Pytorch-lightning: Reproducibility issue.
I am a newbee in using pytorch and pytorch-lightning. My code is to classify the "Sequential" MNIST image, where 4 pixels are fed into the LSTM cell for each time step and one image is processed in 28*28/4 time steps. Since I provide a seed by pytorch_lightning.utilities.seed.seed_everything, same result is expected for each training, but I see every different result as below. Could you please help me to revise my code to behave correctly?
My environment: Linux python 3.7, pytorch 1.5.1, pytorch_lightning 0.8.1
import os
import torch
import pytorch_lightning
import torch.nn as nn
from torch.nn import functional as F
from torch.utils.data import DataLoader, random_split
from torchvision.datasets import MNIST
from torchvision import transforms
from pytorch_lightning.core.lightning import LightningModule
from pytorch_lightning.core.memory import ModelSummary
from pytorch_lightning.metrics.functional import accuracy
pytorch_lightning.utilities.seed.seed_everything(2)
INPUT_SIZE = 4
TIME_STEP = int(28*28/INPUT_SIZE)
HIDDEN_SIZE = 100
NUM_LAYERS = 1
DROPOUT = 0.1 if NUM_LAYERS > 1 else 0
BATCH_SIZE = 128
NUM_WORKERS = 8
LEARNING_RATE = 1e-3
MAX_EPOCHS = 30
class Model(LightningModule):
def __init__(self, hparams):
super().__init__()
self.hparams = hparams
self.rnn = nn.LSTM(input_size=self.hparams.input_size,
hidden_size=self.hparams.hidden_size,
num_layers=self.hparams.num_layers,
dropout=self.hparams.dropout,
batch_first=True)
self.fc = nn.Linear(in_features=self.hparams.hidden_size, out_features=10)
def forward(self, x):
r_out, _ = self.rnn(x, None)
return self.fc(r_out[:, -1, :])
def training_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
tensorboard_logs = {'train_loss': loss}
return {'loss': loss, 'log': tensorboard_logs}
def validation_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
acc = accuracy(torch.argmax(y_hat, dim=1), batch[1])
return {'val_loss': loss, 'val_acc': acc}
def validation_epoch_end(self, outputs):
avg_loss = torch.stack([x['val_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['val_acc'] for x in outputs]).mean()
tensorboard_logs = {'val_loss': avg_loss, 'val_acc': avg_acc}
return {'val_loss': avg_loss, 'log': tensorboard_logs}
def test_step(self, batch, batch_idx):
x, y = batch
y_hat = self(x)
loss = F.cross_entropy(y_hat, y)
acc = accuracy(torch.argmax(y_hat, dim=1), batch[1])
return {'test_loss': loss, 'test_acc': acc}
def test_epoch_end(self, outputs):
avg_loss = torch.stack([x['test_loss'] for x in outputs]).mean()
avg_acc = torch.stack([x['test_acc'] for x in outputs]).mean()
tensorboard_logs = {'test_loss': avg_loss, 'test_acc': avg_acc}
return {'test_loss': avg_loss, 'log': tensorboard_logs}
def prepare_data(self):
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,)),
transforms.Lambda(lambda x: x.view(-1, self.hparams.input_size))])
mnist_train = MNIST(os.getcwd(), train=True, download=True, transform=transform)
mnist_test = MNIST(os.getcwd(), train=False, download=True, transform=transform)
self.mnist_train, self.mnist_val = random_split(mnist_train, [55000, 5000])
self.mnist_test = mnist_test
def train_dataloader(self):
return DataLoader(self.mnist_train, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
def val_dataloader(self):
return DataLoader(self.mnist_val, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
def test_dataloader(self):
return DataLoader(self.mnist_test, batch_size=self.hparams.batch_size, num_workers=self.hparams.num_workers)
def configure_optimizers(self):
optim = torch.optim.Adam(self.parameters(), lr=self.hparams.learning_rate)
sched = torch.optim.lr_scheduler.StepLR(optim, step_size=10, gamma=0.1)
return [optim], [sched]
from pytorch_lightning import Trainer
from pytorch_lightning.callbacks import EarlyStopping
from pytorch_lightning import loggers as pl_loggers
from pytorch_lightning.callbacks import LearningRateLogger
from pytorch_lightning.utilities.parsing import AttributeDict
trainer = Trainer(max_epochs=MAX_EPOCHS,
gpus=1,
num_nodes=1,
callbacks=[LearningRateLogger()],
early_stop_callback=EarlyStopping(patience=3, monitor='val_loss', mode='min', verbose=True))
model = Model(hparams = AttributeDict({'batch_size': BATCH_SIZE,
'num_workers': NUM_WORKERS,
'learning_rate': LEARNING_RATE,
'input_size': INPUT_SIZE,
'time_step': TIME_STEP,
'hidden_size': HIDDEN_SIZE,
'num_layers': NUM_LAYERS,
'dropout': DROPOUT}))
trainer.fit(model)
trainer.test()

 THKIM-CAS
THKIM-CAS
All 8 comments
Hi! thanks for your contribution!, great first issue!
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 25 Jun 2020
github-actions[bot]
on 25 Jun 2020
Hi! I ran the same code what you uploaded, but in my environment works as expected
run shell
python run.py
python run.py

can you share more details for reproducing the problem?
- run script (like run shell, command, etc)
- HW details
You can get the script and run it with:
wget https://raw.githubusercontent.com/PyTorchLightning/pytorch-lightning/master/tests/collect_env_details.py
# For security purposes, please check the contents of collect_env_details.py before running it.
python collect_env_details.py
 davinnovation
on 25 Jun 2020
davinnovation
on 25 Jun 2020
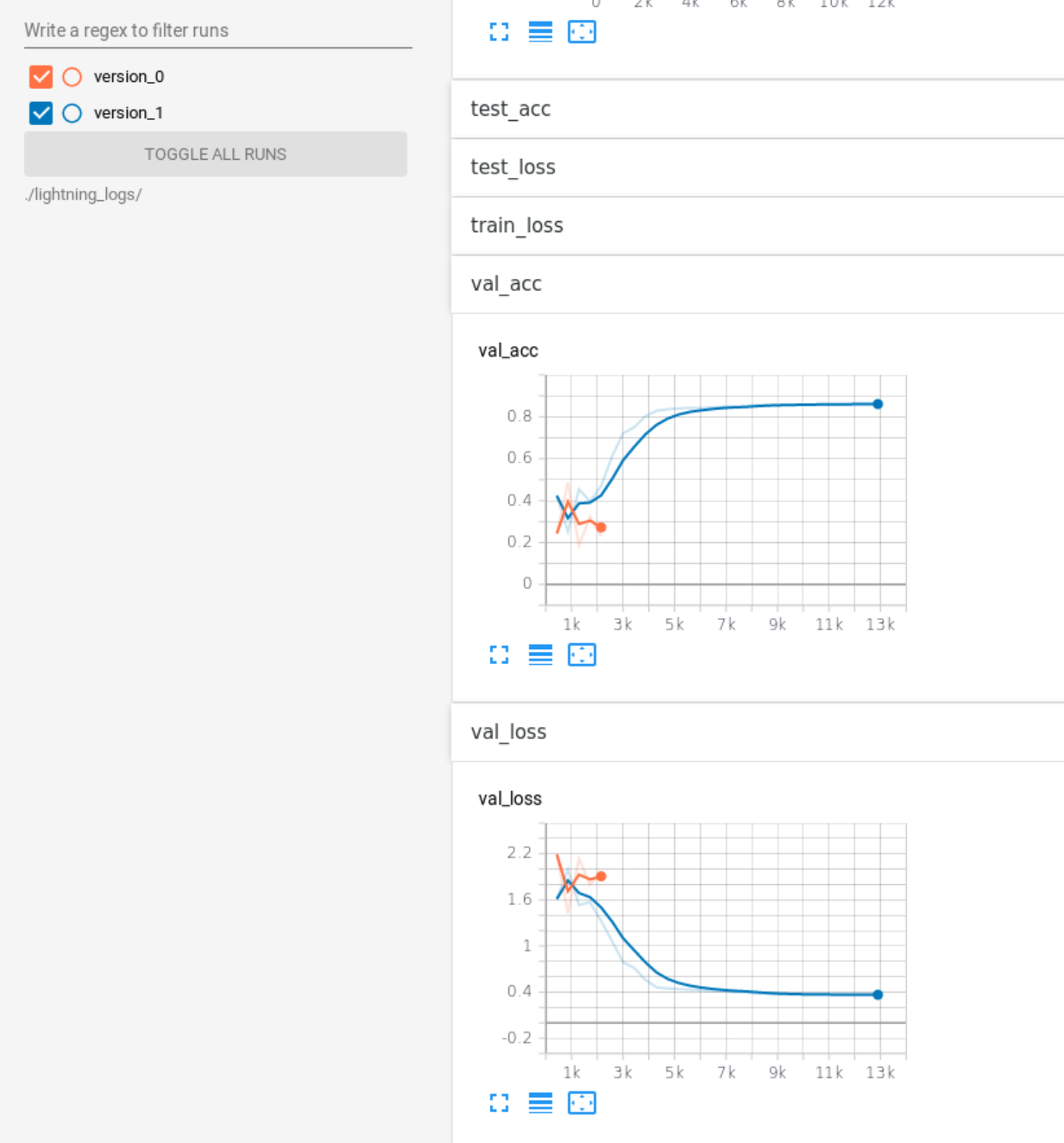
@davinnovation Thank for your kind help. I tried again but the results are still different for each training.
python3.7 seq_mnist_rnn.py
python3.7 seq_mnist_rnn.py
The result from collect_env_details.py is as follows:
* CUDA:
- GPU:
- GeForce RTX 2080 Ti
- GeForce RTX 2080 Ti
- available: True
- version: 10.2
* Packages:
- numpy: 1.16.4
- pyTorch_debug: False
- pyTorch_version: 1.5.1
- pytorch-lightning: 0.8.1
- tensorboard: 2.2.2
- tqdm: 4.46.1
* System:
- OS: Linux
- architecture:
- 64bit
- ELF
- processor: x86_64
- python: 3.7.3
- version: #1 SMP Tue Feb 4 23:02:59 UTC 2020
* CUDA:
- GPU:
- GeForce GTX 1080 Ti
- GeForce GTX 1080 Ti
- GeForce GTX 1080 Ti
- GeForce GTX 1080 Ti
- available: True
- version: 10.2
* Packages:
- numpy: 1.16.4
- pyTorch_debug: False
- pyTorch_version: 1.5.1
- pytorch-lightning: 0.8.1
- tensorboard: 1.14.0
- tqdm: 4.46.1
* System:
- OS: Linux
- architecture:
- 64bit
-
- processor: x86_64
- python: 3.7.4
- version: #88~16.04.1-Ubuntu SMP Wed Feb 12 04:19:15 UTC 2020
Tried which same as your env - except GPU/python3.7.4/TB. Unfortunately, I can't reproduce your problem. May be code isn't causing the problem, what about run your code in another machine?
Or suggest set NUM_WORKERS as 0. Actually pytorch-lightning seed_everything deals it, but just in case
davinnovation
on 25 Jun 2020
This is likely something with your environment... make sure you are using conda and install things properly there.
See the related issue: https://github.com/PyTorchLightning/pytorch-lightning/issues/1868
If problem persists, please create a colab that reproduces this then reopen this issue
 williamFalcon
on 25 Jun 2020
williamFalcon
on 25 Jun 2020
Thanks @davinnovation and @williamFalcon for your consideration of my issue.
I found that my code shows the same results for every training in CPU without any problems of the reproducibility; but different results for every training in GPU as shown above.
THKIM-CAS
on 26 Jun 2020
Is the issue due to a missing torch.cuda.manual_seed as well @williamFalcon ?
 vibhavagarwal5
on 28 Jun 2020
vibhavagarwal5
on 28 Jun 2020
Thanks @davinnovation and @williamFalcon for your consideration of my issue.
I found that my code shows the same results for every training in CPU without any problems of the reproducibility; but different results for every training in GPU as shown above.
There are known non-determinism issues for RNN functions on some versions of cuDNN and CUDA. You can enforce deterministic behavior by setting the following environment variables:
On CUDA 10.1, set environment variable CUDA_LAUNCH_BLOCKING=1. This may affect performance.
On CUDA 10.2 or later, set environment variable (note the leading colon symbol) CUBLAS_WORKSPACE_CONFIG=:16:8 or CUBLAS_WORKSPACE_CONFIG=:4096:2.
See the cuDNN 8 Release Notes for more information.
 NickYi1990
on 22 Oct 2020
NickYi1990
on 22 Oct 2020
Related issues
 chuong98
·
3Comments
chuong98
·
3Comments
 iakremnev
·
3Comments
iakremnev
·
3Comments
 edenlightning
·
3Comments
edenlightning
·
3Comments
 justusschock
·
3Comments
justusschock
·
3Comments
 polars05
·
3Comments
polars05
·
3Comments