frustratingly vague). For starters, does it call the constructor of the subclass?
ezyang
on 10 Dec 2019
I was hoping there would be a way to do it while keeping the same data pointer, whatever that entails, and also keeping any autograd data attached..
hameerabbasi
on 10 Dec 2019
I believe the semantics should be exactly the same as replacing __class__ in a regular python object. That is also the behavior of view() in numpy, I believe. Which is to say:
- All state, including in
__dict__, is preserved __init__is not calledtype()will return the new type, and method dispatch will use that type's methods in the usual python way (including metaclass dispatch, if a metaclass is defined)
I think it's also helpful to have some special method that's called at this time if it exists - in fastai2, for instance, it's called __after_cast__.
jph00
on 10 Dec 2019
I'm not sure how to do it. Let me give some information about how PyObject is implemented in PyTorch and maybe that gives you some information.
The PyObject representing Tensor looks like this:
// Python object that backs torch.autograd.Variable
// NOLINTNEXTLINE(cppcoreguidelines-pro-type-member-init)
struct THPVariable {
PyObject_HEAD
// Payload
torch::autograd::Variable cdata;
// Hooks to be run on backwards pass (corresponds to Python attr
// '_backwards_hooks', set by 'register_hook')
PyObject* backward_hooks = nullptr;
};
Every Variable also contains a pyobj field which points to the unique PyObject object representing the tensor. This ensures that C++ object identity and Python object identity coincide.
Does that answer your question?
ezyang
on 11 Dec 2019
Does that answer your question?
Somewhat. It seems to me that if in true RAII fashion, cdata is actually copied on assignment/copy constructing, we'll need a way to shallow copy it or change it to a pointer, but that's a pretty invasive change. Other than that, we can just copy all the fields, mostly, as well as shallow-copying __dict__.
hameerabbasi
on 19 Dec 2019
This is how I updated the fastai2 implementation a couple of weeks ago:
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__
return res
It seems to be working fine for us - but if we're missing something important, I'd love to know now so we can try to fix it! (And if we're not missing something important, is this a solution that pytorch can use too?)
jph00
on 19 Dec 2019
I'm just going to go ahead and summarise the issue with __torch_function__ for methods as well as __torch_finalize__, and then talk about my preference and my take on @ezyang's composability problem.
__torch_function__ for methods (and the problem with super)
Consider the following code (__torch_function__ for methods will just pass self as the first argument).
class SubclassA(torch.Tensor):
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
Now, consider what happens when we add an instance of SubclassB with another such instance.
Since __add__ is inherited from SubclassA, the flow control goes there first instead of SubclassB's __torch_function__. What happens, concretely, in my current proposal, is:
self/otherare transformed bySubclassA.__add__. Hopefully, if nothing too weird happens, the transformations preserve the class (SubclassBin this case).- Since
self_transformed/other_transformedare an instance ofSubclassB, the call tosupergoes toTensor.__torch_function__, which by default does exactly the same asTensor.__add__, and returns the result. - We then transform
temp_result, and pass it back toSubclassA.__add__. SubclassAdoes the final transformations and then returns the result.
The issue with this is the following: There is an inversion of control. SubclassB.__torch_function__ should be the one controlling the execution flow, but it isn't.
During a previous call, me and @ezyang talked about the following solution: Add a default __add__ to SubclassB (perhaps via metaclasses) that dispatches directly to SubclassB.__torch_function__.
I would like to propose the flip side of this, which has the benefit of making everything behave exactly as Tensor behaves. Possibly we can even make Tensor itself work this way if it weren't for the limitation on performance regression:
Make all implementations of methods on subclasses also go through __torch_function__ by default.
__torch_finalize__ and the problem with super
Here, although less exacerbated, the problem still exists. The inversion of control exists, but since __torch_finalize__ (as the name implies) only finalizes the result (based on one of the inputs of that type), but performs no pre-processing.
as_subclass
I believe @ezyang can talk more about how this is okay or not, but I see at least one problem with it:
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__.copy() ## I added the copy
return res
Otherwise modifying any attribute on res would also modify it on self (unless that was the intention?)
hameerabbasi
on 7 Jan 2020
def as_subclass(self:Tensor, typ):
res = torch.Tensor._make_subclass(typ, self)
if hasattr(self,'__dict__'): res.__dict__ = self.__dict__.copy() ## I added the copy
return res
Otherwise modifying any attribute onreswould also modify it onself(unless that was the intention?)
That is absolutely the intention! :) A cast object should be a reference, not a copy. Note that this is already the behavior you see in _make_subclass:
a = tensor([1,2,3])
class T(Tensor): pass
res = torch.Tensor._make_subclass(T, a)
res[1] = 5
print(res)
tensor([1, 5, 3])
It would be extremely confusing if cast object acted as a reference when it came to their tensor data, but as a copy when it came to its attributes.
jph00
on 7 Jan 2020
Make all implementations of methods on subclasses also go through __torch_function__ by default.
So are you saying, instead of super().__add__ being a valid way to call the parent implementation, you call __torch_function__? Or is this something else? (I apologize if you already described this above but the conversation is pretty long. It might be a good idea to edit the top message with the most up to date proposal for easy access.)
ezyang
on 8 Jan 2020
I mean that all methods that Tensor already has would go through __torch_function__, _even for subclasses_. Concretely, in the example above, SubclassA.__add__ will be _automatically decorated with @torch_function_dispatch_, and we will recommend all subclasses do the same. This would have the desired effect of making super().__add__ go through super().__torch_function__.
hameerabbasi
on 8 Jan 2020
This is the first time you've mentioned torch_function_dispatch in this issue. :)
So, if I understand correctly, what you are proposing is that when you subclass tensor, you are obligated to use a decorator, e.g.,
class SubclassA(Tensor):
@torch_function_dispatch
def __add__(self, other):
...
super().__add__(self)
If this is the case, in what order do I end up calling these functions, if I have multiple subclasses, and __torch_function__ and __add__ defined in both cases? I am still not completely understanding your proposal. It would be helpful if you could post more fleshed out example code, and walk me through what happens in these cases.
ezyang
on 9 Jan 2020
So, for the faulty case, we would replace it with the following code:
def _add_dispatcher(self, other):
return self, other
class SubclassA(torch.Tensor):
@torch_function_dispatch(_add_dispatcher)
def __add__(self, other):
# Do stuff with self, other
temp_result = super().__add__(self_transformed, other_transformed)
# Do stuff with temp_result
return final_result
class SubclassB(SubclassA):
def __torch_function__(self, func, args, kwargs):
# Do stuff with args, kwargs
temp_result = super().__torch_function__(self, func, args_transformed, kwargs_transformed)
# Do stuff with temp_result
return temp_result
What happens is the following:
- We would have a default implementation for each class for
__torch_function__. - Code would dispatch to an implementation if available otherwise the default.
- Suppose
x.__add__is called wheretype(x) is SubclassB. It'll hitSubclassA.__add__. - Which would realise that there are classes other than superclasses of
SubclassAand itself present in the list of arguments, it'll tryself.__torch_function__and thenother.__torch_function_. - So code would go through
SubclassB.__torch_function__ - Transformations would take the form of
t.as_subclass(SubclassA) - When
super().__torch_function__is called it would dispatch toSubclassA.__add__, as appropriate. - Control is passed back to
SubclassB. - Post-processing happens and result is returned.
hameerabbasi
on 14 Jan 2020
I feel there is a step missing before
- So code would go through SubclassB.__torch_function__
I called x.__add__() where x is a SubclassB. By normal Python resolution rules I'll hit SubclassA.__add__ when this happens. Are you saying the dispatch decorator will pass control to to SubclassB.__torch_function__? I'm still not sure how this would work.
ezyang
on 14 Jan 2020
So, think of SubclassA.__add__... It will follow the __torch_function__ protocol. When it realises that there are classes other than superclasses of SubclassA and itself present in the list of arguments, it'll try self.__torch_function__ and then other.__torch_function_. Since you mentioned self is SubclassB, it'll hit SubclassB.__torch_function__.
hameerabbasi
on 15 Jan 2020
One presentational note, we should probably call the code that torch_function_dispatch something distinct from __torch_function__, since it is not the same code at all. I'll call this the "Python dispatcher" for now.
Let me see if I understand what you're saying correctly. Your proposal says:
- Whenever a user calls a method on a Tensor class, we always transfer control to the Python dispatcher first. All built-in methods on Tensor have this functionality, and any explicitly overridden methods on Tensor arrange for this transfer of control via a mandatory decorator (what happens if the user forgets to add this decorator?)
- Once we are in the Python dispatcher, we need to transfer control to the correct user-defined method or
__torch_function__implementation. Similar to how__torch_function__operates from ngoldbaum's PR, we make a decision about the most specific class, and then attempt to invoke the corresponding method in the class (if it exists), or the__torch_function__on that class.
You use super() in your example, but with my recap above I don't see how super can work. A super call will transfer control back to the Python dispatcher, but the Python dispatcher needs to know this time around that we have already "finished" with the most specific class, and we should do something higher in the class hierarchy, but I don't see how you can know that, in the proposal.
ezyang
on 16 Jan 2020
You use
super()in your example, but with my recap above I don't see how super can work. A super call will transfer control back to the Python dispatcher, but the Python dispatcher needs to know this time around that we have already "finished" with the most specific class, and we should do something higher in the class hierarchy, but I don't see how you can know that, in the proposal.
The way NumPy handles this is a types argument in __array_function__, subclasses remove "themselves" from types before calling super()
hameerabbasi
on 23 Jan 2020
I'm also writing an RFC as requested.
hameerabbasi
on 23 Jan 2020
@ezyang @jph00 First draft of the proposal is up. https://github.com/pytorch/rfcs/pull/3
hameerabbasi
on 24 Jan 2020
Related issues
 swecomic
·
59Comments
swecomic
·
59Comments
 bfreskura
·
79Comments
bfreskura
·
79Comments
 JamesOwers
·
61Comments
JamesOwers
·
61Comments
 EMarquer
·
91Comments
EMarquer
·
91Comments
 zym1010
·
189Comments
zym1010
·
189Comments
Most helpful comment
I want to point out another use case of this functionality that surfaced in our conversations with OpenAI. What OpenAI wants to do is insert hooks at a per operator level, so they can inspect the tensors that are flowing through each operation (right now, they are hooking in at the module level, but sometimes there are more fine grained operations they need to hook into).
__torch_function__is tantalizingly close to providing what you need for this, but:Let's make sure we can hit this case too!
cc @suo @orionr @NarineK who were present for this conversation.