Pytorch-lightning: Lose performance between 0.6.0 and 0.7.1
🐛 Bug
When I train exactly the same model with pl 0.7.1, I get worse performance compared to pl0.6.0.
I did a fresh install or Asteroid with both versions and ran exactly the same script on the same hardware.
I get significantly worse performance with pl0.7.1.
Are there some known issues I should be aware of? In the mean time, I'll have to downgrade to 0.6.0
Environment
PL 0.6.0
Collecting environment information... [8/105]
PyTorch version: 1.4.0
Is debug build: No
CUDA used to build PyTorch: 10.1
OS: Debian GNU/Linux 10 (buster)
GCC version: (Debian 8.3.0-6) 8.3.0
CMake version: version 3.14.0
Python version: 3.6
Is CUDA available: No
CUDA runtime version: No CUDA
GPU models and configuration: No CUDA
Nvidia driver version: No CUDA
cuDNN version: No CUDA
Versions of relevant libraries:
[pip3] numpy==1.18.1
[pip3] pytorch-lightning==0.6.0
[pip3] torch==1.4.0
[pip3] torchvision==0.4.2
[conda] blas 1.0 mkl
[conda] mkl 2019.4 243
[conda] mkl-include 2020.0 166
[conda] mkl-service 2.3.0 py36he904b0f_0
[conda] mkl_fft 1.0.14 py36ha843d7b_0
[conda] mkl_random 1.1.0 py36hd6b4f25_0
[conda] torch 1.3.1 pypi_0 pypi
[conda] torchvision 0.4.2 pypi_0 pypi
Diff between 0.6.0 and 0.7.1 envs
diff env_0.7 env_0.6
19c19
< [pip3] pytorch-lightning==0.7.1
---
> [pip3] pytorch-lightning==0.6.0
 mpariente
mpariente
All 53 comments
Could you be more precise what you mean with performance?
It could mean
- Your test loss is lower with 0.7.1 compared to 0.6.0
- Training epochs take longer to finish in 0.7.1 vs. 0.6.0
- or other things.
 awaelchli
on 13 Mar 2020
awaelchli
on 13 Mar 2020
Yeah true, sorry.
Training, validation and testing losses are worse with 0.7.1, that's what I
meant.
mpariente
on 13 Mar 2020
@mpariente could you pls give us some numbers?
 Borda
on 13 Mar 2020
Borda
on 13 Mar 2020
Yes. We minimize negative signal to distortion ratio (SDR), which is widely used in speech separation. I report loss values here, they are negative and lower is better.
With 0.6.0, we reached -18dB / With 0.7.1, we couldn't reach better than -15dB. People publish for 1dB so this is a huge difference.
I'm re-running the experiments with exactly the same version of the code, same libraries, same hardware, only difference is lightning. This is a screenshot of the ongoing runs.We can already see a 2dB difference between the runs

mpariente
on 13 Mar 2020
just crossed some other comment about slower performances https://github.com/PyTorchLightning/pytorch-lightning/issues/525#issuecomment-596963253
Borda
on 13 Mar 2020
I also noticed a similar issue with my code after upgrading to 0.7.1 from 0.6, so I tried running the MNIST example, and confirmed performance difference (both of my environments used torch==1.4.0 and torchvision==0.5.0)

Orange curve is version 0.6, pink curve is version 0.7.1
 gwichern
on 13 Mar 2020
gwichern
on 13 Mar 2020
If it even happens with MNIST, we have to find the bug asap!
I thought there were tests in place to ensure the performance does not change, but it seems this is not the case.
awaelchli
on 13 Mar 2020
Just to be sure, @mpariente and @gwichern did you make the training deterministic before running this comparison?
awaelchli
on 13 Mar 2020
there are test cases to make sure performance doesn't change. please rerun using the exact same seed and only change the versions.
 williamFalcon
on 13 Mar 2020
williamFalcon
on 13 Mar 2020
In my case yes. The pytorch-lightning MNIST example sets both the numpy and torch seeds to 2334. Everything is the same except environments.
gwichern
on 13 Mar 2020
I'm not sure what you mean here.
You still reach the same accuracy just at different times

williamFalcon
on 13 Mar 2020
@gwichern can you post a colab here? we can test it there.
williamFalcon
on 13 Mar 2020
Agreed, on that point about the accuracy getting to the same value, but I just ran pl_examples/basic_examples/cpu_template.py in two different environments (passing --hidden_dim 500 from the command line in both cases). The seed is set to the same value in both versions, so I would have expected things to match better
gwichern
on 13 Mar 2020
Just to be sure, @mpariente and @gwichern did you make the training deterministic before running this comparison?
No, my bad. But I did make each run twice, and have consistent difference between 0.6.0 and 0.7.1
I'll rerun it tonight with the same seed on both trials.
mpariente
on 13 Mar 2020
It looks like the MNIST example doesn't set shuffle=True in the dataloader, that could be the cause of the poor MNIST performance. @mpariente is data being shuffled in your case?
 ethanwharris
on 13 Mar 2020
ethanwharris
on 13 Mar 2020
ok, yeah... finding the same. Let's dig into this a bit.
The problem is that the core logic didn't really change though.
Might be dataloader related
williamFalcon
on 13 Mar 2020
@PyTorchLightning/core-contributors
williamFalcon
on 13 Mar 2020
the @pl.dataloader decorator got removed in 0.7. could it be related? (can't test right now).
awaelchli
on 13 Mar 2020
I didn't try to find the cause of this yet, I thought I should report first.
@mpariente is data being shuffled in your case?
Yes it is.
mpariente
on 13 Mar 2020
might be the refresh rate of the progress bar. maybe that also changed the update freq of the loggers by mistake
williamFalcon
on 13 Mar 2020
might be the refresh rate of the progress bar. maybe that also changed the update freq of the loggers by mistake
Had considered this possibility as well. But for a given epoch (while training), the results are significantly degraded.
mpariente
on 13 Mar 2020
Using this colab (https://colab.research.google.com/drive/1NUrJ7LZqblKW_OIpiGYVaOLGJ2l_tFxs)
0.6.0
At the end of 1 epoch.

0.7.1

Removing the decorators has no effect

Using the new epoch_end signature

When i decrease the refresh rate (gets closet to the 0.6.0 value) (actually, lower loss than 0.6.0)

So, i don't see a huge difference here. Mind playing with it for a bit?
williamFalcon
on 13 Mar 2020
And when doing exactly the same model including environment reset we get an exact curve match... (across 6 epochs)

williamFalcon
on 13 Mar 2020
We'll try to see if we get the same problem when we are setting seeds.
Thanks for taking time for it.
If it persists, I'll try to set up a reproducible example but the dataset we use is not open, it makes things complicated.
mpariente
on 13 Mar 2020
any news @mpariente?
I want to make sure this is in fact a non-issue so we can close or fix.
williamFalcon
on 15 Mar 2020
Real training takes over 2days so I was finishing both trainings.
Differences are still huge and it didn't compensate over time. Didn't try to set the seeds yet. I'll let you know, I don't have a lot of compute power available for these experiments.
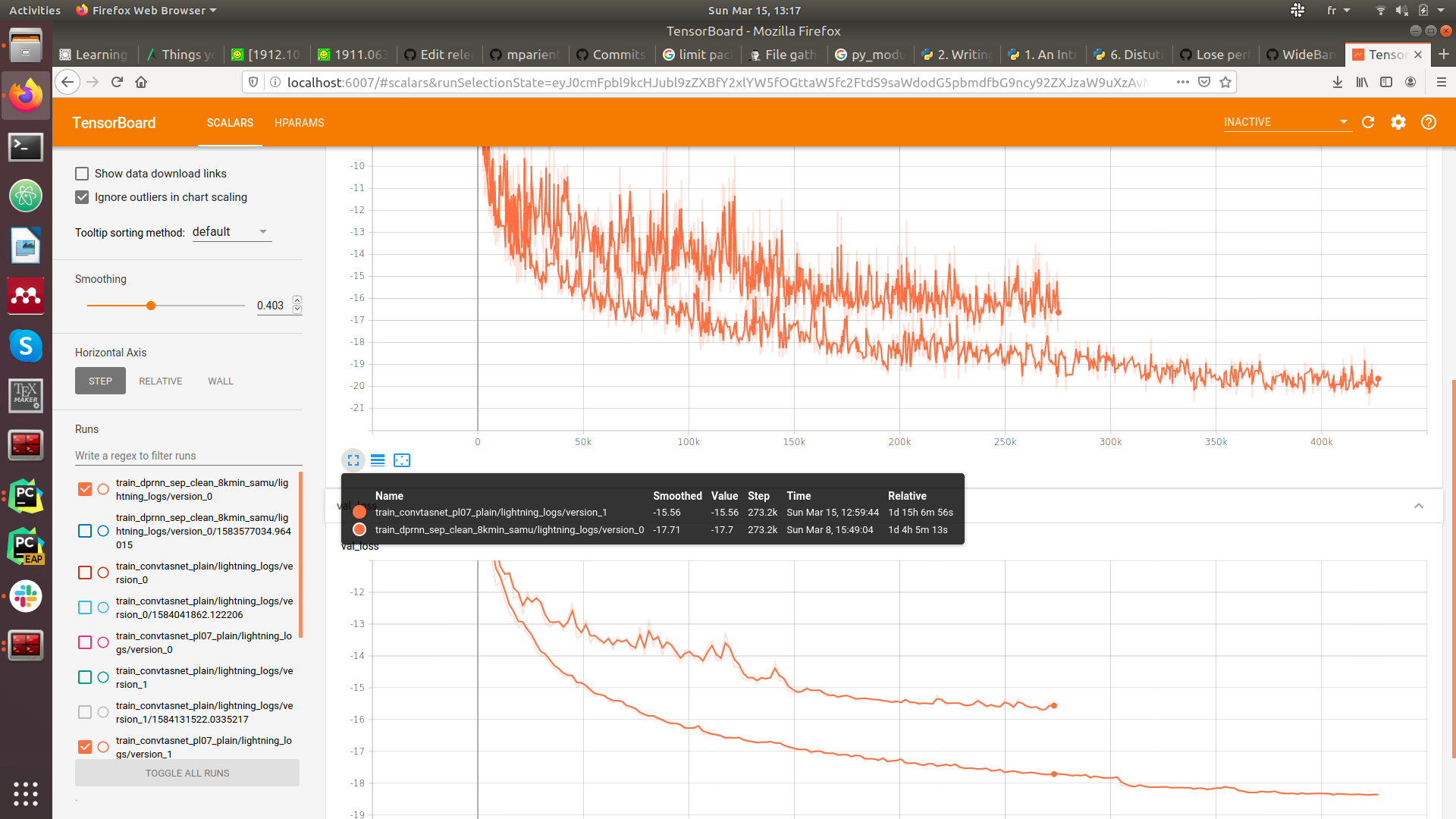
We consider it an issue on our end and downgraded to version 0.6.0 for now.
mpariente
on 15 Mar 2020
@mpariente was thinking about this. maybe it has to do with distributedSampler if you're using that? since we now inject that automatically, it may be that your effective batch size is differnt now and thus if you use the same learning rate, you won't get the best results?
It might be that you have to readjust your learning rate. (from this graph, i would make it slower).
williamFalcon
on 19 Mar 2020
Hmm, we use dp only, not ddp, would this still apply?
Thanks for taking a look again
mpariente
on 19 Mar 2020
Well, this persists.
I finally took time to reproduce the issue, on another architecture.
Now, the training is deterministic, here are the tensorboard logs (grey pl0.7.1, orange pl0.6., nothing else changes between the envs) :

Training is not over but the differences are already not negligible.
I also have a video about the 10 first epochs if you'd like.
This script to reproduce are here but the training dataset is under license..
Info that might be useful, distributed backend is 'dp'.
mpariente
on 28 Mar 2020
ok awesome. will look into this.
and this was introduced in 0.7.1?
@mpariente i'm looking into this today and tomorrow, will push a fix if I find something.
In the meantime I'm also going to put together a few architectures to prove correctness going forward so we know if we mess something up.
It's weird because the tests do test a specific performance goal
williamFalcon
on 28 Mar 2020
IIRC 0.7.0 was not backward compatible because of pl.data_loader so I couldn't test it.
It's weird because the tests do test a specific performance goal
I know you're doing the best you can about this, no worries.
For now, both architecture involved LSTMs, did you change anything about BBTT?
I'm going to try with a ConvNet, see if it changes as well.
mpariente
on 28 Mar 2020
ummm... i don't think we did but that's good to know. Maybe it is RNN related.
Why don't you do the sample in this colab so we can unify efforts here (ping me your email on our slack so I can give you access)
I want to create the following tests:
- MNIST using MLPs.
- cifar10 using CNNs.
- an RNN example, maybe sequence classification. whatever the equivalent simple test is for RNN.
- a VAE
- probably enough
williamFalcon
on 28 Mar 2020
Tried on two convolutional architectures and the training and validation curves are a perfect match.
At first sight, it seems to be RNN related, which would be a good news.
mpariente
on 28 Mar 2020
Any update on that please?
mpariente
on 2 Apr 2020
will do an rnn test. however, we now have a parity test between pytorch pure and lightning with convnets in continuous integration. the test forces a match across trials to 5 decimal points.
i’ll add an rnn test as well
williamFalcon
on 2 Apr 2020
Sounds great !
Could you give me a link to the parity tests you mentioned please?
mpariente
on 2 Apr 2020
williamFalcon
on 2 Apr 2020
this runs on every PR to make sure no PR breaks parity.
We do have a bit of difference in speed with pytorch, but looking into it. It looks related to logging, tqdm and tensorboard.
so, speedwise it's not a fair comparison because the pure pytorch version has no logging or any of that, whereas lightning does
williamFalcon
on 2 Apr 2020
Oh I didn't see the PR, I thought you'd ping this Issue with it.
About the RNN, did you decide the task? Do you want a fake dataset or something real? I can put together an averaging RNN example if needed.
mpariente
on 2 Apr 2020
yeah, that would be super helpful! maybe the addition task is a good dataset to test?
Can do the colab here:
https://colab.research.google.com/drive/1qvQdkiTfCeHot6Db9OI1acXqqn3qZdYO#scrollTo=dTzj2fH6I1Mn
williamFalcon
on 2 Apr 2020
I took the code from #1351 and ran it for 10 epochs and 3 runs on CPU first (because @mpariente also has no GPU), then I noticed that there is a performance gap between 0.6.0 and 0.7.1 in the third decimal point.
https://colab.research.google.com/drive/1yek1fUkIEmJgt9iI7pnr3HWFNgrf14pr
Not sure if it helps.
awaelchli
on 3 Apr 2020
Thanks for looking into this, could you grant me access to the colab please?
Did you also try on GPU?
mpariente
on 3 Apr 2020
Try again, I had sharing turned off.
No, Colab doesn't want to give me GPU for some reason, that's why I tried CPU.
awaelchli
on 3 Apr 2020
Ok, I can reproduce the same results as you and checked that the pytorch vanilla_loop also passes, and this is the case.
I'm trying something else, I'll let you know if it gives anything
mpariente
on 3 Apr 2020
@williamFalcon have you seen this?
I think the parity test are not as good as they could be because if configure_optimizers does something under the hood, it won't have any impact as these are the optimizers used in the pure pytorch case as well.
I took the code from #1351 and ran it for 10 epochs and 3 runs on CPU first (because @mpariente also has no GPU), then I noticed that there is a performance gap between 0.6.0 and 0.7.1 in the third decimal point.
https://colab.research.google.com/drive/1yek1fUkIEmJgt9iI7pnr3HWFNgrf14pr
Not sure if it helps.
And the results @awaelchli mentionned shows exactly this right? Parity test passes but the performances are different, how can we explain that?
mpariente
on 6 Apr 2020
we should also probably include truncated_bptt in the parity test
 jeremyjordan
on 6 Apr 2020
jeremyjordan
on 6 Apr 2020
Sorry to ping you @williamFalcon, but this is not resolved.
mpariente
on 13 Apr 2020
we have parity tests now with an exact performance match...
can you provide a colab where you can reproduce this behavior?
williamFalcon
on 13 Apr 2020
we have parity tests now with an exact performance match...
can you provide a colab where you can reproduce this behavior?
I would not call it exact performance match actually : performance are matching between pytorch-lightning and torch, true. But if you change the version of pytorch-lightning, the perfs are changing and they shouldn't because the seeds are exactly the same.
So something is happening under the hood, see those lines for example, in 0.6.0, the train dataloader is also changed by lightning right?
I don't think these parity tests are as valuable as they should be.
mpariente
on 13 Apr 2020
the performance comparison has to be against pure pytorch because that’s the bound for speed and accuracy. comparing across lightning versions makes no sense.
again, can’t help without a real example that breaks on colab. every other time anyone has brought up a performance difference they’ve ended up finding a bug in their code.
happy to fix if something is broken, but we need tangible proof to find a possible problem.
williamFalcon
on 13 Apr 2020
the performance comparison has to be against pure pytorch because that’s the bound for speed and accuracy. comparing across lightning versions makes no sense.
But I don't think it qualifies as pure pytorch, everything still comes from a lightning module.
again, can’t help without a real example that breaks on colab. every other time anyone has brought up a performance difference they’ve ended up finding a bug in their code.
happy to fix if something is broken, but we need tangible proof to find a possible problem.
I understand, I'll try to build an example that fails next week, thanks again
mpariente
on 13 Apr 2020
it’s literally the same code. it’s like saying 2 = (2) are different haha. it’s written this way for convenience because the pytorch code is exactly the same...
williamFalcon
on 13 Apr 2020
I've tried with 0.7.5 against 0.6.0 and got the same results on several of our architectures. We'll finally upgrade and get all the new features you integrated :grinning:
Thanks again for looking into it, I'm closing this.
mpariente
on 17 May 2020
Related issues
 maxime-louis
·
3Comments
maxime-louis
·
3Comments
 srush
·
3Comments
srush
·
3Comments
 monney
·
3Comments
monney
·
3Comments
 iakremnev
·
3Comments
iakremnev
·
3Comments
 anthonytec2
·
3Comments
anthonytec2
·
3Comments
Most helpful comment
I've tried with 0.7.5 against 0.6.0 and got the same results on several of our architectures. We'll finally upgrade and get all the new features you integrated :grinning:
Thanks again for looking into it, I'm closing this.