Powershell: Attributes don't show up in array of hashtables
I tried the script Dr. Scripto wrote about in 2013:
https://devblogs.microsoft.com/scripting/write-users-and-proxy-addresses-to-csv-by-using-powershell/
but it didn't work. Perhaps it's no surprise since it was written many years ago.
It seems that PowerShell doesn't like this:
$users = @()
$user1 = [ordered]@{first = 1; last = 2}
$user2 = [ordered]@{first = 3; last = 5; middle = 5}
$users += [pscustomobject]$user1
$users += [pscustomobject]$user2
# The `middle` attribute doesn't show up in any of these:
$users
$users | Out-GridView
$users | ConvertTo-Csv -NoTypeInformation
$users | Export-Csv users.csv -NoTypeInformation
But if you add $user2 first, it works fine.
I have a script that calls an API hundreds of times, and will get different user attributes each time.
I can find a workaround, but doesn't this seem like a bug?
Thanks!
 gabrielsroka
gabrielsroka
All 28 comments
It is side effect from Format-Table optimization when it is trying to collect some object before output.
For the case this looks like a bug.
 iSazonov
on 19 May 2020
iSazonov
on 19 May 2020
No, this is by design for this cmdlet. Isn't it in the documentation that the properties on the first object are used to determine the table headers?
Think about it. CSV requires that all lines have the same number of columns and that the column headings be listed at the top of the file.
Short of caching all the objects in memory and iterating the entire collection at least twice before writing the file, there's no way to ensure you haven't missed any properties and don't have a mismatched number of columns on some lines.
It would be extremely bad on performance for large CSV files to try to handle this in any other way imo.
If you have a set of objects that you know the full set of properties for, you can workaround this by using select-object to ensure that all the objects have the same set of properties before exporting them.
$objects |
Select-Object -Property $PropertyNames |
Export-Csv -Path $filepath
 vexx32
on 19 May 2020
vexx32
on 19 May 2020
@vexx32 :
Isn't it in the documentation that the properties on the first object are used to determine the table headers?
Do you know where that is?
I tried this right after, and it does what I want.
$users | ft -Property first,last,middle
but that's not intuitive. Plus, Export-Csv doesn't support it, so you need the Select workaround above (which is a good workaround, but can we "fix the bug" instead?)
Python, by comparison, requires you to name the columns you're exporting (like ft above)"
# Python:
fieldnames = ['first', 'last', 'middle']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
I found it, from https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/format-table?view=powershell-7
If you omit [the
-Property] parameter, the properties that appear in the display depend on the first object's properties. For example, if the first object has PropertyA and PropertyB but subsequent objects have PropertyA, PropertyB, and PropertyC, then only the PropertyA and PropertyB headers will display
The Format-Table cmdlet formats the output of a command as a table with the selected properties of the object in each column. The object type determines the default layout and properties that are displayed in each column. You can use the Property parameter to select the properties that you want to display. PowerShell uses default formatters to define how object types are displayed. You can use .ps1xml files to create custom views that display an output table with specified properties. After a custom view is created, use the View parameter to display the table with your custom view. For more information about views, see about_Format.ps1xml. You can use a hash table to add calculated properties to an object before displaying it and to specify the column headings in the table. To add a calculated property, use the Property or GroupBy parameter. For more information about hash tables, see about_Hash_Tables.
gabrielsroka
on 19 May 2020
That's Format-Table, sure.
It's also in Export-Csv's documentation here:
https://docs.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/export-csv?view=powershell-7#notes
When you submit multiple objects to Export-CSV, Export-CSV organizes the file based on the properties of the first object that you submit. If the remaining objects do not have one of the specified properties, the property value of that object is null, as represented by two consecutive commas. If the remaining objects have additional properties, those property values are not included in the file.
The Export-CSV cmdlet creates a CSV file of the objects that you submit. Each object is a row that includes a comma-separated list of the object's property values. You can use the Export-CSV cmdlet to create spreadsheets and share data with programs that accept CSV files as input. Do not format objects before sending them to the Export-CSV cmdlet. If Export-CSV receives formatted objects the CSV file contains the format properties rather than the object properties. To export only selected properties of an object, use the Select-Object cmdlet.
vexx32
on 19 May 2020
Ok, fair enough. My PowerShell 5 offline help doesn't mention that.
So, does it make sense for these commands to "default" to using the properties from the first object? Or should it require you to specify which properties you want, so you're not surprised?
gabrielsroka
on 19 May 2020
I think allowing users to specify the properties in the cmdlet itself does make some sense, and probably makes a little more sense than trying to search the entire (arbitrarily-large) list for potentially different objects.
vexx32
on 19 May 2020
By the way, any thoughts on the first thread re Dr Scripto? Is this a regression?
gabrielsroka
on 19 May 2020
And, then again! Is this a Windows PowerShell issue? Or, PowerShell 7 issue?
The PowerShell version information was skipped!
This is an example of scripts that were created during the Windows PowerShell era. There will be differences and nothing can't be done to fix Windows PowerShell 5.1.
Long Live Windows PowerShell! Haha! :)
All efforts are towards improving and growing PowerShell 7 (or >).
 MaximoTrinidad
on 19 May 2020
MaximoTrinidad
on 19 May 2020
Not sure what you mean RE the Dr Scripto examples. They seem sound to me, but I don't see how you got to your issue from the examples in that post.
vexx32
on 19 May 2020
@MaximoTrinidad This is on both PowerShell 5 and 7.
@vexx32 this is Dr Scripto's code. I got some of my ideas from his article. The code is similar to mine, but neither his nor mine works. Did it used to? What version of PowerShell was around in 2013?
$users = Get-ADUser -Filter * -SearchBase ‘dc=contoso,dc=local’ -Properties proxyaddresses
foreach ($u in $users) {
$proxyAddress = [ordered]@{}
$proxyAddress.User = $u.name
for ($i = 0; $i -le $u.proxyaddresses.count; $i++) {
$proxyAddress[“ProxyAddress_$i”] = $u.proxyaddresses[$i]
}
[pscustomobject]$proxyAddress |
Export-Csv -Path proxyaddresses.csv -NoTypeInformation –Append -Force
Remove-Variable -Name proxyAddress
}
The screenshot in the article makes it look like the code as written would work.
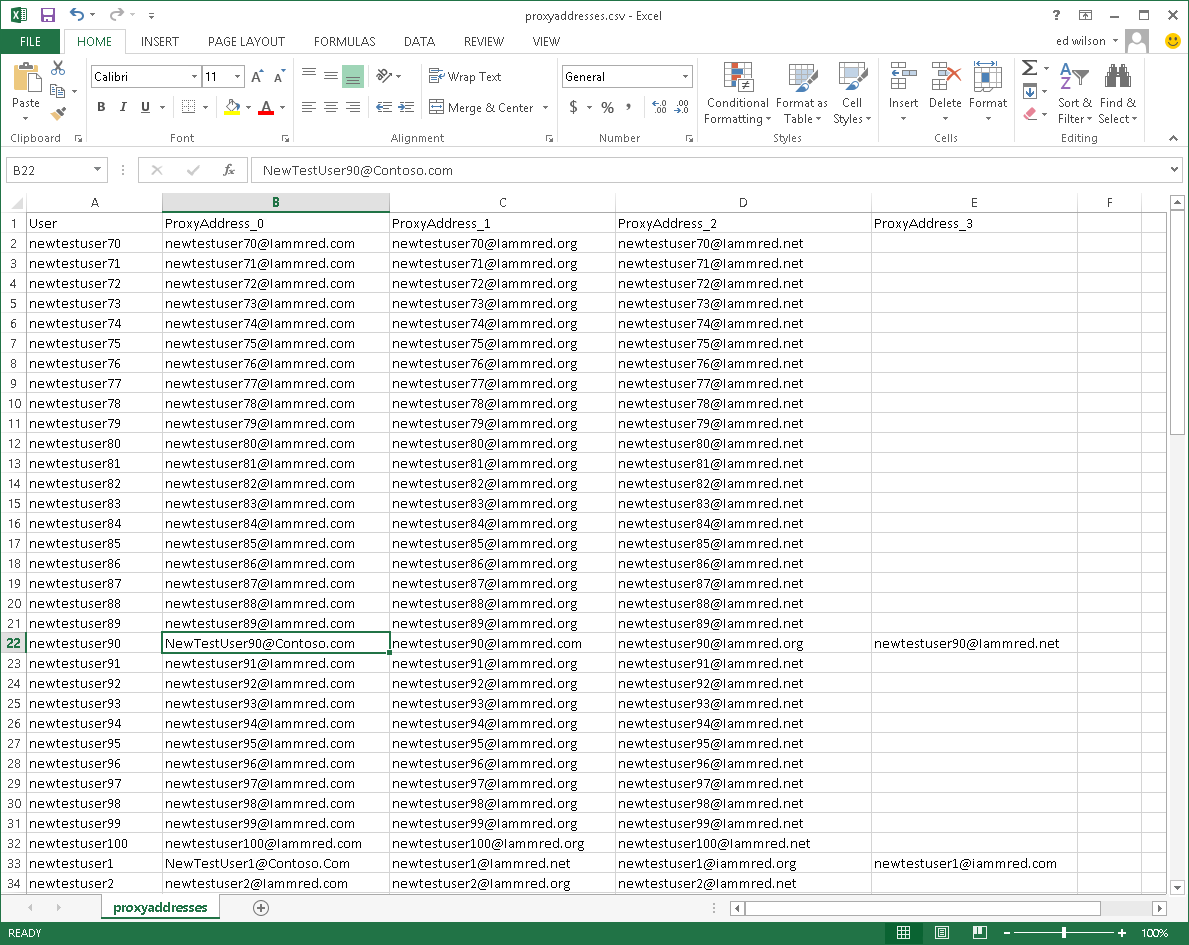
Is this a regression?
gabrielsroka
on 19 May 2020
@vexx32
From the old Microsoft Scripting Center originally maintained by Mr. Ed Wilson (The Scripting Guy) during the flourishing era of Windows PowerShell.
The sample from the post works as expected.. if you run in Windows PowerShell. He provided lots of PowerShell samples to get you started.
:)
MaximoTrinidad
on 19 May 2020
Oh, I see where that comes from, thanks for pointing it out.
I'm not sure if it was different prior to 5.1, but at least in Windows PowerShell 5.1 the code doesn't work as advertised if the first object doesn't have all the properties, no.
Could be that it was simply wrong all these years, but in truth I do not know. 😕
vexx32
on 19 May 2020
@MaximoTrinidad I tried it on (Windows) PowerShell 5. It doesn't work (for me). Does it work for you?
gabrielsroka
on 19 May 2020
@gabrielsroka
Hum! I think is nothing wrong>
First, you're trying to add dissimilar objects.
I tend to normalize the data before I build the object. It need to have the same number for properties so it would work.
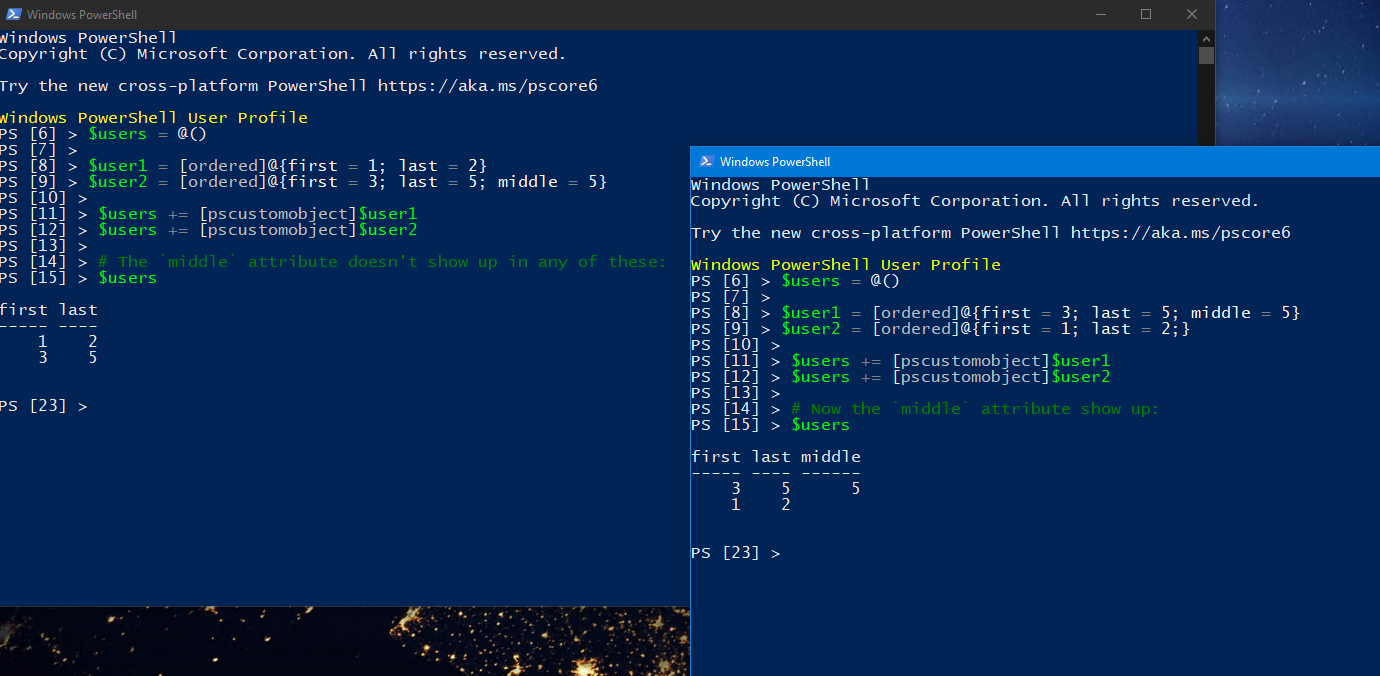
$users = @()
$user1 = [ordered]@{first = 1; last = 2; middle = $null}
$user2 = [ordered]@{first = 3; last = 5; middle = 5}
$users += [pscustomobject]$user1
$users += [pscustomobject]$user2
# Now the `middle` attribute show up:
$users
first last middle
----- ---- ------
1 2
3 5 5
Or, change the order of the line. The first one contains all the properties for the object.
$users = @()
$user1 = [ordered]@{first = 3; last = 5; middle = 5}
$user2 = [ordered]@{first = 1; last = 2;}
$users += [pscustomobject]$user1
$users += [pscustomobject]$user2
# Now the `middle` attribute show up:
$users
first last middle
----- ---- ------
3 5 5
1 2
:)
MaximoTrinidad
on 19 May 2020
Only work if I create the first object with all the properties. And it works on both Windows PowerShell and PowerShell 7.
MaximoTrinidad
on 19 May 2020
@MaximoTrinidad i know that works. I wrote that in my first thread. But it's a hack, imho.
As I wrote above, I have a script that calls an API hundreds of times, and will get different user attributes each time. I don't know all the user attributes until I'm done, so I'd have to take a second pass (which is the same thing @vexx32 is worried about).
gabrielsroka
on 19 May 2020
@gabrielsroka
I don't consider it a hack. I think... its like a database table, you define the table with all the columns and then you can have variable data records to fill the table.
But, that's my opinion!
:)
MaximoTrinidad
on 19 May 2020
@gabrielsroka one option would be to store the data as JSON rather than CSV, since it doesn't share this limitation... but I don't know if that is suitable for your use case.
vexx32
on 19 May 2020
@vexx32 the API returns the data in JSON format. The whole purpose of the script is to convert it to CSV so people can view it, for example, in Excel.
Are you saying keep the JSON for a while and then convert it to CSV? Maybe a little pseudocode would help...
@MaximoTrinidad sure, what I stated is my opinion, too. I think what I've found frustrating over the last 5 years of using PowerShell is you think it's gonna do what you want, but then it doesn't. And then you're surprised, and little sad :). I just read about how PowerShell's ConvertTo-Json defaults the -depth to 2, whereas JavaScript doesn't. I've been bitten by this "bug", too.
See also: https://en.wikipedia.org/wiki/Principle_of_least_astonishment
So, my question is, does PowerShell have a design principle that things just "work"? That the defaults are "good"? Or, do you have to read the manual (not the one on your machine, the one online)?
gabrielsroka
on 19 May 2020
Bit of both. I do hear you on the depth limit though. I think we have a few open issues discussing that. Personally I think a higher default makes sense. The reason the default is there is because there are some common objects in PS that have recursive references, which would quickly confuse the heck out of the JSON serializer and you'd end up with a lot of duplicate data.
I definitely agree we should strive for the principle of least astonishment as much as possible. The difficulty here is that there's not really a good solution to solve this other than perhaps going back and overwriting the header in the file a bunch of times if the cmdlet finds extra properties during processing that aren't present on the first object... That also comes with performance overhead, as inspecting every object's properties and comparing them to the base set is not necessarily cheap. You go from one set of property lookups per pipeline to as many property lookups as there are objects, and that gets quite expensive very quickly and will slow down processing quite a bit.
To be clear, I'm all for solving it, I think it should be solvable. I just don't see a good way to do so in this cmdlet. 😕
vexx32
on 19 May 2020
Understood.
a few open issues
yes, there's where I was reading it.
recursive references
doesn't JavaScript have the same problem?
Well, and I say this half-jokingly, but we could leave Export-Csv to mean "export some columns or the columns you tell me, and also add type information unless you tell me not to" and then add a new cmdlet called Export-CsvPolaEdition that just "does what you want -- export all the columns, with no type information". Because if the cmdlet doesn't do it, I have to code it (and so does everyone else).
(Pola = Principle of Least Astonishment)
gabrielsroka
on 19 May 2020
The type information thing was already dropped in PS 6. 🙂
If it's going to be fixed, it probably makes more sense to just be on Export-Csv itself, even if it does need to be an optional switch for some reason.
vexx32
on 19 May 2020
In JavaScript:
a = {};
b = {p: a};
a.p = b;
JSON.stringify(a); // --> TypeError: Converting circular structure to JSON
The type information thing was already dropped in PS 6
I still support PS 5 users. (but I'm glad it's been dropped)
gabrielsroka
on 19 May 2020
So, my question is, does PowerShell have a design principle that things just "work"? That the defaults are "good"? Or, do you have to read the manual (not the one on your machine, the one online)?
Initial design for JSON cmdlets was for using in interactive sessions. As result there is default depth 2 and converting all over the depth to strings.
Modern user expectations is changed to Web scenarios and we concluded to change the default.
Also .Net Core now has new JSON API and we plan to migrate from NewtonSoft to the new API.
recursive references
This will be resolved to with new API, and more. The PR already exist but is still not merged.
iSazonov
on 20 May 2020
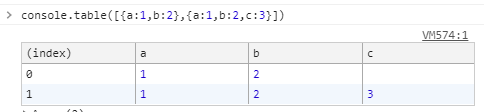
By the way, this JavaScript works fine in Node and Edge, Chrome, Firefox consoles:
console.table([{a: 1, b: 2}, {a: 1, b: 2, c: 3}]);
@iSazonov thanks for your reply. I was asking in general about PowerShell -- not just in regard to JSON on arrays or hashtables. Maybe it's my fault. I've been using JavaScript for 20 years, so that's "normal". When I use another language, I expect it to "work like JS", but maybe it doesn't. It's tricky when two languages seem to do the same thing, but there's subtle (or not to subtle) differences. E.g. https://gabrielsroka.github.io/JavaScript-vs-PowerShell.htm (not complete, of course)
gabrielsroka
on 20 May 2020
This issue has been marked as answered and has not had any activity for 1 day. It has been closed for housekeeping purposes.
![msftbot[bot] picture](https://avatars2.githubusercontent.com/in/26612?v=4&s=40) msftbot[bot]
on 22 May 2020
msftbot[bot]
on 22 May 2020
Related issues
 pcgeek86
·
3Comments
pcgeek86
·
3Comments
 mklement0
·
3Comments
mklement0
·
3Comments
MaximoTrinidad
·
3Comments
mklement0
·
3Comments
mklement0
·
3Comments
MaximoTrinidad
·
3Comments
 rudolfvesely
·
3Comments
rudolfvesely
·
3Comments
Most helpful comment
No, this is by design for this cmdlet. Isn't it in the documentation that the properties on the first object are used to determine the table headers?
Think about it. CSV requires that all lines have the same number of columns and that the column headings be listed at the top of the file.
Short of caching all the objects in memory and iterating the entire collection at least twice before writing the file, there's no way to ensure you haven't missed any properties and don't have a mismatched number of columns on some lines.
It would be extremely bad on performance for large CSV files to try to handle this in any other way imo.
If you have a set of objects that you know the full set of properties for, you can workaround this by using select-object to ensure that all the objects have the same set of properties before exporting them.