Pytorch-lightning: custom training with 0.8.0.dev0 gives import error
Due to another issue and the advise to upgrade to master, I upgraded to 0.8.0.dev0. Now, the same model and no code changes gives the error:
Traceback (most recent call last):
File "/home/luca/project/apps/train_siamnet.py", line 3, in <module>
from ..models.siamnet import SiameseNet
ImportError: attempted relative import with no known parent package
This did not happen before and does not make sense TBH as there is no such invalid import.
After that, the thing just hangs during GGPus initialising phase:
initializing ddp: LOCAL_RANK: 0/3 WORLD_SIZE:4
I am trying to train my model on multiple GPUs and the training code is:
model = SiameseNet(hparams)
if torch.cuda.is_available():
trainer = Trainer(gpus=-1, distributed_backend='ddp')
else:
trainer = Trainer()
trainer.fit(model)
The model def is:
class SiameseNet(pl.LightningModule):
"""
Implement a siamese network as a feature extractor withh Lightning module
"""
def __init__(self,
hparams):
"""
Build the network
"""
super(SiameseNet, self).__init__()
self.net = self._build_net()
self.hparams = hparams
self.train_data_path = hparams.get('train_data_path', None)
self.test_data_path = hparams.get('test_data_path', None)
self.val_data_path = hparams.get('val_data_path', None)
self.train_dataset = None
self.val_dataset = None
self.test_dataset = None
self.lossfn = TripletLoss(margin=1.0)
def forward_once(self, x):
output = self.net(x)
output = torch.squeeze(output)
return output
def forward(self, input1, input2, input3=None):
output1 = self.forward_once(input1)
output2 = self.forward_once(input2)
if input3 is not None:
output3 = self.forward_once(input3)
return output1, output2, output3
return output1, output2
@staticmethod
def _build_net():
net = nn.Sequential(
nn.Conv2d(3, 32,kernel_size=3,stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(32),
nn.Conv2d(32, 64, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(64),
nn.Conv2d(64, 128, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(128),
nn.Conv2d(128, 256, kernel_size=1, stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(256),
nn.Conv2d(256, 256, kernel_size=1, stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(256),
nn.Conv2d(256, 512, kernel_size=3, stride=2),
nn.ReLU(inplace=True),
nn.BatchNorm2d(512),
nn.Conv2d(512, 1024, kernel_size=1, stride=1),
nn.ReLU(inplace=True),
nn.BatchNorm2d(1024))
return net
def prepare_data(self):
transform = torchvision.transforms.Compose([
torchvision.transforms.Resize((128, 128)),
torchvision.transforms.ColorJitter(hue=.05, saturation=.05),
torchvision.transforms.RandomHorizontalFlip(),
torchvision.transforms.RandomRotation(20, resample=PIL.Image.BILINEAR),
torchvision.transforms.ToTensor()
])
if self.train_data_path:
train_folder_dataset = dset.ImageFolder(root=self.train_data_path)
self.train_dataset = SiameseTriplet(image_folder_dataset=train_folder_dataset,
transform=transform)
if self.val_data_path:
val_folder_dataset = dset.ImageFolder(root=self.val_data_path)
self.val_dataset = SiameseTriplet(image_folder_dataset=val_folder_dataset)
if self.test_data_path:
test_folder_dataset = dset.ImageFolder(root=self.test_data_path)
self.test_dataset = SiameseTriplet(image_folder_dataset=test_folder_dataset)
def training_step(self, batch, batch_idx):
anchor, positive, negative = batch
anchor_out, positive_out, negative_out = self.forward(anchor, positive, negative)
loss_val = self.lossfn(anchor_out, positive_out, negative_out)
return {'loss': loss_val}
def configure_optimizers(self):
optimizer = optim.Adam(self.parameters(), lr=self.hparams.get('learning_rate', 0.001))
scheduler = optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=10)
return [optimizer], [scheduler]
@pl.data_loader
def train_dataloader(self):
if self.train_dataset:
return DataLoader(self.train_dataset,
self.hparams.get('batch_size', 64),
num_workers=12)
return None
 pamparana34
pamparana34
All 21 comments
bump anyone? this seems like a major issue where multi GPU or even single Gpu training does not seem to work for this simple case.
pamparana34
on 5 Jun 2020
how are you executing the script?
sounds like your import paths are wrong.
make sure your imports are correct. ie:
call python your_script.py on the command line to make sure it works. the error says that your module is not configured properly to run.
 williamFalcon
on 5 Jun 2020
williamFalcon
on 5 Jun 2020
The import path is correct. In fact, 0.7.6 does not report any errors and runs it although it's very slow and hence my desire to upgrade to master
pamparana34
on 5 Jun 2020
could you share your directory structure?
it’s slow on 0.7.6 because of an issue between dataloaders and ddp. 0.8.0 does it differently now, but your use of relative paths is causing issues
williamFalcon
on 5 Jun 2020
@williamFalcon In 0.8.0-dev what is the best way to call the training script? Here is my folder structure:
repo:
project:
train.py
models/
model.py
bash_scripts/
tarin_bash.sh
train_bash.sh contains the train.py execution command python3 ../train.py [args]
I tried this approach with the folder structure, and it doesn't work.
Also, I tried another approach: move the train_bash.sh to the project folder and modify the execution command to python3 train.py [args]. It also gives me an error.
Surprisingly, both times the error is trying to find the train.py script in the repo folder instead of the project folder.
 mmiakashs
on 8 Jun 2020
mmiakashs
on 8 Jun 2020
So here is my project structure:
All sub-directories and project are python modules.
project:
+apps
-train_siamnet.py
+deep
+pytorch
+models
-siamnet.py
The train_siamnet imports as from ..deep.pytorch.models.siamnet import SiameseNet.
The thing is this works does not complain with 0.7.6. The script is involved from just above project as:
python -m project.apps.train_siamneet
@williamFalcon Any update or suggestion on this?
pamparana34
on 9 Jun 2020
@pamparana34 mind try absolute imports as it is also recommended by PEP
 Borda
on 11 Jun 2020
Borda
on 11 Jun 2020
@williamFalcon In 0.8.0-dev what is the best way to call the training script? Here is my folder structure:
repo: project: train.py models/ model.py bash_scripts/ tarin_bash.sh
train_bash.shcontains the train.py execution commandpython3 ../train.py [args]
I tried this approach with the folder structure, and it doesn't work.
Also, I tried another approach: move the train_bash.sh to the project folder and modify the execution command topython3 train.py [args]. It also gives me an error.
Surprisingly, both times the error is trying to find the train.py script in the repo folder instead of the project folder.
@Borda I used absolute imports but it looks like when I tried to execute the train bash script the ddp subprocess looks the train.py inside the repo folder instead of inside the project folder. I am a little bit confused why the ddp sub-process looks into repo folder instead of project folder for the train.py
mmiakashs
on 11 Jun 2020
you can simply add extra path
import sys, os
sys.path += [os.path.abspath('..')]
or another path you need with relation to the executed file
sys.path += [os.path.dictionary(__file__)]
@Borda This path needs to be added to train.py file?
pamparana34
on 11 Jun 2020
@Borda This path needs to be added to
train.pyfile?
to the entry point so if you execute python3 ../train.py [args] then to ../train.py before all imports
Borda
on 11 Jun 2020
I am sorry but I still get this error:
ImportError: attempted relative import with no known parent package
I added
import sys
import os
sys.path += [os.path.abspath('..')]
at the top of train_siamnet.py. I am pulling my hair over this. I cannot change to absolute paths as this will require a lot of other changes that might break many other things but I really have no clue why this error crops up now and not with the previous version.
pamparana34
on 12 Jun 2020
By following @williamFalcon suggestions, I used ddp_spawn instead of ddp mode. Without changing any of my previous code, it works perfectly with 0.8.0rc1 PL :)
However, I am not sure about how to structure the project to use the recent faster ddp mode, which is introduced in 0.8.0rc1. Because I was facing problem to use argparser to send some arguments to the training script. If I use only one GPU in ddp mode then it was working fine. However, if I switch to mutli-GPUs then it couldn't able to parse the arguments appropriately. As in the ddp mode the training script called multiple times, it seems to me that first time the arguments are parsed properly but the subsequent calls the arguments couldn't able to pass properly.
mmiakashs
on 12 Jun 2020
@mmiakashs Oh nice. So I bit the bullet and converted to absolute paths but... then I now get the following error:
train_siamnet.py: error: unrecognized arguments: --gpus 4
I am guessing this is similar to what you are experiencing? I think it seems to be having issues with the command line arguments. I do not even pass this --gpus argument. This is somehow added by PL and being passed back to the training script, which is barfing as it does not expect it.
pamparana34
on 12 Jun 2020
yeah, check out the docs which explain how the new faster ddp works.
https://pytorch-lightning.readthedocs.io/en/latest/multi_gpu.html#distributed-data-parallel
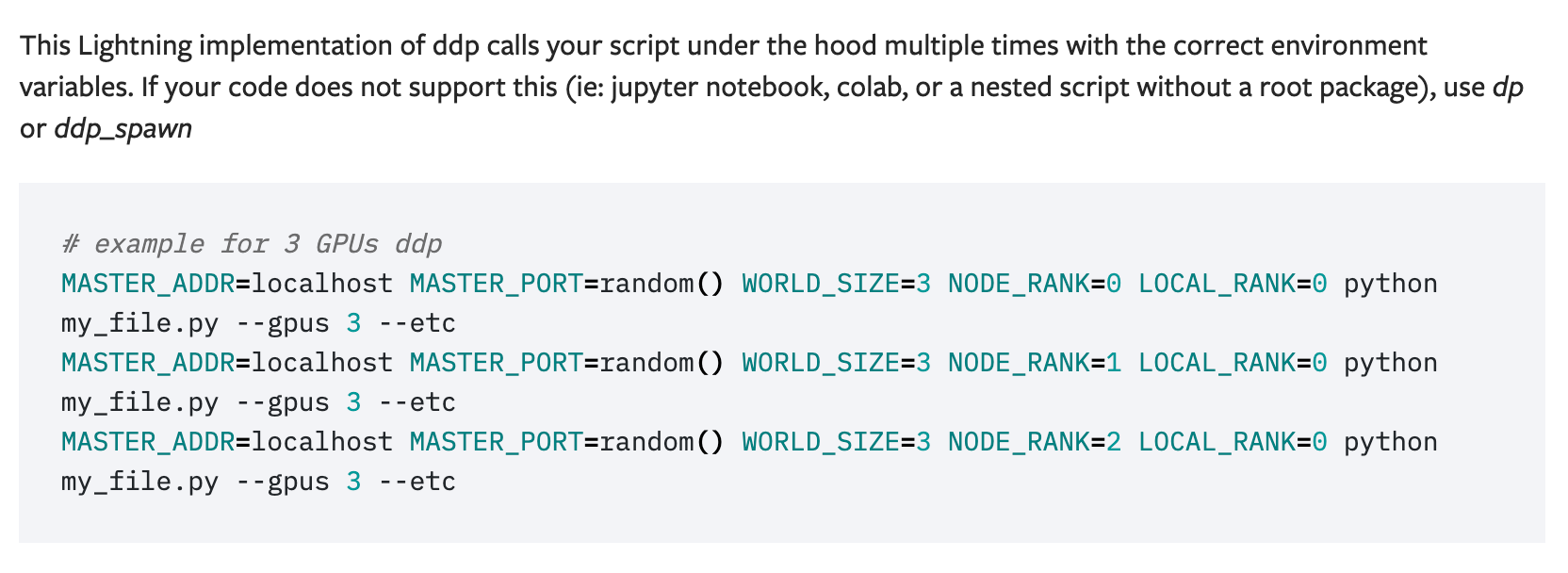
williamFalcon
on 12 Jun 2020
I also faced this error. Once training with ddp starts, it hangs and is unresponsive to even Ctrl-C. Training with ddp_spawn works fine though.
I solved it by switching to absolute import paths, as suggested above. Thanks!
shell script
Traceback (most recent call last):
File "/home/<redacted>/seg_lapa/seg_lapa.py", line 9, in <module>
from .networks.deeplab.deeplab import DeepLab
ImportError: attempted relative import with no known parent package
Any insights on why relative imports fail for ddp and if the package structure can be modified to fix it?
 Shreeyak
on 19 Oct 2020
Shreeyak
on 19 Oct 2020
Please upgrade to 1.0
Borda
on 19 Oct 2020
I am on pytorch-lightning 1.0.2, pytorch 1.6.0
Shreeyak
on 19 Oct 2020
@Shreeyak mind opening a new issue> this is a bit confusing is this issue refers to quite an old version...
Borda
on 19 Oct 2020
(for other's ref) Created new issue: https://github.com/PyTorchLightning/pytorch-lightning/issues/4243
Shreeyak
on 20 Oct 2020
Related issues
 justusschock
·
3Comments
justusschock
·
3Comments
 awaelchli
·
3Comments
awaelchli
·
3Comments
 srush
·
3Comments
williamFalcon
·
3Comments
srush
·
3Comments
williamFalcon
·
3Comments
 iakremnev
·
3Comments
iakremnev
·
3Comments
Most helpful comment
yeah, check out the docs which explain how the new faster ddp works.
https://pytorch-lightning.readthedocs.io/en/latest/multi_gpu.html#distributed-data-parallel