This is a request for someone with access to editing special pages to add this visualization of tags from the beginning of time to November 2016 to the top of publiclab.org/tags
https://www.dropbox.com/s/s78g3ufhsav5xzo/plots_tag_graph_256_filtered.png?dl=0

CC:
@gretchengehrke
@skilfullycurled
 ebarry
ebarry
All 73 comments
Hi, Liz - i'm a bit reluctant to put a static graphic like this in our permanent codebase, but maybe a suggestion could be that we display a "feature" (like our banners) on the top of that page, and then admins could display whatever they want there. Would that work?
 jywarren
on 5 Jul 2017
jywarren
on 5 Jul 2017
It would go above or below this line: https://github.com/publiclab/plots2/blob/master/app/views/tag/index.html.erb#L4
And look like:
<% cache('feature_tag-page-header') do %>
<%= feature('tag-page-header') %>
<% end %>
Well, i don't so much want to decorate that page as i want to add "insight at a glance" .
A different point, but maybe relevant as to why i'd suggest adding a graphic visualization is that this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography.
ebarry
on 5 Jul 2017
There are actually python gephi bindings which we could use to generate it dynamically. I'm actually working on a javascript network visualization right now, so let me see how that works out. If it goes well, then I can translate what I did into a python script which can generate the data structure to then be visualized in javascript.
 skilfullycurled
on 5 Jul 2017
skilfullycurled
on 5 Jul 2017
Hi, all - i think a generated graph would be great, and is something we could put in the permanent code.
@ebarry i'm not saying this is decoration and not content, i'm more saying this would go out of date quickly, and also our goal is to store /no/ content in our codebase -- only infrastructure. So this is just a way to implement it -- does my proposed solution sound OK?
re this tag page still doesn't have any sorting capabilities to see "recent" or "popular" much less to see either of those by geography. I'd be happy to work with you to come up with some feature requests to get contributors building to solve this if it's a priority for you. Could be some easy first-timers-only issues if you can help get them in the queue!
jywarren
on 5 Jul 2017
Let's go back to basics on this issue :)
What is the goal of visualizing tags?
For me, visualizing tags is a way to visually depict associated tags, e.g. tags that appear together on the same content. For great example, see the color-coded clusters in @skilfullycurled 's visualization above. Clustering tags are important because they visually connect the website's presentation of community activity _closer_ to what the Public Lab community culturally refers to as "research areas", or perhaps "topics" --> this is my actual goal with this entire issue.
Here's some background information: on our tags page (https://publiclab.org/tags) we write "We use tags to group research by topic" and encourage people to browse tags (currently only sorted by recent activity). This is an important way that we name, link to, and/or promote people to find and engage with topics. The Dashboard itself emphasizes recent activity. The Dashboard now features a "recently used tags" bar -- which is an important but partial step to the goal of seeing "research areas" or "topics".
To move forward, I am not interested in _navigating_ by a graphic tag visualization (so 2007!), however, the clusters of activity provide an important additional way of connecting/navigating to topics. To achieve the goal, by which i mean the ability for the tags page to show which are the most interconnected tags, to communicate the breadth of connected topics in a research area, to navigate/connect to a research area, and to subscribe appropriately we do not necessarily need color-coded swooping arrows. Let's think about how to achieve these goals.
We might also consider mirroring publiclab.org/tags at publiclab.org/topics to make the language more accessible.
ebarry
on 15 Nov 2017
Cool, thanks Liz!
To try for one stab at a narrower feature towards this goal, what if tag pages (floating new name: topic pages...!?!) had a list of "Related topics", something like:
Related topics:
waterrunoffwetlandsturbidity
Where "related" means that (acknowledging that there are different ways to measure this, and that we want some "computationally efficient" way) these are the tags which most commonly appear on pages that already have the primary tag. So for the topic onions, we tally every page tagged with onions and take the top, say, five.
Small follow-up if the above sounds good -- would it be all right to do this solely for the most recent 20-30 pages? Even if this is just a starting point, that would make this easier to implement without worrying about it causing overall website slowness. There could be more complex ways around this, but this is the easiest way to get started.
jywarren
on 16 Nov 2017
I cross-posted at https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages -- what do you think about moving discussion over there until there are specific discrete coding steps (mini projects for code contributors) we can make?
jywarren
on 16 Nov 2017
ok great! let's go over to that discussion and come back once we have
doable steps.
--
+1 336-269-1539 / @lizbarry http://twitter.com/lizbarry / lizbarry.net
On Wed, Nov 15, 2017 at 9:54 PM, Jeffrey Warren notifications@github.com
wrote:
I cross-posted at https://publiclab.org/questions/tommystyles/10-20-
2017/need-your-feedback-on-tag-pages -- what do you think about moving
discussion over there until there are specific discrete coding steps (mini
projects for code contributors) we can make?—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-344799932,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AAJ2n8PdvpH0GQ_wBU-Utp4xfL7XDmuJks5s26PpgaJpZM4OOvLP
.
ebarry
on 16 Nov 2017
@jywarren, @ebarry , is there any API (or maybe documentation) to know the 'edges' in the above graph ? I mean how are nodes connected ?
Thanks 😄 !
 sagarpreet-chadha
on 23 Jan 2018
sagarpreet-chadha
on 23 Jan 2018
Hey @sagarpreet-chadha!
The visualization is just an image so there's no API (yet! wink) however I can provide you with the list of edges from that particular graph. The most "raw" file formats would be csv and json. Both formats should work with a graph either "programmatically" (iGraph, networkx, d3.js) or with a GUI (Gephi, Cytoscape).
Apparently you can't upload files on github. I tried to upload them to the Public Lab research note but it's not working. @jywarren is there a way to upload files to a research note? If not, @sagarpreet-chadha, can you make a post in the plots-dev googlegroup (you can sign up here if you're not already)? Let's wait to see what @jywarren says because it would be great to have them directly in the research note.
Here's what you can look forward to though:
plots_tag_communities_edges_w_props_9_16.csv: : list of unique edges with calculated properties, in particular the weight of the edge. The weight translates to the number of times the tags occurred together.
plots_tag_communities_nodes_w_props_9_16.csv: list of nodes with calculated properties. Most relevant to the image on the website the "modularity class" which tells you to which community each node belongs.
plots_tag_communities_9_16.json: I don't find json as useful but I know some people prefer it. I think the json file also includes properties for the visualization that's on the website (i.e. RGB color of each node).
skilfullycurled
on 23 Jan 2018
Update: removed plots_tag_communities_edgelist_9_16.csv from list of files above. This file is of limited use because the duplicate edges had already been merged into unique edges with weights. Without the properties, this edge list will only allow you to build a graph with edge weights of 1. I'll look for the original file with the duplicates.
skilfullycurled
on 24 Jan 2018
Thank you @skilfullycurled for your reply !
I was actually trying to build the visualization graph using javascript library (d3.js or vis.js) so that it could be easily added to publiclab.org website . These libraries require the data in the form of :
nodes: [
{
id: 1,
shape: 'circle',
label: 'Infrared } ] for nodes .
And for edges :
edges: [
{from: 1, to: 2},
{from: 1, to: 3}]
Well json would be great otherwise i can create it , or maybe create a Javascript object directly (in this way no need of parsing the JSON file) .
I have created a dummy graph (we can play with the nodes and the edges here 😄 ):

What do you think ? @ebarry , @jywarren , @skilfullycurled
sagarpreet-chadha
on 24 Jan 2018
Ah. That would be awesome! Okay. To further this conversation, we'll need to leave "API-land" and move into into how the visualization in Gephi works and the best way to translate those features into javascript.
Can I trouble you to start this as a question? Something like, "How can I translate the tag visualization created in Gephi into a javascript version?"
Also, shoot me an email at benj.[email protected] so I can share the files. I'll remove my email once you do.
skilfullycurled
on 24 Jan 2018
Actually i think we may not need to leave API-land -- the existing API is pretty robust these days. I'm curious @skilfullycurled how you generated those edges --
could they be generated fresh from a list of all tags and the nodes they've been used on? That is a reasonable query for us to generate, if cached.
We could add it to the API at https://github.com/publiclab/plots2/tree/master/app/api/srch and document it at https://github.com/publiclab/plots2/blob/master/doc/API.md
If it is enough data, the query could be something like:
r = []
Tag.select(:name, :tid).each do |t|
nids = t.nodes.select(:nid, :status).where(status: 1).collect(&:nid)
r << [t.name, nids] if nids.length > 0
end
r # later, r.to_json
I just ran that on production and it took about 15 seconds. If we cache that daily, I think it's manageable, and we might be able to improve it further.
jywarren
on 25 Jan 2018
Also you can share files at http://gist.github.com -- could that work?
jywarren
on 25 Jan 2018
So, using the JSON generated from my query,
- in JavaScript, we could calculate the number of times the tags occurred together.
- how did you group/calculate "communities"?
Here's an excerpt:
["whitebalance", [12476, 13575]], ["wi", [12143, 13067]], ["wi-fi", [11123]], ["width-of-dvd-grating", [12838, 12875, 12895, 12899, 12902, 12926, 12990, 12991, 12995, 12999, 13006, 13014, 13019, 13037, 13046, 13057, 13062, 13069, 13077, 13088, 13089, 13094, 13103, 13117, 13125, 13131, 13133, 13136, 13152, 13154, 13157, 13159, 13169, 13178, 13181, 13183, 13188, 13226, 13248, 13283, 13302, 13305, 13308, 13315, 13316, 13340, 13349, 13355, 13366, 13401, 13402, 13409, 13414, 13423, 13429, 13432, 13434, 13437, 13439, 13440, 13443]], ["wiki", [9048, 10956]], ["wiki-gardening", [10956]], ["wild", [11707, 11711]], ["wildfires", [14803]], ["wildlife", [670]], ["wilkinson-bay", [220, 265, 280, 281, 282, 283, 284, 677]], ["wilkinsonbay", [606]], ["williamsburg", [10343, 10428, 10444]], ["willow", [9979]], ["wind", [9032, 10660, 12610, 13880, 14487, 14527, 14530, 14531, 14713, 14756]], ["wind-direction", [14527]], ["wind-sensor", [14713]], ["wind-speed-meter", [1962, 5837, 9032, 12103, 13064, 13165, 13231, 13880, 14527]], ["winder", [7717]], ["winders", [1900]], ["window", [147, 1759]], ["windows", [11434, 11677, 13037]], ["windows-7", [13037]], ["windows-7-ultimate", [13037]], ["windows-excel", [13037]], ["windspeed", [745]], ["windvane", [14527]], ["windy", [146]], ["wine", [706, 10955]], ["winter", [5161]], ["wintercamp", [5103]], ["wired", [10315]], ["wireframes", [10623]], ["wireless", [3908, 9940, 11123, 12175]], ["wisconsin", [10504, 10552, 10611, 10619, 11331, 11783, 12142, 12143, 12192, 12221, 12337, 12537, 12539, 12562, 12597, 12610, 12919, 13067, 13216, 13217, 13219, 13222, 13223, 13224, 13406, 13578, 13920, 13921, 13922, 14018, 14044, 14087, 14146, 14648]], ["with", [11772, 13742, 14728]], ["with:abdul", [13407, 13412, 13413, 13428, 13493]], ["with:adam-griffith", [11049]], ["with:amal", [12161]], ["with:amandaf", [11556]], ["with:amberwise", [12338, 13280]], ["with:ann", [12850]], ["with:basurama", [11699, 11705]], ["with:becki", [13571]], ["with:bronwen", [10952, 12480, 13493, 14587]], ["with:bsugar", [13449]], ["with:btbonval", [11789]], ["with:cfastie", [11688, 13493, 13980]], ["with:chrisjob", [10464]], ["with:cindy_excites", [11566, 11567, 14537]], ["with:damarquis", [12338]], ["with:danbeavers", [11417, 11567]],
FWIW there may be some even more efficient query like this but this is pretty decent, although doesn't return fully what's above:
Tag.select('term_data.tid, term_data.name, community_tags.nid, community_tags.tid')
.includes(:node_tag)
.references(:node_tag)
Although this wouldn't tell us if the node was published (vs. spam) unless we also mixed node.status in there. But that's possible!
jywarren
on 25 Jan 2018
Hi , i have just few questions here ,
1.) If 2 tags belong to same node , they have an edge between them ?
2.) The different colors is for different types of node like questions , notes , research-notes , etc . ?
Thank you 😄 !
sagarpreet-chadha
on 25 Jan 2018
And i also agree with not leaving the API -land :)
sagarpreet-chadha
on 25 Jan 2018
Arg! Okay. Let's not pile on, please. No one wants to stay in API-land more than I do (well, perhaps with the exception of @ebarry ). In my understanding the building of API-land had all but been delayed indefinitely due to concerns over website sluggishness (see extension of conversation here). But now @jywarren is saying it isn't as big a deal anymore, so good times on that end.
Since using Github can be a barrier to accessible information (not everyone has access, knows how to use), I think (er...thought) having conversations that aren't about "getting things done" in the codebase were better relegated to the website where everyone can learn from them. These aren't community norms I set (see @jywarren's own comment above) but I do think they are good ones.
skilfullycurled
on 25 Jan 2018
Oops, sorry @skilfullycurled I hadn't remembered your last comment on that thread -- https://publiclab.org/questions/tommystyles/10-20-2017/need-your-feedback-on-tag-pages#answer-556-comment-17709 -- where you suggested:
- only running on the top 250 tags
- caching weekly
I'll ping in back over there, but I think that with all the work on the API, code cleanup and outreach, we could do a daily or weekly cached version of such a query, and be OK with 10-15 seconds total compute time per week. The rest would be run locally in the browser. Repeating this over there.
jywarren
on 25 Jan 2018
@jywarren I'll need to get back to you on some of your questions. I'll post my jupyter notebook later. In the meantime, see here for a brief explanation of how the graph is created from the tag pairs. For exact code, see here.
@sagarpreet-chadha (and anyone else who's interested) you can see how a d3.js graph was created from the tag data by checking out the repo for tagoverflow which was the inspiration for this project.
Regarding the community detection, if you look in the tagoverflow repository you'll find that the author implemented their own algorithm. Since that time, others have been implemented such as jLouvain, netClustering a CNM implementation (d3 example). With a limit of 256 tags, they community detection is probably fine in browser.
skilfullycurled
on 25 Jan 2018
So as not to overwhelm the publiclab.org discussion with lots of data, here's a link to the format of data TagOverflow uses:
https://api.stackexchange.com/2.1/tags/python/related/?site=stackoverflow&key=of3hmyFapahonChi8EED6g((&pagesize=16
It makes like 15 calls to fetch what tags relate to a given tag (in the above example, "python")
jywarren
on 25 Jan 2018
So the difference between that and the data I generated above is that my query lists the node ids, but hasn't used them to establish "relatedness". But of course @skilfullycurled's Jupyter notebook does this! Cool, thanks for sharing!
jywarren
on 25 Jan 2018
@sagarpreet-chadha, I posted a question that asked and answered your questions above:
https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
I'm not trying to be "passive aggressive" about my request, but I think people could benefit from this aspect of the conversation being public. So I guess that makes it "aggressive aggressive". ; )
All kidding aside, happy to answer any questions!
skilfullycurled
on 25 Jan 2018
Hey everyone!
@sagarpreet-chadha, I put all of the files you'll need here:
https://spideroak.com/browse/share/skilfullyshared/plots-tag-graph
The folder comes with a readme file which explains the contents.
Please let me know when you have downloaded them so I can close the shareroom. Eventually, I'll post them to my github account for other people to have access to on the wiki.
Happy to answer any further questions you might have!
skilfullycurled
on 1 Feb 2018
Thank You @skilfullycurled !
I have downloaded the files :-)
sagarpreet-chadha
on 2 Feb 2018
No problem @sagarpreet-chadha!
PS: I left you a follow up thought back in the wiki question.
skilfullycurled
on 2 Feb 2018
Great update on ruby based tag relatedness calculations here: https://publiclab.org/questions/bsugar/01-25-2018/how-was-the-tag-graph-visualization-made
more soon!
jywarren
on 17 Jan 2019
Some progress in https://github.com/publiclab/plots2/pull/4657, where I implemented an extremely basic, but live instance of Cytoscape.js (http://js.cytoscape.org/), running off of a weekly cached collection of
It took over 50 seconds to run for ALL tags on the site (which could be cached weekly) but that also generated 8200+ tags and 31k edges... which is a lot to graph. Here's the full set; i think it includes plenty of spam tags: https://gist.github.com/jywarren/4b1f9a032092a8187dd802a375fcb700
You can specify the # of tags you want to query like this: https://stable.publiclab.org/tag/graph.json?limit=10 (once fully published, https://publiclab.org/tag/graph.json?limit=10)
It's currently limited to 5 "edges" per tagname, representing the 5 tags that occur most often alongside the original tag.
This is now live on the stable test server (although this branch rebuilds pretty often so the URL isn't always online... ironically) here:
https://stable.publiclab.org/stats/graph?limit=75
The larger counts like limit=100 or 250 seem to be showing some kind of error and I have to chase that down a bit. But this is a pretty good start.
There are LOTS of configurations that can be added to refine this -- node size, link strength, much much more -- check out the gallery at http://js.cytoscape.org for some possibilities. And making "families" may be possible too, though I'd need a bit more input for that.
jywarren
on 18 Jan 2019

jywarren
on 18 Jan 2019
Ooh, https://stable.publiclab.org/stats/graph?limit=300 seems to work too
jywarren
on 18 Jan 2019
Community detection here! https://github.com/upphiminn/jLouvain/blob/master/README.md
jywarren
on 19 Jan 2019
@jywarren , Super cool !!!
sagarpreet-chadha
on 19 Jan 2019
Also there are a range of clustering algorithms - these can be tested in the JavaScript console:
http://js.cytoscape.org/#collection/clustering
- eles.markovClustering()
- nodes.kMeans()
- nodes.kMedoids()
- nodes.fuzzyCMeans()
- nodes.hierarchicalClustering()
- nodes.affinityPropagation()
I'm not familiar with these but they all seem to use attributes of the nodes or edges to create clusters of similar elements. So, what should we give as attributes upon which to base similarity?
You can try these in the console using the examples in the docs, things like:
var clusters = cy.elements().hca({
mode: 'threshold',
threshold: 5,
attributes: [
function( node ){ return node.data('count'); }
]
});
clusters; // <= then inspect what this returns to see the clusters
OK, using jlouvain I was able to add community detection: https://github.com/upphiminn/jLouvain
I don't have enough test data to see how this'll work but if #4679 passes, i'll merge it and we should be able to see it running with community detection at:
https://stable.publiclab.org/stats/graph?limit=101
(once it builds)
jywarren
on 21 Jan 2019
Hey everyone! Looking awesome. Sorry I haven't been able to reply, catching up on somethings and will return to this later today.
In the meantime, another ingredient which I don't think I mentioned in any of my other posts is the layout. The one closest to what I used is probably the force layout. Technically it may have been something called force layout 2:
Force layout is sort of an annealing attraction/repulsion that reaches a steady state based on the parameters you set (i.e. the number of iterations, strength of attraction/repulsion). Here's a d3 demo.
As for the community detection and the edge weights you have a few options but if you want to recreate that tag graph this is in reference to, then you need co-occurrence which cytoscape, as fortune would have it, has a function to help make easier.
oe_ratio = (all_questions_count * tag_count_AB) / (tag_count_A * tag_count_B)
Where tag_count_AB = edges.parallelEdges()
As it was, I first narrowed down the set of tags to some reasonable number (say, top 512), but then I narrowed down the tags I used for the visualization by only including the top n tags (maybe 64?) with an observed to expected ratio above 1.
You can read more from Tag Overflow. This method is one way to take care of the issue where an edge or node node may be important but of low usage. For example, at a store 100 people _might_ have a 85% probability of buying coffee and cream, but five of those people _always_ purchase coffee, cream, and eggs. So I definitely want to keep 5 cartons of eggs in stock.
An easy alternative is just to make the edge weight between two nodes the tag_count_AB and only take edges/nodes above a given threshold. Personally, I rarely get good results with this due to the reason above.
Regarding the other methods, you may be interested in pg 3. (2.2) to - pg. 7 (3.1) of this paper (no math for these parts) which attempts to classify the different types of community detection methods. This has helped me to choose ones that provide the most salient results given how I've structured the graph and what I want to know from it. For example, communities of common social connections vs. communities based on how frequently messages are sent between two people.
skilfullycurled
on 21 Jan 2019
Working now on stable server!
jywarren
on 25 Jan 2019

Here w 99 top tags!
jywarren
on 25 Jan 2019
It should be running on the live site by later tonight, but i wanted to note that "overuse" of tags by some users has skewed the graph in a way that we've recognized before. I believe one of the users has been moderated from the site, and I wondered if folks thought it appropriate to either delete those tags from the site or to at least omit them from the graph. Deleting them would be easier but we can also craft something to just obscure them. Preference, @ebarry @skilfullycurled ?
Still, this looks nice even though the settings on edge elasticity still need some tweaking, and maybe a different layout type would work better...

jywarren
on 25 Jan 2019
Yup! We have definitely encountered this problem. Unfortunately, the only thing to do was to remove that particular user as an outlier. Someone using that many tags may not be an outlier in and of itself but if they are creating tags that are so specific to themselves and using them over and over again, then it's not really capturing the data.
skilfullycurled
on 25 Jan 2019
I think I even logged a github issue with a feature request that popped up a warning that would in essence say, "Whoaaaaaaaa, easy there fella! Looks like you've got yourself a lot of tags there, eh?".
skilfullycurled
on 25 Jan 2019
Oh, PS. Looking awesome by the way!!
skilfullycurled
on 25 Jan 2019
AAAAAAHHHHHHHHMAYZINGGGGGGGGGG!!!!!!!!!!!!
Yes to manually "remov[ing] that particular user as an outlier"
ebarry
on 26 Jan 2019
I just keep returning to this thread because of how awesome it is and thinking of things (hopefully tiny). Another thing you might consider filtering are the power tags (those are the ones with the colons, right?). I think as soon as the tag overuse issue is rectified, then we'll know more about layout.
Note to self: here's a link to a commit with the pages that are important to the implementation.
skilfullycurled
on 26 Jan 2019
Hi all, glad for the enthusiasm! I got sick but a recovering now and will work a bit on this on the flight home on Tuesday.
I did want to ask - my specific question is whether we should:
- actually delete tags from this moderated user, or
- if we should try to preserve them but filter them out.
Filtering would be considerably more work both to code and for the database calls, but is possible.
jywarren
on 27 Jan 2019
In cases such as this one where an account has been made "inactive" due to moderation, then I think it's fine to just delete the tags from the database outright. Especially if you have a backup. Not because you might want to restore it, just because I have anxiety about losing data forever. It's not healthy, but cheap space is an unfortunate enabler. My feelings would be more complicated if this was an account that was made "inactive" by choice but we can discuss that another time (or now).
skilfullycurled
on 27 Jan 2019
Yeah this is a big topic to contemplate. After reviewing if there are tags that _only_ this user has used (example: aries city-point), i found that actually there are very few tags completely isolated to this user (even purelab was originally used by Shan He about DIY water filtering, and research-notes was originally used on posts discussing the design of research notes on the website).
Since this user is moderated, can our tag visualization exclude all content from moderated users -- and by extension the tags used on that person's content -- without excluding that tag in general as it may be used on other people's content?
ebarry
on 28 Jan 2019
@ebarry, I should clarify (in case it wasn't).
When I said:
delete the tags from the database outright
I meant what you closed with:
...[that] our tag visualization [will] exclude all content from moderated users -- and by extension the tags used on that person's content -- without excluding that tag in general [since] it may be used on other people's content...
If the moderated user and Shan He both used the tag "purelab", "purelab" wouldn't be deleted, just any instance of the tag from the moderated user or, ITMU's, if you will.
The remaining question (if I'm understanding @jywarren) is whether or not to delete these ITMU's from the database entirely, or do we keep them in the database but filter the ITMU's out when all of the tags are requested for the visualization. Deleting them makes life much easier for those implementing the visualization, but there may be arguments for preserving them.
Personally, I think the former is okay when the user has been moderated because there is no chance that the content will ever return to the site. However, this might be different if a user chooses to delete their account based upon whether or not there is any functionality where they can reactivate it. I think we can leave that situation for another time but for the record I just wanted to say my judicial opinion is limited in scope.
skilfullycurled
on 28 Jan 2019
Yes no worries NodeTags don't delete the Tag, just the link associating
tags with nodes and authors. I already did it actually but need to flush
the weekly cache (that's what made this whole thing possible) and there are
a couple more urgent bugs to address first that just came up today, sorry!
On Mon, Jan 28, 2019, 3:24 PM skilfullycurled <[email protected]
wrote:
@ebarry https://github.com/ebarry, I should clarify (in case it wasn't).
When I said:
delete the tags from the database outright
I meant what you closed with:
...[that] our tag visualization [will] exclude all content from moderated
users -- and by extension the tags used on that person's content -- without
excluding that tag in general [since] it may be used on other people's
content...If the moderated user and Shan He both used the tag "purelab", "purelab"
wouldn't be deleted, just any instance of the tag from the moderated user
or, ITMU's, if you will.The remaining question (if I'm understanding @jywarren
https://github.com/jywarren) is whether or not to delete these ITMU's
from the database entirely, or do we keep them in the database but filter
the ITMU's out when all of the tags are requested for the visualization.Deleting them makes life much easier for those implementing the
visualization, but there may be arguments for preserving them.—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-458244753,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AABfJzTXlk18FzlER4PQyoomFE5VTFcrks5vH0AqgaJpZM4OOvLP
.
jywarren
on 28 Jan 2019
OK, managed to delete all tags created by the moderated user. They are stored in backups. This was pretty easy and won't affect code moving forward, unlike the other solution.
Now I want to suggest that there might be a different layout we want to use -- we're using a cose layout, and there are variations (bilkent and others) but there is also a cola layout. I really don't know the appropriate one to use here, but some seem to entangle the links less. Although many of the demos at http://js.cytoscape.org/ have fewer interlinks than our dataset. Any input appreciated!
Docs on built-in layouts at http://js.cytoscape.org/#layouts
Another issue we can try to ask someone to test out and take up is the question of the community detection. I haven't been able to figure out how it works or why it isn't recognizing groups here. The colors are nice, but they're one node per community. Bah.
jywarren
on 28 Jan 2019
So this issue now needs breaking up into:
- layout iteration (input welcome from current crowd)
- community detection
- additional tag filtering (maybe filter out tags with no unapproved nodes to rid ourselves of spam?)
also want to revisit that we're now viewing a specified # of tags (please don't test this to it's limits unless it's on https://stable.publiclab.org -- i've tried up to 1000 tags and it loads fine but no more than that please on the production server, even once)
And we are limited to links between them with each tag reporting a max of 10 tags that it has occurred alongside. This isn't comprehensive, but seemed a feasible balance of optimization vs. thoroughness.
jywarren
on 28 Jan 2019
jywarren
on 28 Jan 2019
@jywarren, is this still the latest commit? I because I wanted to see the json coming from the endpoint /tag/graph.json and it sent me all of the tags. Based on the code in that commit, I would have expected 250 to be the hard limit (my Ruby readability note withstanding).
skilfullycurled
on 31 Jan 2019
@jywarren never mind, I didn't realize the graph was now in the production server, I was using stable.publiclab.org.
skilfullycurled
on 31 Jan 2019
Okay. I just spent a fair amount of time exploring this, and 'm getting a better feeling for how the graph is working.
Now I want to suggest that there might be a different layout we want to use -- we're using a cose
I'll take a look and think on it. I think the question that needs to be answered here is what do we want to be gleaned from the graph? For example, if we're primarily interested in a visitor being able to see which tags are associated which ones, then the circle layout or concentric circle might be the best, boring as though they may be.
If I had to take a guess (informed, but still a guess) as to why the CoSE isn't yielding as great a result it would be because, in looking at the data, as you reach a certain node count, the counts begin to all be the similar. So, if CoSE is repelling the nodes based only on node weight, then it's possible there is an equal amount of repulsion between them. When I use repulsion here, I mean all of the things that go into repulsion, for example, it's gravity setting as well. In that case, it could be that there aren't enough iterations of the algorithm or the repulsion factors don't cause/allow for enough spreading.
Another issue we can try to ask someone to test out and take up is the question of the community detection.
When you have a moment, can you point me to the commit with the latest JavaScript on this? I can get it through the browser but only in that form where it doesn't have any structure and is just one single line. As soon as I do I can see more. I looked at the jLouvain example, and it doesn't appear to have a setting for how many communities you want which might be a part of the problem. Typically Louvain offers a "best number" but sometimes it's not the best. The python implementation that jLouvain is based on does have this parameter but it may not have made it over.
skilfullycurled
on 31 Jan 2019
There we are:
jywarren
on 1 Feb 2019

jywarren
on 1 Feb 2019
Oh i thought i'd left another comment... where'd it go? hang on...
jywarren
on 1 Feb 2019
Anyways i was going to say that I think I've figure out some of the layout issues but judge for yourselves:
https://publiclab.org/stats/graph?limit=50
https://publiclab.org/stats/graph?limit=100
jywarren
on 1 Feb 2019
Here's the JS for the community detection: https://github.com/publiclab/plots2/blob/master/app/views/tag/graph.html.erb#L263
And here's the layout configuration, which we could tweak a lot to try out:
jywarren
on 1 Feb 2019
First, I want to apologize that I can't help out with the heavy lifting on the coding end. It's easy for one just to suggest things but I realize that they also have to be implemented by people and it's not lost on my that I am not helping in that regard.
There are a number of possibilities as to why the jLouvain isn't performing well. @jywarren, I think you're already solving one of them which is that there weren't enough colors. Still, I checked in the console for the communities and each node is a different community which to me implies that the algorithm isn't finding a good place to stop. Typically, there is a parameter for how many communities/sensitivity/resolution you’d like to have and then you play with it until you get something that looks about right.
See this this issue in the jLouvain repository. Someone wrote a very simple fix which could be implemented. I’m not sure quite how it works in terms of what it returns: ideally it returns an entire community detection result for each element in the array? That’d be awesome, and probably solve the problem of each node being it’s own community.
More later…
skilfullycurled
on 1 Feb 2019
Relaying a question from @shapironick who was wondering in another channel if in a future edition there might be varying thinness and thickness in the connection lines to show how closely related any two particular tags are? Thanks!
ebarry
on 6 Feb 2019
that's a great idea. I think at this point we need to close this and open a
new issue with a checklist of possible refinements to the display, and
it'll be much easier for newcomers (less context and history required to
participate) to come in and start implementing them. I'm almost tempted to
spin it out into a new repository which is /just this graph/, since it
doesn't otherwise interconnect with the PL codebase, but for sake of
community cohesion let's keep it in plots2.
Liz, would you be able to start the new issue and kick off with a checklist?
On Wed, Feb 6, 2019 at 11:17 AM Liz Barry notifications@github.com wrote:
Relaying a question from @shapironick https://github.com/shapironick
who was wondering in another channel if in a future edition there might be
varying thinness and thickness in the connection lines to show how closely
related any two particular tags are? Thanks!—
You are receiving this because you were mentioned.
Reply to this email directly, view it on GitHub
https://github.com/publiclab/plots2/issues/1502#issuecomment-461083862,
or mute the thread
https://github.com/notifications/unsubscribe-auth/AABfJ9nxysbBtCAYHEW2tA8UwNH9zelFks5vKv_hgaJpZM4OOvLP
.
jywarren
on 6 Feb 2019
Yay! @shapironick! Right now, the database query only sends the top-n tags and the count of those tags site wide. In the future, in order to have edge weights, we'd need to make a change on the back end to either send all of the tags to the front end so the interconnecting counts could be aggregated, or they need to be aggregated on the back end. Alternatively, on the front end we calculate some network edge property (e.g., some centrality: degree, closeness, betweenness, etc.).
skilfullycurled
on 6 Feb 2019
Very cool! No presh on that idea +1 to starting a new issue this one is epic and awesome tho!
 shapironick
on 6 Feb 2019
shapironick
on 6 Feb 2019
Right now in the data we're passing to the graph code, i think we do see when one tag (say, tag A) is linked to tag B, and we see a second connection if tag B links back to tag A. But that doesn't really tell us much. Refactoring to provide "weight" is interesting... i could imagine a few ways to do this too. I agree, we could either pass in all the node.ids which each tag has, and calculate this locally, or we could try to precalculate this at the moment we collect each tag's top 5 most-related tags. (i think i changed this to 10 recently, but anyways).
Great follow-up refinement. Once we have the checklist we can prioritize a bit and gradually improve this. Thanks!
jywarren
on 6 Feb 2019
Oh look, this made it into the historical record ;) : https://publiclab.org/wiki/community-development#2019
ebarry
on 8 Feb 2019
While looking into this for a possible Summer of Code project this upcoming summer, I found the community detection bug, which was subtle -- data was in a nested object like {data: { DATA }} rather than just { DATA }. Fixed in https://github.com/publiclab/plots2/pull/9169 !
jywarren
on 9 Feb 2021

jywarren
on 9 Feb 2021
That's just with our test data; full fix will be visible in the stable server once we merge it and it rebuilds; probably 30m or so.
jywarren
on 9 Feb 2021
Nice there we go:
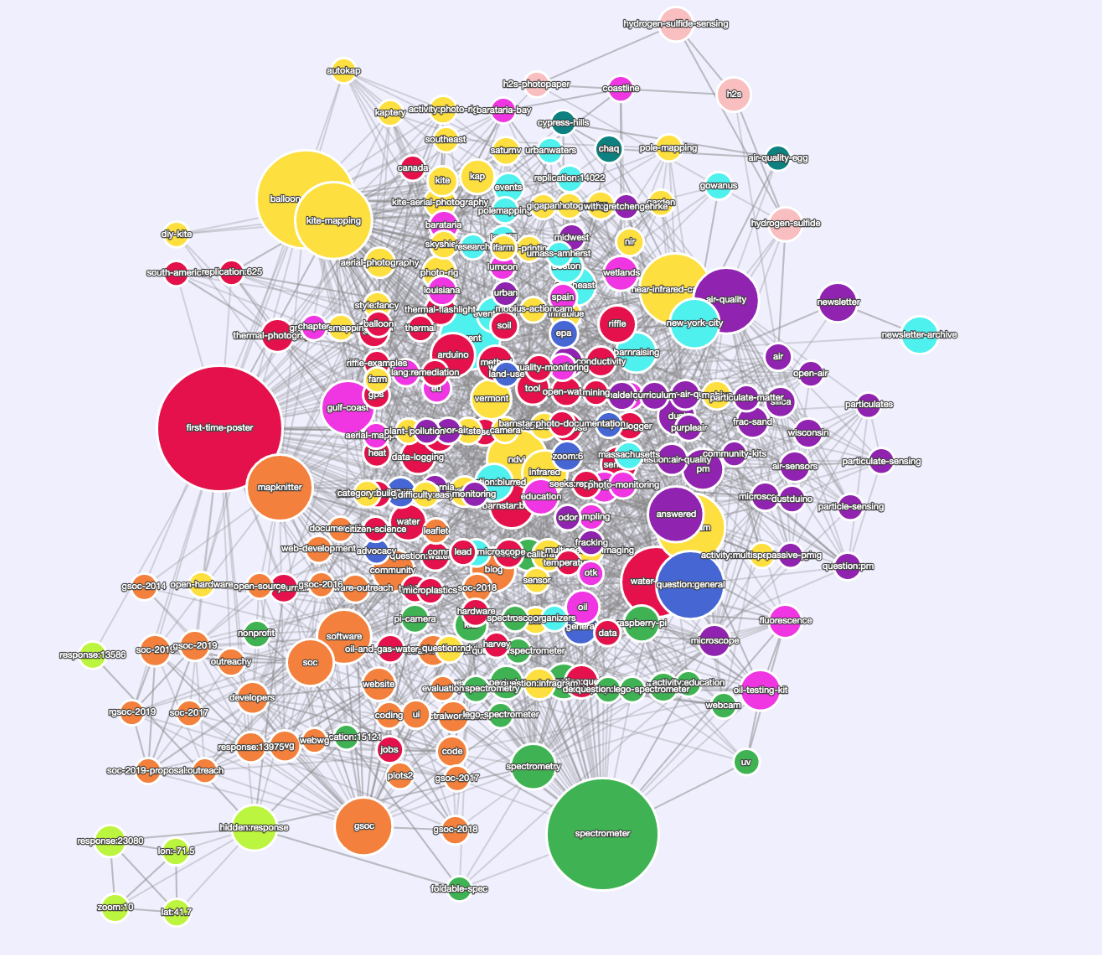
https://stable.publiclab.org/tags (remember this will go down for 10m each time we merge a new change)
jywarren
on 9 Feb 2021
Related issues
 keshavsethi
·
3Comments
keshavsethi
·
3Comments
 milaaraujo
·
3Comments
milaaraujo
·
3Comments
![first-timers[bot] picture](https://avatars.githubusercontent.com/in/4832?v=4&s=40) first-timers[bot]
·
3Comments
first-timers[bot]
·
3Comments
 grvsachdeva
·
3Comments
grvsachdeva
·
3Comments
 noi5e
·
3Comments
noi5e
·
3Comments
Most helpful comment
It should be running on the live site by later tonight, but i wanted to note that "overuse" of tags by some users has skewed the graph in a way that we've recognized before. I believe one of the users has been moderated from the site, and I wondered if folks thought it appropriate to either delete those tags from the site or to at least omit them from the graph. Deleting them would be easier but we can also craft something to just obscure them. Preference, @ebarry @skilfullycurled ?
Still, this looks nice even though the settings on edge elasticity still need some tweaking, and maybe a different layout type would work better...