Pytorch-lightning: CUDA out of memory
I set Cuda to 5
INFO:lightning:CUDA_VISIBLE_DEVICES: [5]
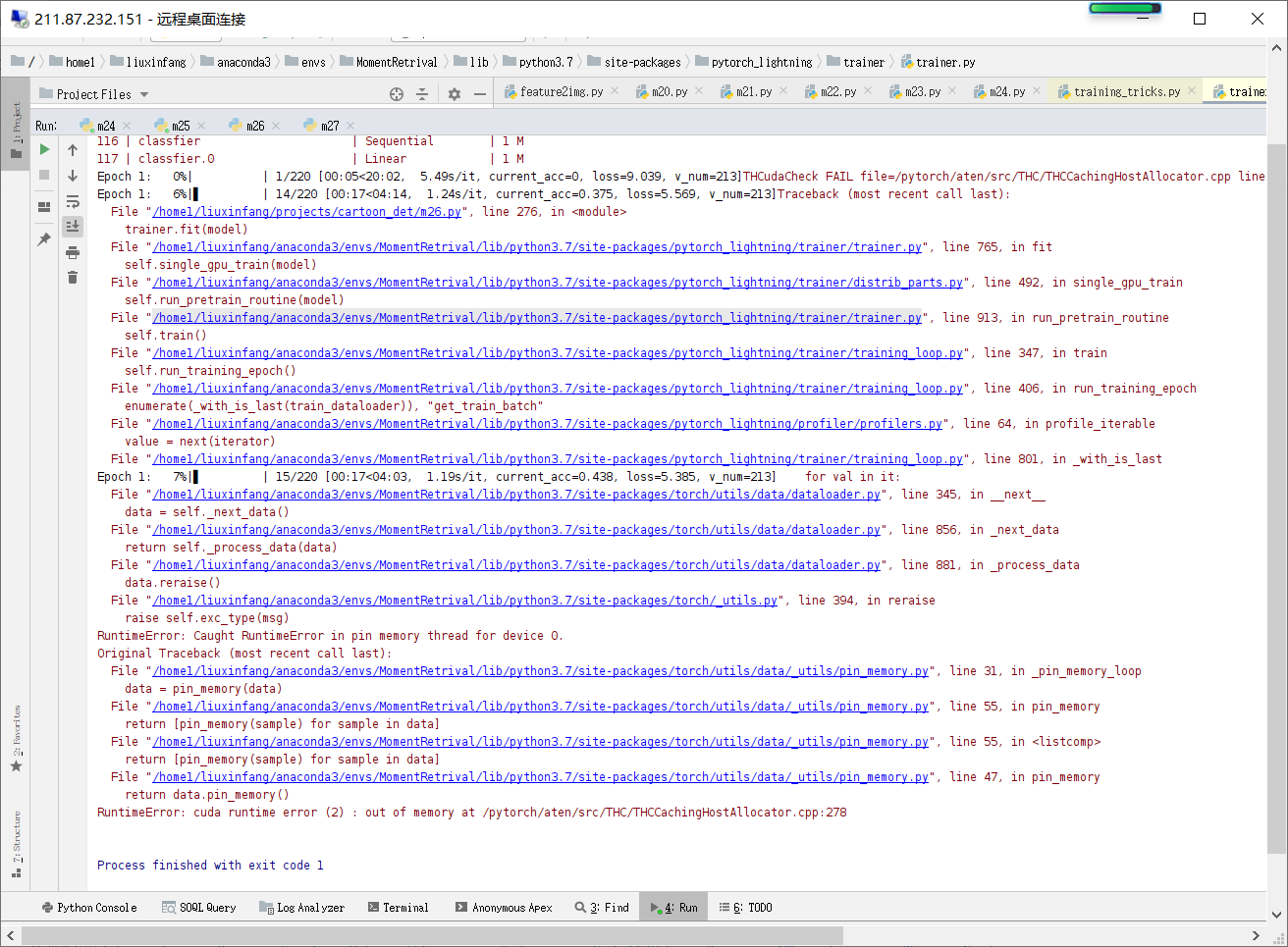
however, there always a small part of the memory in gpu 0, when gpu 0 has not enough memory, error is produced.

in the img you can see that two processes is running on gpu5,6 and 2 * 577M is running gpu0.
I want the processes to only use what GPU I set.
 xinfangliu
xinfangliu
All 6 comments
m24.py
xinfangliu
on 2 May 2020
I have this same issue as well, it happens regardless of memory pinning
 jiahuei
on 10 May 2020
jiahuei
on 10 May 2020
I am using this as a temporary fix
if __name__ == "__main__":
args = parse_arguments()
os.environ['CUDA_DEVICE_ORDER'] = 'PCI_BUS_ID'
os.environ['CUDA_VISIBLE_DEVICES'] = ','.join(map(str, args.gpus))
args.gpus = list(range(len(args.gpus)))
...
trainer = pl.Trainer(gpus=args.gpus)
However, if I call torch.cuda.device_count() beforehand like so, the issue still occurs. There might be something that occurred when device_count is called.
if len(args.gpus) != torch.cuda.device_count():
os.environ['CUDA_VISIBLE_DEVICES'] = ','.join(map(str, args.gpus))
args.gpus = list(range(len(args.gpus)))
you shall user batch side finder
 Borda
on 26 Jun 2020
Borda
on 26 Jun 2020
can you try running on master? and also decrease your batch size?
 williamFalcon
on 26 Jun 2020
williamFalcon
on 26 Jun 2020
can you try running on master? and also decrease your batch size?
It has no matter with the batch size, I solved the problem with torch.cuda.set_device(6)
xinfangliu
on 26 Jun 2020
Related issues
 monney
·
3Comments
monney
·
3Comments
 awaelchli
·
3Comments
awaelchli
·
3Comments
 versatran01
·
3Comments
versatran01
·
3Comments
 iakremnev
·
3Comments
williamFalcon
·
3Comments
iakremnev
·
3Comments
williamFalcon
·
3Comments