Presto: Approx_percentile() implementation gives wrong results with accuracy specified as param
Currently in presto documentation, when we are trying to find percentiles with more accurate results we are supposed to use Approx_percentile() which as per the documentation has this syntax :

By default the accuracy is set to 0.01 but this can be changed in the syntax when called with smaller value giving more accurate results.
But somehow when I pass accuracy as a parameter to my query, the results are not correct. I ran the below code:
with temp AS (
SELECT 1 AS num
UNION
SELECT 5 AS num
UNION
SELECT 10 AS num
UNION
SELECT 100 AS num
UNION
SELECT 200 AS num
UNION
SELECT 500 AS num
UNION
SELECT 1000 AS num
UNION
SELECT 10000 AS num
UNION
SELECT 20000 AS num
)
SELECT
APPROX_PERCENTILE(num, 0.5),
APPROX_PERCENTILE(num, 0.5, 0.01),
APPROX_PERCENTILE(num, 0.5, 0.5),
APPROX_PERCENTILE(num, 0.5, 0.5, 0.001)
FROM temp
In the code above results for first two aggregations should be same since default accuracy is 0.01 as mentioned HERE
But the results I get are completely off :

_As we can see the first function gives the correct median value while the second doesn't._
My intuition is that somehow instead of calling approx_percentile() with accuracy, presto is calling approx_percentile() with weight specified.
i.e. even though it should call THIS

I feel its somehow calling THIS

Another Suspected issue for this could be the way sql actually calls the underlying java functions: I found that sql expected this kind of params in its function calls :
i.e. Nowhere it has a function defined for approx_percentile(bigint, BIGINT, double) which should have been for case of weight

 kunalkohli
kunalkohli
All 7 comments
CC: @jagill
 mbasmanova
on 2 Jul 2020
mbasmanova
on 2 Jul 2020
CC: @kaikalur @tdcmeehan
mbasmanova
on 2 Jul 2020
Ran a docker instance of presto and tested the above query there :
with temp AS ( SELECT 1 AS num UNION SELECT 5 AS num UNION SELECT 10 AS num UNION SELECT 100 AS num UNION S
ELECT 200 AS num UNION SELECT 500 AS num UNION SELECT 1000 AS num UNION SELECT 10000 AS num UNION SELECT 20000 AS n
um ) SELECT APPROX_PERCENTILE(num, 0.5), APPROX_PERCENTILE(num, 0.5, 0.01), APPROX_PERCENTILE(num, 0.5, 0.5) FROM temp;
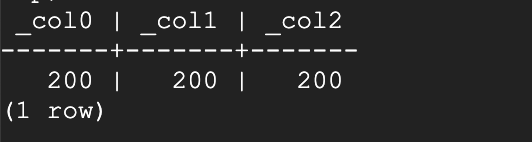
the results I get are correct in presto running in docker instance so I suspect there is some issue in presto instance running locally in my system.
I will check if there is some issue in my local presto instance.
kunalkohli
on 2 Jul 2020
The FB clusters have the expected behavior: the first three approx_percentile calls all return 200, and the last is a syntax error. OP's behavior is consistent with his conjecture that the second argument in the 2nd and 4th case is cast to a BIGINT. The call APPROX_PERCENTILE(num, cast(0.5 as BIGINT), 0.01) returns 1, as expected: 0.5 is cast to 1, and the 1th percentile of the list is 1.
I know there's a difference in how numerical literals are parsed (double vs decimal); is it possible that parsing code is somehow casting that argument to BIGINT?
 jagill
on 2 Jul 2020
jagill
on 2 Jul 2020
@jagill I am also confused by the different versions of documentation present online for presto.
https://prestosql.io/docs/current/functions/aggregate.html : Doesn't have the implementation of approx_percentile(x, percentage, accuracy)
https://prestodb.io/docs/current/functions/aggregate.html : has the implementation of approx_percentile(x, percentage, accuracy)
Is there a reason where we should use one documentation over the other?
kunalkohli
on 2 Jul 2020
@kunalkohli prestosql.io is a fork of this project, prestodb.io. If you are using PrestoDB you should use documentation from prestodb.io. If you are using PrestoSQL you should use the other documentation.
mbasmanova
on 2 Jul 2020
Thanks guys for clearing this confusion. Closing this issue for now.
Also the current prestodb implementation expects weight to be an INTEGER if we call approx_percentile(x, w, percentage) but in prestosql implementation we except weight to be a double as can be seen here
kunalkohli
on 2 Jul 2020
Related issues
 jeremy-degroot
·
3Comments
jeremy-degroot
·
3Comments
 tomz
·
3Comments
tomz
·
3Comments
 cps333
·
3Comments
cps333
·
3Comments
 synhershko
·
4Comments
synhershko
·
4Comments
 tesseract2048
·
3Comments
tesseract2048
·
3Comments