Pytorch-lightning: neptune.ai logger console error: X-coordinates must be strictly increasing
🐛 Bug
When using the neptune.ai logger, epochs automatically get logged, even though I never explicitly told it to do so. Also, I get an error, yet everything seems to get logged correctly (apart from the epochs, which also get logged every training step and not every epoch):
WARNING:neptune.internal.channels.channels_values_sender:Failed to send channel value: Received batch errors sending channels' values to experiment BAC-32. Cause: Error(code=400, message='X-coordinates must be strictly increasing for channel: 2262414e-e5fc-4a8f-b3f8-4a8d84d7a5e2. Invalid point: InputChannelValue(2020-03-18T17:18:04.233Z,Some(164062.27599999998),None,Some(Epoch 35: 99%|#######', type=None) (metricId: '2262414e-e5fc-4a8f-b3f8-4a8d84d7a5e2', x: 164062.27599999998) Skipping 3 values.
To Reproduce
Steps to reproduce the behavior:
Write a lightning module and use the neptune.ai logger. See my own code below.
Code sample
class MemoryTest(pl.LightningModule):
# Main Testing Unit for Experiments on Recurrent Cells
def __init__(self, hp):
super(MemoryTest, self).__init__()
self.predict_col = hp.predict_col
self.n_datasamples = hp.n_datasamples
self.dataset = hp.dataset
if self.dataset is 'rand':
self.seq_len = None
else:
self.seq_len = hp.seq_len
self.hparams = hp
self.learning_rate = hp.learning_rate
self.training_losses = []
self.final_loss = None
self.model = RecurrentModel(1, hp.n_cells, hp.n_layers, celltype=hp.celltype)
def forward(self, input, input_len):
return self.model(input, input_len)
def training_step(self, batch, batch_idx):
x, y, input_len = batch
features_y = self.forward(x, input_len)
loss = F.mse_loss(features_y, y)
mean_absolute_loss = F.l1_loss(features_y, y)
self.training_losses.append(mean_absolute_loss.item())
tensorboard_logs = {'batch/train_loss': loss, 'batch/mean_absolute_loss': mean_absolute_loss}
return {'loss': loss, 'batch/mean_absolute_loss': mean_absolute_loss, 'log': tensorboard_logs}
def on_epoch_end(self):
train_loss_mean = np.mean(self.training_losses)
self.final_loss = train_loss_mean
self.logger.experiment.log_metric('epoch/mean_absolute_loss', y=train_loss_mean, x=self.current_epoch)
self.training_losses = [] # reset for next epoch
def on_train_end(self):
self.logger.experiment.log_text('network/final_loss', str(self.final_loss))
def configure_optimizers(self):
return torch.optim.SGD(self.parameters(), lr=self.learning_rate)
@pl.data_loader
def train_dataloader(self):
train_dataset = dg.RandomDataset(self.predict_col, self.n_datasamples)
if self.dataset == 'rand_fix':
train_dataset = dg.RandomDatasetFix(self.predict_col, self.n_datasamples, self.seq_len)
if self.dataset == 'correlated':
train_dataset = dg.CorrelatedDataset(self.predict_col, self.n_datasamples)
train_loader = DataLoader(dataset=train_dataset, batch_size=1)
return train_loader
@staticmethod
def add_model_specific_args(parent_parser):
# MODEL specific
model_parser = ArgumentParser(parents=[parent_parser])
model_parser.add_argument('--learning_rate', default=1e-2, type=float)
model_parser.add_argument('--n_layers', default=1, type=int)
model_parser.add_argument('--n_cells', default=5, type=int)
model_parser.add_argument('--celltype', default='LSTM', type=str)
# training specific (for this model)
model_parser.add_argument('--epochs', default=500, type=int)
model_parser.add_argument('--patience', default=200, type=int)
model_parser.add_argument('--min_delta', default=0.01, type=float)
# data specific
model_parser.add_argument('--n_datasamples', default=1000, type=int)
model_parser.add_argument('--seq_len', default=10, type=int)
model_parser.add_argument('--dataset', default='rand', type=str)
model_parser.add_argument('--predict_col', default=2, type=int)
return model_parser
def main(hparams):
neptune_logger = NeptuneLogger(
project_name="dunrar/bachelor-thesis",
params=vars(hparams),
)
early_stopping = EarlyStopping('batch/mean_absolute_loss', min_delta=hparams.min_delta, patience=hparams.patience)
model = MemoryTest(hparams)
trainer = pl.Trainer(logger=neptune_logger,
gpus=hparams.cuda,
val_percent_check=0,
early_stop_callback=early_stopping,
max_epochs=hparams.epochs)
trainer.fit(model)
Expected behavior
Epochs should not be logged without my explicit instruction. Also there should be no error when running that code.
 Dunrar
Dunrar
All 45 comments
Hi! thanks for your contribution!, great first issue!
![github-actions[bot] picture](https://avatars2.githubusercontent.com/in/15368?v=4&s=40) github-actions[bot]
on 18 Mar 2020
github-actions[bot]
on 18 Mar 2020
@jakubczakon pls ^^
 Borda
on 18 Mar 2020
Borda
on 18 Mar 2020
Hi @Dunrar I am on it.
 jakubczakon
on 19 Mar 2020
jakubczakon
on 19 Mar 2020
@Dunrar I couldn't reproduce your error.
I ran a simple mnist example with a similar lightning module you showed.
First without early stopping:
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-71/charts
Then with early stopping:
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-72/charts
Both seem fine to me.
Also, there are no errors in either case.
Could you please take a look at the source code there (for example this one) and tell me what is different from your case?
Also, as we are working on this I will continue to run those experiments with tags bug and 1186 to easily find it. It will be in the "bugs" dashboard view here.
jakubczakon
on 19 Mar 2020
Thank you @jakubczakon ! The automatically logging the epochs problem also happens when using TensorBoard and when running your code, too. So it might be a Lightning and not a Neptune thing. I'm using Lightning 0.6.0 btw. The metricId is always the same in the error messages, and if I log nothing explicitly epochs still get logged for every time-step with the same error message from neptune, so it might be that.
Dunrar
on 19 Mar 2020
Hmm,
the code quite explicitly says:
def on_epoch_end(self):
self.logger.experiment.log_metric('epoch/mean_absolute_loss', y=np.random.random(), x=self.current_epoch)
to log things on epoch end and that is why I don't quite understand what we want to achieve here.
Looking at the example experiments I linked to, what would you like to not see there?
As there are no errors there it is hard for me to understand what am I fixing.
jakubczakon
on 19 Mar 2020
I additionally log self.current_epoch at every timestep, even when running your example:
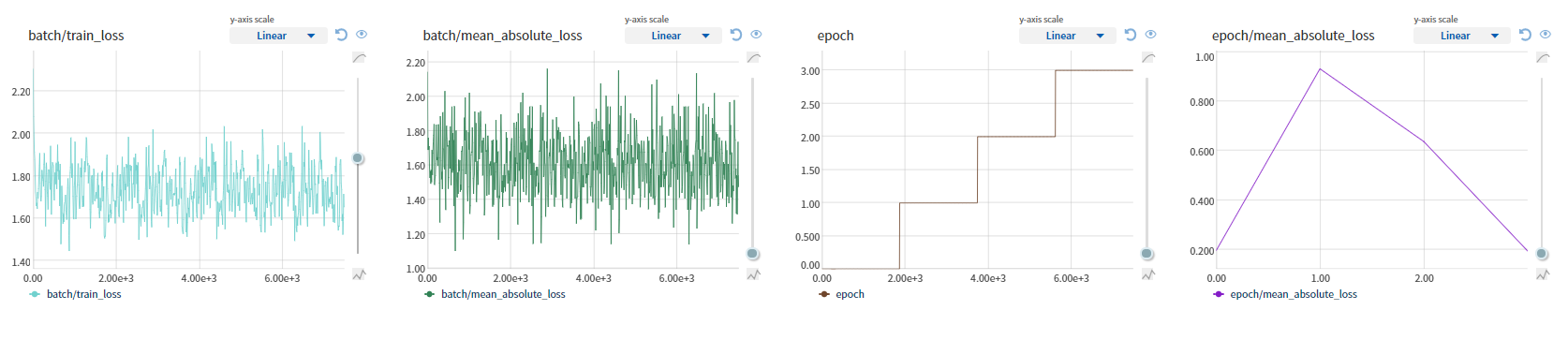
The error message is still the same:

Dunrar
on 19 Mar 2020
Mhm, so maybe it's simply a lightning thing.
I am running it on:
pytorch-lightning==0.7.2.dev0
It works just fine on
pytorch-lightning==0.7.1
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-74/logs
Any chance you could upgrade lightning?
By the way, this project is public and you can log to it via "ANONYMOUS" token anonymously.
It could make things easier to communicate I think.
jakubczakon
on 19 Mar 2020
Alright, I upgraded Lightning to 0.7.1, and logged to the project anonymously. It no longer logs the epoch per timestep, but the error message persists.
Dunrar
on 19 Mar 2020
Great, we're halfway there :)
Also, I don't see any error message here:
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-75/logs
should I add self.current_epoch channel to the training loop or something?
jakubczakon
on 19 Mar 2020
Yea, no error message in neptune, but my console shows it anyway. I tried logging nothing but self.logger.experiment.log_metric('epoch/mean_absolute_loss', y=train_loss_mean, x=self.current_epoch), where I state x and y explicitly, but still no luck. Thank you for your quick response btw!
Dunrar
on 19 Mar 2020
Is that on epoch end?
jakubczakon
on 19 Mar 2020
Yes. I logged my own project to the public project now, too, if you want to have a look at the code.
Dunrar
on 19 Mar 2020
Trying to reproduce on my data loader and cannot for some reason get EarlyStopping to stop it -> I think this could be the problem.
By the way why are you saving loss as text here?
def on_train_end(self):
self.logger.experiment.log_text('network/final_loss', str(self.final_loss))
Also, could you try do the following:
When definiting the logger go:
neptune_logger = NeptuneLogger(
api_key="ANONYMOUS",
project_name="shared/pytorch-lightning-integration",
close_after_fit=False,
...
)
and then simply at the very end of your training (after trainer.fit() in your case) do
neptune_logger.experiment.stop()
This is something that fixes trainer.test(test) and lets you log additional info after training as explained in the docs here.
jakubczakon
on 19 Mar 2020
I wrote that before I knew that you could see logged metrics in textform, before my first run. I average over ten runs per network-configuration and create a graph. I thought it would be nice to check for myself if everything works without having too find the value in the graph :D I will delete that now.
I get TypeError: create_experiment() got an unexpected keyword argument 'close_after_fit'
Dunrar
on 19 Mar 2020
close_after_fit goes into NeptuneLogger from pytorch lightning.
jakubczakon
on 19 Mar 2020
Can you check if you are getting the same error without EarlyStopping?
Would make things easier to debug.
jakubczakon
on 19 Mar 2020
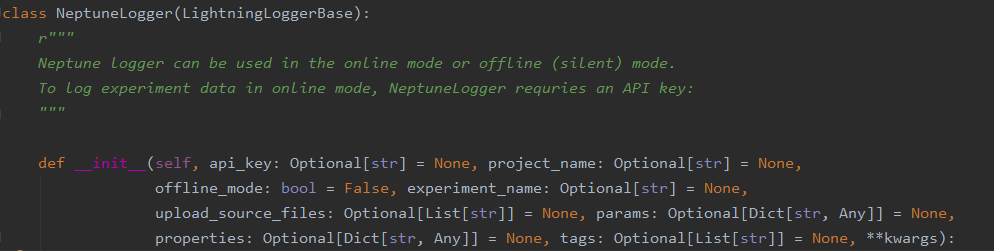
Weirdly my NeptuneLogger does not have that parameter, even though I have 0.7.1. I see it in the GitHub repository, but not in my local version.
Dunrar
on 19 Mar 2020
I tried no EarlyStopping for my code and it made no difference. Also in my code: Initialize a neptune.ml logger., which is probably not right...
Dunrar
on 19 Mar 2020
Perhaps that is not in 0.7.1.
You can install bleeding edge 0.7.2dev via:
pip install git+git://github.com/PyTorchLightning/pytorch-lightning.git
Installed bleeding edge, now I seem to have the current neptune logger version. I tried with and without early stopping again, still the same problem
Dunrar
on 19 Mar 2020
Okay, when I run the code via the PyCharm python console I get no error, only when using the anaconda prompt...
Dunrar
on 19 Mar 2020
Hmm, I am running from the terminal and it is working fine.
What is your environment/setup exactly?
jakubczakon
on 19 Mar 2020
A conda environment with all the packages I need, some of them installed via conda and some via pip. Pycharm with the conda environments python as the interpreter. You can see the error messages from my anaconda prompt under monitoring -> stderr. PYTOR-94 is my run with the pycharm python console, no stderr or stdout
Dunrar
on 19 Mar 2020
Mhm I see it now.
Which neptune-client version is it?
jakubczakon
on 19 Mar 2020
I just updated it, so 0.4.107. It seems the logger can only log my console output when psutil is installed in the environment, right? And write to the console, too. As my pycharm environment does not have psutil installed I get no error. You do not seem to have it installed either, so maybe you'll get the error, too, when you install psutil?
Edit: Okay, I see that stdout get's logged, but not stderr
Dunrar
on 19 Mar 2020
This one does have psutil:
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-98/charts
jakubczakon
on 19 Mar 2020
Ok, but overall at this point:
- experiment runs start to finish
- loss values are logged
- on some envs there is a warning printed to the console
Correct @Dunrar ?
jakubczakon
on 19 Mar 2020
Hmm, okay, so no errors. Well I have no idea what causes neptune to throw an error when logging from my system vs logging the same code from yours. Something has to be different in my environment, right?
Dunrar
on 19 Mar 2020
I'd suppose so.
jakubczakon
on 19 Mar 2020
Yes, that is right. When I run the code from my anaconda prompt with my conda environment active, I get the error. When I run the same code via pycharm I get no error. But I don't know how the pycharm console works, as I have the anaconda python version as the interpreter of my pycharm project. So shouldn't it use the same environment as ist also recognizes all the installed packages etc.?
Dunrar
on 19 Mar 2020
Logged my env in this experiment:
https://ui.neptune.ai/o/shared/org/pytorch-lightning-integration/e/PYTOR-102/source-code?path=.&file=my_local_env.yml
jakubczakon
on 19 Mar 2020
Well, you can choose which pycharm interpreter you are using.
Those could be different from the conda in the pycharm terminal.
jakubczakon
on 19 Mar 2020
Updated local_env link with full conda dump.
jakubczakon
on 19 Mar 2020
Okay, I'll compare, make a few updates/downgrades and report back
Dunrar
on 19 Mar 2020
Okay, little update, I tried to recreate your environment 1:1 via the yml file which did not prove successful. Now I created a completely fresh conda environment and ran the code:
conda create --name pytorch2conda activate pytorch2conda install pytorch torchvision cudatoolkit=10.1 -c pytorchpip install pytorch-lightningpip install neptune-clientconda install -c conda-forge psutilpython neptune_bug.py
The problem persists (PYTOR-106), I don't know why stderr isn't being logged, but I get the error in my console.
Edit: Created a fresh conda env on another system and ran some versions of your neptune_bug.py there. Still get the same error. I could try to get my environment as close to yours as possible, but I don't know where I should start and how useful that would be, as a fresh environment with the latest packages should just work, right?
Dunrar
on 19 Mar 2020
Hi @Dunrar I was talking to the team and the problem is likely resulting from you running it on Windows.
I am running it on Linux hence the difference. Our dev team is looking into it.
jakubczakon
on 20 Mar 2020
Thank you, @jakubczakon!
Dunrar
on 20 Mar 2020
Ok @Dunrar , it seems that it really is Windows related.
As we want to let people log everything (no sampling or averaging as some other solutions do) there is a limit into how often you can send things.
It turns out that datetime on linux is in mircosenconds and on windows in miliseconds.
What it means that if I send 2 values in under milisecond it is passed to our backend as something that happened at the same time. Those values are passed from terminal logs (which is logged to neptune).
My understanding is that you can work (almost) normally right now with only some terminal logs being lost correct?
We've put it in the backlog and we will handle this in future releases but since this problem is not critical I am not sure when exactly would that happen.
jakubczakon
on 20 Mar 2020
Okay, yes, that is correct. And my terminal get's cluttered with errors, but it is definitely not critical and logging works otherwise. Thank you for your help!
Dunrar
on 20 Mar 2020
Sorry for the trouble @Dunrar :)
We will work on a better Windows experience.
I will post updates about this here once I have them.
jakubczakon
on 20 Mar 2020
@jakubczakon @Dunrar I assume that this is also Neptune issue only, not related to PL, right?
Borda
on 4 May 2020
Yes @Borda, this is neptune-only issue.
jakubczakon
on 4 May 2020
Related issues
 monney
·
3Comments
monney
·
3Comments
 versatran01
·
3Comments
versatran01
·
3Comments
 srush
·
3Comments
srush
·
3Comments
 baeseongsu
·
3Comments
baeseongsu
·
3Comments
 williamFalcon
·
3Comments
williamFalcon
·
3Comments
Most helpful comment
Okay, I'll compare, make a few updates/downgrades and report back