Presto: Add Array/Object support for elasticsearch connector via _meta field mapping
Quoting this thread from @martint on the slack Channel:
One of the limitations of the current [elasticsearch connector] implementation is that it doesn't support the ARRAY type. The underlying problem is that Elasticsearch itself does not have a way to describe such a concept. Fields in a document can be scalar values or arrays implicitly, depending on whether they have one or more values assigned.
Clearly, we could model everything as arrays, but that would make the connector unusable.
Fortunately, Elasticsearch supports per-index (i.e., table) application-specific metadata. My idea is to exploit that feature to allow users/admins to specify which columns or fields should be treated as arrays.
There are a couple of possible approaches for this:
- If the table has arrays, require the user to declare the schema of the table explicitly (vs letting the connector figure it out automatically). The downside of this approach is that it can be painful to have to describe the entire schema of a table just because one field somewhere is an array. To make this concrete, consider the following document:
{
"a" : {
"b": {
"x" : 1,
"y" : ["hello", "world"]
}
},
"c" : {
"d": "foo",
"e": "bar",
"f": [
{ "g" : [10, 20], "h": 100 },
{ "g" : [30, 40], "h": 200 }
]
}
}
There are only a handful of fields (a.b.y, c.f and c.f.g) that contain arrays. Requiring the user to declare the schema explicitly means they'd have to supply the following:
row(a row(b row(x bigint, y array(varchar))), c row(d varchar, e varchar, f array(row(g array(bigint), h bigint))))
Seems cumbersome, error prone and unnecessary.
- An alternative would be for users pinpoint the fields that should be interpreted as arrays by providing their full path. The connector will take care of inferring the rest of the schema from the metadata exposed by ES. For the example above, they'd just need to say:
a.b.y, c.f, c.f.g
I'm leaning towards option 2. Thoughts? Any other possibilities I'm missing?
 bitsondatadev
bitsondatadev
All 10 comments
@martint it sounds like you may have already started some work on this issue, is that true? Otherwise I'd be glad to start working on it.
bitsondatadev
on 8 Jan 2020
I haven't started working on it, so feel free to tackle it.
 martint
on 8 Jan 2020
martint
on 8 Jan 2020
@dain you made a few comments about encoding of the field.
One alternative would be to model this as field metadata, so you would have a.b.c::isArray=true, and then have a bag of these
dain 3 months ago
or have properties like field.a.b.c={ "isarray"=true, "comment"="stuff")dain 3 months ago
IMO option 2 is the way to go… then we talk about encodingsdain 3 months ago
I think I like my first encoding better, because it makes alter table coment property much easierdain 3 months ago
we have some naming convention like p.field.[a.b.c].propertyName=value
I'm not exactly following or know the standard encodings that is used in the project but I'll propose my idea and if it's not the standard then could you point me to an example in the code that does something close? Is this on the right track?
Say we have a document like this:
{
"a" : {
"b": {
"x" : 1,
"y" : ["hello", "world"]
}
},
"c" : {
"d": "foo",
"e": "bar",
"f": [
{ "g" : [10, 20], "h": 100 },
{ "g" : [30, 40], "h": 200 }
]
}
}
We might have some the following properties with a nested "presto_meta" object that I can traverse while parsing the mapping and building the IndexMetadata bean.
{
"test_index": {
"mappings": {
"test_type": {
"_meta": {
"presto_meta": {
"a": {
"b": {
"y": {
"isArray": true
}
}
},
"c":{
"f":{
"g":{
"isArray": true
},
"isArray": true
}
}
}
},
"properties":{
"a": {
"type": "object",
"properties": {
"b": {
"type": "object",
"properties": {
"y": {
"type": "integer",
},
"y": {
"type": "keyword",
}
}
}
}
},
"c": {
"type": "object",
"properties": {
"d": {
"type": "keyword",
},
"e": {
"type": "keyword",
},
"f": {
"type": "object",
"properties": {
"g": {
"type": "integer",
},
"h": {
"type": "integer",
}
}
}
}
}
}
}
}
}
}
Something else we may need to consider is how this would work with an alias that pointed to multiple indices.
bitsondatadev
on 10 Jan 2020
Hi @brianolsen87 , I just share you my thinking, because I'm facing the issue the pull request #2478 solve and was thinking to implement before I find it and because the introduction ask for eventual method to infer if a field is an array or not.
It is clear that presto will not be able to support what is describe in elastic documentation here https://www.elastic.co/guide/en/elasticsearch/reference/current/array.html since a field cannot be an array of primitive type or a primitive type.
So we have to consider that the property "isArray" of a specific field is static across the index to be compatible with presto. In this case, the combination of a sample doc extracted from a search query and the mapping will contain the same information as the combination of mapping and presto_meta in many(most?) cases without any user configuration.
Maybe using a document as a fallback (optional) method when presto_meta is not populated to infer if a field is an array will satisfy most of users and will ease the connector usage or maybe the presto_meta field can be generated by a procedure using an index name and an(optional) doc _id.
Many thanks !
 luhhujbb
on 14 Jan 2020
luhhujbb
on 14 Jan 2020
maybe the presto_meta field can be generated by a procedure using an index name and an(optional) doc _id.
That's a great idea. We could add a procedure that given an index name, fetches a sample of documents, tries to infer which fields are arrays and generates the corresponding _meta entries for them. Let's do that as a separate task, though. I filed https://github.com/prestosql/presto/issues/2508.
martint
on 14 Jan 2020
Fix merged
martint
on 15 Jan 2020
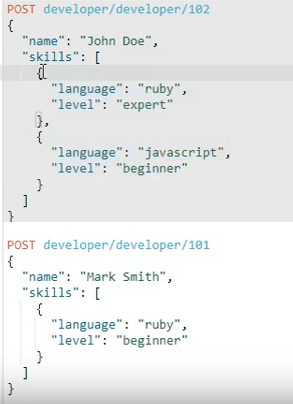

Hi, this is how i created the index and mapping. And inserted two records. I want to fetch these records from presto command line. How can i do that? And also , do i need to create one xxx.json file to provide any metadata information ?
 MT2017081
on 25 Feb 2020
MT2017081
on 25 Feb 2020
Hi @MT2017081
No need for an extra file, the mappings PUT statement is where you will need to add a small bit of metadata about where the arrays in your schema are actually located. We search in the mapping's _meta.presto. location to infer which fields should be treated like arrays see the Array Types section here. The example my not be super clear but you need to align the property nesting under _meta.presto with the same nesting structure of you array fields under properties. So when you add your mapping you would need to do this.
PUT developer
{
"_meta": {
"presto":{
"skills":{
"isArray":true
}
}
}
}
This can be added in a separate curl call or with your original put mapping statement.
PUT developer
{
"_meta":{
"presto":{
"skills":{
"isArray":true
}
}
},
"mappings":{
"developer":{
"properties":{
"name":{
"type":"text"
},
"skills":{
"type":"object",
"properties":{
"language":{
"type":"keyword"
},
"level":{
"type":"keyword"
}
}
}
}
}
}
}
If you have more questions i'm on the slack group. Feel free to tag me for elasticsearch presto related questions and i'll do my best to answer them.
bitsondatadev
on 25 Feb 2020
Hi @MT2017081
No need for an extra file, the mappings PUT statement is where you will need to add a small bit of metadata about where the arrays in your schema are actually located. We search in the mapping's_meta.presto.location to infer which fields should be treated like arrays see the Array Types section here. The example my not be super clear but you need to align the property nesting under_meta.prestowith the same nesting structure of you array fields underproperties. So when you add your mapping you would need to do this.PUT developer { "_meta": { "presto":{ "skills":{ "isArray":true } } } }This can be added in a separate curl call or with your original put mapping statement.
PUT developer { "_meta":{ "presto":{ "skills":{ "isArray":true } } }, "mappings":{ "developer":{ "properties":{ "name":{ "type":"text" }, "skills":{ "type":"object", "properties":{ "language":{ "type":"keyword" }, "level":{ "type":"keyword" } } } } } } }If you have more questions i'm on the slack group. Feel free to tag me for elasticsearch presto related questions and i'll do my best to answer them.
Thanks @brianolsen87 for the help.
MT2017081
on 25 Feb 2020
Related issues
 byungnam
·
4Comments
byungnam
·
4Comments
 BruceKellan
·
4Comments
BruceKellan
·
4Comments
 findepi
·
3Comments
findepi
·
3Comments
 tooptoop4
·
4Comments
tooptoop4
·
4Comments
 lxynov
·
4Comments
lxynov
·
4Comments