Pyro: Undocumented restrictions on discrete inference?
Weird behaviour in discrete inference with shared mixture weights
pyro version - 1.1.0 (and earlier)
Consider the following pyro model, defining a mixture of gaussians
K = 5
d = 2
N_obs = 100
@infer.config_enumerate
def model(N=1):
with pyro.plate('data_plate', N, dim=-2):
mixing_weights = pyro.param('pi', th.ones(K) / K, constraint=constraints.simplex)
means = pyro.sample('mu', D.Normal(th.zeros(K, d), th.ones(K, d)).to_event(2))
with pyro.plate('observations', N_obs, dim=-1):
s = pyro.sample('s', D.Categorical(mixing_weights))
x = pyro.sample('x', D.Normal(I.Vindex(means)[..., s, :], 0.1).to_event(1))
This can be enumerated, and works fine. In particular, gradients flow to the mixing weights variable, as can be checked with the following snippet
pyro.clear_param_store()
conditioned_model = pyro.condition(model, data={'x': x})
guide = infer.autoguide.AutoDelta(poutine.block(conditioned_model, hide=['s']))
elbo = infer.TraceEnum_ELBO(max_plate_nesting=2)
opt = pyro.optim.Adam({'lr': 1e-2})
svi = infer.SVI(conditioned_model, guide, opt, elbo)
# probably need
losses = []
for i in range(1000):
l = svi.step(x.size(0))
if i % 100 == 0:
print(i, l)
elbo.loss_and_grads(conditioned_model, guide, x.size(0))
print(pyro.get_param_store()._params['pi'].grad)
losses.append(l)
Now, if we add another random variable after x that depends on the same mixture component, everything breaks
pyro.clear_param_store()
K = 5
d = 2
N_obs = 100
@infer.config_enumerate
def model(N=1):
with pyro.plate('data_plate', N, dim=-2):
mixing_weights = pyro.param('pi', th.ones(K) / K, constraint=constraints.simplex)
means = pyro.sample('mu', D.Normal(th.zeros(K, d), th.ones(K, d)).to_event(2))
with pyro.plate('observations', N_obs, dim=-1):
s = pyro.sample('s', D.Categorical(mixing_weights))
x = pyro.sample('x', D.Normal(I.Vindex(means)[..., s, :], 0.1).to_event(1))
# this line breaks stuff
y = pyro.sample('y', D.Normal(I.Vindex(means)[..., s, :], 0.1).to_event(1))
Now, running the above snippet will show no gradient passing back to the mixing weights. The fitted means are also nonsense.
In probabalistic terms I think this is certainly wrong, since I _think_ y should simply marginalise out and have no effect on the rest of the model.
But this doesn't seem to break any of the restrictions detailed here - y does not introduce cross-plate coupling, and it is within the plate where s is enumerated, and it doesn't break the 'single path' restriction because it isn't discrete.
I'm pretty sure (though not certain) that this behaviour is not correct in probabilistic terms, and results from some kind of bug or undocumented assumption in the enumeration code.
 lsgos
lsgos
All 6 comments
Hi @lsgos, your model looks good. My first guess is that, while y indeed marginalizes out, it introduces high-variance zero-mean noise into the optimization process and thereby breaks learning. One way you could test this hypothesis would be to wrap the y site in a poutine.scale
with poutine.scale(scale=1e-6):
y = pyro.sample('y', ...)
Then train on fixed data for each of scales in [1e-6,1e-5,...,1e-1,1]. If my hypothesis is correct then the model should learn correct (or to make things easy, identical) mixing weights for all scales, but convergence time will be a quickly growing function of scale. You could plot on a single figure loss curves for each of the scales; if my hypothesis is correct you would see convergence to the same ELBO loss but taking longer and longer as scale increases.
 fritzo
on 12 Dec 2019
fritzo
on 12 Dec 2019
So I don't think that this is right - this doesn't explain the fact that no gradient passes back to the mixing weights, when it certainly should (print(pyro.get_param_store()._params['pi'].grad) prints None in my example snippet above). In fact at the end of training the mixing weights will be whatever they were initialised as, even if you scale y such that the effect should be imperceptible (i.e scale=1e-12). I think the lack of gradients is a sign of a deeper problem - I can try and do a bit more digging through the mechanics of traceenum_elbo to see what is going on in more detail when I have some time if that's helpful?
Everything seems to start behaving more as expected if you condition on y, by the way.
lsgos
on 12 Dec 2019
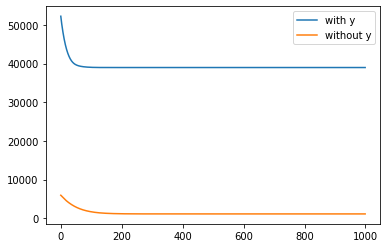
If it helps, here is a graph showing the scale of the elbo with and without the nuisance variable y. Kinda difficult to intepret this but it certainly seems like the models are converging to totally different objectives. But these curves are quite smooth so it doesn't seem like it's because of gradient noise
lsgos
on 12 Dec 2019
Good debugging, that indeed looks like a bug! Let me know what you find. Ideally we could add your .grad is not None check as a unit test in Pyro; if you submit a PR with the failing test I'd help out with debugging.
fritzo
on 13 Dec 2019
OK, after i'm home from neurips I'll try to write up the test and make a pull request, and then we can try to see what is going on
lsgos
on 14 Dec 2019
Think this issue should have been resolved by #2226 being merged so closing
lsgos
on 22 Dec 2019
Related issues
 neerajprad
·
4Comments
fritzo
·
4Comments
neerajprad
·
4Comments
fritzo
·
4Comments
 robsalomone
·
4Comments
robsalomone
·
4Comments
 fehiepsi
·
3Comments
fritzo
·
5Comments
fehiepsi
·
3Comments
fritzo
·
5Comments
Most helpful comment
OK, after i'm home from neurips I'll try to write up the test and make a pull request, and then we can try to see what is going on