Presto: Performance issue on Unnest operator
Problem query:
SELECT
*
FROM
my_table ---- A table with 100+ columns
CROSS JOIN UNNEST(field) AS l
WHERE
l.field1 = 'abc' ---- A very selective filter on the unnest field
limit 10;
Explain analyze:
-Output[<......>]
-LimitPartial[<......>]
- Filter[filterPredicate = ...] => [<......>]
CPU: 2.01m (6.79%), Scheduled: 2.07m (5.71%), Input: 800152 rows (63.35GB), Output: 75222 rows (4.42GB), Filtered: 90.60%
Input avg.: 247.73 rows, Input std.dev.: 63.96%
- Unnest [replicate=<......>,unnest=field] => [<......>]
CPU: 23.32m (78.52%), Scheduled: 23.75m (65.65%), Output: 800152 rows (63.35GB)
Input avg.: 3.33 rows, Input std.dev.: 96.75%
- TableScan[hive:my_table, grouped = false] => [<......>]
CPU: 4.20m (14.14%), Scheduled: 10.18m (28.14%), Output: 10740 rows (664.73MB)
Input avg.: 3.33 rows, Input std.dev.: 96.75%
100+ columns are replaced by <......>
CPU Profiling on worker:
Profiler: https://github.com/jvm-profiling-tools/async-profiler
sudo ./profiler.sh -d 30 -f /tmp/flamegraph.svg -e wall -t <pid>
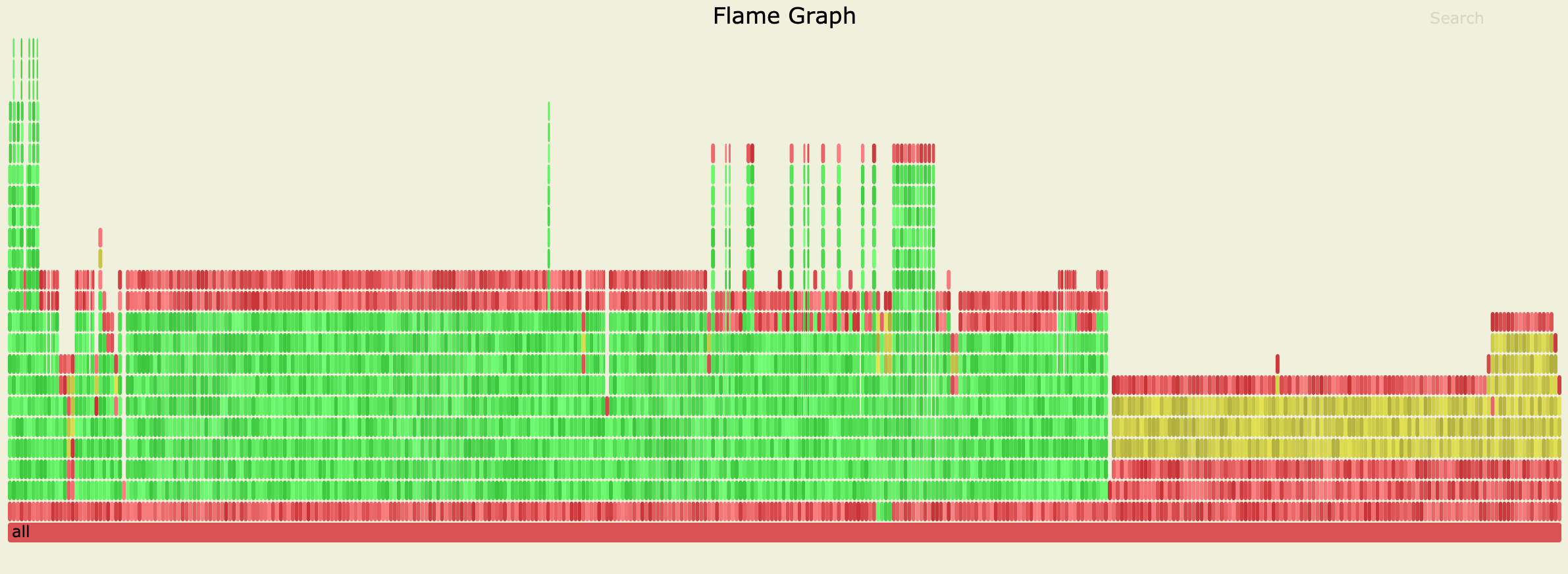
Most of the threads are in "Unsafe_Park :: pthread_cond_wait@GLIBC"
Raw svg file: file
sudo ./profiler.sh -d 30 -f /tmp/flamegraph.svg <pid>
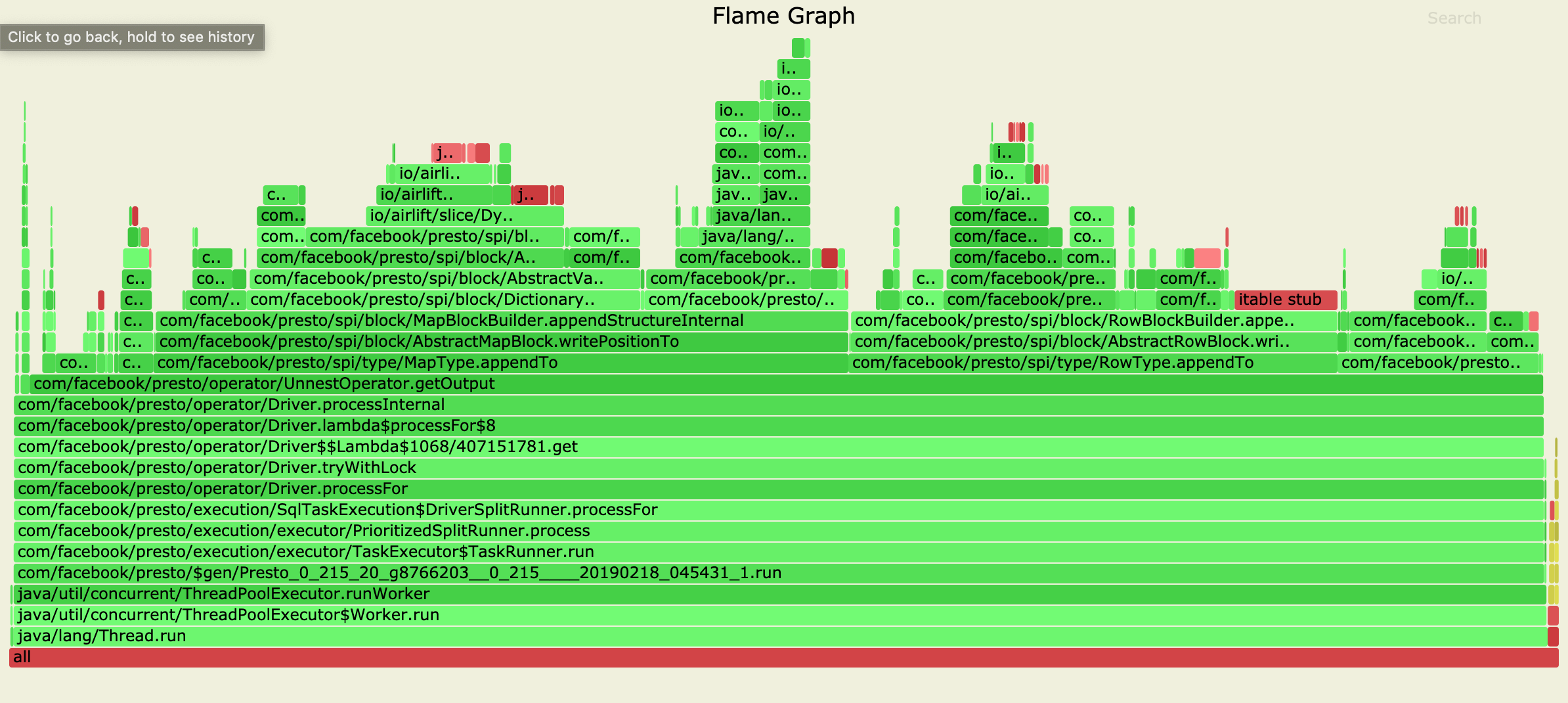
Raw svg file: file
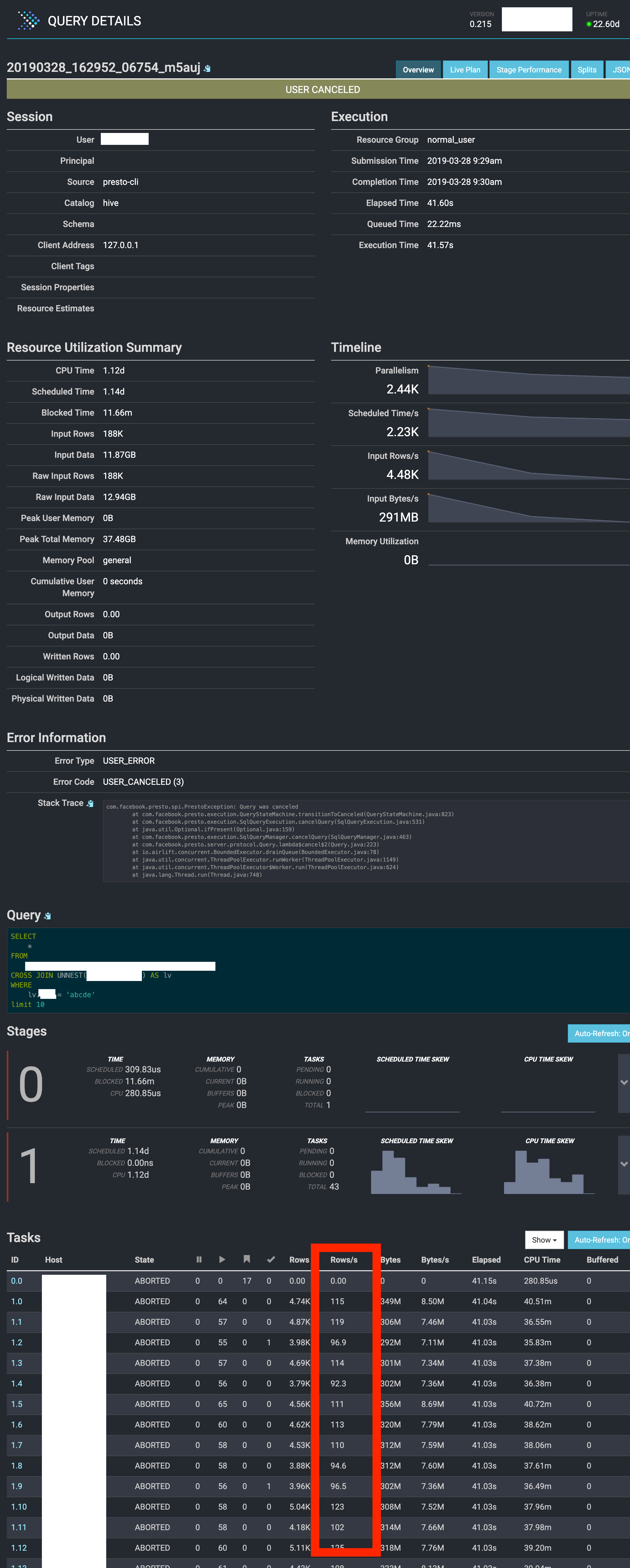
Issue observed:
- Unnest operator is painfully slow when number of replicate column is high (especially combine with
SELECT *) - The parallelism is very low. The spec of our server is 32 CPU and 250GB ram but the processing speed per server is only around 100rows/s
- Unnest operator is not a vectorized operation
Possible solutions:
- Modify unnest operator and let it handle do the filtering related to the unnest fields, so that we can avoid building the unnecessary rows
- Modify filter operator and make it able to handle nested fields, then push the filter operator below the unnest operator
- Make unnest operator faster (somehow change it to a vectorized operation?)
Any suggestions will be much appreciated.
 oneonestar
oneonestar
All 10 comments
I'm pretty sure that UnnestOperator can be rewritten to use dictionary blocks to mask/replicate the data, which would completely avoid the copies. (This operator was written 2014 before we did that)
 dain
on 28 Mar 2019
dain
on 28 Mar 2019
@dain So if I understand this correctly, having dictionary blocks will help reduce shuffled data significantly for complex replicate channels, especially for cases like the one @oneonestar mentioned with >100 columns. but when the array/map fields have high cardinality, won't RLE blocks be a better choice?
 phd3
on 23 Apr 2019
phd3
on 23 Apr 2019
@phd3 Yes. If an RLE block can be used, it is a better choice than a dictionary block. The biggest part of the win comes switching away from a direct block to either a dictionary or RLE block.
BTW there will also a significant improvement in CPU time spent in the unnest operator itself since it will no longer need to copy data.
dain
on 23 Apr 2019
@dain Thanks for the clarification. That makes sense. I would like to work on this and create a PR. Planning to include memory tracking to this operator as well.
phd3
on 23 Apr 2019
@oneonestar, were you already working on this? If not, @phd3, please go for it!
 martint
on 23 Apr 2019
martint
on 23 Apr 2019
Sorry for the late reply. I got some brief POC works on hand only. @phd3 If you already started your work, you can take over it. Or else I’ll continue the work (slowly although).
In unnest operator, there are unnest columns and replicate columns.
For the replicate columns, it is obvious that a dictionary block can save a lot of CPU copying time and memory usage.
For the unnest columns, in some cases we need to insert null.
> unnest([1,2], [3,4,5])
1 | 3
2 | 4
Null | 5
I’m not sure what is the best approach to insert null into block.
For complicated and deeply nested blocks (row block), unnest the block will becomes a deep copy on every single row (this explain why the flamegraph looks like this).
In this case some wrapping (RLE / DictionaryBlock) is much better IMO. However, currently dictionary block seems doesn’t support insert null.
For simple blocks like IntArrayBlock, unnest it could be better since we don’t need the extra wrapping block and the memory usage will be lower. Also the following operators don’t have to work on the indirect pointers, which can produce a tight loop.
oneonestar
on 26 Apr 2019
@oneonestar you can use the Columnar* classes to convert structured blocks into their elements. For example, ColumnarArray gives you the raw elements array for the arrays column (all arrays concatenated together), the lengths and offsets. I think this will make it possible to do deep unnesting.
The null problem is interesting. I suppose we could use a negative ID to represent null. We would have to update all users of DictionaryBlock.getId(position), but there don't appear to be that many.
dain
on 26 Apr 2019
@oneonestar Thanks for your response and sharing your observations. We've seen issues getting more frequent with unnest queries on deeply nested columns. This improvement can be a huge help to us, happy to take this up.
phd3
on 26 Apr 2019
@phd3 Any good news?
oneonestar
on 23 May 2019
@oneonestar Thanks for checking.
Initially I had thought of an implementation design based on the conversation here, and was hitting a few roadblocks. Then I exchanged ideas about the implementation details with @dain, and was able to move forward with his suggestions. I've implemented it for the most part and working on testing the changes. Hoping to getting it ready for review soon.
phd3
on 23 May 2019
Related issues
 findepi
·
4Comments
findepi
·
4Comments
 bill-warshaw
·
4Comments
bill-warshaw
·
4Comments
 fredabood
·
3Comments
fredabood
·
3Comments
 byungnam
·
4Comments
byungnam
·
4Comments
 kokes
·
3Comments
kokes
·
3Comments
Most helpful comment
@oneonestar Thanks for checking.
Initially I had thought of an implementation design based on the conversation here, and was hitting a few roadblocks. Then I exchanged ideas about the implementation details with @dain, and was able to move forward with his suggestions. I've implemented it for the most part and working on testing the changes. Hoping to getting it ready for review soon.