I am a big fan of the spaCy library and we should definitely support some of the basic functionalities of the framework https://spacy.io/usage/spacy-101#features
In essence I would like to create spaCy pipelines using Prefect tasks since we can chain together the outputs of each task. As a good first step we could easily support tokenization which encompasses a lot of functionality:
nlp = spacy.load('specified model')
tokens = nlp(u'task input')
However it would also be nice to break out some of the functionality into individual tasks because Prefect has mechanisms in place to support smaller units of execution. Tasks for this first pass:
- [ ] tokenizer
- [ ] tagger
- [ ] parser
- [ ] ner
- [ ] textcat
The optimal solution for this issue is if we can support this workflow (https://spacy.io/usage/spacy-101#pipelines):
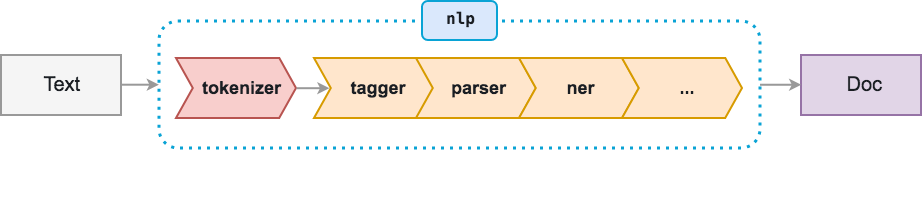
^ This flow in Prefect could look something similar to:
with Flow('processing pipeline') as flow:
text = Parameter('text')
tagger = TaggerTask(input)
parser = ParserTask(tagger)
ner = NERTask(parser)
doc = DoSomethingWithResultTask(ner)
flow.run(parameters=dict(text="here is my input"))
 joshmeek
joshmeek
All 13 comments
I'll put together a PR for these tasks this week
 zangell44
on 14 May 2019
zangell44
on 14 May 2019
As a side note, I had a short convo with @galtay offline about these tasks and he proposed a different approach where the tasks would take in a spaCy pipeline and return the desired items. We need to make sure whatever input/output approach we take here it is both easy to understand and pickleable (via cloudpickle).
This other approach would look something like:
with Flow('processing pipeline') as flow:
doc = Parameter('doc')
tagger = TaggerTask(doc)
parser = ParserTask(doc)
ner = NERTask(doc)
transform = DoSomethingWithOutputsTask(tagger, parser, ner)
my_spacy_doc = nlp('text stuff') # could also be a task itself
flow.run(parameters=dict(doc=my_spacy_doc))
I like this approach because it avoids having to reparse the text every task and instead uses the nlp() output to pull out each step's respective values.
This is definitely up for debate on which method we think is most generalizable and straightforward to use.
joshmeek
on 14 May 2019
trying to make sure i understand the above correctly -
when "returning the desired items" for the subtasks (e.g. TaggerTask), are we returning subcomponents of the spacy pipeline? or are we applying pipeline components at each step?
zangell44
on 16 May 2019
I think we should go the route of returning the subcomponents. I like the idea of having a task which runs nlp(doc) and then returns the spacy doc. Then the other tasks would take in that doc and return the components requested (NER, Tagger, etc...)
joshmeek
on 16 May 2019
That seems fine to me, but I think the components to request are part of the nlp object, not the doc object. The doc object possesses properties that the Tagger and other components create.
For example, if I wanted to access the tagger in my pipeline
nlp = spacy.load('some model')
doc = nlp('some text')
tagger = nlp.tagger
more_stuff = DoSomethingWithTagger(tagger)
Am I understanding correctly?
zangell44
on 16 May 2019
Yeah you are correct, I worded my response poorly!
joshmeek
on 16 May 2019
Before going too deep, I'd highly recommend ensuring these objects are pickleable and can be safely returned by tasks:
import cloudpickle
check = cloudpickle.loads(cloudpickle.dumps(nlp.tagger))
 cicdw
on 16 May 2019
cicdw
on 16 May 2019
Tried this ^ I was able to pickle the doc however on attempt of pickling a token spaCy outputs:
NotImplementedError: [E111] Pickling a token is not supported, because tokens are only views of the parent Doc and can't exist on their own. A pickled token would always have to include its Doc and Vocab, which has practically no advantage over pickling the parent Doc directly. So instead of pickling the token, pickle the Doc it belongs to.
Not sure if this is an issue since it seems like they have taken pickling into account when building spaCy.
joshmeek
on 16 May 2019
No problems when picking the pipeline or portions of the pipeline object. I'll keep going unless the individual token finidng is a showstopper
zangell44
on 16 May 2019
Everything is more or less good to go on this. I'll tie up any loose ends and open a PR tomorrow morning.
On another note, one of the tests, TestHeartBeats.test_task_runner_has_a_heartbeat_with_timeouts[local], seems to be failing non-deterministically on my machine. Has anyone else seen this happening periodically or is it user error on my part?
zangell44
on 16 May 2019
Definitely not user error, although it is surprising to me that the local executor is the one producing the errors and not either of sync or mthread. The main assert (which I have personally seen fail randomly, but not often) is: assert len(results.split()) >= 30. Do you happen to remember what number the length was when the test failed?
cicdw
on 16 May 2019
Yep that's the test that was failing randomly, the length was 26 when it failed.
I went back and looked at some of the prior failures, sync, mthread, mproc had all failed at some point too, with varying incorrect lengths
This is the error log from one of my runs (local) -
E AssertionError: assert 26 >= 30
E + where 26 = len(['called', 'called', 'called', 'called', 'called', 'called', ...])
E + where ['called', 'called', 'called', 'called', 'called', 'called', ...] = <built-in method split of str object at 0x11fafa3d0>()
E + where <built-in method split of str object at 0x11fafa3d0> = 'called\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\ncalled\n'.split
Gotcha gotcha; the number 30 there is somewhat arbitrary - for the sake of the test I have the task runner heartbeat (by writing to a file) every 0.025 seconds which is totally unrealistic (in production we usually set it to every 30 seconds, and in that case it makes a GraphQL API call) and I imagine some of the file writes are just missed for random threading reasons.
So if you want to bump it down to 25 in your PR tomorrow, that is totally fine by me.
cicdw
on 16 May 2019
Related issues
 GZangl
·
3Comments
GZangl
·
3Comments
 rej-jsa
·
4Comments
rej-jsa
·
4Comments
 jameslamb
·
3Comments
jameslamb
·
3Comments
 mark-w-325
·
3Comments
mark-w-325
·
3Comments
 gryBox
·
3Comments
gryBox
·
3Comments
Most helpful comment
No problems when picking the pipeline or portions of the pipeline object. I'll keep going unless the individual token finidng is a showstopper