Pulsar: Consumer stop receive messages from broker
Actual behavior
A process subscribe a topic with 2 subscriptionName. After a few hours, we found backlog of 1 subscriptionName growing continuous, then check the broker stats:


Stats of unackedMessages and availablePermits looks weird, i don't understand why both of them is 0 at the same time.
Then make the heap dump of client, but did not find anything abnormal. I'm already upload the heap dump to slack:
https://apache-pulsar.slack.com/files/UC0BYCXKQ/FELNFAZ6W/heap.hprof
System configuration
Pulsar Broker version: 2.2.0
Pulsar Client version: 2.2.0
 codelipenghui
codelipenghui
All 8 comments
Hi @codelipenghui, Do you think this is related with #3185?
 jiazhai
on 17 Dec 2018
jiazhai
on 17 Dec 2018
When a subscription's consume rate less than produce rate will produce a large backlog, at this moment, I increase the consume note, the consume rate will increase. Sometimes ago, the consume rate will return to initial rate I haven't increase the note. I check the broker stats, some consumer's msgRateOut is 0.Then I unload the topic,the consume rate will increase,but sometimes ago,the consume rate will also return to initial rate
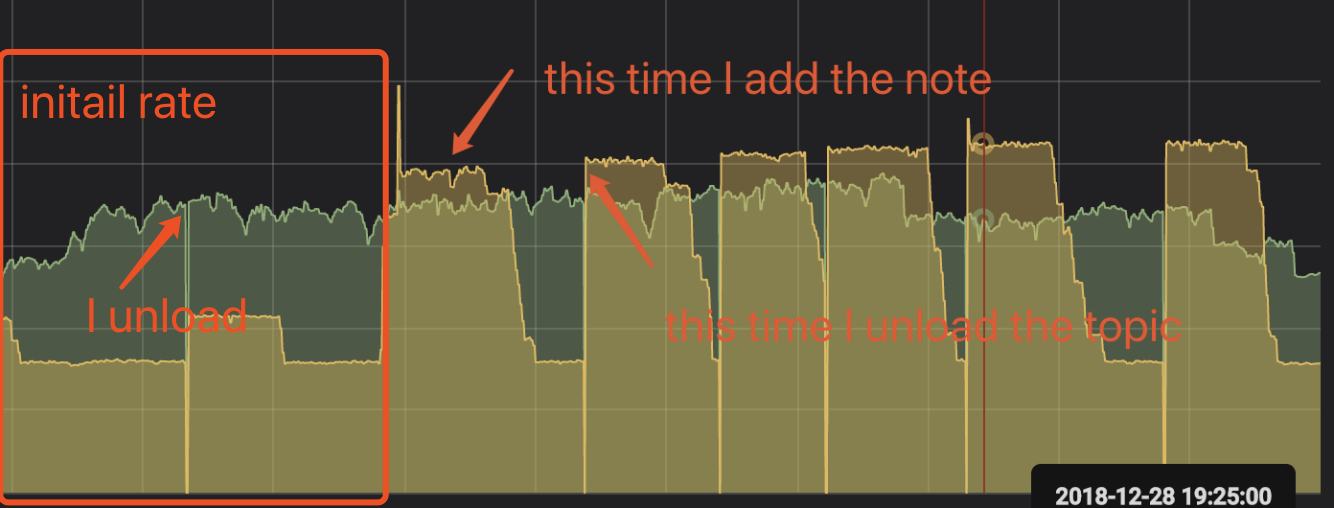
Once unload haven't consume the backlog completed the consume rate return to initial rate, it will
happen.
 congbobo184
on 29 Dec 2018
congbobo184
on 29 Dec 2018

Consumer in the same subscription stop consume messages, seems like broker update available permits problem?
codelipenghui
on 4 Jan 2019
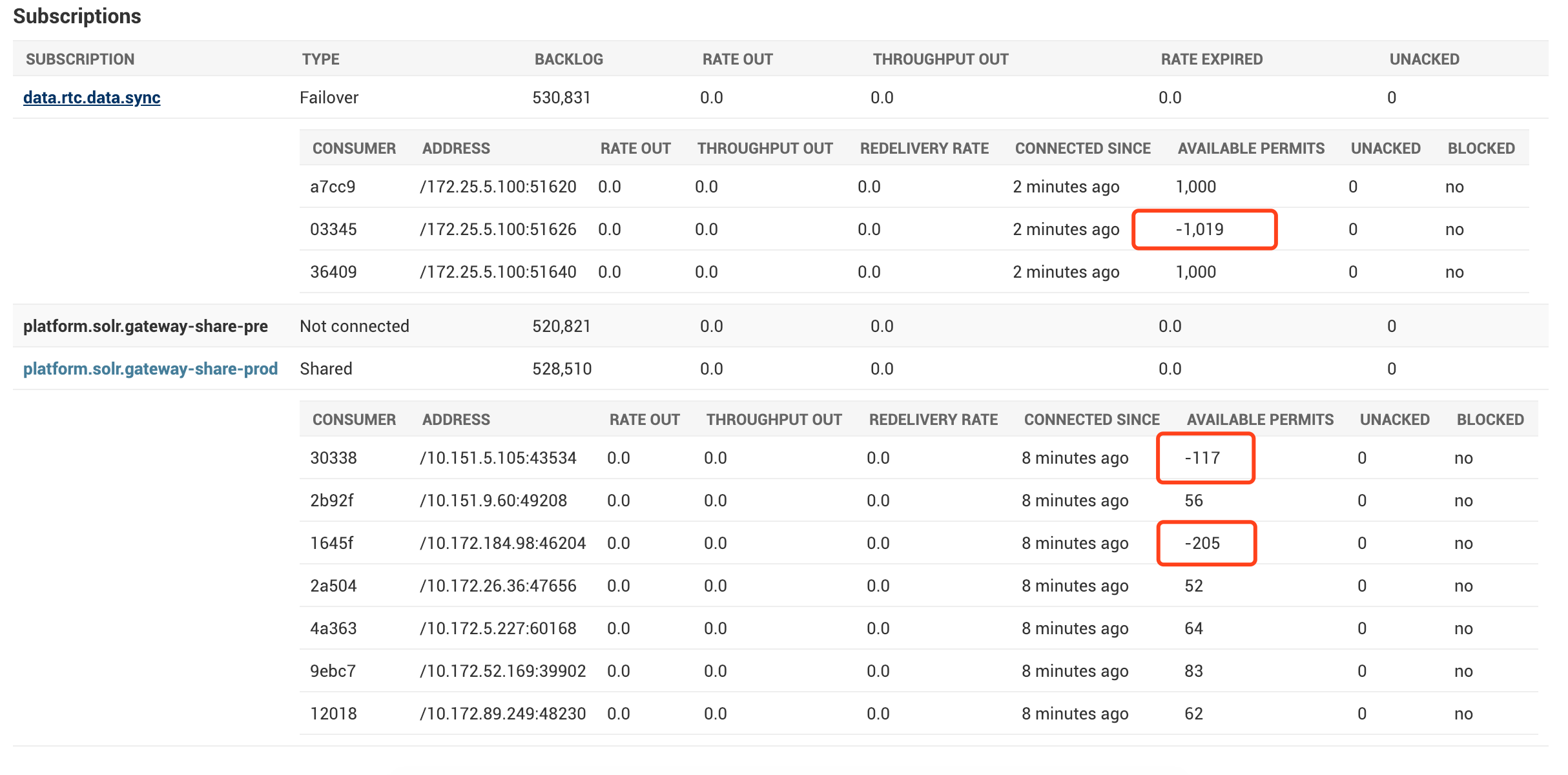
Found some common problem cause consumer stop consume messages, stats of broker show us AVAILABLE PERMITS is negative number.
codelipenghui
on 9 Jan 2019
This is a test case to show how consumer stop consume messages:
package com.zhaopin.pulsar.issues;
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.Message;
import org.apache.pulsar.client.api.Producer;
import org.apache.pulsar.client.api.PulsarClient;
import org.apache.pulsar.client.api.PulsarClientException;
import org.apache.pulsar.client.api.SubscriptionType;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
public class ConsumerStopReceiveMessages {
public static void main(String[] args) throws PulsarClientException {
final String topic = "your-topic";
/**
* Broker configs:
*
* maxUnackedMessagesPerConsumer=500
* maxUnackedMessagesPerSubscription=2000
*/
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
// Create a producer with enable message batching
Producer<byte[]> producer = client.newProducer()
.topic(topic)
.batchingMaxMessages(1000)
.batchingMaxPublishDelay(30, TimeUnit.SECONDS)
.blockIfQueueFull(true)
.maxPendingMessages(1000)
.enableBatching(true)
.create();
// Create 6 consumers
List<Consumer<byte[]>> consumers = new ArrayList<>();
for (int i = 0; i < 6; i++) {
consumers.add(client.newConsumer()
.topic(topic)
.subscriptionType(SubscriptionType.Shared)
.subscriptionName("test")
.ackTimeout(1, TimeUnit.SECONDS)
.receiverQueueSize(100)
.subscribe());
}
// Producer start publish messages
new Thread(() -> {
int index = 0;
for (; ; ) {
producer.sendAsync((index++ + "").getBytes());
}
}).start();
// Consumers start consume messages
consumers.forEach(consumer -> new Thread(() -> {
do {
// can't receive message
try {
Message<byte[]> msg = consumer.receive();
System.out.println("Message Received [x] " + consumer.getConsumerName() + " --- [" + msg.getMessageId() + "]" + " ---- " + new String(msg.getValue()));
//Do not ack messages, wait broker redelivery
} catch (Exception e) {
e.printStackTrace();
}
} while (true);
}).start());
}
}
After a while, you will get following logs:
Message Received [x] 78cab --- [15361:48:-1:990] ---- 0
Message Received [x] 78cab --- [15361:48:-1:991] ---- 0
Message Received [x] 78cab --- [15361:48:-1:992] ---- 0
Message Received [x] 78cab --- [15361:48:-1:993] ---- 0
Message Received [x] 78cab --- [15361:48:-1:994] ---- 0
Message Received [x] 78cab --- [15361:48:-1:995] ---- 0
Message Received [x] 78cab --- [15361:48:-1:996] ---- 0
Message Received [x] 78cab --- [15361:48:-1:997] ---- 0
Message Received [x] 78cab --- [15361:48:-1:998] ---- 0
Message Received [x] 78cab --- [15361:48:-1:999] ---- 0
[ConsumerBase{subscription='test', consumerName='78cab', topic='your-topic'}] 9 messages have timed-out
[your-topic] [pulsar-api-test-14-3291] Pending messages: 1 --- Publish throughput: 7583.21 msg/s --- 0.33 Mbit/s --- Latency: med: 222.155 ms - 95pct: 587.127 ms - 99pct: 666.942 ms - 99.9pct: 766.028 ms - max: 766.102 ms --- Ack received rate: 7566.54 ack/s --- Failed messages: 0
[your-topic] [test] [2a5ea] Prefetched messages: 0 --- Consume throughput: 16.45 msgs/s --- Throughput received: 0.00 msg/s --- 0.00 Mbit/s --- Ack sent rate: 0 ack/s --- Failed messages: 0 --- Failed acks: {}
[your-topic] [test] [78cab] Prefetched messages: 0 --- Consume throughput: 332.48 msgs/s --- Throughput received: 0.00 msg/s --- 0.00 Mbit/s --- Ack sent rate: 0 ack/s --- Failed messages: 0 --- Failed acks: {}
as discussed with @codelipenghui , above code is reproduce-able under both 2.2.0 and 2.2.1, and seems related with batch.
jiazhai
on 9 Jan 2019
Any indication when this fix would get released, maybe 2.2.2?
 bputt
on 9 Jan 2019
bputt
on 9 Jan 2019
Broker dispatch process:
- In the test, we will
settings: broker.MaxUnackMessagesPerConsumer=100 and broker.MaxUnackMessagesPerSubscription=500.
setup 2 consumer in share mode, and set consumer.receiverQueueSize=100. Producer enable batching, and set producer.BatchingMaxMessages=2000.
InPersistentDispatcherMultipleConsumers, we have fixed setting :MaxReadBatchSize=100, andMaxRoundRobinBatchSize=20; - Once a consumer subscribes to a topic, consumer will send a flow request with 100(receiverQueueSize) permits to broker to get messages.
- By default, broker will read 100(MaxReadBatchSize) entries from ledger and distribute entries to 2 consumers, each consumer is expecting to get 20(MaxRoundRobinBatchSize) entries.
- Once broker send messages to the first consumer, unacked messages will be 40000(20 * 2000), dispatcher will be blocked, so the dispatcher init available permits is 200(2 * consumer.receiverQueueSize), after send 40000 messages(20 permits) to the first consumer, available permits is 200 - 40000 = -39800. and Dispatcher is set as blocked.
- Client Consumer start receiving messages, then after received 50 messsages, it reaches threshold (receiverQueueSize,100/2), consumer will send Flow request to the broker again, but now broker.consumer is blocked by un-ack messages, so broker do not send any messages to consumer, and broker.consumer will increase permitsReceivedWhileConsumerBlocked.
- Since messages received but not acked, consumer will send a redelivery request, dispatcher should release the flow control, but the logic in the broker.consumer, consumer will use min(permitsReceivedWhileConsumerBlocked, totalRedelivery) to increase the available permits in the dispatcher.
I think the problem is here, if totalRedelivery < permitsReceivedWhileConsumerBlocked, consumer is already send flow request, but broker can't release the flow control in time, because remaining flowPermits is too small(received_total - permitsReceivedWhileConsumerBlocked) comparing to permits in broker(-39800) . Dispatcher will be blocked forever.
e.g.
When a consumer receive 10000 messages(5 message, batch size is 2000), consumer will send 200 times flow request(50 messages per request),
If permitsReceivedWhileConsumerBlocked = 9000, at this time consumer redelivery 2000 messages, dispatcher will use 2000 to increase the available permits(at this time, available permits in dispatcher will be -8000). consumer will send the last 1000 messages(<8000) flow request, so the dispatcher blocked continue.
This is the test log:
codelipenghui
on 11 Jan 2019
Related issues
 LvBay
·
3Comments
LvBay
·
3Comments
 dzmitryk
·
4Comments
dzmitryk
·
4Comments
 tfhappy
·
3Comments
tfhappy
·
3Comments
 bilahepan
·
4Comments
bilahepan
·
4Comments
 annubiz
·
3Comments
annubiz
·
3Comments