Pytorch-lightning: Model alone makes different predictions compared to trainer + model
🐛 Bug
I have trained a model and stored it in a checkpoint file. When I load the model from the checkpoint file and make predictions for my test set I get different results when I use the raw model compared to when I use the trainer class + model.
Problematic code snippets
Using the trainer class
trainer = Trainer(gpus=1)
ckpt_path='/content/gdrive/My Drive/colab_projects/colab_demo/checkpoints/model.ckpt'
model = TransferLearningModel.load_from_checkpoint(str(ckpt_path), **config)
trainer.test(model)
Not using the trainer class
model = TransferLearningModel.load_from_checkpoint(str(ckpt_path), **config)
model.freeze()
model.cuda()
with torch.no_grad():
for x,y in dataloader:
x = x.cuda()
output = model(x)
....
To Reproduce
I have setup a colab notebook which reproduces the bug.
https://drive.google.com/file/d/16Vjcx_-NZ-pBA2mZJRSfytGTmDC8P9xY/view?usp=sharing
Happy to add more information when needed.
 JanRuettinger
JanRuettinger
All 12 comments
it is interesting, that shall not happen, are you using the same data without shuffle?
@SkafteNicki mind have a look at it? :]
 Borda
on 31 Jul 2020
Borda
on 31 Jul 2020
By results, if you are referring to the DataFrames you printed in the notebook, then I think the results looks the same to me.
 rohitgr7
on 1 Aug 2020
rohitgr7
on 1 Aug 2020
Could it be not running model = model.eval() when not using trainer class.
eval() does more than freeze, it uses overall mean and std for batchnorm instead of running mean and std. Also it will turn off the dropout.
 raynardj
on 3 Aug 2020
raynardj
on 3 Aug 2020
@raynardj model.freeze() does that automatically I think.
rohitgr7
on 3 Aug 2020
@raynardj
model.freeze()does that automatically I think.
u r right, eval() is there.
I also took a close look at the comparison of 2 dataframe and they r the same
raynardj
on 3 Aug 2020
@rohitgr7 @raynardj @Borda @SkafteNicki Any update on this issue?
I am facing a similar behavior in my prediction.
 agemagician
on 4 Aug 2020
agemagician
on 4 Aug 2020
@agemagician Can you share code sample we can look at?
rohitgr7
on 4 Aug 2020
@rohitgr7 Sure, I will write a Colab notebook for my code and share it, but did you figure out the problem from the above-shared notebook?
agemagician
on 4 Aug 2020
Not yet. We still don't find the results that are referred in the notebook by author. If the results are the dataframes then both are same. There is no difference in final prediction.
rohitgr7
on 4 Aug 2020
@agemagician Can you share code sample we can look at?
this is the notebook above - https://colab.research.google.com/drive/16Vjcx_-NZ-pBA2mZJRSfytGTmDC8P9xY
Borda
on 4 Aug 2020
After implementing the code again in Colab, I figured out the problem.
In my case, the input pipeline for test and prediction was different and that's why I didn't get the same results.
agemagician
on 5 Aug 2020
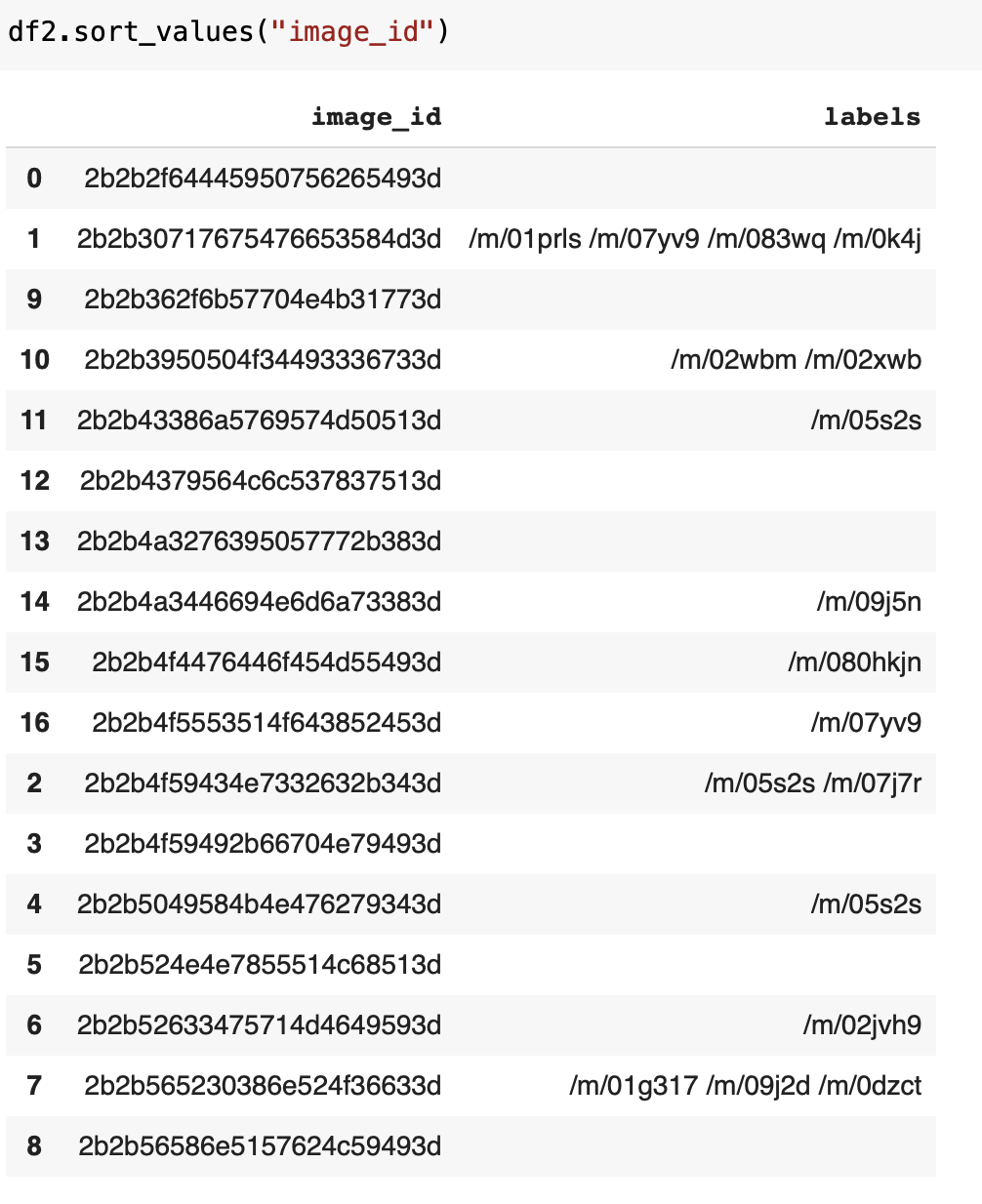
@raynardj the results I get are not the same as you can see in the two pictures below. They are similar but not the same. Do you have any pointers where to look for errors?

JanRuettinger
on 6 Aug 2020
Related issues
 awaelchli
·
3Comments
awaelchli
·
3Comments
 maxime-louis
·
3Comments
maxime-louis
·
3Comments
 edenlightning
·
3Comments
edenlightning
·
3Comments
 Vichoko
·
3Comments
Vichoko
·
3Comments
 anthonytec2
·
3Comments
anthonytec2
·
3Comments