Pysyft: Backpropagation not producing gradients
I'm currently working on the implementation of the federated training of a Recurrent Neural Network, and I stumbled upon the following issue: when operating on the remote pointer of the loss function initialized with Negative Log Likelihood, the grad_fn function is not set and it will still say "requires_grad=True" despite the loss function being set in the code:
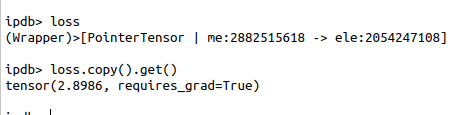
Instead, in the sequential version or when the input arguments of the loss function are ".get()", the grad_fn is actually set in the loss function:
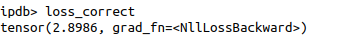
Because of this issue, the backpropagation does not successfully generate all the model's gradient parameters (i.e.: only two parameters are generated in the remote version vs four parameters in the local version), hence preventing the model from converging in the remote version. I looked up if other people are having the same issue, and these pages seem to suggest that the graph is broken (?): https://discuss.pytorch.org/t/list-model-parameters-0-grad-doubt-in-weight-updates/8422
To reproduce:
import torch.nn as nn
import torch
import syft as sy
import numpy as np
hook = sy.TorchHook(torch)
dani = sy.VirtualWorker(hook, id="dani")
ele = sy.VirtualWorker(hook, id="ele")
workers_virtual = [dani, ele]
criterion = nn.NLLLoss()
output = torch.from_numpy(np.ones((1, 18)))
output.requires_grad_()
output_sent = output.send(dani)
category_single = torch.from_numpy(np.array([2]))
category_sent = category_single.send(dani)
#Non-working version, with requires_grad=True
loss = criterion(output_sent, category_sent)
print(loss.copy().get()) #Requires_grad=True
#Working version, with grad_fn properly set.
loss_working = criterion(output_sent.copy().get(), category_sent.copy().get())
print(loss_working) #grad_fn = NllLossBackward
loss.backward()
model just has 2 parameters with grad != None following the backpropagation. Consequently, during the training process, the model weights are not updated.
for param in model_ptr.parameters():
Returns an error, as parameters at position [0] is not present.
 DanyEle
DanyEle
All 5 comments
I've tried to run the snippet above, and I got the following error:
File "original_syft_bug.py", line 12, in <module>
output = np.ones(1, 18)
File "/home/marianne/anaconda3/envs/syft/lib/python3.6/site-packages/numpy/core/numeric.py", line 203, in ones
a = empty(shape, dtype, order)
TypeError: data type not understood
I've changed line 12 to: output = torch.from_numpy(np.ones((1, 18)))
And the script doesn't break, it gives me the following output:
tensor(-1., dtype=torch.float64, requires_grad=True)
tensor(-1., dtype=torch.float64, grad_fn=<NllLossBackward>)
I'm using syft from dev branch.
 mari-linhares
on 6 May 2019
mari-linhares
on 6 May 2019
Thank you for running my example!!
Yes, that's exactly the same output I got too. Isn't the pointed loss supposed to have grad_fn=
for param in model_ptr.parameters():
#if(param.grad is not None):
#Daniele: code breaks here, as not all gradient parameters are there
param.data.add_(-args.learning_rate, param.grad.data)
I've attached a full example about my federated code for RNNs (kinda messy though). Bear in mind to change the following line before running it:
os.chdir("/home/daniele/py_thesis/RNN_Example")
DanyEle
on 6 May 2019
I tried replicating my issue with the hidden layer, the model, the output and the input arguments obtained via the "copy().get()" function and the backpropagation seems to be successfully working in that case, with all gradients being present in the model's parameters.
This is the current non-working version:
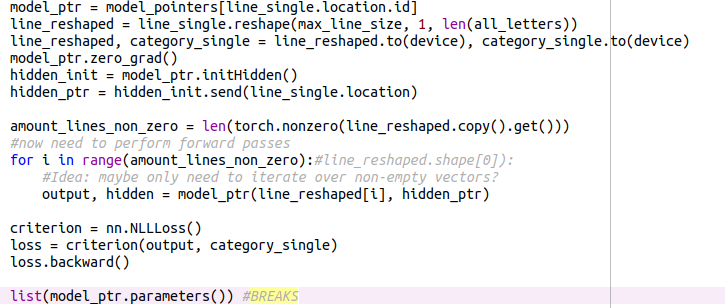
Working version, with all variables extracted via the .get() function:
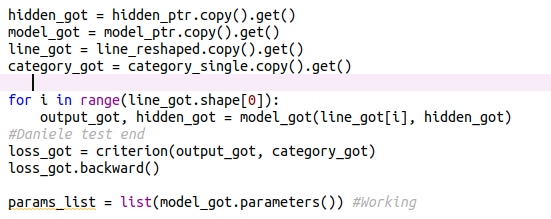
I presume there could be some issues the PySyft backpropagation function when operating on the remote pointers for such case?
DanyEle
on 7 May 2019
I believe the issue is related to the fact that the .grad and .data attributes are still not supported by PySyft, but there seems to be some code about it in syft/frameworks/torch about it. This comment seems to suggest that the .grad and .grad.data tensors are not supported yet?
# TODO: add .data and .grad to syft tensors
However, it turns out that by de-commenting the following lines in syft/frameworks/torch/hook.py (which were previously commented), the gradients are properly computed following the backpropagation phase.
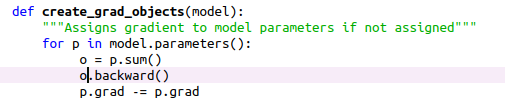
DanyEle
on 7 May 2019
Fixed by #2127, great job @DanyEle!
mari-linhares
on 8 May 2019
Related issues
 iamtrask
·
4Comments
iamtrask
·
4Comments
 beatrizsmg
·
4Comments
beatrizsmg
·
4Comments
 wentaiwu92
·
4Comments
wentaiwu92
·
4Comments
 robert-wagner
·
4Comments
robert-wagner
·
4Comments
 LaRiffle
·
3Comments
LaRiffle
·
3Comments
Most helpful comment
Fixed by #2127, great job @DanyEle!