Pkp-lib: [OJS] DOI status functions broken in Crossref plugin
The status of DOIs is not updated in the Crossref plugin when you select a DOI and hit the Mark Active button. Probably also DOIs that are deposited do not get their status updated.
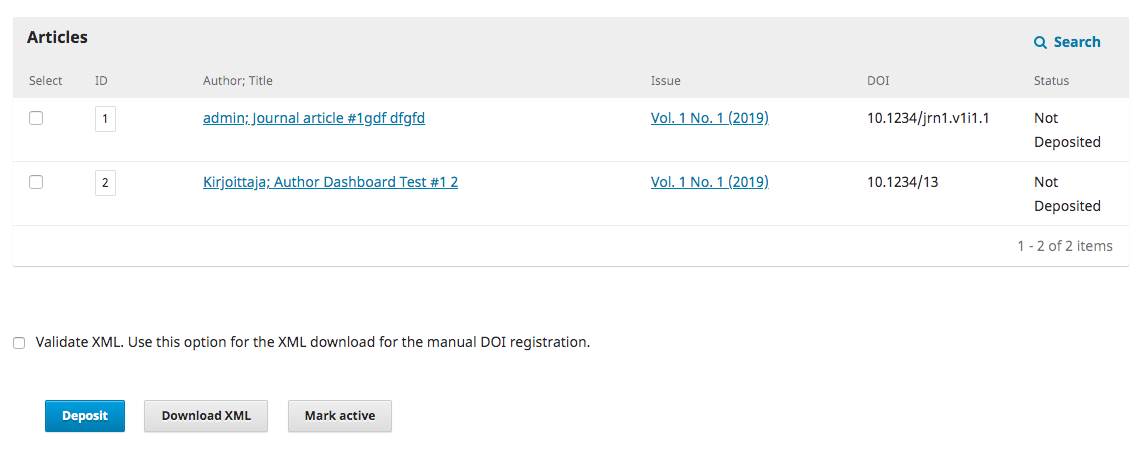
The action calls markRegistered here:
https://github.com/pkp/ojs/blob/master/plugins/importexport/crossref/CrossRefExportPlugin.inc.php#L392
Calling saveRegisteredDoi
https://github.com/pkp/ojs/blob/master/classes/plugins/DOIPubIdExportPlugin.inc.php#L98
Which adds the crossref::registeredDoi to the passed object.
Then it call the updateObject function here: https://github.com/pkp/ojs/blob/master/classes/plugins/PubObjectsExportPlugin.inc.php#L386
But the crossref::registeredDoi selection is not saved to the settings.
It seems that the updateObject ignores the getAdditionalFieldNames function here and does not consider those fields at all.
https://github.com/pkp/ojs/blob/master/plugins/importexport/crossref/CrossRefExportPlugin.inc.php#L167
 ajnyga
ajnyga
All 17 comments
cc @jmacgreg
 NateWr
on 6 Feb 2020
NateWr
on 6 Feb 2020
The issue is that the DOIPubIdExportPlugin wants to store a setting with the submission (e.g. in submission_settings), but that SubmissionDAO is now backed by SchemaDAO. The getAdditionalFieldNames mechanism is not supported by SchemaDAO.
The new equivalent is the Schema::get::submission hook, as per this this draft.
However, as it stands an import/export plugin (or really anything that's not a generic plugin) cannot use that mechanism as it depends on the plugin being loaded. Otherwise the get/update methods will strip the content when the plugin isn't being loaded.
I think this introduces a couple of additional problems -- if a generic plugin uses this mechanism to store data, but is disabled or removed, its data will gradually become stripped from the elements it used to be attached to.
I suggest we move to being permissive about maintaining and fetching data that's not described by the schema, like we used to do in the _settings tables. @NateWr, what do you think?
 asmecher
on 14 Feb 2020
asmecher
on 14 Feb 2020
Thanks Alec, would have never figured that out!
ajnyga
on 14 Feb 2020
@AhemNason and I have also replicated this, using the Crossref test deposit API. If/when there's a fix, we can test.
 jmacgreg
on 14 Feb 2020
jmacgreg
on 14 Feb 2020
Behaviour we've seen, in more detail:
1) publish article;
2) manually deposit article using the Crossref test deposit API - the deposit API indicates success;
3) OJS doesn't display the new status, and there's no additional recording of the status in the publications table (ie. no crossref::status record).
jmacgreg
on 14 Feb 2020
@jmacgreg and @AhemNason, I've applied the draft work-around to the testing installation so testing can proceed while a nicer solution is worked out!
asmecher
on 14 Feb 2020
I've tested this - the work-around works, deposits are made, and statuses are updated!
jmacgreg
on 14 Feb 2020
Excellent, thanks, @jmacgreg!
@NateWr, of all this noise, only this is relevant to you: https://github.com/pkp/pkp-lib/issues/5474#issuecomment-586059808
asmecher
on 14 Feb 2020
So should I use the same code in OPS?
ajnyga
on 14 Feb 2020
@ajnyga, you mean the draft code mentioned in https://github.com/pkp/pkp-lib/issues/5474#issuecomment-586059808? No, that's not ready yet; it's just a work-around. Watch this issue for PRs.
asmecher
on 14 Feb 2020
I think this introduces a couple of additional problems -- if a generic plugin uses this mechanism to store data, but is disabled or removed, its data will gradually become stripped from the elements it used to be attached to.
I suggest we move to being permissive about maintaining and fetching data that's not described by the schema, like we used to do in the _settings tables. @NateWr, what do you think?
Data that does not match the schema won't be loaded but it should not be deleted. If data is added by a plugin and that plugin is removed, the data should remain in the database even if it is not retrieved with the object and passed around.
If that's not the case -- if a settings row is getting deleted when its property doesn't exist in the schema -- that's a bug.
However, as it stands an import/export plugin (or really anything that's not a generic plugin) cannot use that mechanism as it depends on the plugin being loaded.
In my view, this is a challenging issue with the way that plugin categories work and one reason why we should move more plugins to generic plugins. A plugin category should only ever exist when it has a very specific function, and category plugins should only ever work with their own plugin_settings table.
As a temporary workaround to this issue for pubid plugins in v3.2, I load them early in the request:
https://github.com/pkp/pkp-lib/blob/master/classes/core/Dispatcher.inc.php#L132-L133
Although its not an approach we can use in every case, this may work to solve this issue at this late stage for 3.2.
Long-term I think that what we're dealing with is plugins that really push the boundaries of how categories were envisioned. In both use cases (pub-ids and crossref exports) I think that what we want are plugins which extend the underlying data structure of an entity, and then that data may be exposed in lots of different ways. With crossref we're going to want to add UI indications of deposit status in a centralized panel as the plugin already does, but also eventually in the workflow, in submissions lists, etc. In these cases it's very difficult to predict when they'll be needed beyond the specific use cases at any given time, and our evolving UI means that we're constantly calling them into action under new circumstances.
One way to do this is to migrate more plugins to the generic category and to make use of hooks rather than loading plugins at specific times. To do that, though, we'll also need to think about how these plugins are architected so that they can be "loaded" early in the boot process but don't actually execute much of their code until they're called upon. This is how hooks work in WordPress. Most plugins do nothing on load other than register hooks, so that loading them doesn't provide a meaningful drag on performance. This is also, though, why a lot of WordPress sites run slowly. A carelessly written plugin can execute a lot of unnecessary code.
NateWr
on 17 Feb 2020
I double-checked this and can confirm that settings not included in the schema's self-description are maintained, i.e. deletion/stripping of these settings is not a problem. However, some of the objects that need their entities extended have DAOs that are SchemaDAOs and some don't, and the extension mechanisms are different. I'm still wading through the details...
asmecher
on 21 Feb 2020
Merged the fix for PKPPubIdPlugin and co. (https://github.com/asmecher/ojs/commit/873479535825777cfa4bfcbeaab156d54e32f139 https://github.com/asmecher/pkp-lib/commit/8c5a2f19e763a175a184b4b1f27163fbf0fdd3c2 https://github.com/pkp/omp/commit/42f2fcbf5203ea488530b14dee1e1784805cd732) to master.
asmecher
on 24 Feb 2020
@NateWr (and @ajnyga), here's the PR for part 2 of this fix: https://github.com/pkp/ojs/pull/2641/files
Here's what it does...
- Adds a new function that PubObjectsExportPlugin (and subclasses) can use to list new settings that will be stored with the pub object. This cuts down code duplication.
- Moves the schema augmentation from just-before-the-object-is-updated (it's too late by this point, as data that's in the DB won't be loaded into the
DataObjectunless it's also described by the schema) to the plugin's registration function. - Adds a new function listing DAOs for objects that need to be augmented. This is necessary because the plugin registration function needs to know which objects to augment per the above change. This parallels a function in
PKPPubIdPlugin.
With this change, both PKPPubIdPlugin and PubObjectsExportPlugin have parallel implementations for SchemaDAO vs. RegularDAO backed objects. These can be simplified once all the objects they deal with are adapted over to using the schema toolset. Meanwhile the complexity is not too bad and the details are at least kept to just a couple of classes.
@NateWr, please let me know if this checks out for you, and if so I'll update the testing installation for another quick round of DOI/CrossRef testing. And of course porting to OPS, @ajnyga! Thanks, both.
asmecher
on 26 Feb 2020
I will cherry-pick this to OPS as soons as I see a commit to OJS
ajnyga
on 26 Feb 2020
I left a comment on the PR but it looks like a really clever solution. It's also good to have an option for extending a schema even after it has been loaded for cases like this where there's little wiggle room. :+1:
NateWr
on 26 Feb 2020
Committed to OJS -- thanks, @NateWr -- and ready for porting to OPS, @ajnyga! I'll update the testing install and let Mike know so we can get a bit of extra smoke testing on this. Thanks all!
asmecher
on 26 Feb 2020
Related issues
NateWr
·
5Comments
 jonasraoni
·
6Comments
ajnyga
·
7Comments
jonasraoni
·
6Comments
ajnyga
·
7Comments
 mtub
·
6Comments
mtub
·
6Comments
 Ph-We
·
3Comments
Ph-We
·
3Comments