Pytorch-lightning: Add stochastic weight averaging
Looks like we need to keep two copies of the model. Let $m_r$ define the root model and $m_c$ the current model. Then at the end of each epoch $n$, we update the weights of $m_r$ using a weighted average:
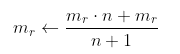
Anyone interested in implementing?
maybe enable as a callback? not sure this needs a flag?
@PyTorchLightning/core-contributors
 williamFalcon
williamFalcon
All 9 comments
Isnt SWA already in PyTorch master? https://github.com/pytorch/pytorch/pull/35032
 KeAWang
on 26 May 2020
KeAWang
on 26 May 2020
So using torchcontrib.optim.SWA is relatively simple. Just wrap it around your base optimizer(s) in the configure_optimizers method.
The only tricky part would be that opt.swap_swa_sgd() needs to be called at training_epoch_end. What is the ideal way to do this? We should have access to optimizers using self.trainer.optimizers ... at which point, one would need to iterate the list and check if any of them are an instance of torchcontrib.optim.SWA and invoke opt.swap_swa_sgd() on them.
def configure_optimizers(self):
optimizer = AdamW(self.parameters(), lr=1e-3, weight_decay=0.001)
optimizer = torchcontrib.optim.SWA(optimizer, swa_start=10, swa_freq=5)
return [optimizer]
def training_epoch_end(self, outputs):
for opt in self.trainer.optimizers:
if not type(opt) is torchcontrib.optim.SWA:
continue
opt.swap_swa_sgd()
return {}
 authman
on 29 May 2020
authman
on 29 May 2020
I have the entirety of "Stochastic Weight Averaging Gaussian" or "SWAG" implemented in Lightning (the extended version of SWA): https://arxiv.org/abs/1902.02476. It's a different approach than just switching optimizers though. I'm not sure if it's more pythonic or less.
It records the average parameters, the average squared parameters, along with a a small number of recent weights to estimate the covariance of the weight posterior mode the optimizer currently sits in.
I'm not sure the best way of implementing it, but right now, I have a second "SWAG" model that inherits the first model (since SWA requires a pretrained model), and does SGD. I feel like this is the way to do it because the learning schedules are completely different, and you only do SWA after you have tuned your original model; but at the same time, you do want the same model, dataloader, augmentation, loss function, etc. So inheritance seems a decent way of implementing it: maybe inherit pl.LightningModule for the regular one, then inherit from that & a pl.SWAGLightningModule for the averaged one.
My current workflow, which should probably be refactored:
- First model is a pl.LightningModule that you train normally. Call it
MyModel - Second model is the SWAG variation, that inherits
MyModel. It doesn't have it's own initialization function. Call itMyModelSWAG - You initialize the second model with
model = MyModelSWAG.load_from_checkpoint(checkpoint_path). - You then call
model.init_swag(swag_hparams)to record the SWAG hyperparameters. - You then train this model with a new Trainer.
Then, I add these functions:
- Common:
- Model function
flat_state_dictconverts the current model's state dict to a 1D vector and returns it. - Model function
load_tensor_as_state_dictis the opposite: it takes a 1D vector and uses it to set the model's state dict. - Model function
swag_aggregate_modelusesflat_state_dictto update the average parameters and square parameters, and records the current weights, and then removes 1 set of old weights if you have greater thanKnumber recorded (part of SWAG is they store several old weights to estimate Gaussian covariance at the end). - I write a
swa_forwardto load the average parameters withload_tensor_as_state_dict, callforwardon the average parameters, and then load back the current parameters. - I write a
swag_forwardto sample parameters using the average weight, average square weight, and an estimate of the Gaussian covariance. It then usesload_tensor_as_state_dicton the parameters, callsforwardthen loads back the current parameters.
- Model function
- Functions the user needs to write:
- I rewrite
configure_optimizersto use a constant learning rate schedule, and SGD. This should load the parameters entered ininit_swag. - I rewrite my version of
validation_stepto use the average parameters for validation loss: it callsswag_aggregate_model, and then measures the validation loss usingswa_forward. But the user should write this themselves to record different statistics here, or if they'd like to record the validation loss of the current weights.
- I rewrite
In practice, one could use swa_forward to use the average parameters for prediction, or swag_forward to randomly sample weights and make a prediction using that sample.
Let me know what you think of this structure and if I should share some code for a lightning implementation.
Cheers,
Miles
 MilesCranmer
on 12 Jul 2020
MilesCranmer
on 12 Jul 2020
I think for now, we could go and add this to bolts.
 justusschock
on 13 Jul 2020
justusschock
on 13 Jul 2020
hi @MilesCranmer this is really cool!
Mind waiting a few weeks since we need to wrap up the v1 before adding this? the main reason is that we are focused on improving the stability of PL and don't want to add big features that might affect this.
williamFalcon
on 23 Jul 2020
Sure, no problem!
And happy to add to bolts instead if preferred. I'm curious: when does an algorithm move from bolts to the main framework? Though generally applicable to any NN, I don't think SWA/SWAG/MultiSWAG have found popular use yet. But at least SWA (=Stochastic Weight Averaging) seems like such a simple yet powerful strategy - you just average the weights in a final segment of training and get better loss - that maybe it would be good to eventually embed in the main trainer as a flagged option.
MilesCranmer
on 25 Jul 2020
Hi! Did anyone managed to make SWA work with lightning?
We tried to move our training from custom code to Pytorch lightning and SWA causes problems in migration. We use torchcontrib.optim.SWA implementation. I first wrapped my optimizer in cofigure_optimizers:
base_optimizer = AdamW(param_groups, ...)
optimizer = SWA(base_optimizer)
And then I swap_swa_sgd before and after validation cycles:
def on_pre_performance_check(self) -> None:
if self.current_epoch > 0:
for opt in self.trainer.optimizers:
if isinstance(opt, SWA):
opt.update_swa()
opt.swap_swa_sgd()
opt.bn_update(self.train_dataloader(), self.model, device=self.device)
def on_post_performance_check(self) -> None:
if self.current_epoch > 0:
for opt in self.trainer.optimizers:
if isinstance(opt, SWA):
opt.swap_swa_sgd()
 zerogerc
on 13 Aug 2020
zerogerc
on 13 Aug 2020
Any update on the issue? What's the most idiomatic way to approach this?
 sakvaua
on 7 Oct 2020
sakvaua
on 7 Oct 2020
This issue has been automatically marked as stale because it hasn't had any recent activity. This issue will be closed in 7 days if no further activity occurs. Thank you for your contributions, Pytorch Lightning Team!
![stale[bot] picture](https://avatars3.githubusercontent.com/in/1724?v=4&s=40) stale[bot]
on 6 Nov 2020
stale[bot]
on 6 Nov 2020
Related issues
 polars05
·
3Comments
polars05
·
3Comments
 remisphere
·
3Comments
remisphere
·
3Comments
 as754770178
·
3Comments
williamFalcon
·
3Comments
as754770178
·
3Comments
williamFalcon
·
3Comments
 awaelchli
·
3Comments
awaelchli
·
3Comments
Most helpful comment
Any update on the issue? What's the most idiomatic way to approach this?