Prisma1: Permission queries are ignored in filters, allowing data to leak
Scenario
Business logic
- I have two types:
UserandGroup. - Users can be members of one or more groups.
- Important privacy constraint:
- Members of a group can see a list of all other users who are members of that group.
- Users should not be able to see the other groups that users are members of.
Sample data
- I have three users:
Jack,JillandBob - I have two groups:
New hireswhich has two members:JackJillFuture Managerswhich has two members:JillBob
Permission queries
- Read group -› permission query
- Read user -› permission query
For the team in Graphcool: I have set up a dummy project containing only the configuration detailed above. Project ID cj87xu7xv03020129kgke08yd.
Test cases that work as expected
_When authenticated as Jack_ (see sample data above)
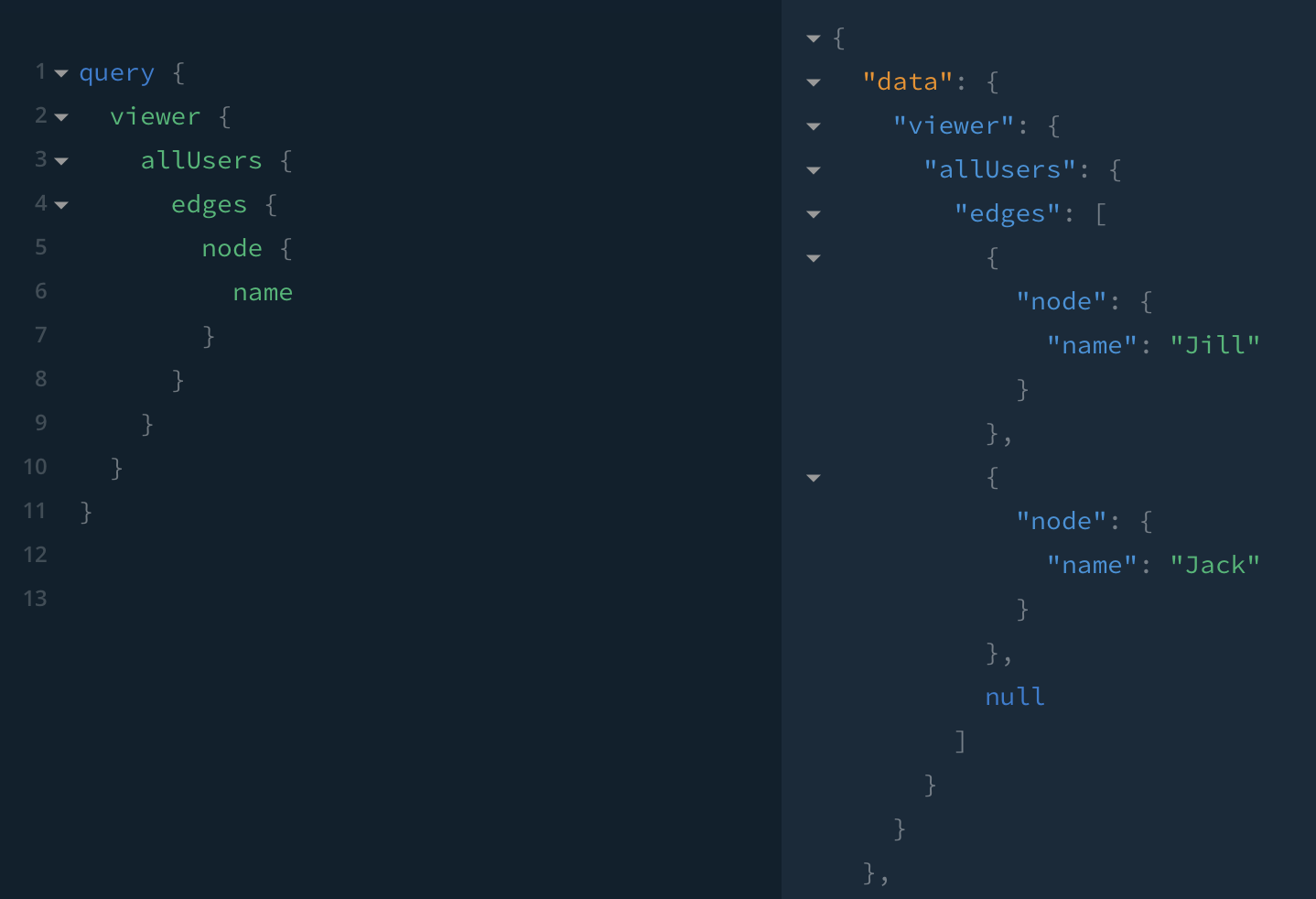
✅ When Jack reads all users, only Jack and Jill are returned, with a null node for Bob, who is not in any of Jack's groups.
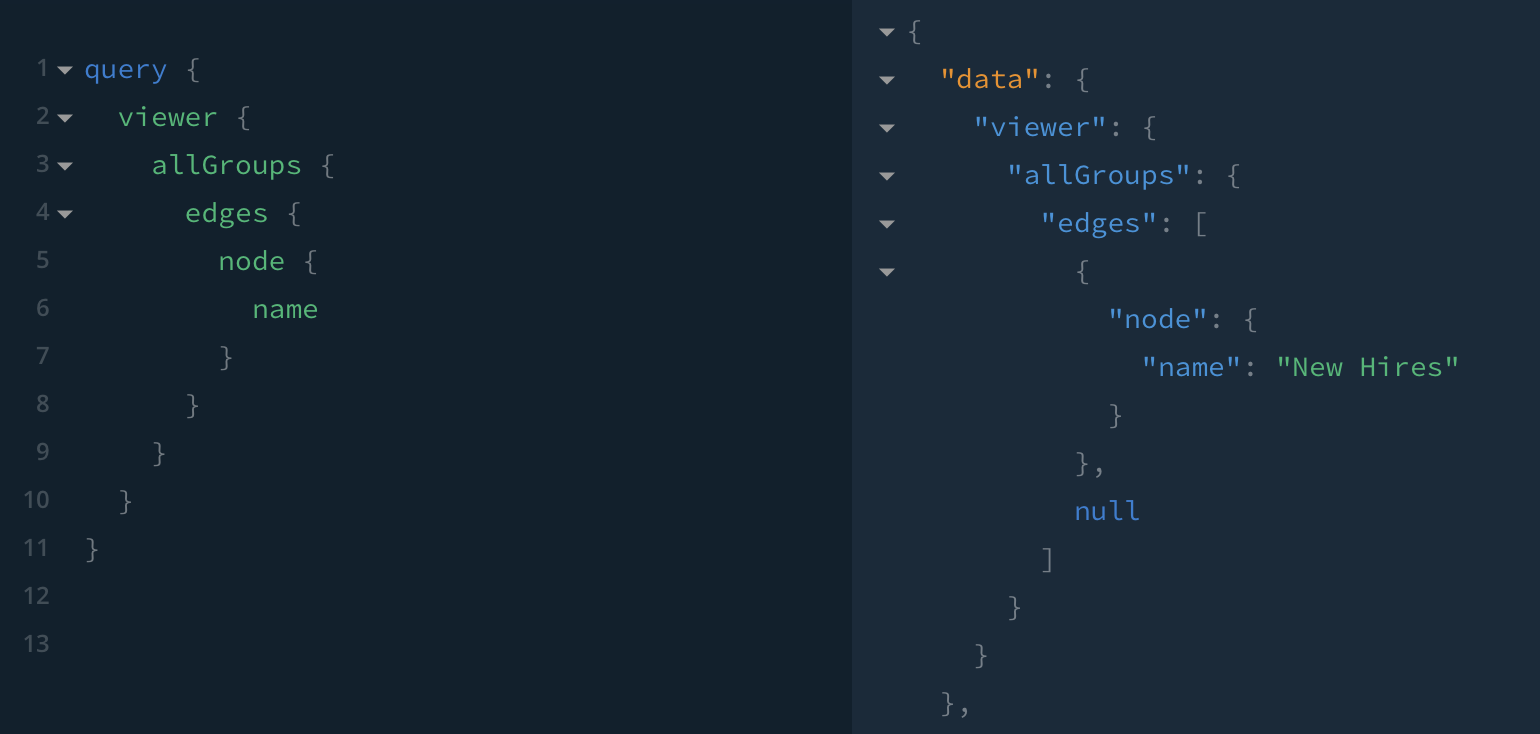
✅ When Jack reads all groups, only New hires is returned, with a null node for Future Managers as Jack is not a member of Future Managers
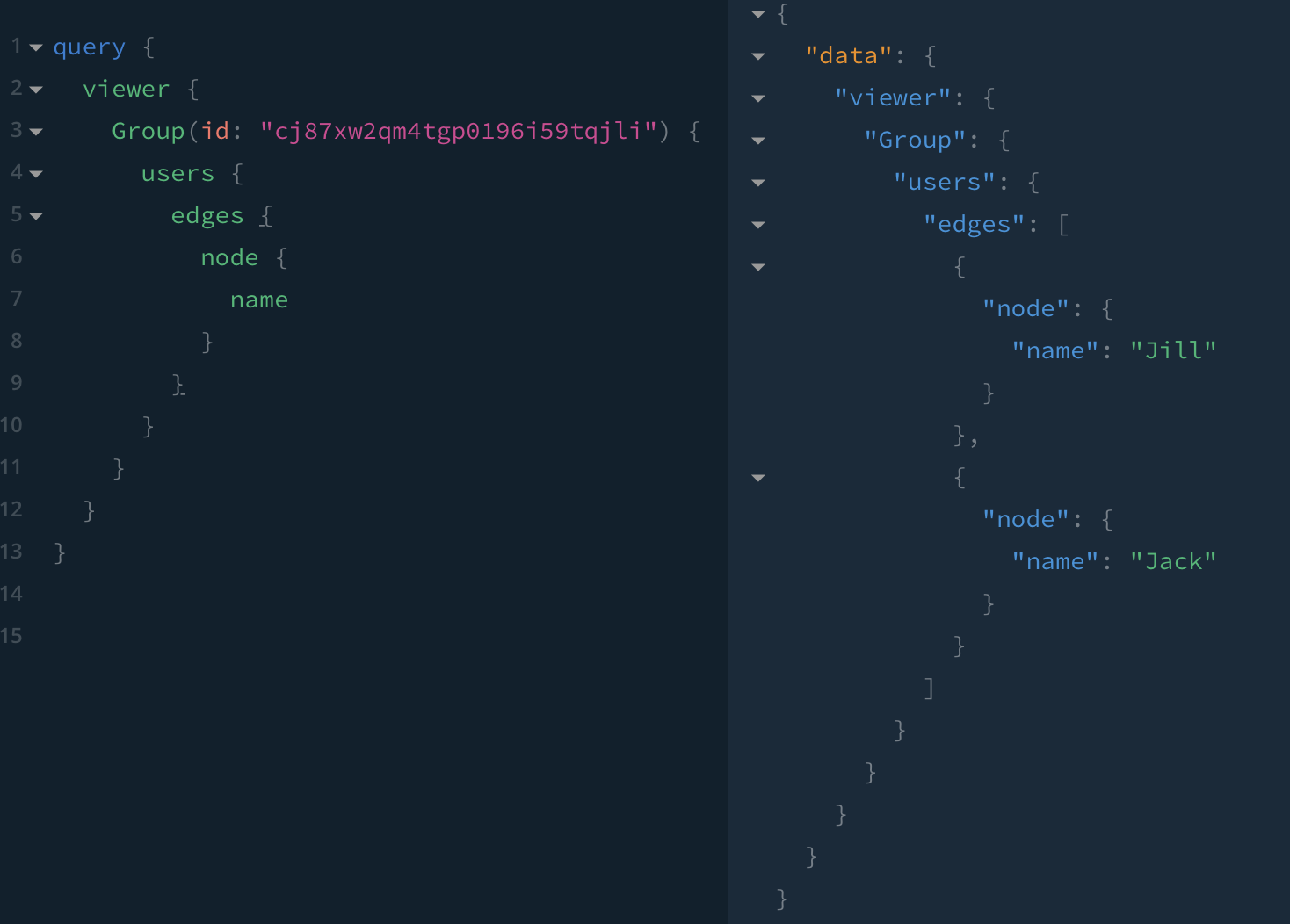
✅ When Jack lists members of the group New hires, Jack and Jill are returned.
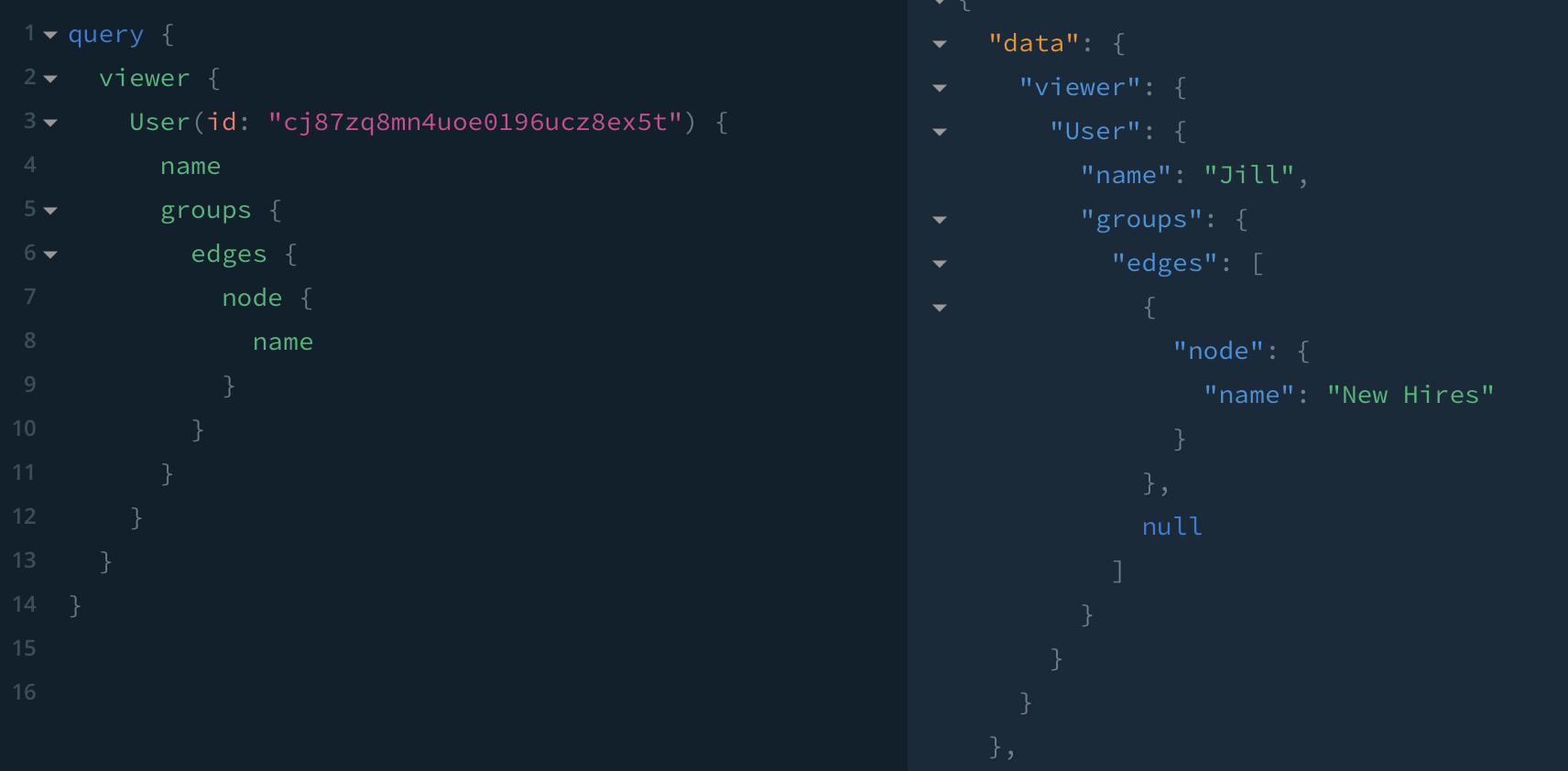
✅ When Jack lists Jill's groups, he can only see New hires; a null node is returned for Future Managers because although Jill is a member, Jack is not
✅ Jack is unable to read Future Managers directly; a null node is returned
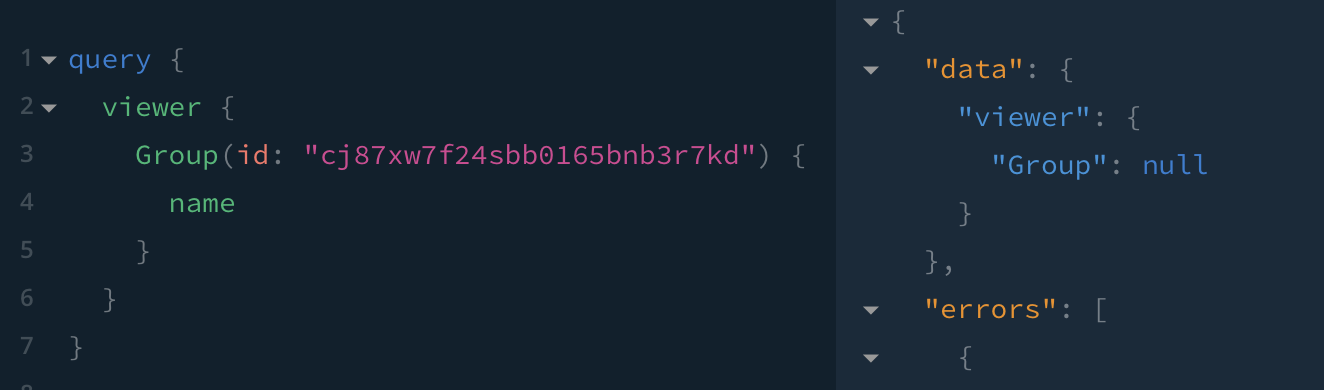
✅ Jack is unable to read Future Managers and its users if his query tries to return data about the group, such as name; a null node is returned and so it's members cannot be listed

Text cases that do not work as expected
🔴 Jack is able to read some users in Future Managers if his query does not try to read data about the group, such as name — Jill is returned because she is in another group with Jack. Bob comes back as null because he is not in any of Jack's groups.
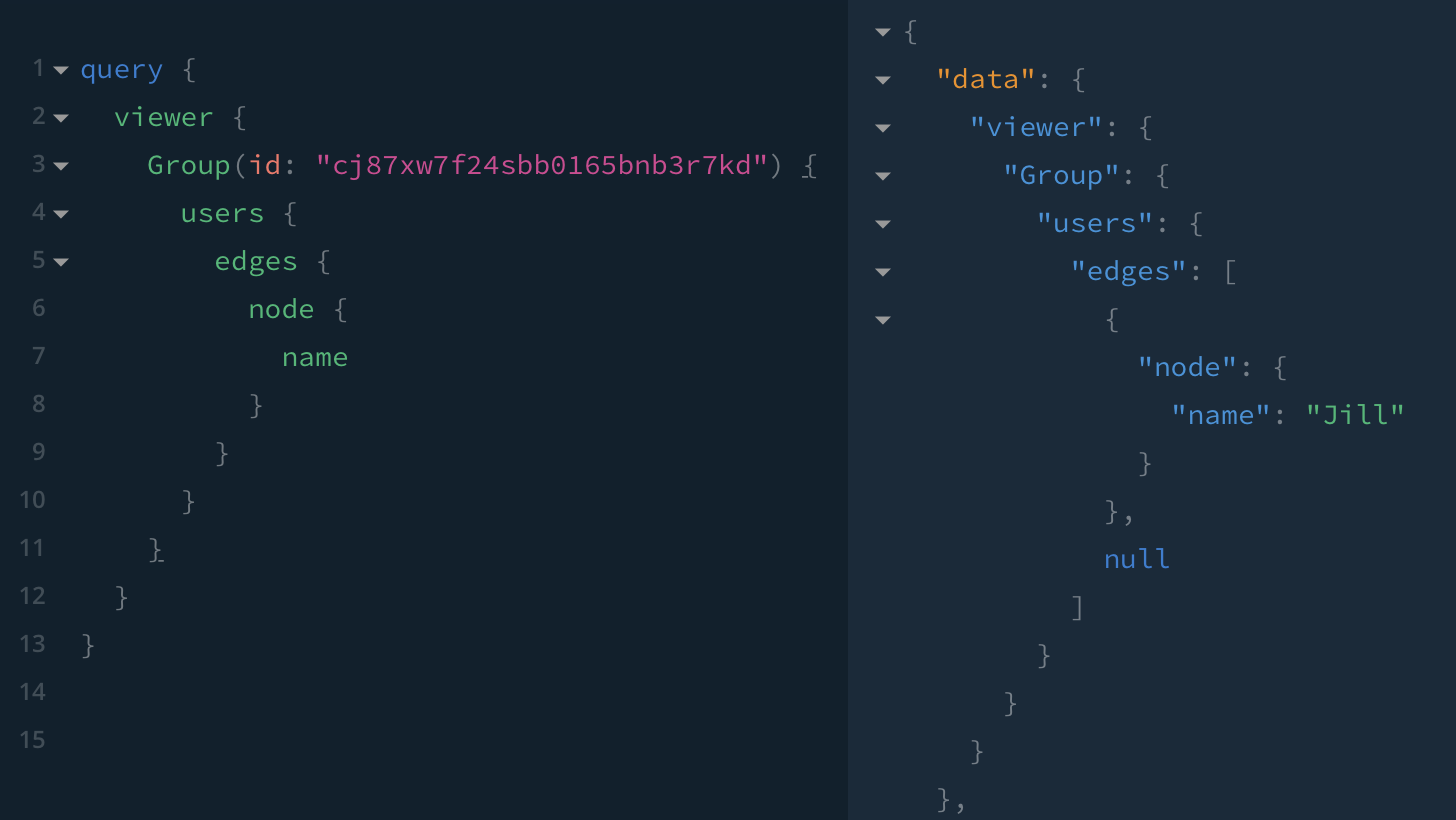
Expected behaviour: Jack is not able to read Future Manager (because he's not a member), so he should not be able to read its related/child nodes. Per the previous test case, I would expect a null node to be returned for the Group, with zero information about related/child nodes.
🔴 When Jack reads All Users with a filter specifying membership of the group Future Managers, Jill is returned; a null node for Bob is also returned, because Bob is not in any of Jack's groups.
Because this filter allows string matches on the name of a group, Jack can guess at group names… he doesn't need to know IDs.
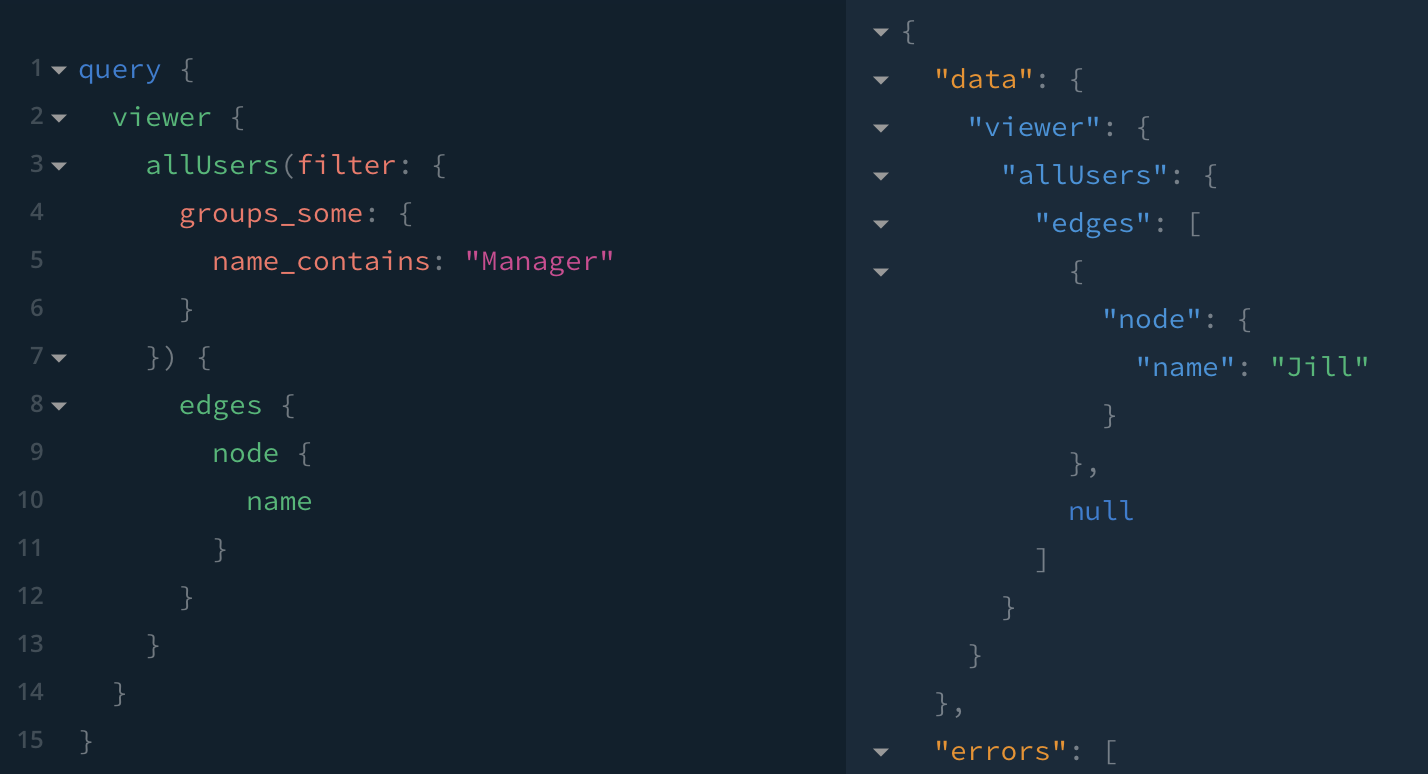
Expected behaviour: Jack cannot read Future Manager (because he's not a member), so he should not be able to retrieve users based on their membership of that group. I would expect no matching users to be returned.
 jonathanheron
jonathanheron
All 21 comments
Technically, in both cases you are querying users, and the results match the User READ permissions, so nothing is 'ignored' here. So the question is 'How can I set up my permission queries to get the desired behavior?'. I don't see an easy way to achieve this though. Maybe you can post your question on https://graph.cool/forum, so more community members can chime in?
 kbrandwijk
on 1 Oct 2017
kbrandwijk
on 1 Oct 2017
My mental model of permission queries is: "if the permission query says a particular node or field cannot be read by someone, the values in that node or field should be completely opaque"
To me, this is a reasonable expectation. And the two example scenarios I have above show that model breaking quite severely.
I thought through this a little more and I have a much simpler scenario that I think gets to the core of what's broken (to me) about the current interaction betweens filters and permission queries.
Let's say I'm building the next great employee directory system. It allows employees to see the org chart for the whole company, and managers can also see the salaries of people who report to them. Salaries should be hidden to everyone else though.
If I'm logged in as an employee (not a manager), and I try to see the salary of a colleague, I should not be able to read that field.
✅ If I try to read the salary field directly, I get null and a permissions warning, exactly as I would expect.
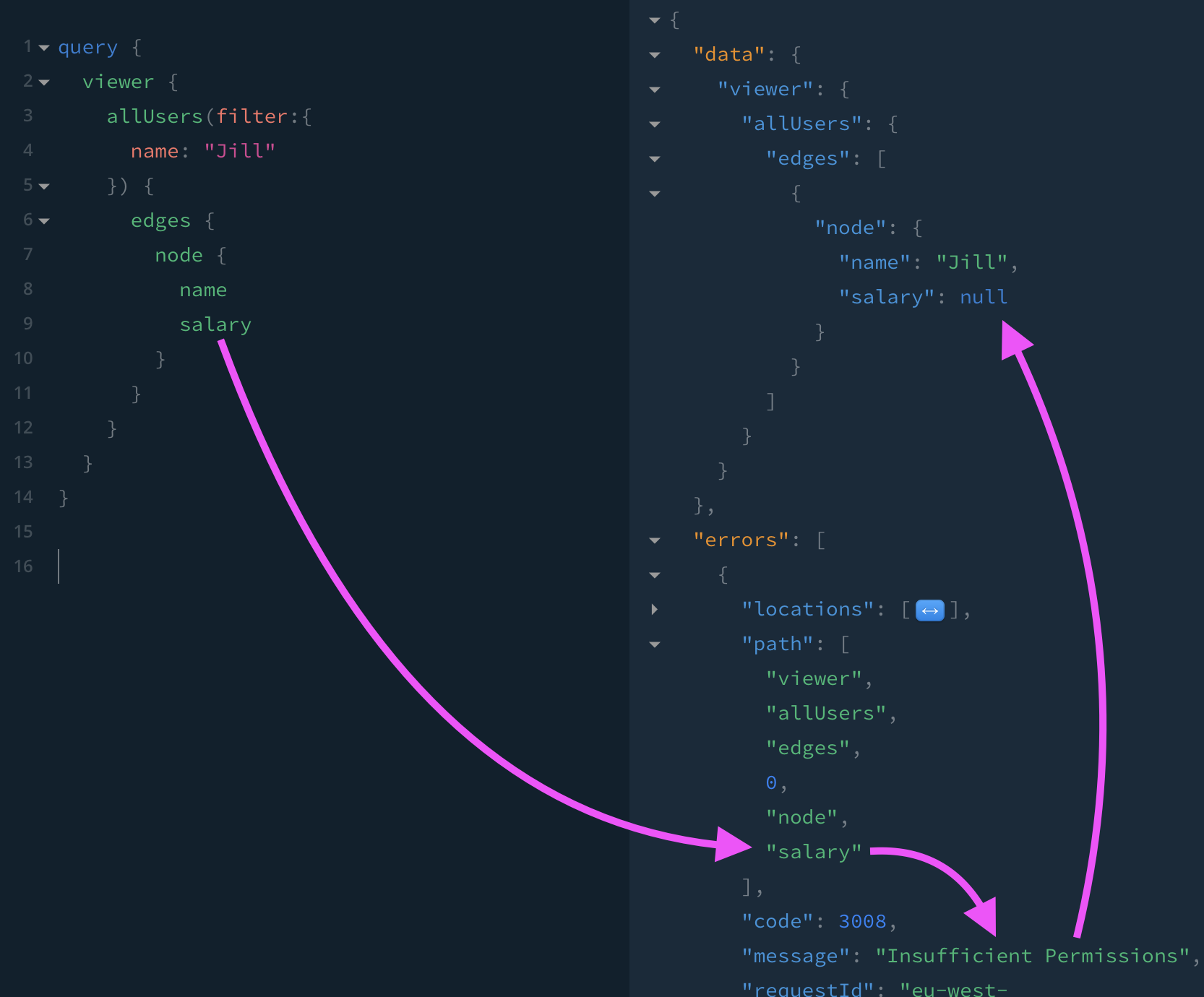
🔴 But I can check if her salary if matches a particular value, thus revealing her salary:

I can also check if her salary is greater/less than etc, so it's pretty quick and easy to determine her salary.
A similar approach could likely be used to, for example, count how many paying customers a Saas business has; or count the number of customer by pricing tier — without even needing to run the query as an authenticated user:
jonathanheron
on 1 Oct 2017
You have a valid point there actually, as well as in your previous issue related to this https://github.com/graphcool/graphcool/issues/530. Also it is something I touched upon here: https://github.com/graphcool/graphcool/issues/314.
@sorenbs @marktani Given these, and previous issues boiling down to the same, can you make a clear statement about this?
kbrandwijk
on 1 Oct 2017
@jonathanheron I think we have the following two scenarios that need to be changed, can you add to this?
Given users that belong to a group:
- You shouldn't be able to access child relations if you don't have
READpermission for the parent -> You shouldn't be able to access the users relation if you don't haveREADpermission on the Group. - The children_... filters should not return any nodes you don't have
READpermission for -> The groups_... filters should not return groups that you don't haveREADpermissions for.
kbrandwijk
on 1 Oct 2017
@kbrandwijk I think the child relations are a symptom of a higher-level problem.
If I do not have read rights to a given field, it should be impossible for me to filter based on the value of the field.
Today, this is not the case and, because I can filter based on the value of fields I have no access to, I can craft queries to extract ostensibly-protected data.
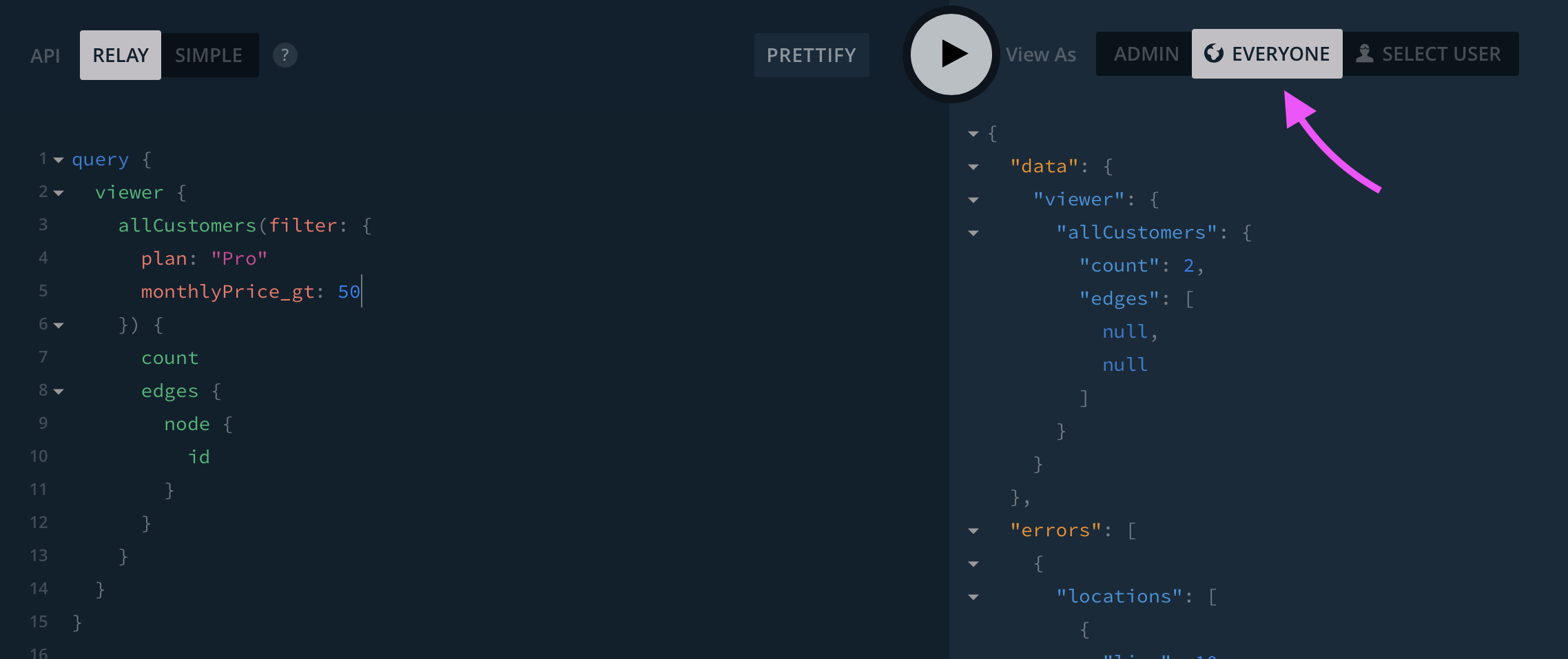
To spell out some thorny, non-obvious scenarios, imagine Tinder was implemented on Graphcool, and someone is suspicious that their partner Jack is cheating on them.
Does Jack have an account on Tinder?

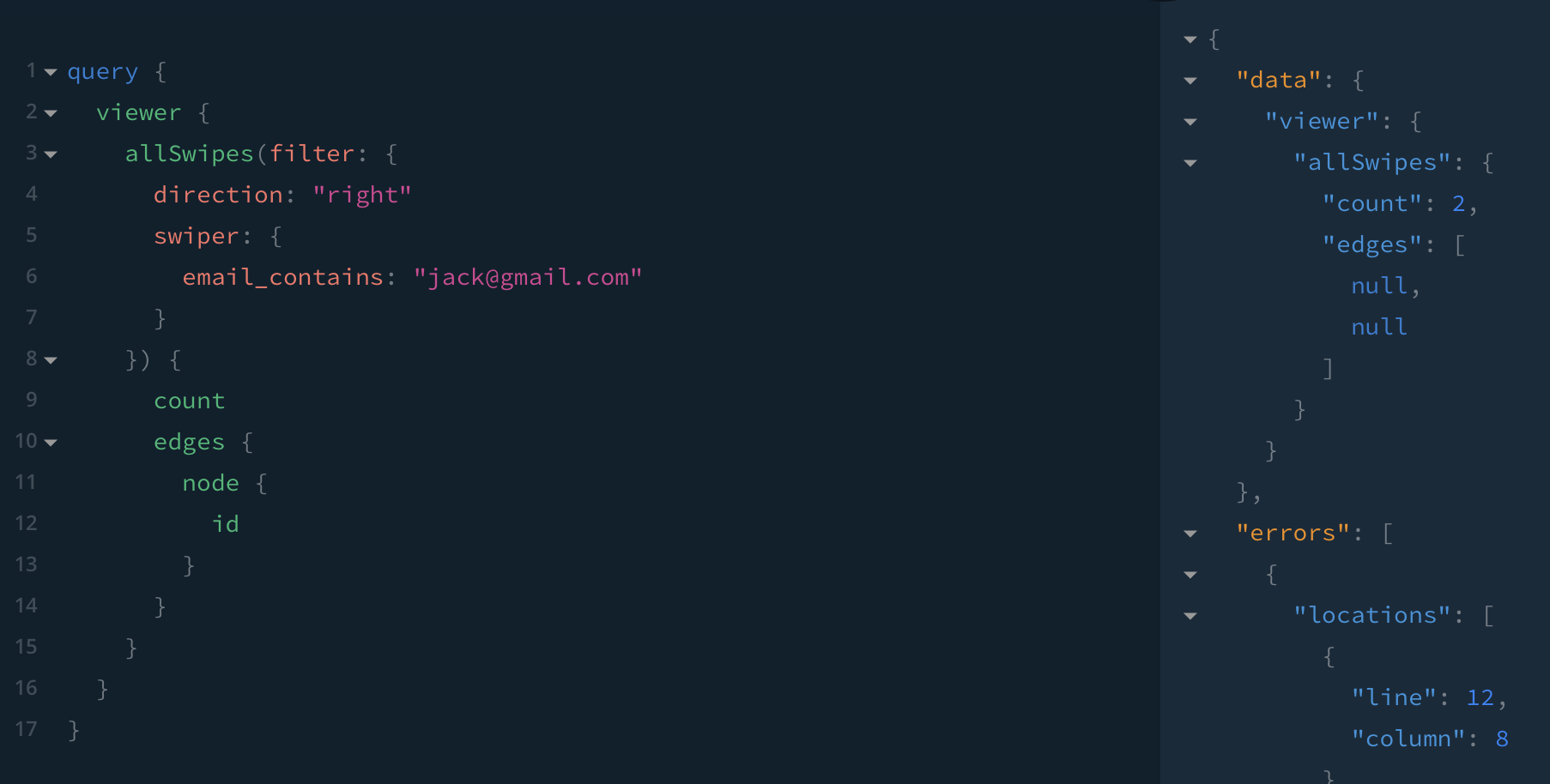
But has Jack been actually using Tinder? Has he been swiping right on anyone?
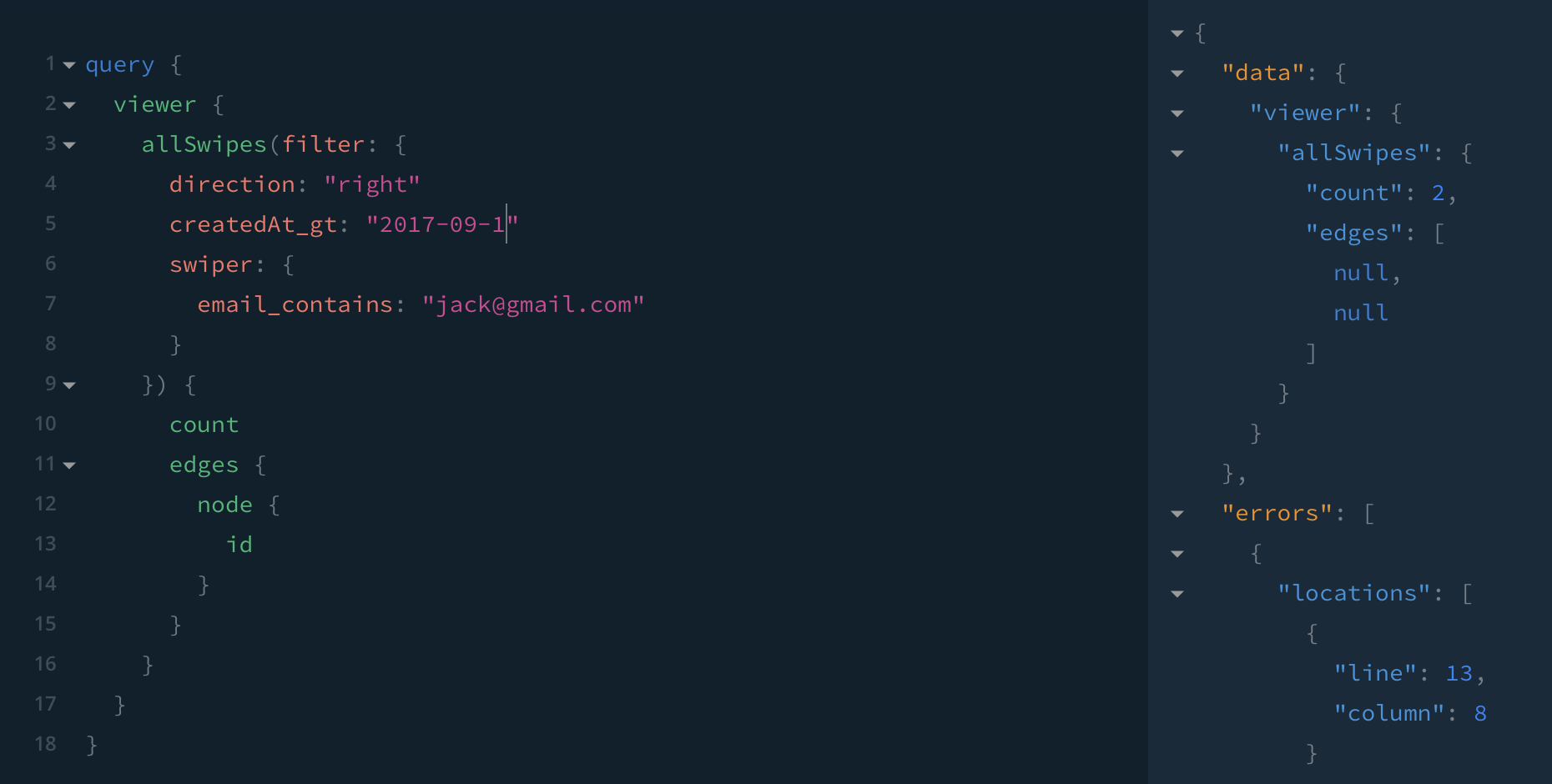
Maybe those swipes are from before we got together a month ago. Has he swiped right in the past month?
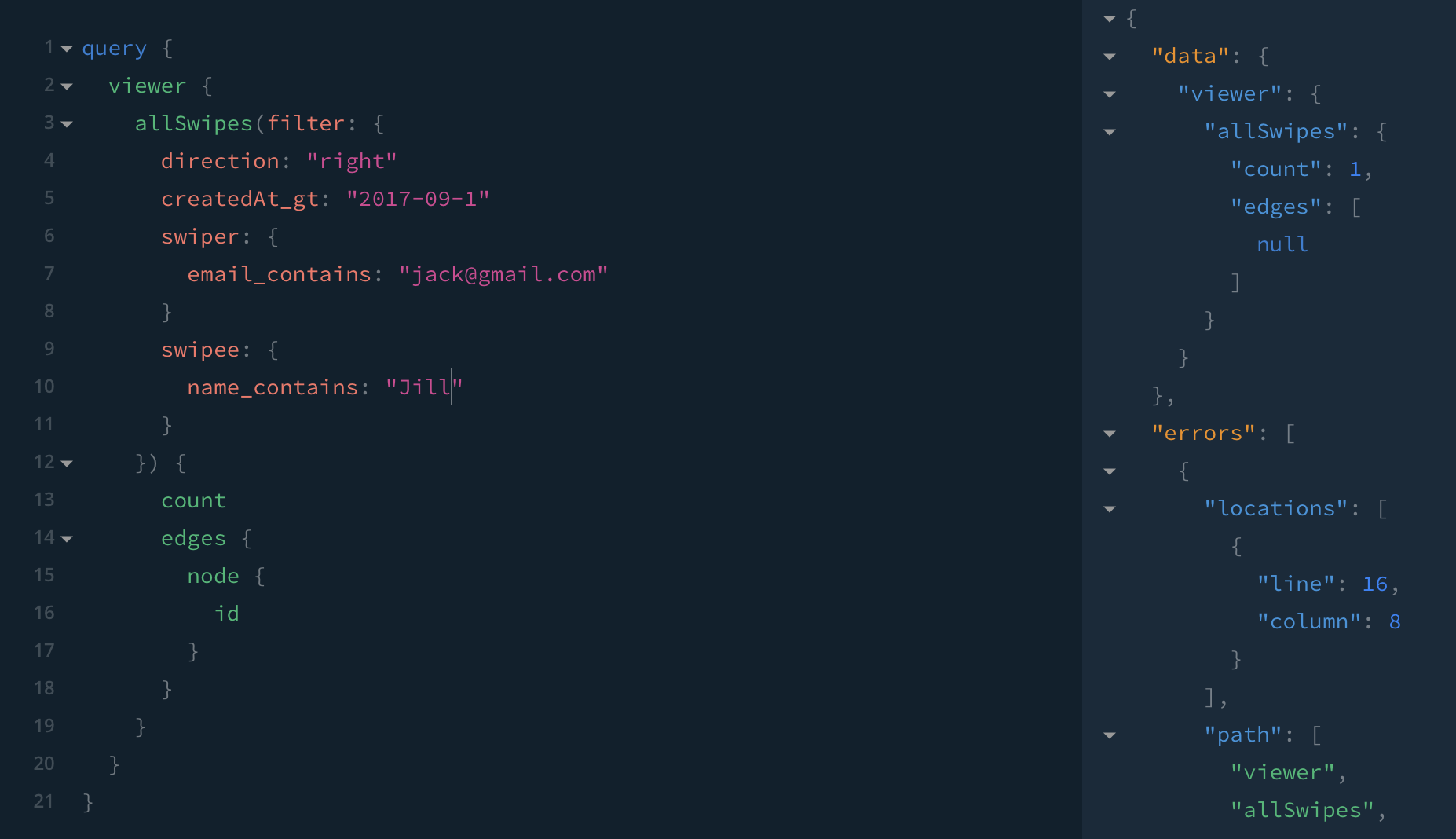
I saw a text from some named Jill on his phone, was that someone from Tinder?
In each of the above examples, I'm working with simple, predictable data like names, emails, dates. But you could also extract more complex data…
Let's say you are building a Saas app that integrates with multiple 3rd party services. To facilitate this, you collect and store API keys such as
{
"accountId: "123",
"service": "intercom",
"key": "YTliXzY5MGYyOTk4MmZlMzoxOjAdG9rOjVhODE1YWQxX2IyMDE3Y185",
}
If Graphcool were to implement case-sentive filter matching, a malicious user could extract API keys by iteratively querying for progressively-longer strings and checking for a match.
To begin with…

A little later…

Much later…
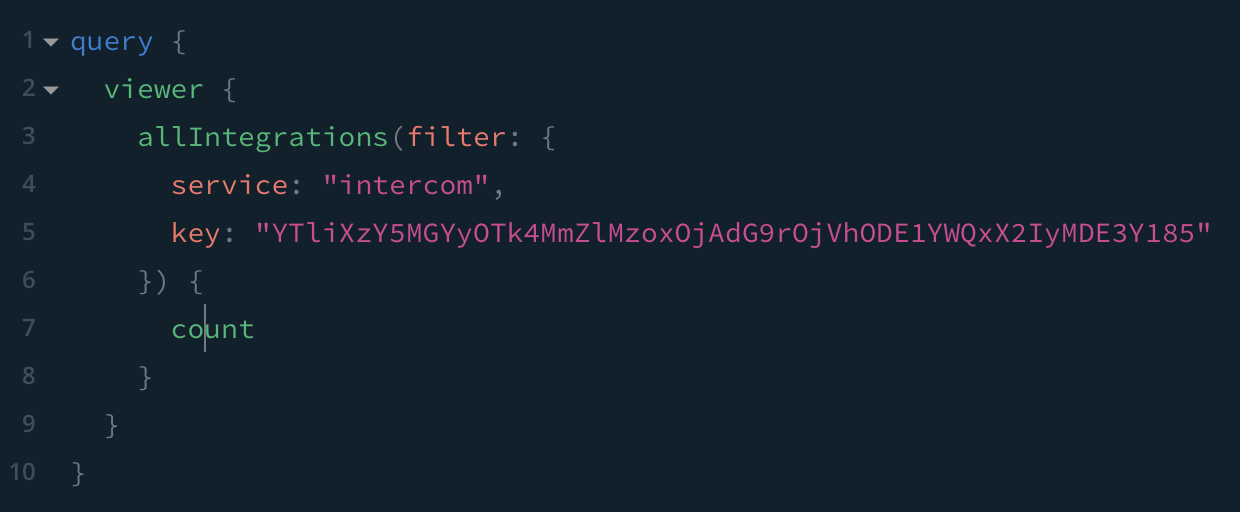
This is a contrived example. A huge number of requests would be necessary to extract a key, but an almost incomparably small number of requests compared to trying all possible API key combinations. If I had stronger math skills, I'd work out the actual numbers, but this sort of hack should not be possible at all.
jonathanheron
on 1 Oct 2017
I think those cases are still covered by my abstraction. If you had no read access on users (except for your own user node), the filter by child (so in this case 'swiper', which is a user), should not return results for other users. In your first example, I don't think the count would return '1' with the current permissions, did you actually implement this?
In the second example, again, if you don't have read access on the Integrations Type, the count should not return '1'.
kbrandwijk
on 1 Oct 2017
@kbrandwijk My reason for disagreeing with framing this as an issue related to parent-child relationships is this: filters in Graphcool completely bypass permissions restrictions for all nodes, fields, and relationships. It's a much bigger problem than just parent-child relationships.
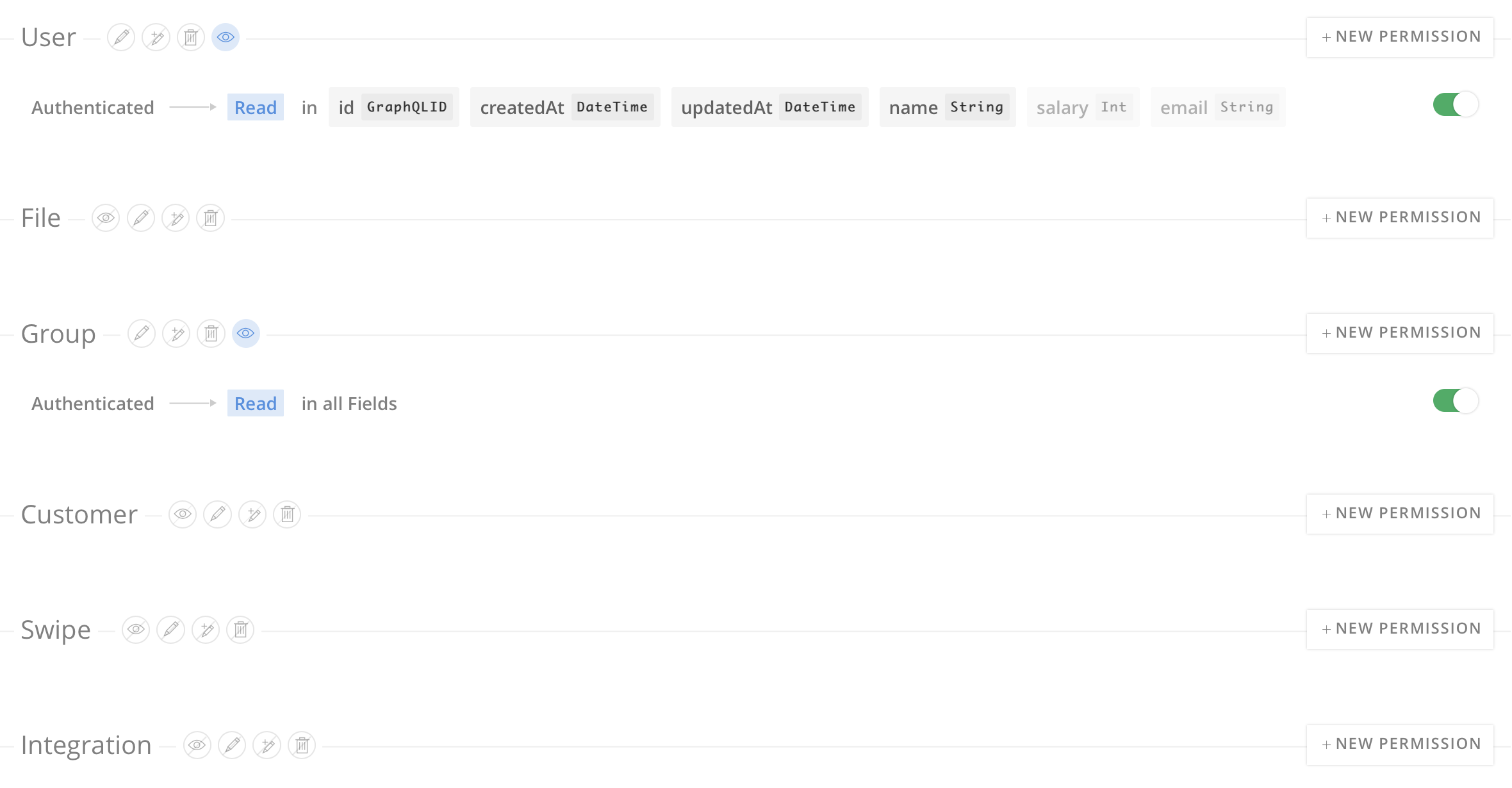
All of the examples above show real results from the Graphcool console. You can see the first and last Tinder examples, and first Integrations example, here: https://graphqlbin.com/7L6hZ
Here are the permissions configured in the sample project:
jonathanheron
on 1 Oct 2017
That's strange, because you don't have any permissions defined on Swipe, you shouldn't get the count.
However, this is related to: https://github.com/graphcool/graphcool/issues/225.
I still don't fully agree that permission are ignored for all filters. It's about correctly applying the permissions to the results of those filters that matters. In the end, it doesn't matter how you get to a certain subset of data (relation field, current user field, filter, paging, etc.), permissions need to be applied correctly to the results. In your case, the fact that meta information (a separate field in the simple API) ignores all permissions is a different issue. Another issue is that permissions are not applied to empty resultsets, which also leads to implicit data leaks.
But a filter in itself has no relevance for permissions as far as I can see from your examples.
kbrandwijk
on 1 Oct 2017
In the end, it doesn't matter how you get to a certain subset of data (relation field, current user field, filter, paging, etc.), permissions need to be applied correctly to the results.
…
But a filter in itself has no relevance for permissions as far as I can see from your examples.
@kbrandwijk I disagree about this. And I think this is a good example…
Imagine Glassdoor ran on Graphcool. One feature of that site is you can tell them your salary (which is only ever shared anonymously).
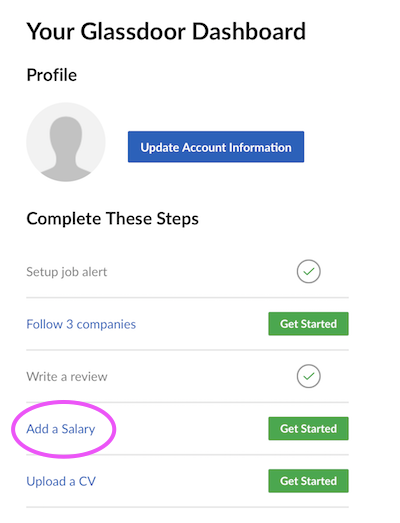
When I query Graphcool as an unauthenticated user, I can filter using any field on any type, even if types/fields are restricted to authenticated users (or further restricted through a permission query). In my hypothetical Glassdoor-on-Graphcool example, if I try to find out if [email protected] has a salary greater than 30000, what I will observe in the response is:
- Because Graphcool applies the permissions to the _results_ it will correctly return a null node.
- Because Graphcool applies the permissions to the _results_ it will return a count of
1, thus confirming that[email protected]has a salary greater than30000.
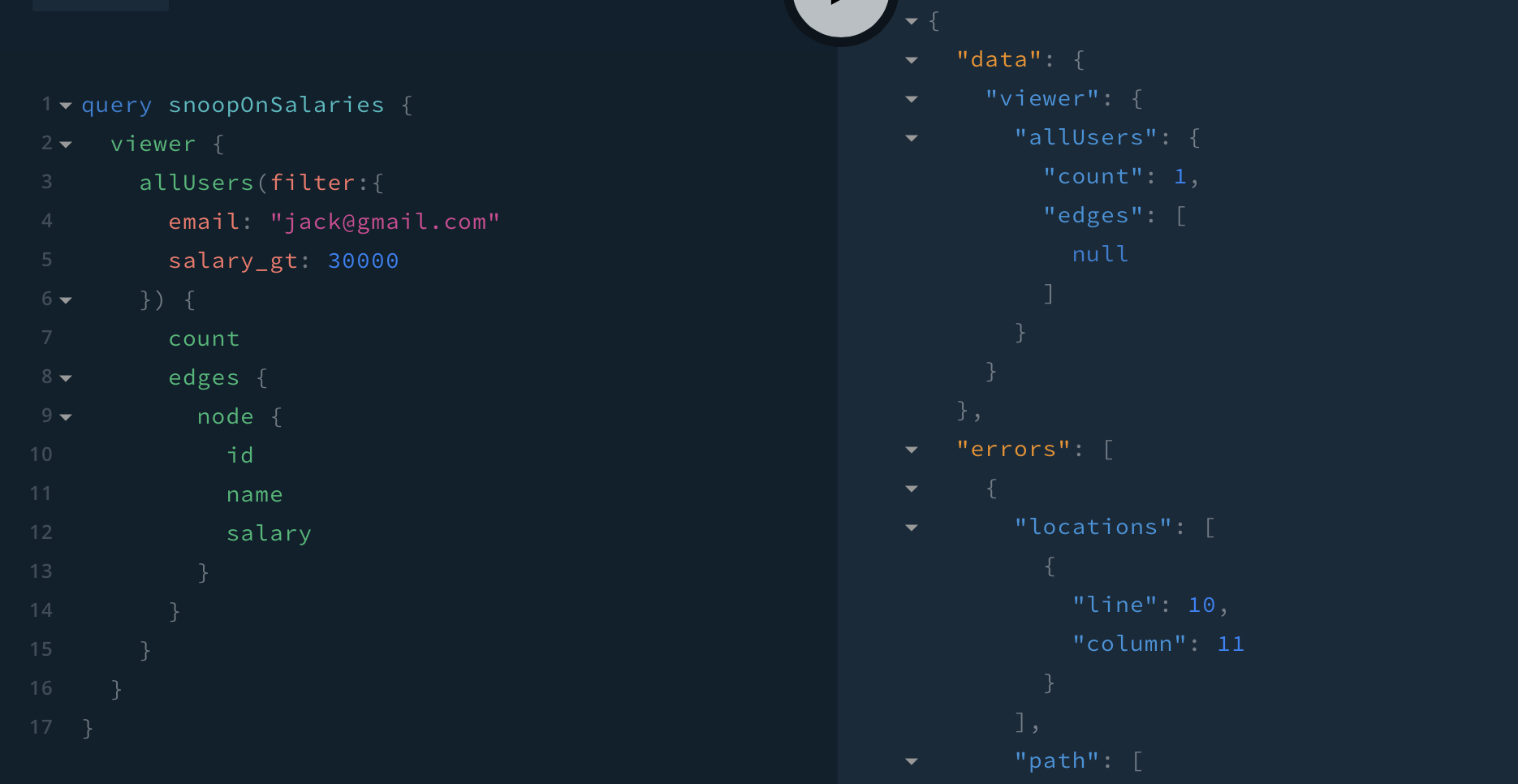
-› https://graphqlbin.com/gLptw
In a simplistic scenario, attempts to filter a query using a field I don't have access to, should completely fail and throw a permissions warning, just like they do when I try to read a field I don't have permission to read.
Permission queries greatly complicate this however. I might have the right to see the salary of a subset of users. In that case, the filter should work but return only users who match the filters AND who I have access to see their salary. Crucially, the count on that query should count only the people whose salary I can see.
To illustrate this expected behaviour…
User | Salary | Groups
-----|--------|-------
Joe | $100,000 | Engineering
Jane | $100,000 | Engineering
Jack | $75,000 | Engineering
Jamie | $100,000 | Product Design
Imagine Joe is the manager of the engineering group, and we have a permission query that allows managers of a group to read the salary field of a user who is in a group they manage.
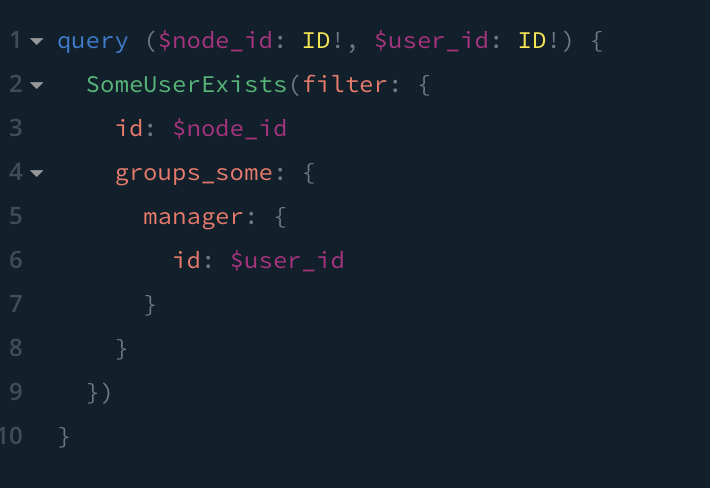
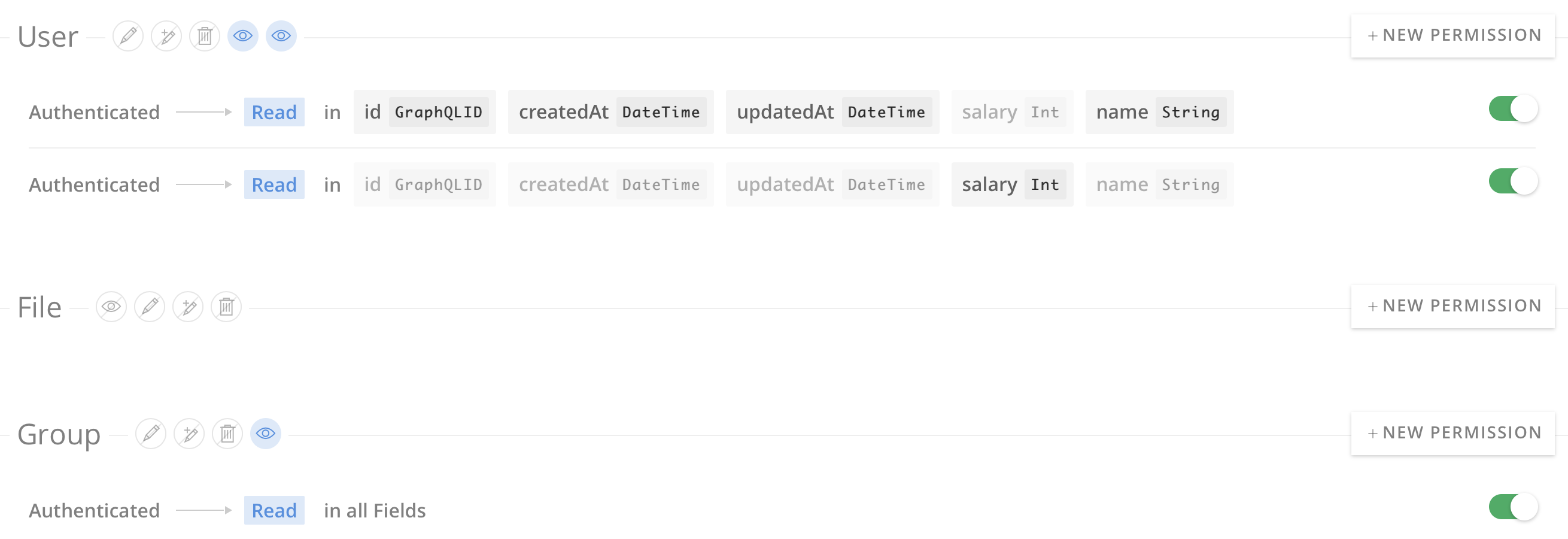
Permissions also dictate that authenticated users can see everything else about Users and Groups, other than their salary.
Here's all the sample data in Graphcool, queried as an admin (so that permissions don't apply):
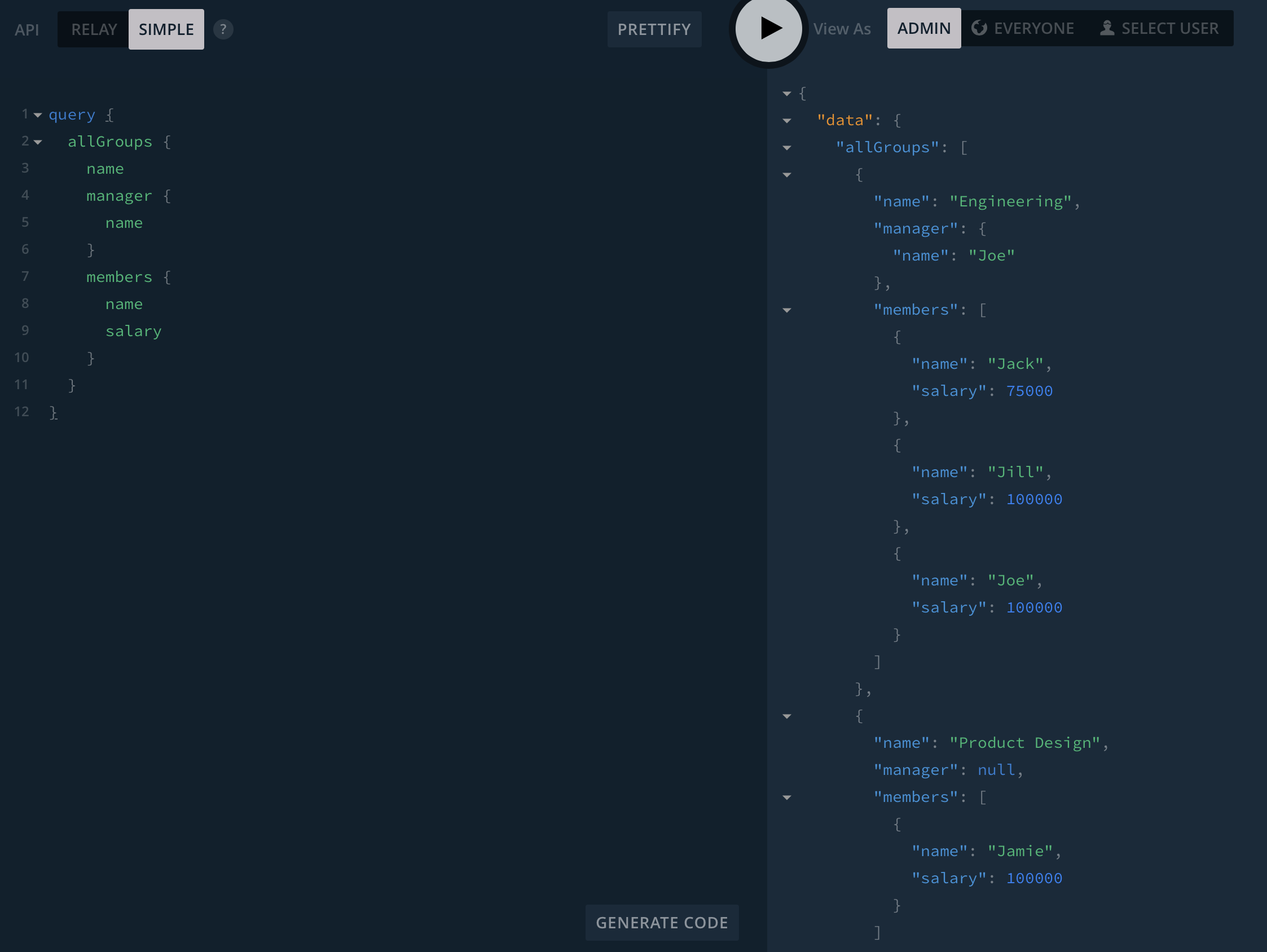
When I run the same query as Joe (the manager of Engineering group), you can see that Jamie is returned as a null node because Joe doesn't have permission to see his salary:

Things get interesting when I filter by people with a salary over $80k. Note how Joe can see there's a user in the Product Design group with a salary of more than $80k.
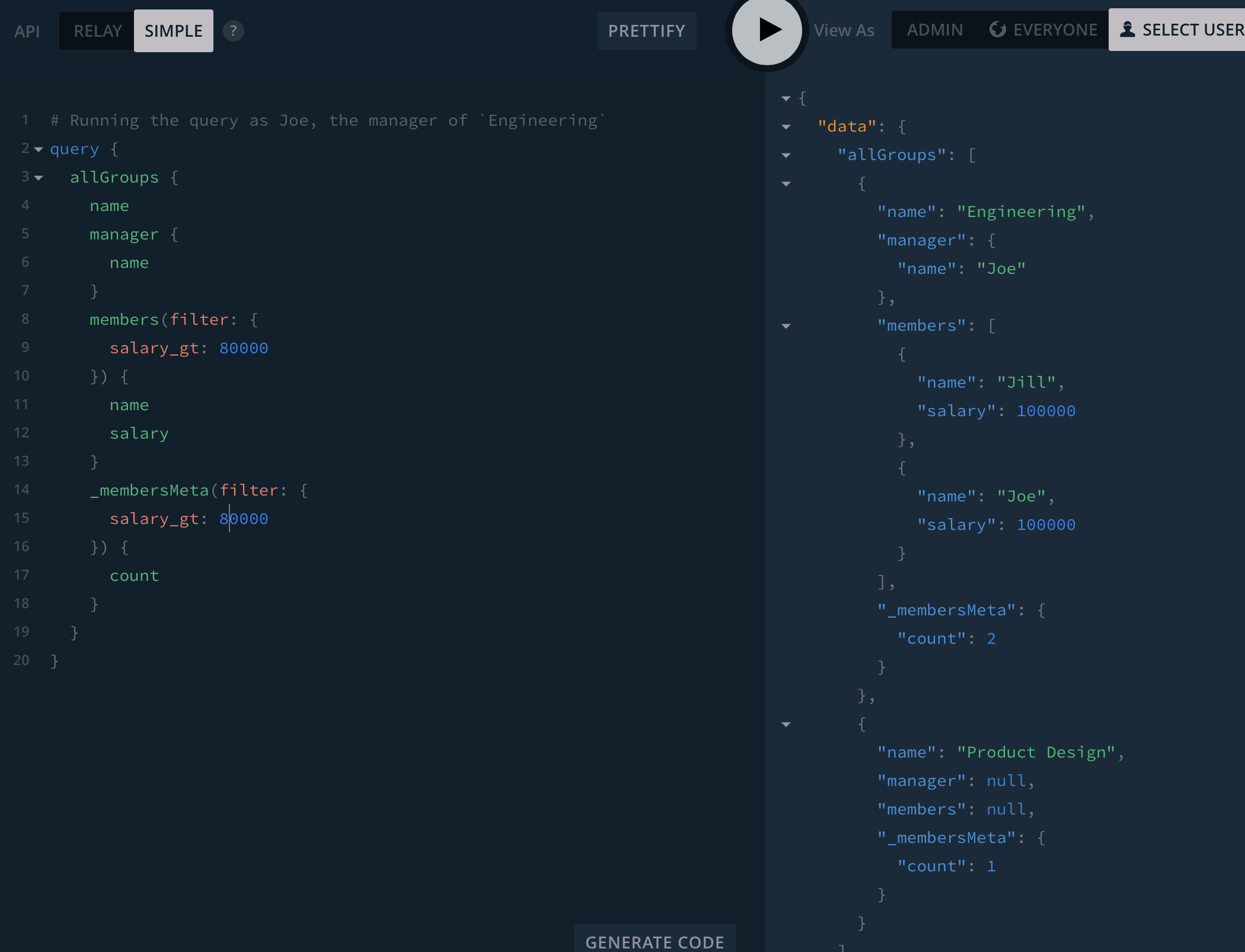
Let's tighten the query to only look at the Product Design group, and remove the query for the salary field so that Joe can see the name of the users in that group who match the filters:
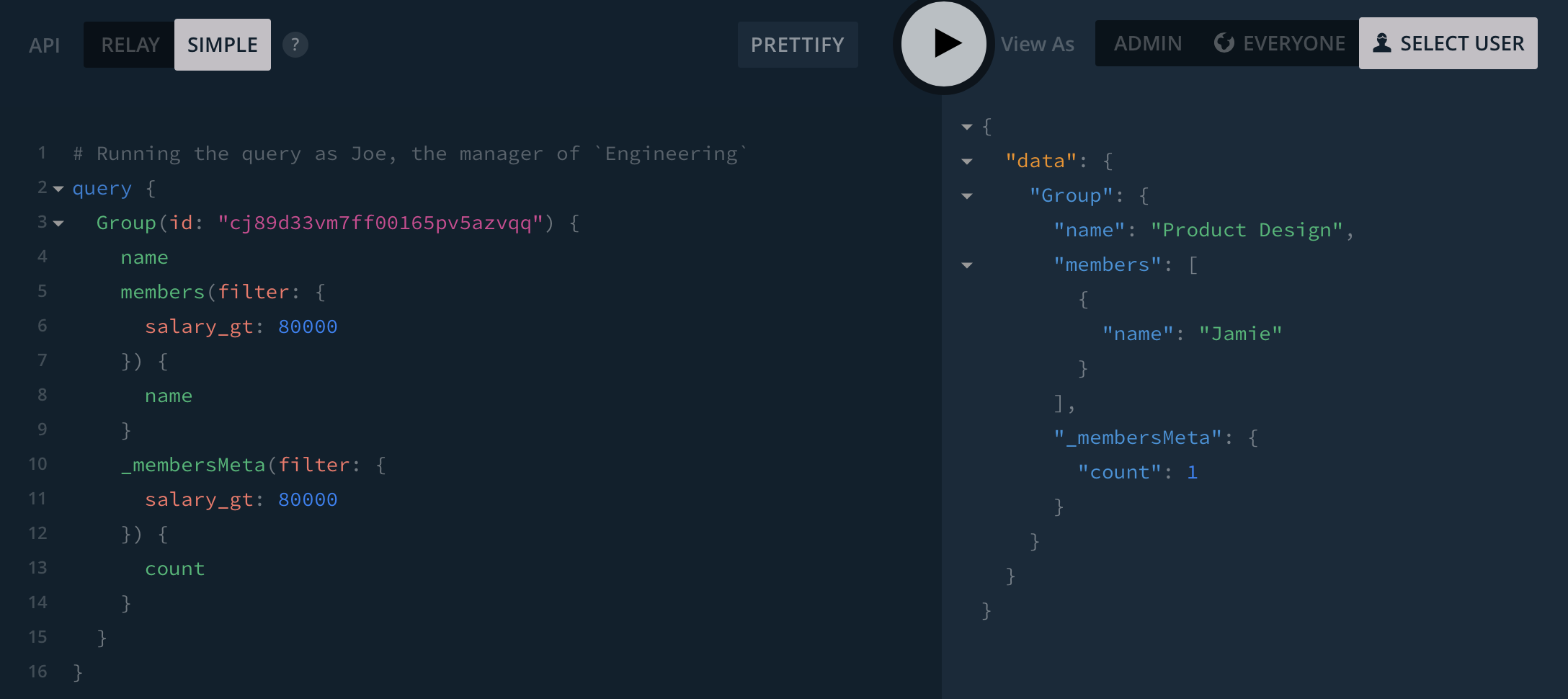
Right now, Joe can see that Jamie has a salary of >$80k despite not having permission to read the salary field on Jamie (because Jamie is not in a group Joe manages).
In my opinion the right behaviour would be to return and empty list of members (not even null nodes) and a count of 0 in this instance:

jonathanheron
on 2 Oct 2017
Oh, and I forgot to say… having permissions to specifically cover _meta is not a fix, because that means hiding the count value when it can be useful.
jonathanheron
on 2 Oct 2017
Well, regarding the _meta count permission, that would not hide the field, but simply take permissions into consideration when counting, so that would solve half of your problems.
The other issue you mention (filtering by a field you don't have access to if it's not included in the results, is indeed not covered by this, or my earlier abstractions.
So it took some effort, but now I do agree with you that in addition to the parent-child relation permission issues and the meta permission issue, there's also the issue you mentioned before: you shouldn't be able to filter by fields you don't have READ permissions for.
kbrandwijk
on 2 Oct 2017
So by now we have:
- The _meta field ignores
READpermissions - Permissions for parent are ignored when just querying child relations
- All field filters (including collection filters like _some, _every etc.) should adhere to
READpermissions on the fields you are trying to filter on.
Is that correct?
kbrandwijk
on 2 Oct 2017
Thanks @kbrandwijk, your summary looks spot-on.
jonathanheron
on 2 Oct 2017
Thanks for this detailed writeup Jonathan! And thanks for helping move this along Kim :-)
You touch on 2 different areas. I'll address them individually below.
Relations
When you specify a relation between two models, you can specify permissions for the relation. Currently you can enable connect
and disconnect. For relations there is always an implicit read permission. See this feature request for explicitly controlling read permissions on relation fields https://github.com/graphcool/graphcool/issues/724
Meta and allX queries
Most of the unexpected examples are around the count and allX queries. Before diving into this it is important to understand how permission queries work.
The permission query system is designed to implement logic that decides whether the given user has access to particular fields on a specific node.
The issue here is that the top-level allX and count queries break out of this model. Normally, when adding functionality like this in your API, you would take great care to only allow specific filters when listing or counting all data. In the Glasdoor example, you might want to expose the number of users for each group, but you don't want to allow counts by arbitrary queries.
The solution to this issue is to limit access to the allX and meta queries. We are working on several ways to do this. I imagine people will want to use a mix of them depending on use case:
Query Whitelist
The full Graphcool API is really convenient when developing applications. When an application is running in production, you generally want to lock down the API as much as possible.
The query whitelist will make it easy to capture queries sent by the developer while developing and explicitly allow them in production. This will allow you to run in unrestricted mode during development while completely locking down your API in production.
The added benefit of this approach is that it becomes very easy to perform a security audit as all whitelisted queries are available in a central list.
See this feature request https://github.com/graphcool/graphcool/issues/134
Both Relay and Apollo has support for this concept through Persisted Queries https://dev-blog.apollodata.com/persisted-graphql-queries-with-apollo-client-119fd7e6bba5
Proxy Layer
The GraphQL community is currently investing heavily into finding the best way to transform and merge GraphQL apis in a proxy layer. Efforts include https://github.com/aeb-labs/graphql-weaver, https://dev-blog.apollodata.com/graphql-schema-stitching-8af23354ac37 and our own https://github.com/graphcool/graphql-transform-schema
Our plan is to make it easy to deploy a proxy together with your GraphQL API and lock down direct access, so that the proxy can be used to hide specific functionality from the public API.
Simple permissions to disallow access to allX and meta fields
Many people have requested a way to disable or limit access to specific allX and meta fields. Our plan is to roll out Query Whitelist and Proxy Layer first, and then reevaluate if there is a need for a more lightweight approach.
Today we are releasing custom resolvers that allow you to re-expose a subset of functionality https://www.graph.cool/forum/t/feedback-schema-extensions-beta/405
Additionally we are exploring ways to manipulate filters on the server without using a schema-mapping proxy as described in https://github.com/graphcool/graphcool/issues/530#issuecomment-329736894 but I'm not convinced this is the right way to go.
 sorenbs
on 3 Oct 2017
sorenbs
on 3 Oct 2017
Thanks for the lengthy response. I've a bunch of reading to do to wrap my head around this :-)
jonathanheron
on 4 Oct 2017
@sorenbs You touch on a few great points, but none of them address the main issue around filtering we mentioned above (except for Query Whitelisting/persisted queries, which I think is one of the biggest emerging anti-patterns of GraphQL at the moment).
I like #724 alot, that addresses the relations permissions issue.
I don't believe limiting access to _meta fields is the solution in this case. I believe the current implementation of _meta fields to ignore permissions on the records it aggregates over is a flaw that should be fixed.
Also, I do not believe that this is a great use case for the Proxy layer concept. It's main advantages are merging and 'filtering' GraphQL api's, not fixing what should work properly in the original API endpoint you're proxying.
I seriously urge you to tackle these issues before adding new tools to the toolbox, like the praised Proxy or the dreaded persisted queries. Permissions are an essential component in the solution, and simply by looking at the number of issues and FR's around this topic, it falls short of expectation. This needs to be solved at the core.
kbrandwijk
on 4 Oct 2017
@sorenbs While I don't have a deep understanding of each of the strategies you propose, from what I can tell they will not easily solve the following scenario:
- I am a manager with access to the company's HR software.
- The HR software enables me to see all employees and all employee groups.
- The HR software enables me to filter employees within _my groups_ based on their salary.
- To allow this, there is a whitelisted query that enables me to pass in a
group IDand a salary criteria to filter on.
- To allow this, there is a whitelisted query that enables me to pass in a
- The page which lists matching employees includes a pagination control and shows a count of matching users.
Because the query whitelist allows me to pass in a group ID and salary criteria, I can do something like this:
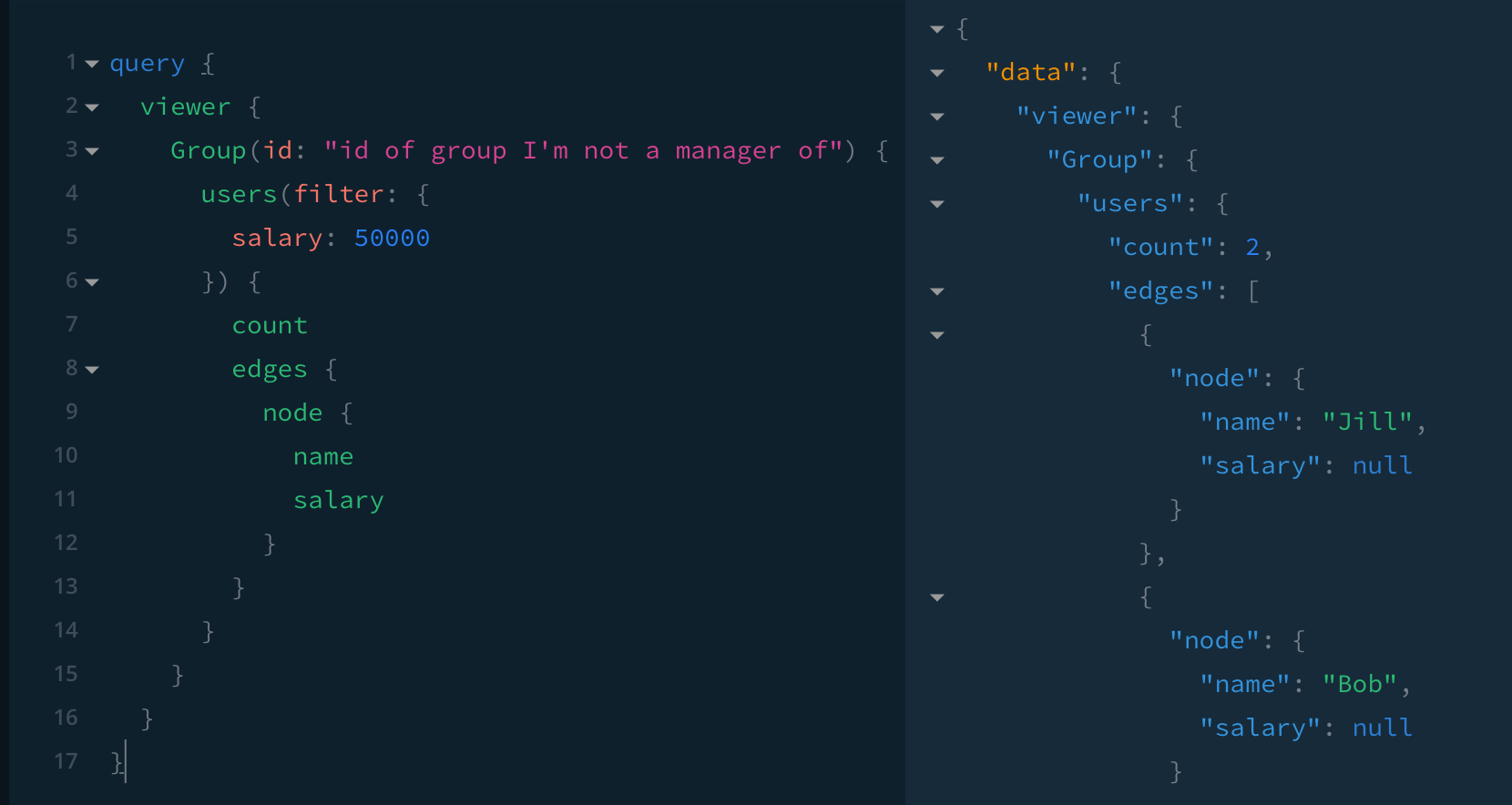
Security-related behaviours should be easy to implement and reason about
Perhaps this could be solved by manipulating filters on the server to validate I'm only using this particular query on a group I'm a manager of, but that is _very_ complex to reason about, or to audit. It means that restrictions need to be expressed in two places (permissions and a proxy) in two different ways. Even with this trivial example, there's huge scope for mistakes slipping through unnoticed. What about a more complex app with a more complex data model?
The potential real world cost of insecure-by-default
I'm very aware that Graphcool are not optimising for my use case (I'm a product manager building workflow tools as side projects), and customers like me probably aren't a safe-bet for growing a successful business :-)
What occurs to me though is this: securing data is hard. Protecting users' privacy is hard. The general trend of the internet is for data breaches and privacy breaches to get worse. And for the abuse of data to become ever more compromising for individuals.
In the context of "Graphcool is where I store my data", I would propose that making it easy to protect access to sensitive data should be of paramount importance.
To spell out a nightmare scenario:
If Graphcool were to be very widely adopted by a lot of products, and many of those products failed to implement the multiple layers of protection necessary (in the current proposal) to stop queries that trick Graphcool into disclosing the existence of a user account, it becomes feasible to do large-scale automated attacks that identify the sites and services users are members of.
What if membership of those sites reveal political affiliation, activism, or sexual orientation that is illegal or problematic in a given country?
What if membership of those sites allows someone to build a profile of people so they can be targeted for manipulation?
In a world where the data held by online services can be weaponised so easily, it is essential that we (the people building these services) strive to protect that data.
Graphcool is in a position that it can choose to make protecting data _easy by default_. Permission queries are very close to right solution. They make it relatively easy to protect data from being directly read. But if they don't also protect data from being _inferred_ through filters, I think there's a strong risk they give developers a false sense of protection.
Access control has established conventions for comprehensiveness and trustworthiness
If I define ACLs in a database or file system, those ACLs apply all of the time in every scenario.
If I remove someone's Admin rights in my Saas app of choice, I know they'll lose access to all Admin functionality, all of the time.
When I restrict a user's access to a database or table in MySQL, I know with certainty they can never access or infer anything about the data they don't have access to.
Permission queries _sound_ like they have the same comprehensiveness, and when you first start using them they _look_ like they are comprehensive. But they aren't.
The road travelled by PHP and Rails
There are two software projects that come to mind when I think about the power vs. security-by-default decision…
PHP made dynamic web development accessible to millions, but made it incredibly easy to allow SQL injection. Countless sites over the years have suffered as a result of this.
Ruby on Rails included smart defaults (no SQL injection) and optimised for productivity. Almost a win win — but the decision to allow mass assignment of variables by default meant that Rails apps would, by default, be exposed to certain bugs and attack vectors. Over time, Rails learned from the painful experience of its adopters, and now _"rails complains abouts calling model#update_attributes without first setting up your attr_accessors"_
Are permission queries the right design?
It sounds like getting permission queries to work predictably (and automatically) with filters is difficult or infeasible. Is there a different design that could both put power in developer's hands and ensure it's easy to be secure by default?
jonathanheron
on 4 Oct 2017
There has been a lot of feedback on the current permission system already (including by me), but never so eloquently put as your feedback in this thread @jonathanheron. I am convinced this will lead into the right direction.
kbrandwijk
on 4 Oct 2017
Thanks @kbrandwijk
jonathanheron
on 4 Oct 2017
@sorenbs have you thought any more about this?
jonathanheron
on 18 Oct 2017
This issue has been moved to graphcool/graphcool-framework.
 marktani
on 23 Jan 2018
marktani
on 23 Jan 2018
Related issues
 sedubois
·
3Comments
marktani
·
3Comments
sedubois
·
3Comments
marktani
·
3Comments
 hoodsy
·
3Comments
marktani
·
3Comments
hoodsy
·
3Comments
marktani
·
3Comments
 MitkoTschimev
·
3Comments
MitkoTschimev
·
3Comments
Most helpful comment
@sorenbs While I don't have a deep understanding of each of the strategies you propose, from what I can tell they will not easily solve the following scenario:
group IDand a salary criteria to filter on.Because the query whitelist allows me to pass in a group ID and salary criteria, I can do something like this:
Security-related behaviours should be easy to implement and reason about
Perhaps this could be solved by manipulating filters on the server to validate I'm only using this particular query on a group I'm a manager of, but that is _very_ complex to reason about, or to audit. It means that restrictions need to be expressed in two places (permissions and a proxy) in two different ways. Even with this trivial example, there's huge scope for mistakes slipping through unnoticed. What about a more complex app with a more complex data model?
The potential real world cost of insecure-by-default
I'm very aware that Graphcool are not optimising for my use case (I'm a product manager building workflow tools as side projects), and customers like me probably aren't a safe-bet for growing a successful business :-)
What occurs to me though is this: securing data is hard. Protecting users' privacy is hard. The general trend of the internet is for data breaches and privacy breaches to get worse. And for the abuse of data to become ever more compromising for individuals.
In the context of "Graphcool is where I store my data", I would propose that making it easy to protect access to sensitive data should be of paramount importance.
To spell out a nightmare scenario:
If Graphcool were to be very widely adopted by a lot of products, and many of those products failed to implement the multiple layers of protection necessary (in the current proposal) to stop queries that trick Graphcool into disclosing the existence of a user account, it becomes feasible to do large-scale automated attacks that identify the sites and services users are members of.
What if membership of those sites reveal political affiliation, activism, or sexual orientation that is illegal or problematic in a given country?
What if membership of those sites allows someone to build a profile of people so they can be targeted for manipulation?
In a world where the data held by online services can be weaponised so easily, it is essential that we (the people building these services) strive to protect that data.
Graphcool is in a position that it can choose to make protecting data _easy by default_. Permission queries are very close to right solution. They make it relatively easy to protect data from being directly read. But if they don't also protect data from being _inferred_ through filters, I think there's a strong risk they give developers a false sense of protection.
Access control has established conventions for comprehensiveness and trustworthiness
If I define ACLs in a database or file system, those ACLs apply all of the time in every scenario.
If I remove someone's Admin rights in my Saas app of choice, I know they'll lose access to all Admin functionality, all of the time.
When I restrict a user's access to a database or table in MySQL, I know with certainty they can never access or infer anything about the data they don't have access to.
Permission queries _sound_ like they have the same comprehensiveness, and when you first start using them they _look_ like they are comprehensive. But they aren't.
The road travelled by PHP and Rails
There are two software projects that come to mind when I think about the power vs. security-by-default decision…
PHP made dynamic web development accessible to millions, but made it incredibly easy to allow SQL injection. Countless sites over the years have suffered as a result of this.
Ruby on Rails included smart defaults (no SQL injection) and optimised for productivity. Almost a win win — but the decision to allow mass assignment of variables by default meant that Rails apps would, by default, be exposed to certain bugs and attack vectors. Over time, Rails learned from the painful experience of its adopters, and now _"rails complains abouts calling model#update_attributes without first setting up your attr_accessors"_
Are permission queries the right design?
It sounds like getting permission queries to work predictably (and automatically) with filters is difficult or infeasible. Is there a different design that could both put power in developer's hands and ensure it's easy to be secure by default?